概述
在有大量数据需要写入到HBase当中时,通常有put 和Bulkload两种方式。
put方式
在put数据时会先将数据的更新操作信息和数据信息写入WAL,在写入到WAL后,数据就会被放到MemStore中,当MemStore满后数据就会被 flush 到磁盘(即形成HFile文件)。在这种写操作过程会涉及到 flush、split、compaction 等操作,容易造成节点不稳定、数据导入慢、耗费资源等问题。在海量数据的导入过程极大的消耗了系统性能。避免这些问题最好的方法就是使用 BulkLoad 的方式来加载数据到 HBase 中。
scala
val put = new Put(rowKeyBytes)
put.addColumn(cf, column, value)
put.addColumn(cf, column, value)
put.addColumn(cf, column, value)
put.addColumn(cf, column, value)
table.put(put)HBase 写入路径流程图
Client RegionServer WAL Memstore HFile Put/Delete Write to WAL Write to memstore Flush to disk Client RegionServer WAL Memstore HFile
Bulkload方式
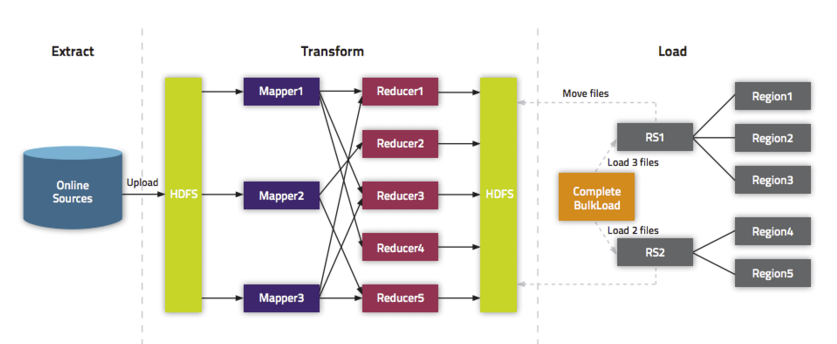
BulkLoad 数据导入流程
- BulkLoader 利用 HBase 数据按照 HFile 格式存储在 HDFS 的原理,使用 MapReduce 直接批量生成 HFile 格式文件后,RegionServers 再将 HFile 文件移动到相应的 Region 目录下。
BulkLoad 流程图