一、介绍
RSRS(阻力支撑相对强度)是一种基于价格阻力位与支撑位动态变化的市场择时技术指标,由光大证券在2017年提出。其核心原理是通过量化最高价与最低价之间的线性关系,预测市场趋势变化。
原理:
- 线性回归建模:取N日最高价和最低价,以最低价为自变量,最高价为因变量进行线性回归,得到斜率(beta)。斜率反映支撑位强度与阻力位强度的比值。
- 动态阈值 :计算斜率的滚动均值和标准差,将当前斜率标准化为Z分数(标准分)。Z分数反映当前支撑阻力强度在历史中的相对位置。
3 交易信号:当标准分突破阈值(如>1)时买入,跌破阈值(如<0.8)时卖出。结合均线、成交量等可进一步优化策略。
策略优化方向(报告中提及):
- 均线过滤:结合20日均线方向过滤开仓信号
- 成交量验证:加入量价相关性分析
- 动态阈值:使用滚动窗口计算自适应的交易阈值
- 右偏修正:通过R²和斜率乘积降低低质量信号的权重
该指标在沪深300、上证50等指数回测中显示出较强的左侧预判能力,但需注意参数敏感性和市场适应性。完整策略实现需结合具体风控规则和成本控制。
pdf原文我放在群文件里: 《20170501-基于阻力支撑相对强度(RSRS)的市场择时.pdf》
二、关键点阐述
我们考虑另外一种阻力位与支撑位的运用方式,关注点不再是直接地把它们理解为价格区间的阈值,而是考虑它们之间的相对强度。也就是说,我们不再把阻力位与支撑位当做一个定值,而是看做一个变量。
我们用 high的变化量/low的变化量 来作为支撑位、阻力位的相对强度,换言之,就是最低价每变动1单位时 最高价变动的幅度。
又因为:high的变化量/low的变化量 = (high1-high0)/(low1-low0),所以只需要计算(low0,high0)、(low1,high1)两点的斜率就行。为了降低噪音,我们通过多个点进行最小二乘拟合,这样算出来的斜率曲线更加准确。
三、代码实现
python
import pandas as pd
import numpy as np
import statsmodels.api as sm
def calculate_rsrs(df, n=18, lookback=600):
"""
计算RSRS右偏标准分指标
df 包括 high, low
"""
# 1. 计算斜率beta
beta_list = []
r2_list = []
for i in range(n, len(df)):
# 第一列是常数1(初始值,fit后会调整);第二列为原本选定的 low 列数值
x = sm.add_constant(df['low'].iloc[i-n:i])
y = df['high'].iloc[i-n:i]
# y = constant*1 + beta*x (所以前面加了一列1)
# OLS 类(普通最小二乘法)
model = sm.OLS(y, x).fit()
# 它代表直线的斜率(beta)
beta = model.params[1]
# R²:模型拟合度、解释力,值在 0 到 1 之间,越接近 1 表示模型拟合的越好。
r2 = model.rsquared
beta_list.append(beta)
r2_list.append(r2)
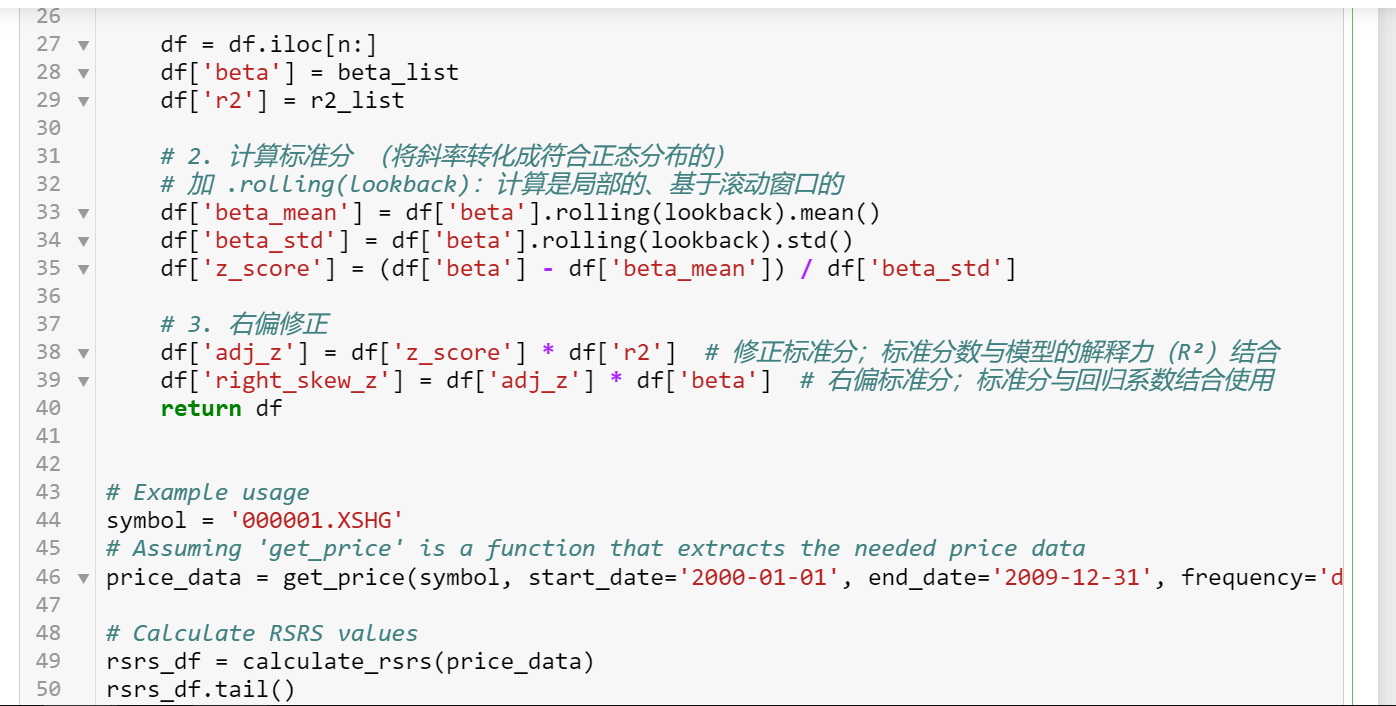
df = df.iloc[n:]
df['beta'] = beta_list
df['r2'] = r2_list
# 2. 计算标准分 (将斜率转化成符合正态分布的)
# 加 .rolling(lookback):计算是局部的、基于滚动窗口的
df['beta_mean'] = df['beta'].rolling(lookback).mean()
df['beta_std'] = df['beta'].rolling(lookback).std()
df['z_score'] = (df['beta'] - df['beta_mean']) / df['beta_std']
# 3. 右偏修正
df['adj_z'] = df['z_score'] * df['r2'] # 修正标准分;标准分数与模型的解释力(R²)结合
df['right_skew_z'] = df['adj_z'] * df['beta'] # 右偏标准分;标准分与回归系数结合使用
return df
# Example usage
symbol = '000001.XSHG'
# Assuming 'get_price' is a function that extracts the needed price data
price_data = get_price(symbol, start_date='2000-01-01', end_date='2009-12-31', frequency='daily', fields=['high', 'low'])
# Calculate RSRS values
rsrs_df = calculate_rsrs(price_data)
rsrs_df.tail()| | high | low | beta | r2 | beta_mean | beta_std | z_score | adj_z | right_skew_z |
| 2009-12-25 | 3154.77 | 3128.15 | 0.910763 | 0.871082 | 0.923743 | 0.099105 | -0.130978 | -0.114092 | -0.103911 |
| 2009-12-28 | 3202.09 | 3148.86 | 0.930477 | 0.867347 | 0.923685 | 0.099091 | 0.068542 | 0.059450 | 0.055317 |
| 2009-12-29 | 3212.52 | 3166.76 | 0.946970 | 0.871842 | 0.923622 | 0.099064 | 0.235687 | 0.205482 | 0.194585 |
| 2009-12-30 | 3267.00 | 3206.22 | 0.955810 | 0.871369 | 0.923794 | 0.099030 | 0.323293 | 0.281708 | 0.269259 |
| 2009-12-31 | 3282.21 | 3250.03 | 0.939307 | 0.883740 | 0.924108 | 0.098779 | 0.153871 | 0.135982 | 0.127729 |
|---|

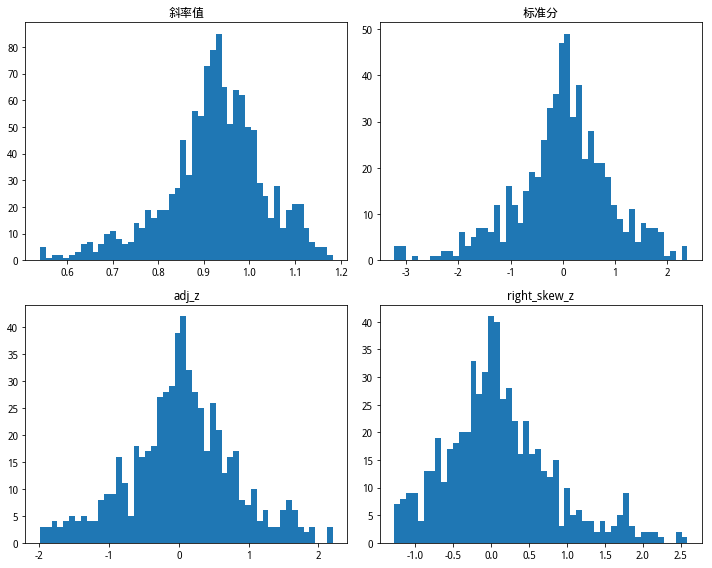
我们使用'right_skew_z'字段内容,判断一个阈值,来进行买卖。(下一节将使用其进行回测)
然后,我们可以作图看一下分布情况
python
import matplotlib.pyplot as plt
# 设置字体 用来正常显示中文标签
mpl.rcParams['font.sans-serif'] = ['SimHei']
# 用来正常显示负号
plt.rcParams['axes.unicode_minus'] = False
# 创建一个2x2的画布,设置图形大小
fig, axs = plt.subplots(2, 2, figsize=(10, 8))
# 画第一个柱状图
axs[0, 0].hist(rsrs_df['beta'], bins=50)
axs[0, 0].set_title("斜率值")
# 画第二个柱状图
axs[0, 1].hist(rsrs_df['z_score'], bins=50)
axs[0, 1].set_title("标准分")
# 画第三个柱状图
axs[1, 0].hist(rsrs_df['adj_z'], bins=50)
axs[1, 0].set_title("adj_z")
# 画第四个柱状图
axs[1, 1].hist(rsrs_df['right_skew_z'], bins=50)
axs[1, 1].set_title("right_skew_z")
# 调整布局,避免标题及标签的重叠
plt.tight_layout()
# 显示图表
plt.show()