一、配置kafka
首先进到software目录当中,如下图所示:
安装包上传/解压/重命名/解压过后的目录如下图所示:
修改配置:
· cd config
· v i server.properties
全部修改语句如下所示(以node01为样例):
|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| broker.id=0 从0 开始 ,0 1 2 delete.topic.enable=true //这条在文件中没有,手动添加,默认主题不允许删除 listeners=PLAINTEXT://node01:9092 log.dirs=/root/kafkadata // 数据存放的目录,会自动生成,不需要创建 num.partitions=3 zookeeper.connect=node01:2181,node02:2181,node03:2181 |
返回到software目录里面:
分发kafka的安装包,到其他的节点中:
|---------------------------------------------------|
| scp -r kafka node02:PWD scp -r kafka node03:PWD |
在其他的节点上,修改broker.id 和 listeners中的主机名。
启动kafka集群
启动脚本和停止脚本命令。
以后台守护进程启动:
kafka-server-start.sh -daemon /opt/software/kafka/config/server.properties
注意: 在启动kafka之前,必须先启动zookeeper。
bin/zkServer.sh start
Kafka.sh:一键启动和关闭kafka集群。
①添加一个kafka环境变量


②node02、node03也进行相同的配置
③进入到当前目录并把kafka.sh也上传进来
④修改一下权限,让它变成绿色的可执行脚本文件
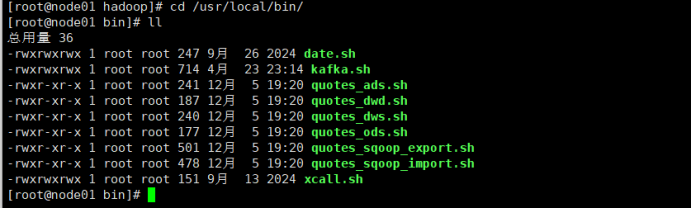
⑤路径和主机名称修改为和自己一致的
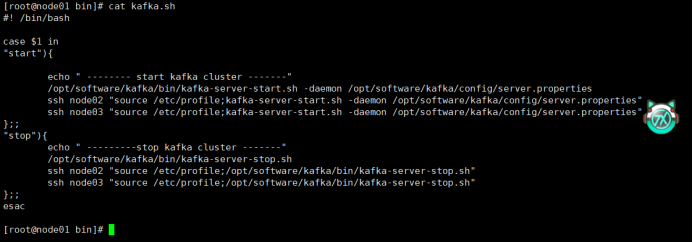
⑥试一下一键启动

安装部署Spark
解压缩文件,并重命名为spark-yarn。
tar zxvf spark-3.0.0-bin-hadoop3.2.tgz
mv spark-3.0.0-bin-hadoop3.2 spark-yarn

- 修改配置文件
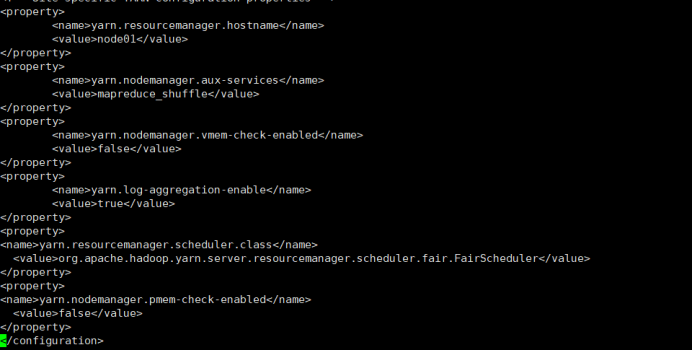
1)修改hadoop配置文件/opt/software/hadoop/hadoop-2.9.2/etc/hadoop/yarn-site.xml,并分发给其他节点。
是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是 true
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是 true
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
2)返回到spark-yarn目录,修改conf/spark-env.sh,添加 JAVA_HOME 和 YARN_CONF_DIR 配置。
mv spark-env.sh.template spark-env.sh
v i spark-env.sh

3)启动HDFS以及Yarn集群
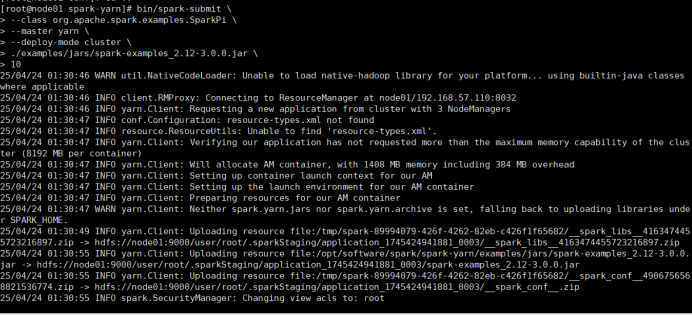
4)提交测试应用
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
./examples/jars/spark-examples_2.12-3.0.0.jar \
1 0
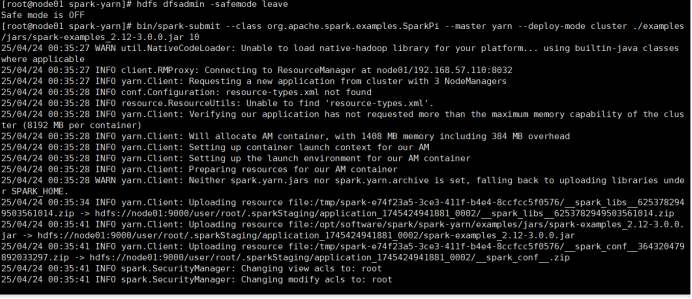
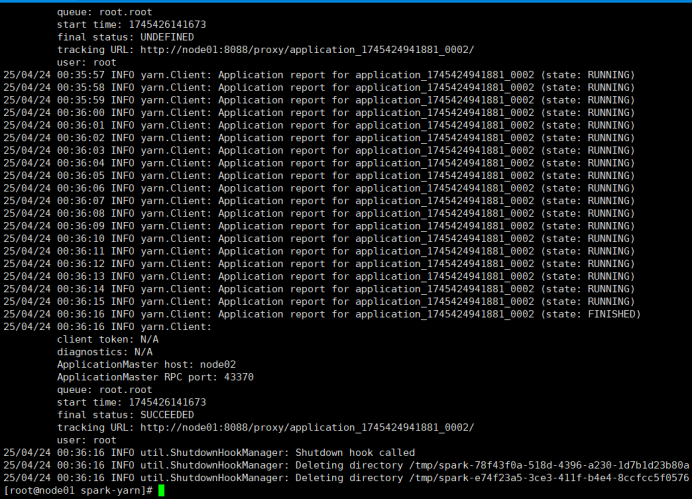
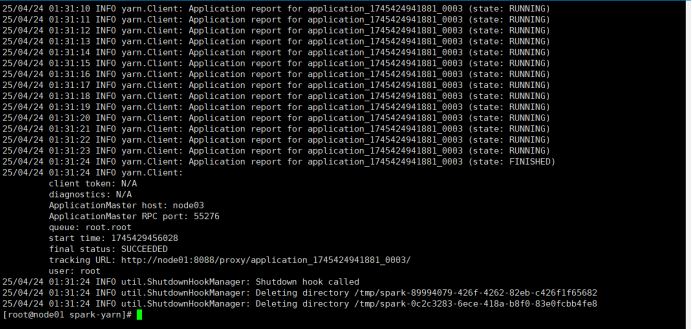
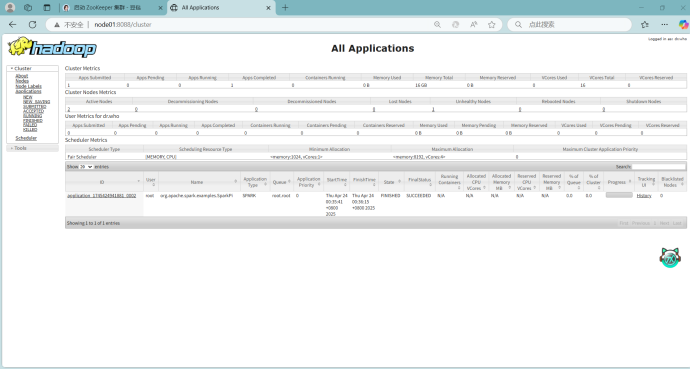
查看node01:8088页面
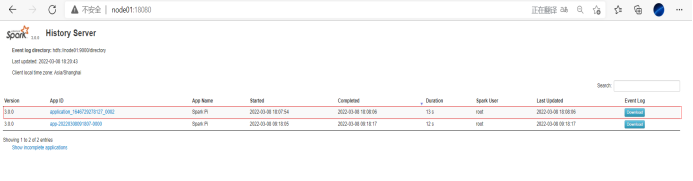
配置历史服务
由于 spark-shell 停止掉后,集群监控 node01:4040 页面就看不到历史任务的运行情况,所以 开发时都配置历史服务器记录任务运行情况。
1)修改 spark-defaults.conf.template 文件名为 spark-defaults.conf
mv spark-defaults.conf.template spark-defaults.conf
2)修改 spark-default.conf 文件,配置日志存储路径
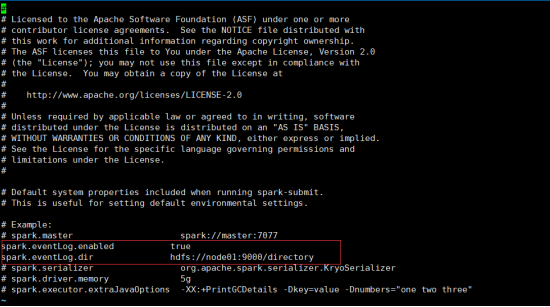
注意: 需要启动 hadoop 集群,HDFS 上的 directory 目录需要提前存在。
h d fs dfs -mkdir /directory
3)修改 spark-env.sh 文件, 添加日志配置
export SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=18080
-Dspark.history.fs.logDirectory=hdfs://node01:9000/directory
-Dspark.history.retainedApplications=30"
4)开启历史服务,并且重新提交应用
sbin /start-history-server.sh
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
./examples/jars/spark-examples_2.12-3.0.0.jar \
10