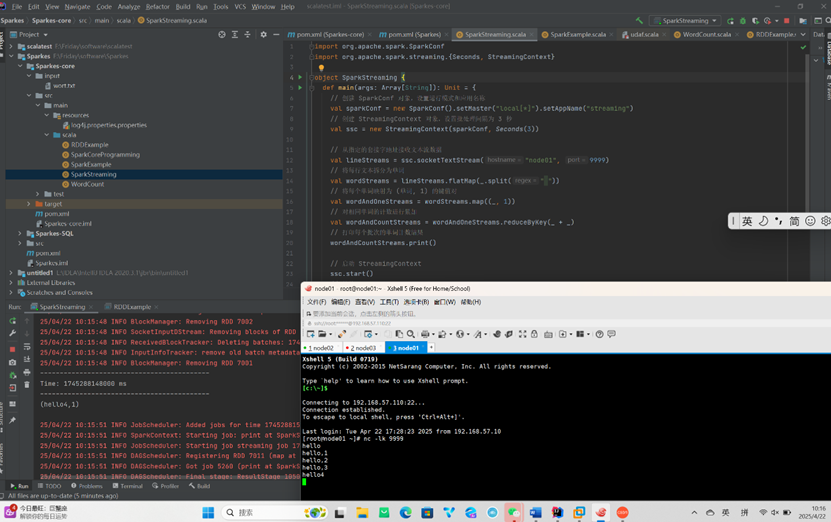
WordCount案例
添加依赖
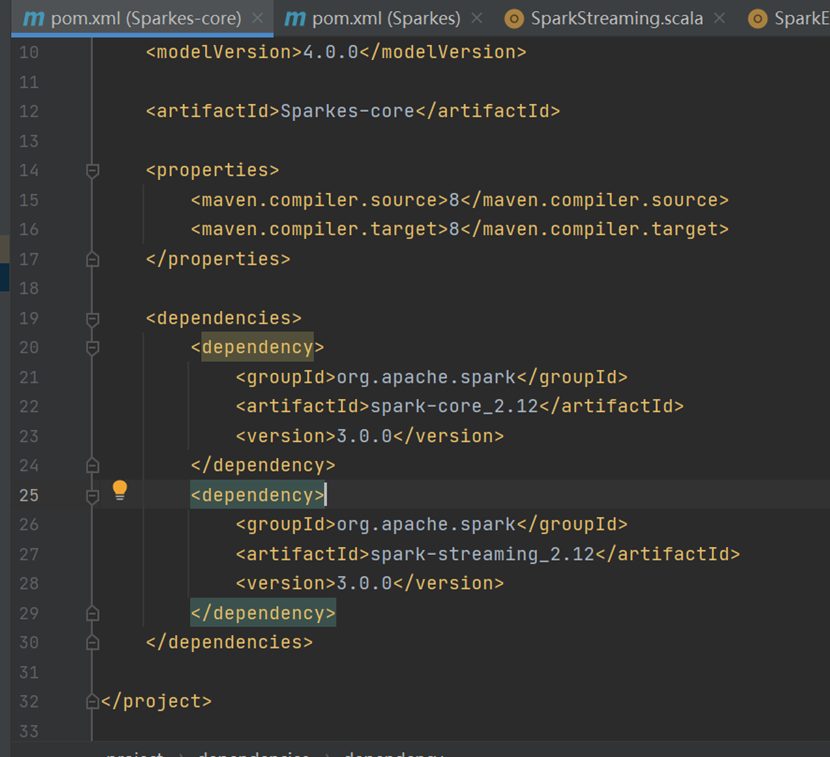
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>Sparkes</artifactId>
<groupId>org.example</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>Sparkes-core</artifactId>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.12</artifactId>
<version>3.0.0</version>
</dependency>
</dependencies>
</project>
代码
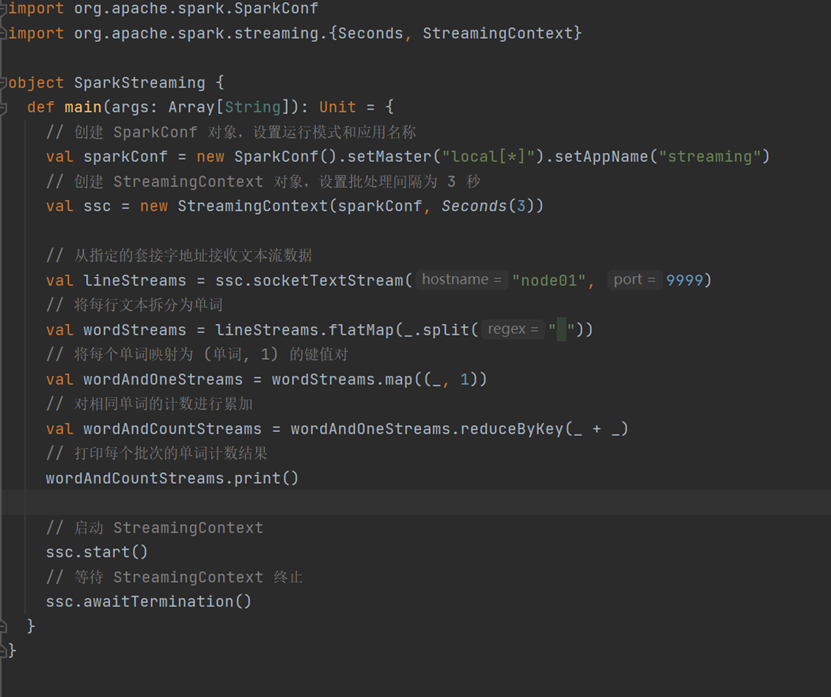
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
object SparkStreaming {
def main(args: ArrayString): Unit = {
// 创建 SparkConf 对象,设置运行模式和应用名称
val sparkConf = new SparkConf().setMaster("local\*").setAppName("streaming")
// 创建 StreamingContext 对象,设置批处理间隔为 3 秒
val ssc = new StreamingContext(sparkConf, Seconds (3))
// 从指定的套接字地址接收文本流数据
val lineStreams = ssc.socketTextStream("node01", 9999)
// 将每行文本拆分为单词
val wordStreams = lineStreams.flatMap(_.split(" "))
// 将每个单词映射为 (单词, 1) 的键值对
val wordAndOneStreams = wordStreams.map((_, 1))
// 对相同单词的计数进行累加
val wordAndCountStreams = wordAndOneStreams.reduceByKey(_ + _)
// 打印每个批次的单词计数结果
wordAndCountStreams.print()
// 启动 StreamingContext
ssc.start()
// 等待 StreamingContext 终止
ssc.awaitTermination()
}
}