文章目录
hadoop完全分布式部署
hdfs-site.xml
bash
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/src/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/src/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</property>
<!-- Secondary NameNode 所在主机的ip和端口 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master02:9890</value>
</property>
</configuration>core-site.xml
bash
<configuration>
<!-- -->
<!-- 设置hadoop的文件系统,由URI指定 -->
<property>
<!-- 指定namenode地址节点所在机器 -->
<name>fs.defaultFS</name>
<value>hdfs://master01:9000</value>
</property>
<!-- 配置hadoop临时目录,默认/tmp/hadoop-${user.name} -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/src/hadoop/tmp/</value>
</property>
</configuration>marpred-site.xml
bash
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master01:10020</value>
</property>
</configuration>yarn-site.xml
bash
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master01:10020</value>
</property>
</configuration>spark集群部署
spark-env.sh
bash
export JAVA_HOME=/usr/local/src/jdk1.8.0_152
export HADOOP_CONF_DIR=/usr/local/src/hadoop-3.2.2/etc/hadoop/
export SPARK_MASTER_IP=master01
export SPARK_MASTER_PORT=7077
export SPARK_WORKER_MEMORY=512m
export SPARK_WORKER_CORES=1
export SPARK_EXECUTOR_MEMORY=512m
export SPARK_EXECUTOR_CORES=1
export SPARK_WORKER_INSTANCES=1mongodb分片模式部署
| 服务器名称 | IP地址 | Shard1 (端口/角色) | Shard2 (端口/角色) | Shard3 (端口/角色) | mongos (端口) | Config Server (端口/角色) |
|---|---|---|---|---|---|---|
| master01 | 192.168.121.134 | 27018 (主节点) | 27020 (仲裁节点) | 27019 (副节点) | 27021 | 27022 (主节点) |
| node01 | 192.168.121.135 | 27019 (副节点) | 27018 (主节点) | 27020 (仲裁节点) | 27021 | 27022 (副节点) |
| node02 | 192.168.121.136 | 27020 (仲裁节点) | 27019 (副节点) | 27018 (主节点) | - | 27022 (副节点) |
config 服务器
bash
dbpath=/usr/local/src/mongodb_demo/shardcluster/configServer/data
logpath=/usr/local/src/mongodb_demo/shardcluster/configServer/logs/config_server.log
port=27022
bind_ip=master01
logappend=true
fork=trues
maxConns=5000
replSet=configs
configsvr=true初始化config 副本集
bash
$ ./mongod -f /usr/local/src/mongodb_demo/shardcluster/configServer/configFile/mongodb_config.conf
$ ./mongo --host master01 --port 27022
> rs.initiate()
configs:SECONDARY> rs.add('node01:27022')
configs:PRIMARY> rs.add('node02:27022')shard 服务器
bash
dbpath=/usr/local/src/mongodb_demo/shardcluster/shard/shard1_data
logpath=/usr/local/src/mongodb_demo/shardcluster/shard/logs/shard1.log
port=27018
bind_ip=master01
logappend=true
fork=true
maxConns=5000
replSet=shard1
shardsvr=true类似地,编辑 shard2.conf 和 shard3.conf,分别修改 dbpath, logpath, port, bind_ip, 和 replSet 参数。
初始化shard 副本集
bash
# 所有节点都启动
$ ./mongod -f /usr/local/src/mongodb_demo/shardcluster/shard/configFile/mongodb_shard1.conf
$ ./mongod -f /usr/local/src/mongodb_demo/shardcluster/shard/configFile/mongodb_shard2.conf
$ ./mongod -f /usr/local/src/mongodb_demo/shardcluster/shard/configFile/mongodb_shard3.conf
# master01节点
$ ./mongo --host master01 --port 27018
> rs.initiate()
configs:SECONDARY> rs.add('node01:27019')
configs:PRIMARY> rs.add('node02:27020')
# node01节点
$ ./mongo --host node01--port 27018
> rs.initiate()
configs:SECONDARY> rs.add('node02:27019')
configs:PRIMARY> rs.add('master01 :27020')
# node02节点
$ ./mongo --host node02 --port 27018
> rs.initiate()
configs:SECONDARY> rs.add('master01 :27019')
configs:PRIMARY> rs.add('node01:27020')mongos服务器
bash
logpath=/usr/local/src/mongodb_demo/shardcluster/mongos/logs/mongos.log
logappend=true
port=27021
bind_ip=master01
fork=true
configdb=configs/master01:27022,node01:27022,node02:27022
maxConns=20000类似地,在node01节点配置
添加shard
bash
$ ./mongo --host master01--port 27021
mongos> use gateway
mongos> sh.addShard("shard1/master01:27018,node01:27019,node02:27020")
mongos> sh.addShard("shard2/master01:27020,node01:27018,node02:27019")
mongos> sh.addShard("shard3/master01:27019,node01:27020,node02:27018")设置chunk大小
bash
use config;
db.settings.insertOne({ _id: "chunksize", value: 64 });启动分片
bash
mongos> use gateway
mongos> sh.enableSharding("xxxdatabase")为集合 user 创建索引并进行分片
bash
mongos> use xxxdatabase
mongos> db.user.createIndex({"id":1})
mongos> sh.shardCollection("xxxdatabase.xxxcollection",{"id":1})fillder抓包+数据采集
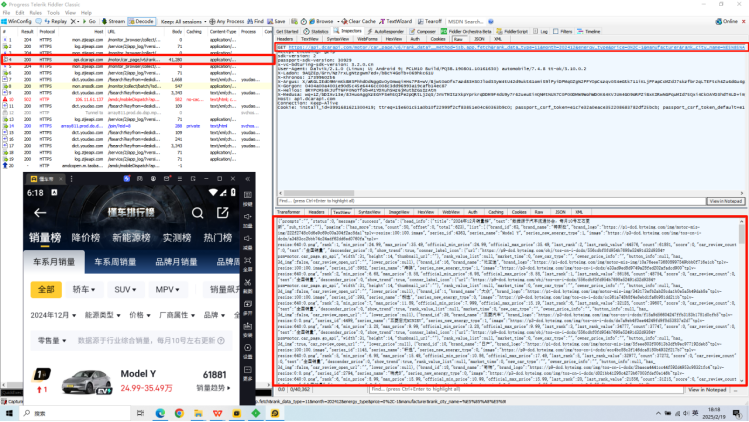
python
def data_SalesVolume(self,allcity):
'''
获取全国和各城市车辆销售量排名
数据结果存储到本地和hdfs
:param allcity: 城市名称-->list
:return:
'''
data_list = []
for city in allcity:
city_quote = quote(city)
newurl = self.url+f'method=jsb.app.fetch&rank_data_type=116&month=202412&energy_type&price=0%2C-1&manufacturer&rank_city_name={city_quote}&market_time=0&offset=0&count=500&scm_version=1.0.0.2209&iid=3991681621300419&device_id=3991681621296323&ac=wifi&channel=home&aid=36&app_name=automobile&version_code=748&version_name=7.4.8&device_platform=android&os=android&ab_client=a1%2Cc2%2Ce1%2Cf2%2Cg2%2Cf7&ab_group=3167590%2C3577236&ssmix=a&device_type=PCLM10&device_brand=OPPO&language=zh&os_api=28&os_version=9&manifest_version_code=748&resolution=720*1280&dpi=320&update_version_code=7483&_rticket=1738335686380&cdid=637e94d4-1e98-49a9-9b9e-7f567951c149&rom_version=coloros__pq3b.190801.10161630+release-keys&longi_lati_type=0&longi_lati_time=0&content_sort_mode=0&total_memory=3.85&cpu_name=Qualcomm+Technologies%2C+Inc+MSM8998&overall_score=8.6995&cpu_score=7.9848&host_abi=armeabi-v7a'
print(f'准备获取=={city}==的数据---{newurl}---')
citynames = self.session.get(url=newurl, headers=self.headers).json()
city_sales = {city:citynames}
data_list.append(city_sales)
# print(citynames)
print('----------获取销量数据完成-----------')
data_json = {'SalesValue':data_list}
with open(f'data/data_salesvolume.json','w',encoding='utf-8') as f:
json.dump(data_json,f,ensure_ascii=False,indent=4)
hdfs_path = "/data_doncar/data_carkm.json" # HDFS 目标路径
self.hdfs_client.create(hdfs_path, data_json, overwrite=True) # 上传到 HDFSspark清洗数据
创建对象
scala
package org.example
import org.apache.log4j.{Level, Logger}
import org.apache.spark._
import org.apache.spark.sql.{DataFrame, SparkSession}
import org.apache.spark.sql.functions._
object DonCar_spark {
def main(args: Array[String]): Unit = {
Logger.getLogger("org").setLevel(Level.ERROR)
Logger.getLogger("akka").setLevel(Level.ERROR)
val spark = SparkSession.builder()
.appName("car_analysis")
.master("local[*]")
.config("spark.mongodb.read.connection.uri", "mongodb://root:123456@192.168.121.134:27017")
.getOrCreate()连接mongodb数据库
scala
def readmongocollection(db:String,collection:String) = {
spark.read
.format("mongodb")
.option("database",db)
.option("collection",collection)
.load()
}创建临时表
scala
val car_info = readmongocollection("doncar_top","car_info")
val citys_sv = readmongocollection("doncar_top","citys_sv")
val nationwide_sv = readmongocollection("doncar_top","nationwide_sv")
citys_sv.createOrReplaceTempView("citys_table")
car_info.createOrReplaceTempView("car_table")
nationwide_sv.createOrReplaceTempView("nationwide_table")数据分析 并且把数据存到HDFS
scala
// 各城市汽车销量
val citys_sales = spark.sql("select city,sales from citys_table")
.groupBy("city").sum("sales")
// 电车续航排名
val brand_max_km = spark.sql("select brand,range_km from car_table").groupBy("brand").max()
brand_max_km.limit(7).show()
// 油电销量
val car_type_sales =spark.sql("select sales,car_type from nationwide_table ")
.withColumn(
"category",
when(col("car_type") === 0,0)
.otherwise(1)
)
.groupBy("category")
.sum("sales")
car_type_sales.show()
// 能源占比
// 0 纯油
// 1 纯电
// 2 混动
// 3-4 增程
val car_type = spark.sql("select car_type,sales from nationwide_table")
.groupBy("car_type")
.sum("sales")
// car_type.printSchema()
val car_type2 = car_type.withColumn(
"sum(sales)",
when(col("car_type") === 3,col("sum(sales)")+car_type.filter(col("car_type") === 4).select("sum(sales)").first().getLong(0))
.otherwise(col("sum(sales)"))
)
car_type2.show()
//销量------价格关系
val price_sales = spark.sql("SELECT min_price,max_price,sales from nationwide_table")
.withColumn(
"average_price",
(col("min_price") + col("max_price")) / 2
)
.drop("min_price","max_price")
price_sales.show()
// 品牌销量
val brand_sales = spark.sql("SELECT brand_name,model,sales FROM nationwide_table")
.groupBy("brand_name")
.sum("sales")
.sort(col("sum(sales)").desc)
brand_sales.show()
// 城市销量排名
val city_top = citys_sales.sort(col("sum(sales)").desc)
city_top.show()
// 车辆销售排名
val car_top = spark.sql("SELECT model,sales FROM nationwide_table")
.sort(col("sales").desc)
car_top.show()
}
}
Flask+echarts进行可视化
python
from flask import Flask, render_template, redirect, url_for, request, flash, session,jsonify
from SparkAnalysis import analysis
from SparkAnalysis import Get_HdfsData
import pymysql
app = Flask(__name__)
#重定向路由
@app.route('/')
def default():
return redirect(url_for('login'))
@app.route('/login', methods=['GET', 'POST'])
def login():
if request.method == 'POST':
username = request.form['username']
password = request.form['password']
conn = pymysql.connect(
host='localhost', # 数据库主机地址
user='root', # 数据库用户名
password='123456', # 数据库密码
database='users' # 数据库名称
)
with conn.cursor() as cursor:
cursor.execute("SELECT * FROM account WHERE username = %s AND password = %s", (username, password))
account = cursor.fetchone() # 获取第一行记录
conn.close()
if account:
return redirect(url_for('index'))
else:
return redirect(url_for('login'))
return render_template('login.html')
@app.route('/register', methods=['GET', 'POST'])
def register():
if request.method == 'POST':
username = request.form['username']
password = request.form['password']
conn = pymysql.connect(
host='localhost',
user='root',
password='123456',
database='users'
)
with conn.cursor() as cursor:
cursor.execute("SELECT * FROM account WHERE username = %s", (username,))
if cursor.fetchone():
return redirect(url_for('register'))
# 如果用户名不存在,插入新用户
cursor.execute("INSERT INTO account (username, password) VALUES (%s, %s)", (username, password))
conn.commit()
conn.close()
return redirect(url_for('login'))
return render_template('register.html')
@app.route('/index')
def index():
return render_template('index.html',
map_data=Get_HdfsData.get_map_data(),
bar1_x = analysis.get_bar1_data()['brand'].values.tolist(),
# bar1_y=Get_HdfsData.get_bar1_data()['range_km'].values.tolist(),
bar1_y=[float(num) for num in analysis.get_bar1_data()['range_km'].values.tolist()],
type_0 = Get_HdfsData.get_num_data()[0][2:],type_n0 = Get_HdfsData.get_num_data()[1][2:],
pie_data = Get_HdfsData.get_pie_data(),
scatter_data = Get_HdfsData.get_scatter_data(),
bar2_x=analysis.get_bar2_data()['brand_name'].values.tolist()[:5],
bar2_y=analysis.get_bar2_data()['sales'].values.tolist()[:5],
line1_x_top=Get_HdfsData.get_line1_data()['city'].values.tolist()[:12],
line1_y_top=Get_HdfsData.get_line1_data()['value'].values.tolist()[:12],
line1_x_last=analysis.get_line1_data()['city'].values.tolist()[-12:],
line1_y_last=analysis.get_line1_data()['value'].values.tolist()[-12:],
line2_x_top=Get_HdfsData.get_line2_data()['model'].values.tolist()[:10],
line2_y_top=Get_HdfsData.get_line2_data()['sales'].values.tolist()[:10],
)
if __name__ == '__main__':
app.run(host='127.0.0.1', port=5001)echarts部分代码
javascript
(function() {
var myChart = echarts.init(document.querySelector(".map .chart"));
echarts.registerMap('china', chinaData);
option = {
tooltip: {
trigger: 'item',
formatter: '{b}<br/>{c} (辆)'
},
visualMap: {
min: 1,
max: 40000,
text: ['High', 'Low'],
realtime: false,
calculable: true,
inRange: {
color: ['lightskyblue', 'yellow', 'orangered']
},
textStyle: {
color: 'red' // 设置字体颜色为红色
}
},
series: [
{
name: 'city_map',
type: 'map',
map: 'china',
data: map_data,
roam: true // 在这里添加 roam 属性
}
]
};
myChart.setOption(option);
// 监听浏览器缩放,图表对象调用缩放resize函数
window.addEventListener("resize", function() {
myChart.resize();
});}
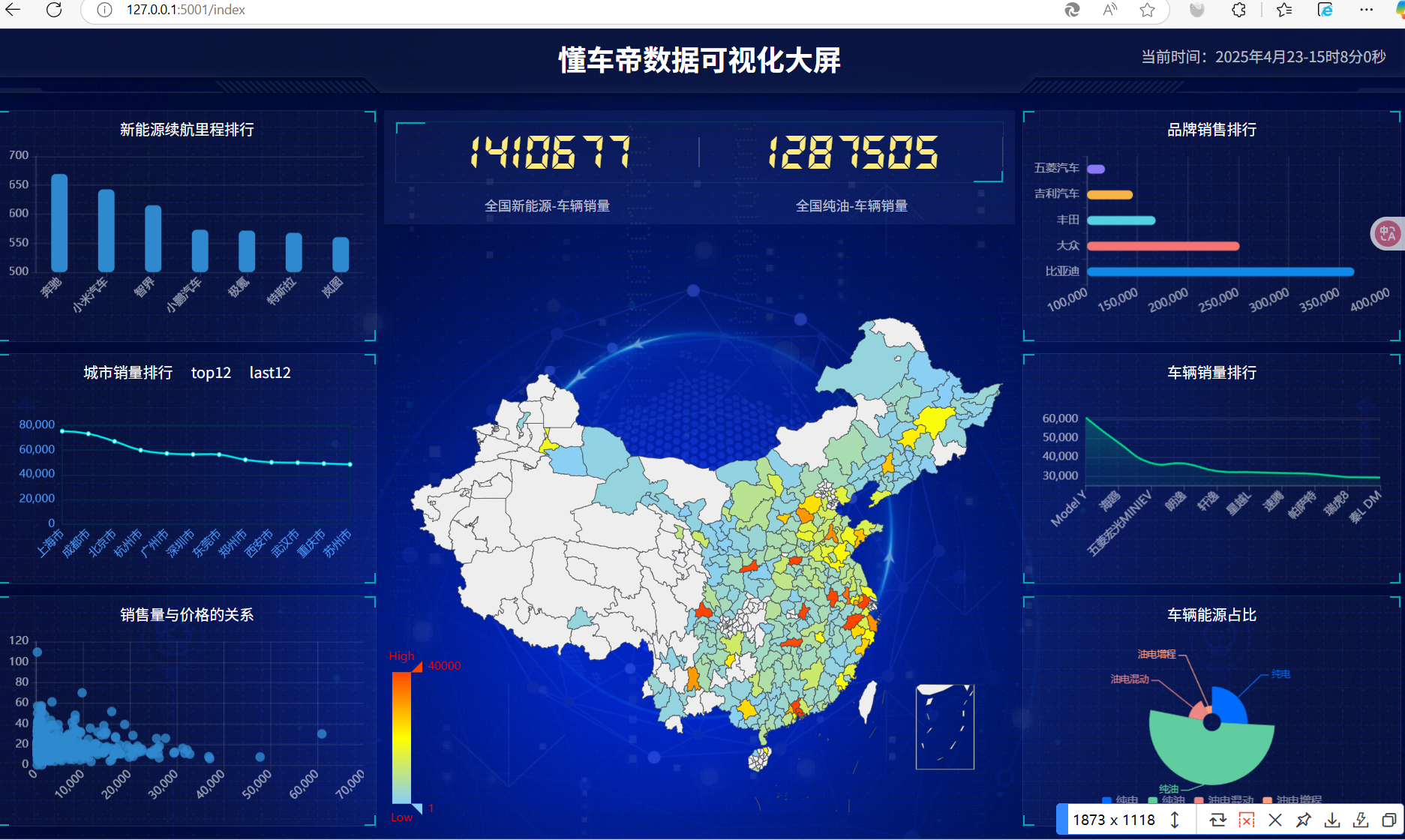
)();效果图