39.替换所有的问号
给你一个仅包含小写英文字母和 '?' 字符的字符串 s,请你将所有的 '?' 转换为若干小写字母,使最终的字符串不包含任何 连续重复 的字符。
注意:你 不能 修改非 '?' 字符。
题目测试用例保证 除 '?' 字符 之外,不存在连续重复的字符。
在完成所有转换(可能无需转换)后返回最终的字符串。如果有多个解决方案,请返回其中任何一个。可以证明,在给定的约束条件下,答案总是存在的。
示例 1:
输入: s = "?zs"
输出: "azs"
解释: 该示例共有 25 种解决方案,从 "azs" 到 "yzs" 都是符合题目要求的。只有 "z" 是无效的修改,因为字符串 "zzs" 中有连续重复的两个 'z' 。
示例 2:
输入: s = "ubv?w"
输出: "ubvaw"
解释: 该示例共有 24 种解决方案,只有替换成 "v" 和 "w" 不符合题目要求。因为 "ubvvw" 和 "ubvww" 都包含连续重复的字符
我们遍历这个数组,当碰到一个问号的时候,那么我们就用a~z进行替换,并且一次进行判断是否重复了
C++
class Solution {
public:
string modifyString(string s)
{
int n=s.size();//计算字符串的长度
for(int i=0;i<n;i++)
{
//遇到问号我们就将这个进行替换
if(s[i]=='?')
{
for(char ch='a';ch<='z';ch++)
{
//改变这个字符不能和前面相同,
//因为我们这里是不能存在连续的重复的字符的
if((i==0||ch!=s[i-1])&&(i==n-1||ch!=s[i+1]))//i=0就是前面字符不存在的情况,第一个括号就是判断i的位置是不是和前面位置的字符相等,第二个符号就是判断是否和后面的字符相等
{
s[i]=ch;//我们直接将当前的字符ch放进去
break;
}
}
}
}
return s;
}
};我们先利用遍历数组找到我们的这个字符串中的问号,然后对当前位置进行字符的插入,然后在插入字符的时候对前后位置的字符进行判断,是否和当前插入的字符相等,不能是连续的重复字符
40.提莫攻击
在《英雄联盟》的世界中,有一个叫 "提莫" 的英雄。他的攻击可以让敌方英雄艾希(编者注:寒冰射手)进入中毒状态。
当提莫攻击艾希,艾希的中毒状态正好持续 duration 秒。
正式地讲,提莫在 t 发起攻击意味着艾希在时间区间 [t, t + duration - 1](含 t 和 t + duration - 1)处于中毒状态。如果提莫在中毒影响结束 前 再次攻击,中毒状态计时器将会 重置 ,在新的攻击之后,中毒影响将会在 duration 秒后结束。
给你一个 非递减 的整数数组 timeSeries ,其中 timeSeries[i] 表示提莫在 timeSeries[i] 秒时对艾希发起攻击,以及一个表示中毒持续时间的整数 duration 。
返回艾希处于中毒状态的 总 秒数。
示例 1:
输入: timeSeries = 1,4, duration = 2
输出: 4
解释: 提莫攻击对艾希的影响如下:
- 第 1 秒,提莫攻击艾希并使其立即中毒。中毒状态会维持 2 秒,即第 1 秒和第 2 秒。
- 第 4 秒,提莫再次攻击艾希,艾希中毒状态又持续 2 秒,即第 4 秒和第 5 秒。
艾希在第 1、2、4、5 秒处于中毒状态,所以总中毒秒数是 4 。
示例 2:
输入: timeSeries = 1,2, duration = 2
输出: 3
解释: 提莫攻击对艾希的影响如下:
- 第 1 秒,提莫攻击艾希并使其立即中毒。中毒状态会维持 2 秒,即第 1 秒和第 2 秒。
- 第 2 秒,提莫再次攻击艾希,并重置中毒计时器,艾希中毒状态需要持续 2 秒,即第 2 秒和第 3 秒。
艾希在第 1、2、3 秒处于中毒状态,所以总中毒秒数是 3 。
如果我们相邻中毒时间点之间的差值大于等于d的话,那么我们是需要将差值累加上的
如果相邻中毒时间小于d的话,那么我们就说明我们在a点中毒了,但是只能中毒b-a秒,而不是完整的d秒,所以这里我们的中毒时间就是d-a秒
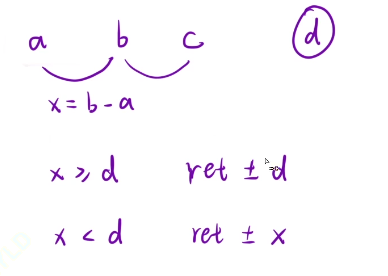
如果我们的时间差值小于中毒时间的话那么就是会进行重置操作的
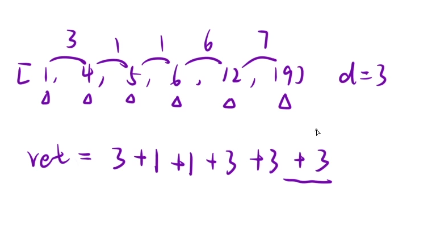
C++
class Solution
{
public:
int findPoisonedDuration(vector<int>& timeSeries, int duration)
{
int ret=0;//记录最终的中毒时间
for(int i=1;i<timeSeries.size();i++)
{
int x=timeSeries[i]-timeSeries[i-1];//计算我们当前位置和前一秒位置的时间差值
if(x>=duration) ret+=duration;//差值大于我们的中毒时间的话
else ret+=x;//差值小于我们的中毒时间的话
}
//到这里的话,我们还没有计算最后的时间中毒的
return ret+=duration;
}
};41.Z字形变换
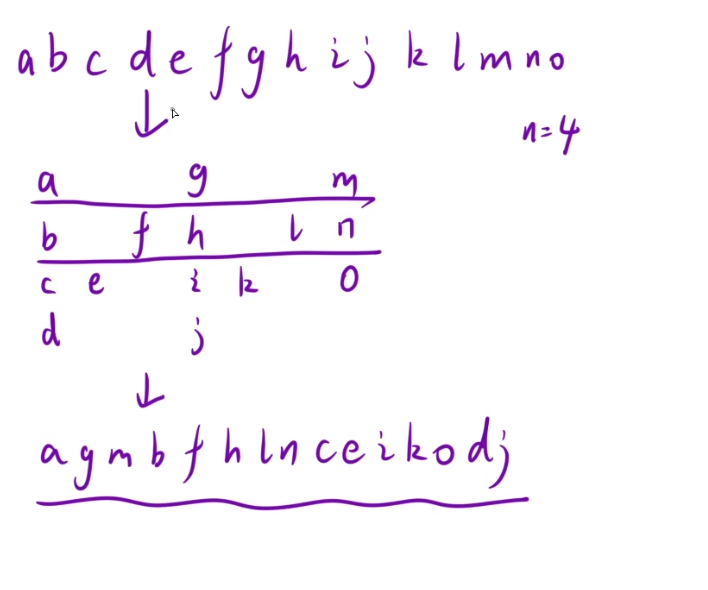
将一个给定字符串 s 根据给定的行数 numRows ,以从上往下、从左到右进行 Z 字形排列。
比如输入字符串为 "PAYPALISHIRING" 行数为 3 时,排列如下:
P A H N
A P L S I I G
Y I R
之后,你的输出需要从左往右逐行读取,产生出一个新的字符串,比如:"PAHNAPLSIIGYIR"。
请你实现这个将字符串进行指定行数变换的函数:
string convert(string s, int numRows);
示例 1:
输入: s = "PAYPALISHIRING", numRows = 3
输出:"PAHNAPLSIIGYIR"
示例 2:
输入: s = "PAYPALISHIRING", numRows = 4
输出: "PINALSIGYAHRPI"
解释:
P I N
A L S I G
Y A H R
P I
示例 3:
输入: s = "A", numRows = 1
输出: "A"
我们先需要基于原来的数组进行Z字型变换,然后再将轨迹上的字符提取出来
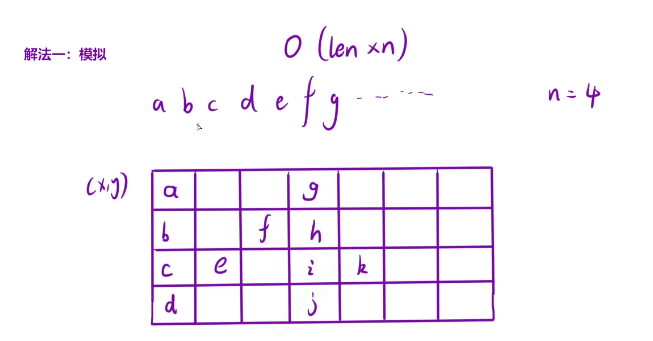
这种解法的时间复杂度太高了,我们需要在当前模拟的基础上进行优化的操作,去找规律
我们这里发现我们第一行的满足条件的字符的区间是6,所以我们就能将第一行的所有满足条件的字符找到
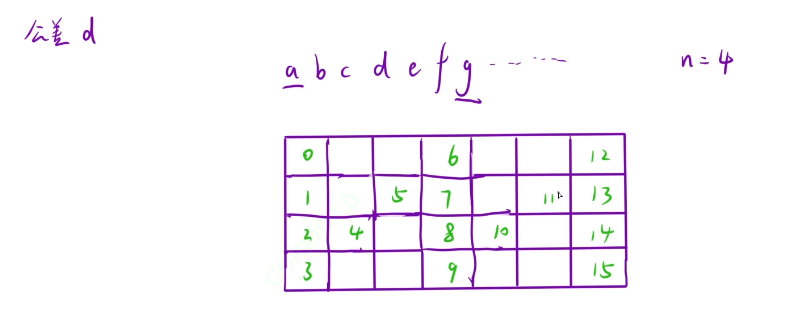
公差的计算就是这先前两列的元素减去两个空格就行了,公式就是2n-2
这里的话第一行和最后一行的元素,我们依次加上公差就能获得我们的符合的元素
对于第k行的话,我们这里以(4,5)进行举例子
k行(k,d-k)->(k+d,d-k+d)->(k+2d,d-k+2d)
我们的1是k,5是这个d-k,然后我们依次进行变化,每次加k个元素
现在我们将这个变成3行再看看我们总结出的这个规则也是符合规则的
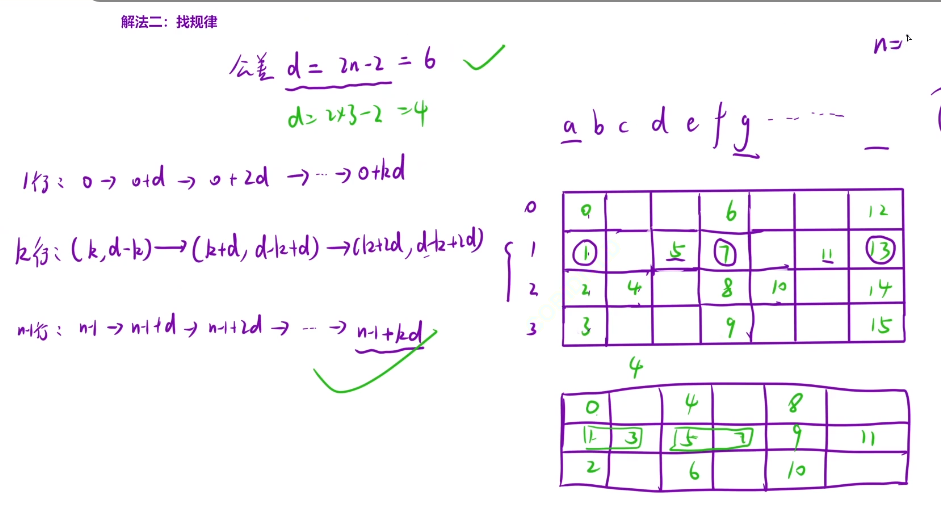
我们当n=1的时候需要进行特殊情况进行处理操作
C++
class Solution
{
public:
string convert(string s, int numRows)
{
//处理边界情况
if(numRows==1) return s;//只有一行的话,我们直接将当前的字符进行返回了
string ret;//记录最终、返回的结果
//我们直接在原本的字符串通过规律进行符合条件的字符的寻找
int d=2*numRows-2,n=s.size();//计算公差的长度
//1.先处理第一行
for(int i=0;i<n;i+=d)
{
//我们这里第一行每次向后面移动是移动d个单位的
ret+=s[i];//直接将对应的放到s[i]里面去
}
//2.处理中间行
for(int k=1;k<numRows-1;k++)//中间行的范围是1~n-2行
{
//我们这里使用或,没有使用并且,因为当我们的i越界了,但是j没有越界,j这个位置的元素需要加到我们的数组中去,所以我们使用||或者
for(int i=k,j=d-k;i<n||j<n;i+=d,j+=d)//我们这一行的第一个元素是从下标k开始的,第二个元素从d-k开始的,i和j每次向后移动d个单位
{
//先添加i位置的元素,再添加j位置的元素,但是我们此时的i可能会存在越界的情况,所以我们在添加之前我们先进行判断是否出现越界的情况
if(i<n)ret+=s[i];//如果i没有越界的话就将当前的元素添加到ret中
if(j<n) ret+=s[j];//j没有越界就将当前的元素添加到元素中去
}
}
//3.处理最后的一行的数据
for(int i=numRows-1;i<n;i+=d)
{
ret+=s[i];
}
return ret;
}
};先将第一行的处理了,然后将中间行的元素处理了,最后将最后一行的元素处理了
我们这里是直接在原先数组的基础上进行改变的,通过找规律找到我们想要的字符
42.外观数列
「外观数列」是一个数位字符串序列,由递归公式定义:
countAndSay(1) = "1"countAndSay(n)是countAndSay(n-1)的行程长度编码。
行程长度编码(RLE)是一种字符串压缩方法,其工作原理是通过将连续相同字符(重复两次或更多次)替换为字符重复次数(运行长度)和字符的串联。例如,要压缩字符串 "3322251" ,我们将 "33" 用 "23" 替换,将 "222" 用 "32" 替换,将 "5" 用 "15" 替换并将 "1" 用 "11" 替换。因此压缩后字符串变为 "23321511"。
给定一个整数 n ,返回 外观数列 的第 n 个元素。
示例 1:
输入: n = 4
输出:"1211"
解释:
countAndSay(1) = "1"
countAndSay(2) = "1" 的行程长度编码 = "11"
countAndSay(3) = "11" 的行程长度编码 = "21"
countAndSay(4) = "21" 的行程长度编码 = "1211"
示例 2:
输入: n = 1
输出:"1"
解释:
这是基本情况。

第一行是一个一
那么我们第二行即是对第一行的解释的
第三行就是对第二行的解释的
第四行就是对第三行的解释的:一个二和一个一
我们在每次解释的时候找到一个相同的部分就解释一下这部分是什么数字组成的
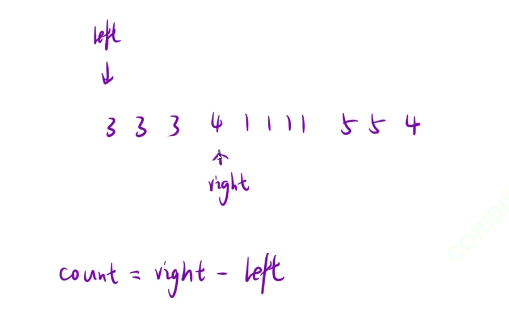
我们的right一直进行向右移动的操作,直到我们遇到不同的数字,我们就进行次数的3出现的次数的统计了
次数就是right-left+1
然后我们让left移动到我们right的位置继续进行遍历判断的操作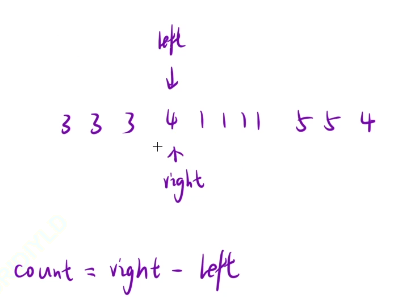
我们这边的算法就是模拟+双指针就可以解决这个问题了
C++
class Solution {
public:
string countAndSay(int n)
{
string ret="1";//因为我们是从第一项开始进行解释的,所以我们将第一项定义为1
//如果n=1的话,我们是直接返回结果的,如果n=2的话,我们翻译一次,n=3的话,我们翻译两次,所以我们下面的for循环进行n-1次就行了
for(int i= 1;i<n;i++)//进行n-1次
{
string tmp;//记录本次翻译的结果
//我们利用双指针进行数组的遍历操作
int len=ret.size();//获取当前ret中需要翻译的字符串的长度,我们的right是不能超过这个len的
for(int left=0,rihgt=0;right<len;)
{
//直到我们碰到不同的数字的话我们就停下来,然后将这一段进行翻译下存到我们的tmp中
while(right<len&&ret[left]==ret[right]) right++;//先保证我们right的范围没有出现越界的情况再进行移动的操作
tmp+=to_string(right-left)+ret[left];//前面的是计算多少个,后面是多少个什么元素
left=right;
}
//当我们循环结束之后我们整个字符串就解释完成了
ret=tmp;
}
return ret;
}
};定义一个ret为1,然后我们从1开始进行翻译操作
如果给到我们的是一个n,那么我们就得循环进行n-1次
在循环中创建一个字符串,进行翻译结果的存储操作
我们利用双指针进行数组遍历的操作,只要我们的right指针不查过我们翻译的字符串ret的长度,我们就持续进行翻译操作
只要是相等的字符的话,我们的right就一直进行右移操作,直到我们遇到不同的字符停下来了,然后我们就将我们先前遍历的那些相同的字符全部翻译到我们的tmp中去,利用to_string将我们这串字符加等到tmp中
然后将我们的left移动到我们的right的位置,结束了内部循环后我们将tmp赋值给ret,然后进行下一轮的内部循环操作
43.数青蛙
给你一个字符串 croakOfFrogs,它表示不同青蛙发出的蛙鸣声(字符串 "croak" )的组合。由于同一时间可以有多只青蛙呱呱作响,所以 croakOfFrogs 中会混合多个 "croak" 。
请你返回模拟字符串中所有蛙鸣所需不同青蛙的最少数目。
要想发出蛙鸣 "croak",青蛙必须 依序 输出 'c', 'r', 'o', 'a', 'k' 这 5 个字母。如果没有输出全部五个字母,那么它就不会发出声音。如果字符串 croakOfFrogs 不是由若干有效的 "croak" 字符混合而成,请返回 -1 。
示例 1:
输入: croakOfFrogs = "croakcroak"
输出: 1
解释: 一只青蛙 "呱呱" 两次
示例 2:
输入: croakOfFrogs = "crcoakroak"
输出: 2
解释: 最少需要两只青蛙,"呱呱" 声用黑体标注
第一只青蛙 "cr coak roak"
第二只青蛙 "crc oakroak"
示例 3:
输入: croakOfFrogs = "croakcrook"
输出: -1
解释: 给出的字符串不是 "croak " 的有效组合。
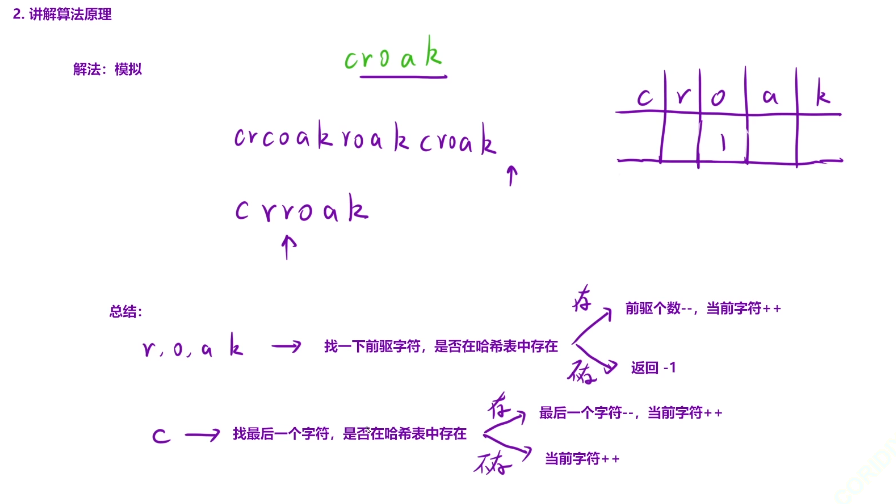
假设我们现在遍历到r这个字符了,那么我们就需要判断我们当前字符前面是否存在c这个字符,如果遍历到了o这个字符的话,那么我们就需要判断我们当前字符的前面是否出现了我们的r这个字符
所以这里我们是需要借助哈希表进行统计的

我们在哈希表中计数,假设我们的数组是上面这样的,我们从c开始统计,c的个数+1,遍历到r,判断r前面是否出现c,我们将1移动到我们的r的位置,然后遍历到c的位置,就说明又出现了一只青蛙,那么我们在c的位置再次加上1,遍历到o,我们判断前面是否出现r,哈希表中出现了,那么我们将r位置上的1移动到o了,然后遍历到a的位置,我们判断前面是否出现o,出现了,我们将o的位置上的1移动到a的位置,那么遍历到k,前面出现了a,那么我们将1移动到k的位置,那么现在我们的1只青蛙就完成了呱叫,但是此时我们的c位置上还有一个数据,就说明还有1只青蛙,我们再次进行相同的步骤,到这里我们的两只青蛙都完成了呱,但是后面还有一个croak,那么此时我们将这两只青蛙其中一只拿去遍历,看看是否能完成呱叫,最少出现了两只青蛙了
并且哈希表中最后只有k的位置不为0,k里面放的是最终的结果,如果前面的字符里面存的是0的话,那么就说明存在错误的叫
在遍历的时候找一下是否存在前驱的字符
roak
C++
class Solution
{
public:
int minNumberOfFrogs(string croakOfFrogs)
{
string t="croak";
int n=t.size();//计算字符串的长度
vector<int >hash(n);//用数组来模拟哈希表
unordered_map<char,int>index;//存的是x字符和x字符对应的下标
for(int i=0;i<n;i++)
{
index[t[i]]=i;//直接将对应的字符下标和字符对应上
}
for(auto ch:croakOfFrogs)
{
//如果我们遍历的到的是c的话,那么我们进行下面的判断操作
if(ch=='c')
{
//想求出最后一个位置在hash中出现的次数
if(hash[n-1]!=0) hash[n-1]--;//我们让这个位置上的数字减一,这个青蛙重新进行呱叫
hash[0]++;
//这里的话就是我们之前已经存在了一只青蛙叫完了,然后我们n-1的位置就是次数,然后呢我们再让其中的一个青蛙再叫一遍,那么就是我们这个n-1的位置的此时-1了,到开头的位置重新遍历了
//不管怎么样,我们的hash[0]都得进行加加的操作
}
else//遇到的是其他的字符
{
int i=index[ch];//ch是当前的字符,index[ch]就是当前字符的下标
//那么我们仅仅需要判断我们当前字符的前驱字符是否存在
if(hash[i-1]==0) return -1;//前驱字符不存在的话,就说明没有青蛙叫
//到这里的话,就说明我们的前驱是存在的
hash[i-1]--;hash[i]++;//那么我们让前驱字符的出现数字的1移动到我们的当前数字的位置上
}
}
//整个for循环结束之后,我们需要判断我们的0~n-2的区间是否存在数字,一定要都是0才表示我们的青蛙叫完了
for(int i=0;i<n-1;i++)
{
if(hash[i]!=0) return -1;//说明我们的青蛙还没叫完,或者是异常的叫
}
return hash[n-1];//否则的话我们直接返回的是最后一个符号里面存的数字,这个数字就是我们最少的青蛙个数
}
};两个hash表,一个存的是我们的对应字符出现的次数,一个存的是我们字符对应的下标
第一个循环我们将我们字符对应的下标存在我们的hash中去,第二个循环我们就开始进行遍历数组了
我们先判断我们当前的字符是否是是c,如果是c的话,那么我们判断下我们最后一个字符出现的次数,如果最后一个字符出现的字符是0 的话,那么就说明这个青蛙刚开始叫的,如果最后一个字符不是0的话,那么就说明我们这只青蛙已经开始叫第二声呱了,重新叫
如果最后一个字符存在数据的话,那么我们让最后一个字符对应的数据-1,然后让我们的开始位置的元素的次数进行加加的操作,在这个条件判断中不管怎么样我们都是需要进行hash0++的操作
如果遇到的是其他的字符的话,那么我们就得判断我们当前字符前面的那个字符是否存在,我们获取当前字符的下标,然后我们利用这个判断我们的当前字符的前一个字符出现的次数是否为0,如果没有出现为0的话,那么就说名这个字符串是错误的,我们直接return -1就行了
如果存在的话,那么我们让前一个字符的次数移动到我们当前字符的次数
整个循环结束后,我们还需与判断、我们的0~n-2的区间是否存在数字,一定要都是0才表示我们的青蛙叫完了,如果其他的字符还存在次数的话,那么就说明青蛙没叫完,或者是字符串异常的问题,我们直接返回-1就行了
循环结束我们直接返回最后一个字符出现的次数,这个就是我们最小的青蛙次数