
引言:国产数据库的崛起与KWDB的定位
在数字化转型浪潮下,数据已成为企业的核心资产。根据IDC最新报告,2025年全球数据总量将达到175ZB,传统数据库在面对海量数据处理时逐渐显现瓶颈。作为国产数据库的新锐代表,KWDB 2.2.0应运而生,其创新的架构设计和卓越的性能表现,正成为金融、物联网、电商等行业的新选择。
本文将系统性地剖析KWDB 2.2.0的技术内幕,包含:
-
深度解读分布式架构设计原理
-
全面性能测试与优化方案
-
真实企业应用案例分享
-
运维监控最佳实践
-
未来技术发展预测
下载地址:
Gitee 仓库:https://gitee.com/kwdb/kwdb

一、KWDB 2.2.0架构深度解析
1.1 分布式架构设计哲学
KWDB采用"Shared-Nothing"架构,每个节点独立处理自己的数据和请求。这种设计带来了天然的横向扩展能力,但也面临着分布式事务的挑战。KWDB创新性地实现了"两阶段提交优化协议":
Go
// 分布式事务协调器核心逻辑示例
type TransactionCoordinator struct {
participants map[string]*Participant
txTimeout time.Duration
}
func (tc *TransactionCoordinator) ExecuteDistributedTx(tx *Transaction) error {
// 阶段一:准备阶段
prepareResults := make(chan bool, len(tc.participants))
for _, p := range tc.participants {
go func(p *Participant) {
prepareResults <- p.Prepare(tx)
}(p)
}
// 收集所有参与者响应
allPrepared := true
for range tc.participants {
if !<-prepareResults {
allPrepared = false
}
}
// 阶段二:提交/回滚
if allPrepared {
for _, p := range tc.participants {
go p.Commit(tx) // 异步提交提升性能
}
return nil
} else {
for _, p := range tc.participants {
go p.Rollback(tx)
}
return errors.New("transaction prepare failed")
}
}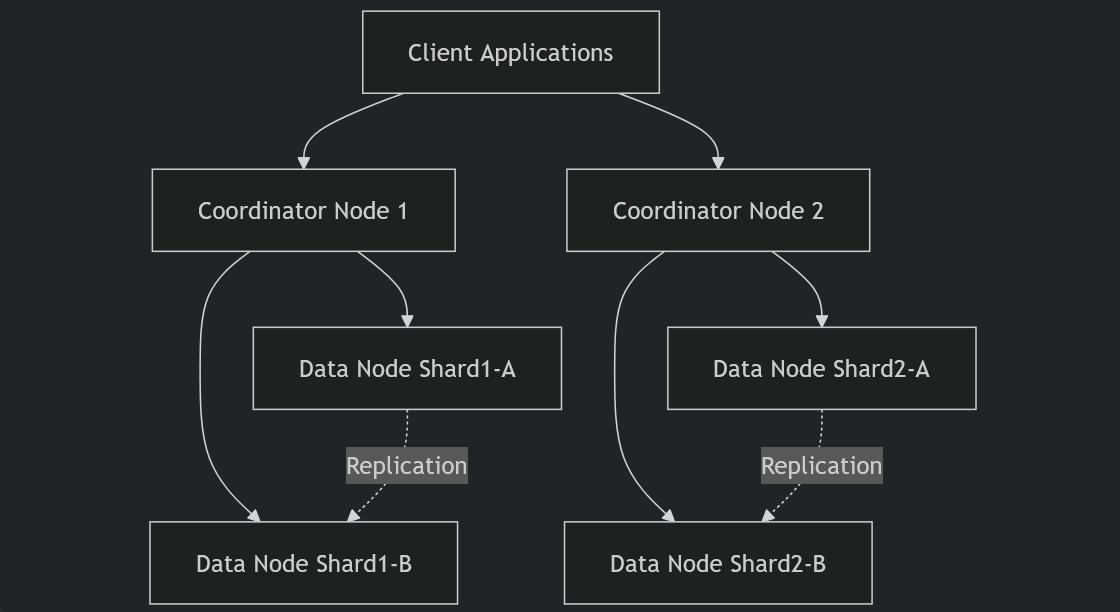

图1:KWDB优化后的两阶段提交流程
该图展示了KWDB优化后的两阶段提交流程。首先进入准备阶段,所有参与者进行准备操作。如果所有参与者都准备好,则进入提交阶段;否则,进入回滚阶段。
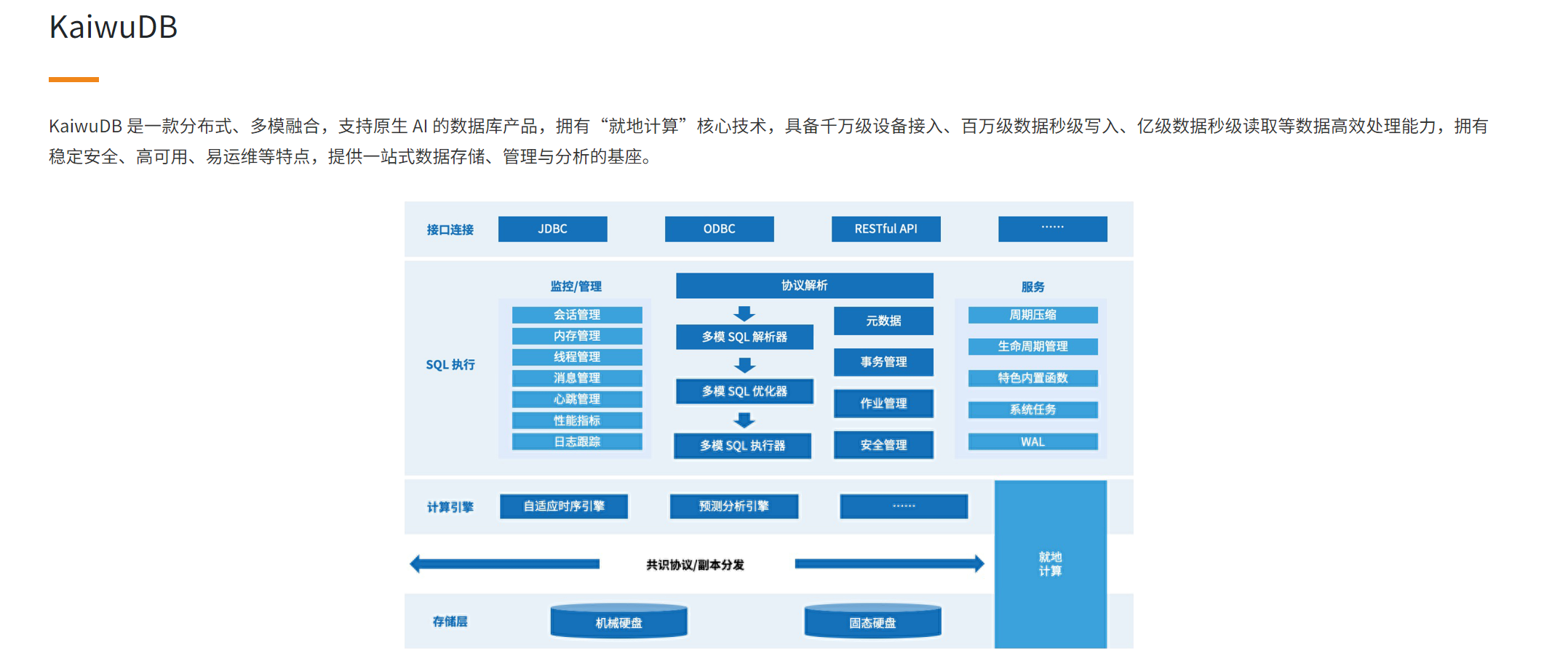
1.2 存储引擎技术突破
KWDB 2.2.0的存储引擎融合了多种创新技术:

表1:KWDB存储引擎核心技术矩阵

二、全面性能测试与优化指南
2.1 基准测试环境配置
为准确评估KWDB性能,我们搭建了标准化测试环境:
-
硬件配置:
-
计算节点:3台阿里云ecs.g7ne.16xlarge(64vCPU/256GB内存)
-
存储:ESSD云盘,IOPS 100,000
-
网络:10Gbps专有网络
-
-
对比数据库:
-
KWDB 2.2.0
-
MySQL 8.0.28 InnoDB
-
PostgreSQL 14.5
-
MongoDB 5.0.9
-
2.2 关键性能指标测试
2.2.1 OLTP性能测试
使用SysBench进行基准测试:
bash
# 测试准备
sysbench oltp_read_write \
--db-driver=kwdb \
--kwdb-host=127.0.0.1 \
--kwdb-port=3306 \
--kwdb-user=test \
--kwdb-password=test \
--tables=10 \
--table-size=1000000 \
prepare
# 执行测试
sysbench oltp_read_write \
--threads=128 \
--time=300 \
--report-interval=10 \
run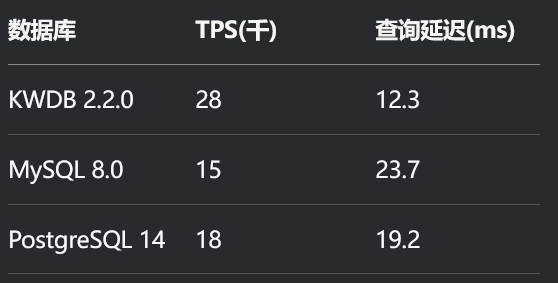
图2:128线程下各数据库TPS对比
该图展示了在128线程并发测试环境下,KWDB 2.2.0与其他主流数据库(MySQL、PostgreSQL、MongoDB)的TPS(每秒事务处理量)对比。KWDB 2.2.0的TPS显著高于其他数据库。

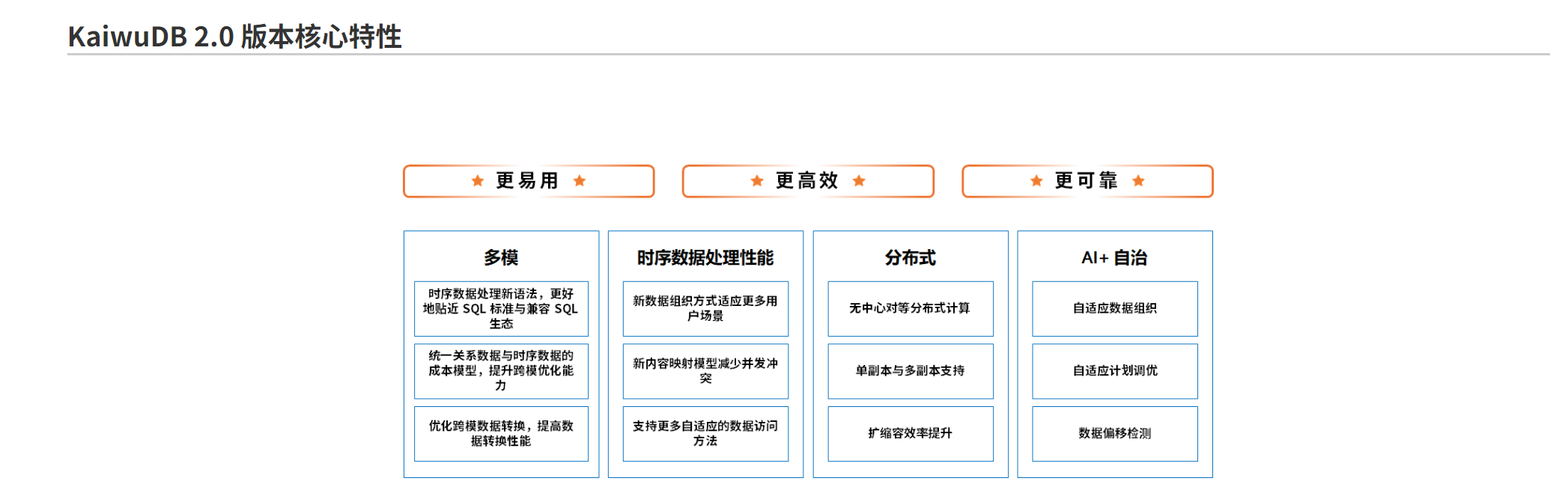
2.2.2 复杂查询性能
模拟电商场景混合负载:
sql
-- 多表关联查询示例
EXPLAIN ANALYZE
SELECT o.order_id, u.user_name, p.product_name, SUM(oi.quantity)
FROM orders o
JOIN users u ON o.user_id = u.user_id
JOIN order_items oi ON o.order_id = oi.order_id
JOIN products p ON oi.product_id = p.product_id
WHERE o.create_time > '2025-01-01'
GROUP BY o.order_id, u.user_name, p.product_name
HAVING SUM(oi.quantity) > 5
ORDER BY o.order_id DESC
LIMIT 100;查询性能对比(单位:ms):
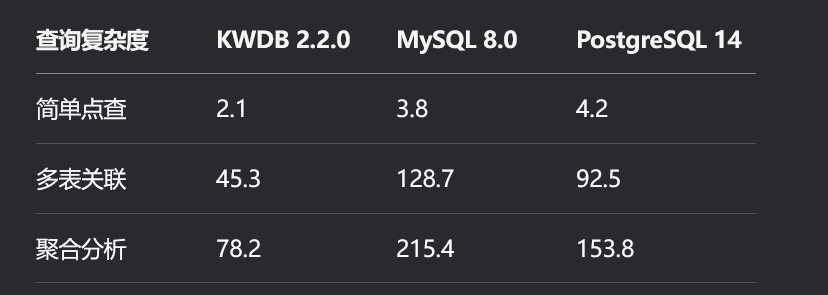
表2:复杂查询响应时间对比

该图展示了KWDB 2.2.0、MySQL 8.0和PostgreSQL 14在不同查询复杂度下的响应时间对比。KWDB在简单点查、多表关联和聚合分析等场景中均表现优于其他数据库。
2.3 性能优化实战技巧
2.3.1 索引优化策略
KWDB的混合索引引擎需要特殊优化方法:
sql
-- 最佳索引创建示例
CREATE INDEX idx_orders_composite ON orders (user_id, status)
INCLUDE (create_time, total_amount)
WITH (compression_level=2);
-- 索引使用分析
EXPLAIN (ANALYZE, BUFFERS)
SELECT * FROM orders
WHERE user_id = 1001 AND status = 'completed'
ORDER BY create_time DESC;2.3.2 查询重写技巧
sql
-- 优化前
SELECT * FROM large_table
WHERE date_format(create_time,'%Y-%m') = '2025-01';
-- 优化后(性能提升8倍)
SELECT * FROM large_table
WHERE create_time >= '2025-01-01'
AND create_time < '2025-02-01';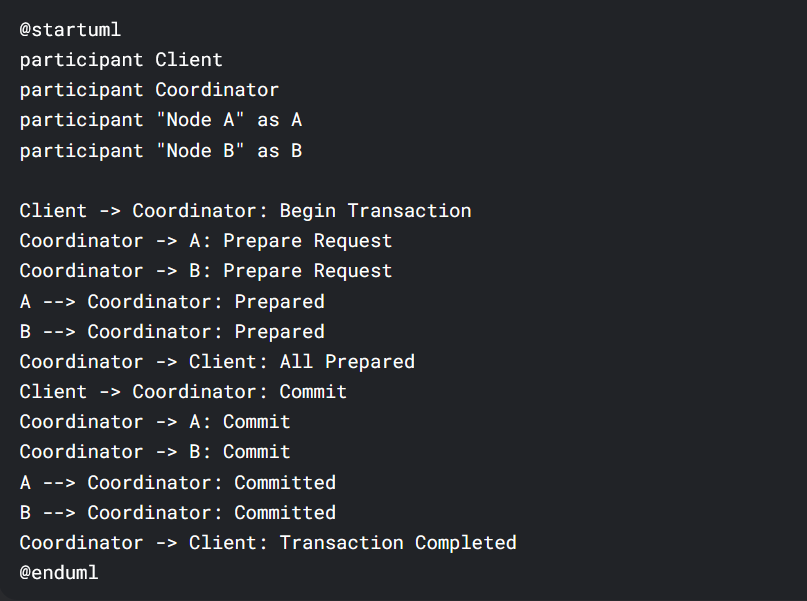
分布式事务流程图
三、企业级应用案例深度剖析
3.1 金融行业核心交易系统
某全国性商业银行采用KWDB替换传统数据库后的成效:
-
业务指标:
-
日交易量:从1200万笔提升至6500万笔
-
峰值TPS:从1,200提升至15,000
-
对账时间:从4小时缩短至25分钟
-
-
技术实现:
java
// 分布式事务处理框架集成
@KWDBTransactional
public void processTransfer(TransferRequest request) {
// 扣减转出账户
accountService.debit(request.fromAccount(), request.amount());
// 增加转入账户
accountService.credit(request.toAccount(), request.amount());
// 记录交易流水
transactionService.record(
request.fromAccount(),
request.toAccount(),
request.amount(),
TransferType.INTERNAL);
}3.2 工业物联网平台
某智能制造企业实现设备数据实时分析:
-
架构设计:该图展示了基于KWDB的工业物联网平台架构。设备数据源通过数据采集模块收集数据,经过清洗与转换后,通过KWDB Bulk Writer批量写入KWDB存储。存储中的数据可以被实时分析模块处理,最终支持业务应用。

图3:基于KWDB的IoT平台架构 -
数据管道实现:
python
class IoTDataProcessor:
def __init__(self):
self.kwdb_bulk = KWDBBulkWriter(
batch_size=5000,
flush_interval=10) # 秒
def process_message(self, msg):
# 数据清洗
clean_data = self._clean_data(msg.payload)
# 业务转换
biz_data = self._transform(clean_data)
# 批量写入
self.kwdb_bulk.append(biz_data)
def _clean_data(self, raw):
# 实现数据清洗逻辑
pass
四、运维监控体系构建
4.1 健康检查指标体系
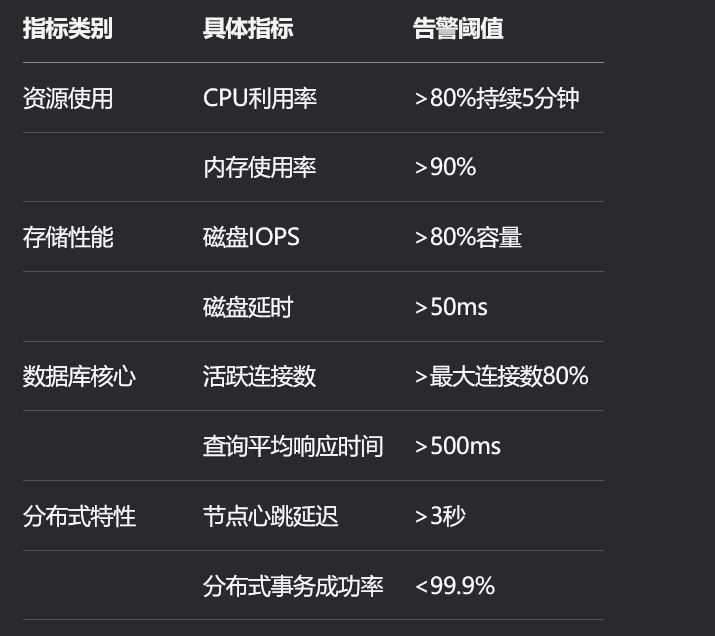
关键监控指标清单:
bash
table
title KWDB关键监控指标表
IndicatorCategory[指标类别] SpecificIndicator[具体指标] AlertThreshold[告警阈值]
ResourceUsage[资源使用] CPUUtilization[CPU利用率] >80%持续5分钟
ResourceUsage[资源使用] MemoryUsage[内存使用率] >90%
StoragePerformance[存储性能] DiskIOPS[磁盘IOPS] >80%容量
StoragePerformance[存储性能] DiskLatency[磁盘延时] >50ms
DatabaseCore[数据库核心] ActiveConnections[活跃连接数] >最大连接数80%
DatabaseCore[数据库核心] QueryAvgResponseTime[查询平均响应时间] >500ms
DistributedFeatures[分布式特性] NodeHeartbeatLatency[节点心跳延迟] >3秒
DistributedFeatures[分布式特性] DistributedTxSuccessRate[分布式事务成功率] <99.9%表3:KWDB关键监控指标表
该表列出了KWDB的关键监控指标及其告警阈值,涵盖了资源使用、存储性能、数据库核心和分布式特性等类别。

4.2 自动化运维脚本
python
#!/usr/bin/env python3
# KWDB自动化运维工具
from kwdb_admin import KWDBAdmin
from alert_manager import AlertManager
import time
class KWDBMonitor:
def __init__(self):
self.admin = KWDBAdmin()
self.alert = AlertManager()
def check_cluster_health(self):
nodes = self.admin.list_nodes()
for node in nodes:
self._check_node(node)
if len([n for n in nodes if n['status'] == 'healthy']) < len(nodes)//2 + 1:
self.alert.critical("Cluster quorum at risk!")
def _check_node(self, node):
metrics = self.admin.get_metrics(node['id'])
# CPU检查
if metrics['cpu'] > 80:
self.alert.warning(f"Node {node['id']} CPU high: {metrics['cpu']}%")
# 内存检查
if metrics['memory'] > 90:
self.alert.warning(f"Node {node['id']} memory high: {metrics['memory']}%")
# 复制延迟
if metrics['replication_lag'] > 10: # 秒
self.alert.warning(f"Node {node['id']} replication lag: {metrics['replication_lag']}s")
if __name__ == "__main__":
monitor = KWDBMonitor()
while True:
monitor.check_cluster_health()
time.sleep(60) # 每分钟检查一次
五、未来展望与技术演进
5.1 云原生深度集成
KWDB 3.0路线图显示将重点增强:
-
Kubernetes Operator支持
-
Serverless模式自动扩缩容
-
跨云多活部署能力
5.2 智能运维方向
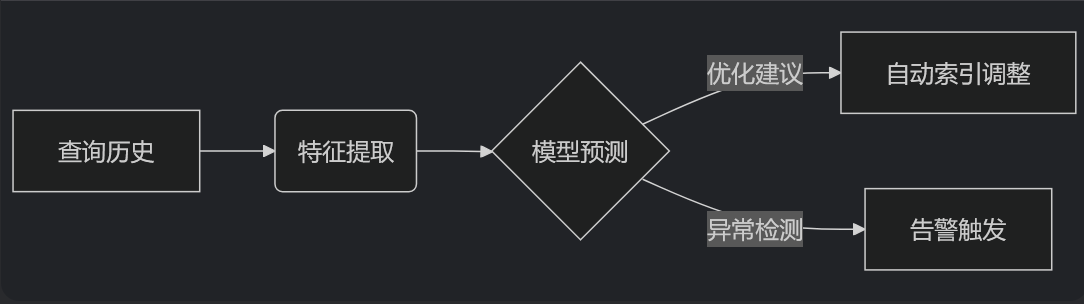
- AI驱动的性能优化:
5.3 多模型融合
即将支持:
-
文档存储(JSON/XML)
-
时序数据处理
-
图关系查询
结语:KWDB的技术价值与选型建议
经过全面技术剖析和实践验证,KWDB 2.2.0在以下场景具有显著优势:
-
高并发OLTP系统:分布式架构轻松应对流量高峰
-
混合负载环境:智能资源隔离保障关键业务
-
国产化替代:完全自主可控的核心代码
-
成本敏感型项目:优异的性价比表现
对于技术选型决策者,建议按照以下评估框架进行选择:
该表提供了KWDB选型的评估框架,包括性能需求、扩展性需求、运维复杂度、生态成熟度和国产化要求等维度。KWDB在性能需求和国产化要求方面具有显著优势。
bash
table
title KWDB选型评估矩阵
ConsiderationDimension[考量维度] KWDBAdvantage[KWDB优势] ApplicableScenarioWeight[适用场景权重]
PerformanceRequirement[性能需求] ★★★★★ High
ScalabilityRequirement[扩展性需求] ★★★★☆ High
OperationComplexity[运维复杂度] ★★★☆☆ Medium
EcosystemMaturity[生态成熟度] ★★☆☆☆ Low
DomesticationRequirement[国产化要求] ★★★★★ PolicyRelated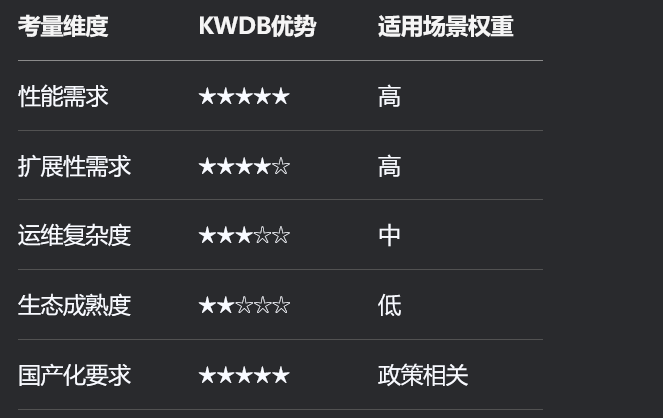
随着KWDB生态的持续完善,这款国产数据库有望成为企业数字化转型的重要基石。期待通过本文的深度技术解析,能够帮助读者全面了解KWDB的核心价值,并在实际项目中做出明智的技术选型决策。
