一、核心概念:
1.Spark-Streaming 是流式数据处理框架,基于 **DStream(离散化流)** 抽象,将实时数据划分为多个时间区间的 RDD 序列。
DStream 本质是RDD 序列,每个时间区间数据对应一个 RDD。
2.特点:
易用性:支持 Java、Python、Scala 等语言,编程方式类似离线处理。
容错性:无需额外配置即可恢复丢失数据。
易整合性:可与 Spark 批处理结合,支持离线与实时处理统一代码。
3.架构与机制:
背压机制:Spark 1.5 + 引入,通过spark.streaming.backpressure.enabled控制(默认false),根据作业执行情况动态调整数据接收速率,替代静态参数spark.streaming.receiver.maxRate。
实操案例:
WordCount 案例:通过socketTextStream读取 TCP 端口(如 9999)数据,经flatMap、map、reduceByKey等操作统计单词计数,时间间隔设置为3 秒
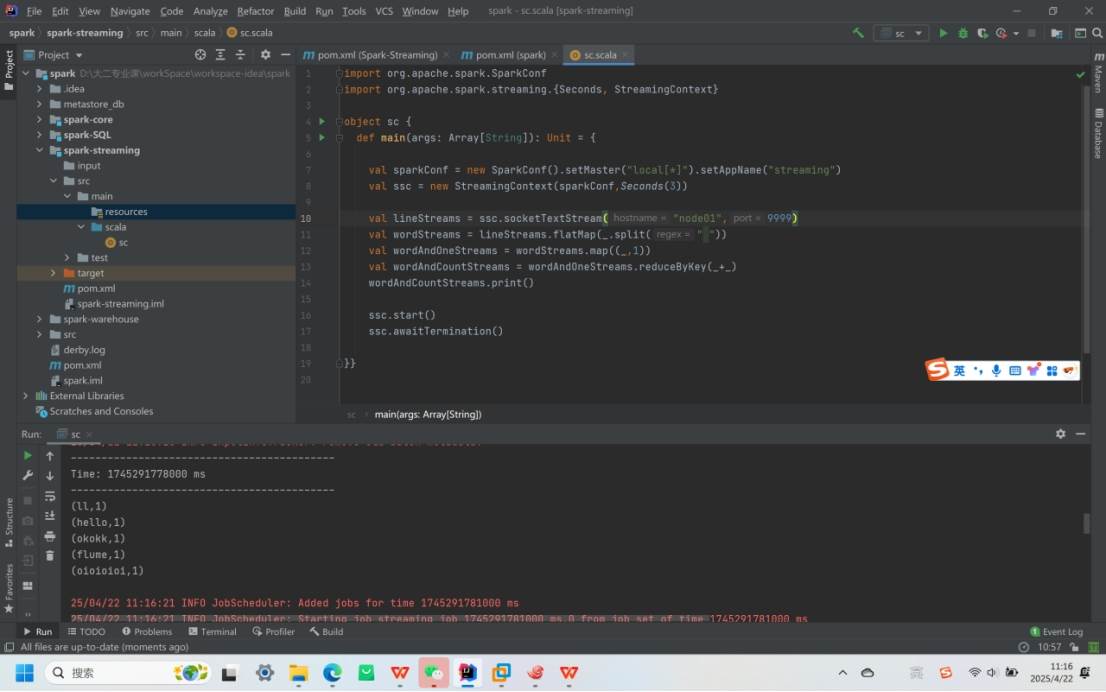
二、Spark-Streaming 核心编程
1.DStream 创建方式:
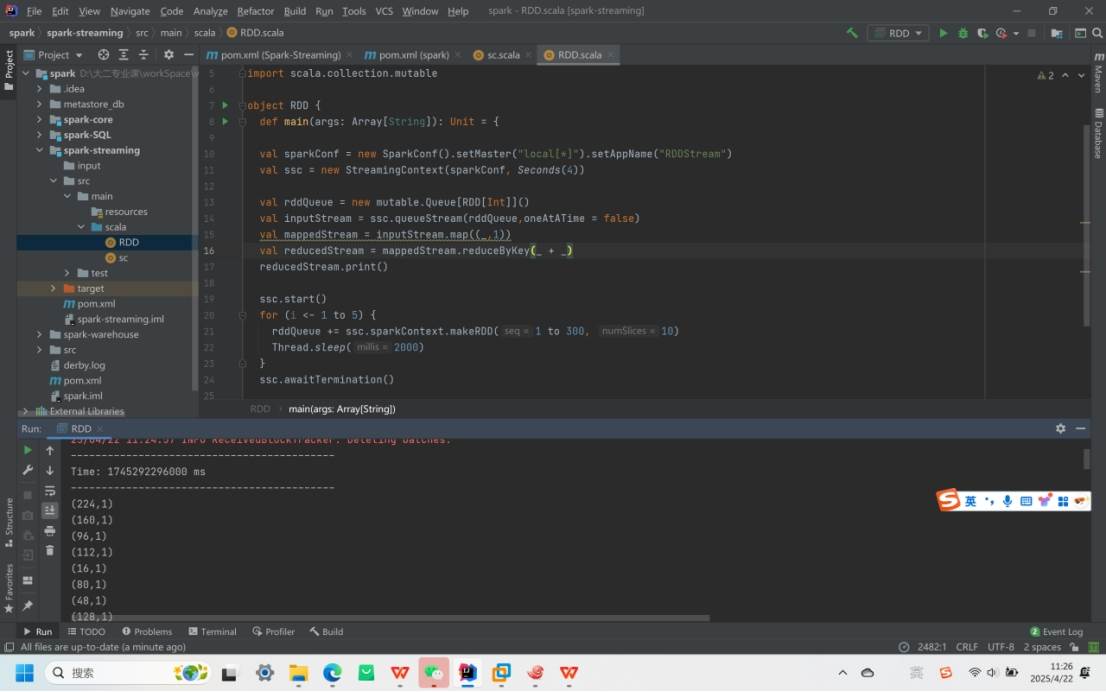
RDD 队列:通过ssc.queueStream(queueOfRDDs)创建,案例中使用队列循环添加 RDD(含 1-300 的整数),时间间隔4 秒,每次添加后线程休眠2000 毫秒。
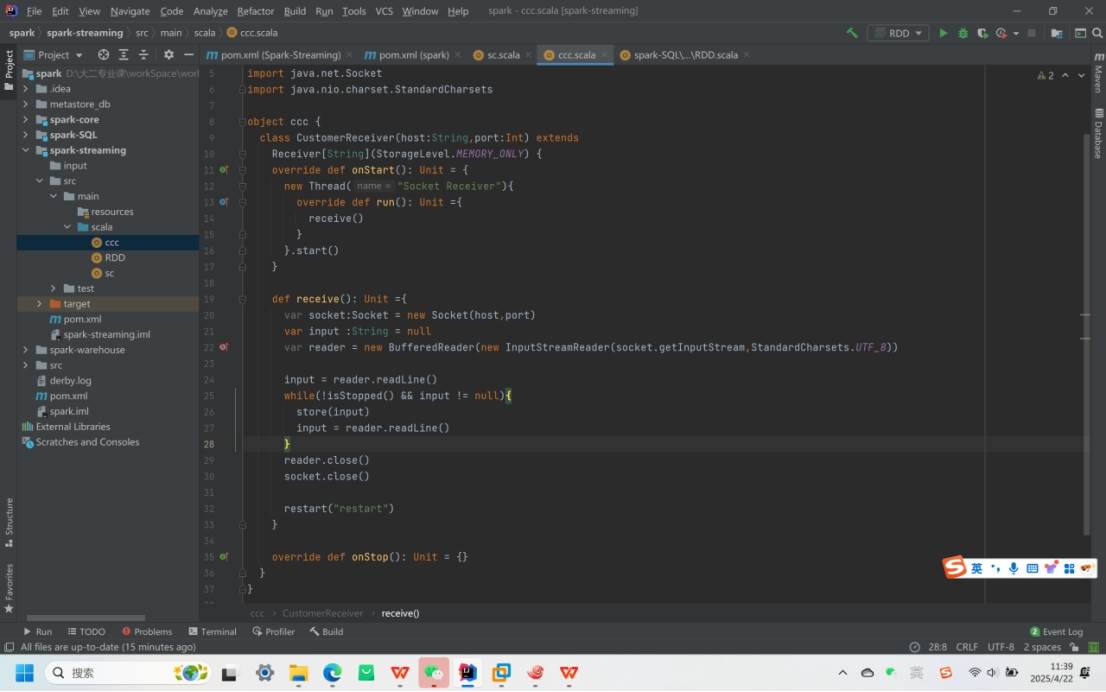
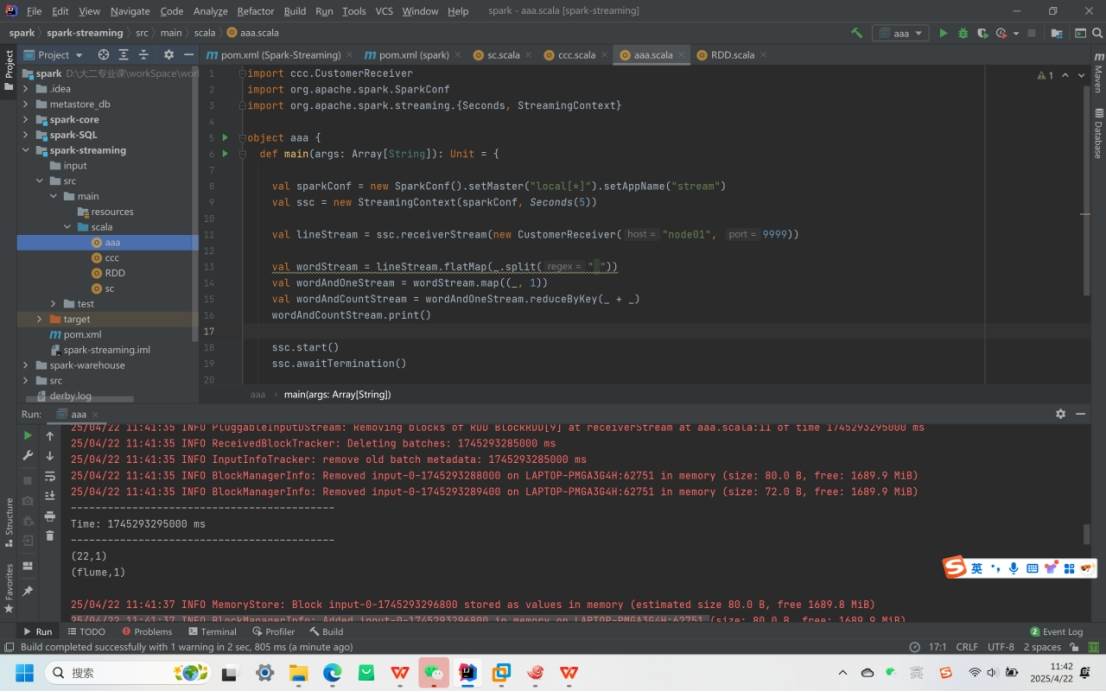
自定义数据源:继承Receiver类,实现onStart(启动线程接收数据)和onStop方法,案例中监控端口 9999,时间间隔5 秒,通过receiverStream获取数据。
关键实现:
自定义CustomerReceiver类通过 Socket 读取指定端口数据,使用store(input)存储数据,并在连接中断时调用restart("restart")重启