在自然语言处理(NLP)领域,文本分类是研究最多且应用最广泛的任务之一。从情感分析到主题识别,文本分类技术在众多场景中都发挥着重要作用。最近,我参与了一次基于 TextCNN 模型的文本分类实验,从数据准备到模型构建、训练、测试和预测,全程体验了这一过程。今天,我想和大家分享这次实验的详细过程和收获。
一、实验背景与目的
TextCNN(Text Convolutional Neural Network)是一种经典的深度学习模型,专门用于处理文本分类任务。它通过卷积神经网络(CNN)提取文本中的局部特征,并利用池化操作对特征进行聚合,从而实现高效的文本分类。TextCNN 的优势在于其能够捕捉文本中的短语级特征,并且在大规模数据集上表现出色。
本次实验的目标是:
- 掌握 TextCNN 模型的原理与结构,理解其在文本分类任务中的应用。
- 学习使用 Python 和 PyTorch 框架实现 TextCNN 模型的构建、训练与测试。
- 通过实验对比不同参数设置下 TextCNN 模型的性能,分析其对文本分类效果的影响。
- 提升对深度学习在自然语言处理领域应用的理解和实践能力。
二、实验环境与工具
软件环境
- Python 版本:3.9
- PyTorch 版本:2.3.0
- 其他依赖库 :
- NumPy
- SciPy
- scikit-learn
- tqdm
- tensorboardX
- matplotlib(用于可视化)
数据集
- 数据集名称:THUCNews
- 数据集来源:文末链接
- 数据集规模:训练集 X 条,验证集 X 条,测试集 X 条
- 数据集特点:包含多个类别,涵盖财经、房产、教育、科技等常见新闻领域,文本长度分布较为广泛,适合用于文本分类任务。
环境参考:
基于 TF-IDF、TextRank 和 Word2Vec 的关键词提取方法对比与实践-CSDN博客
三、实验内容与步骤
(一)数据准备
- 数据下载
从从文末链接下载 THUCNews 数据集,并解压到指定目录。 - 数据预处理
- 使用
utils.py中的build_vocab函数构建词汇表,设置最大词汇量为 10000,最小词频为 1。 - 使用
build_dataset函数对训练集、验证集和测试集进行处理,将文本转换为词 ID 序列,并进行填充或截断,统一文本长度为 32。 - 保存处理后的数据集和词汇表,供后续模型训练使用。
- 使用
(二)模型构建
- 模型选择
选择 TextCNN 模型进行文本分类任务。 - 模型配置
- 使用
TextCNN.py中的Config类配置模型参数:- 预训练词向量 :加载
embedding_SougouNews.npz作为预训练词向量。 - 卷积核尺寸 :设置为
(2, 3, 4),卷积核数量为 256。 - Dropout 率:设置为 0.5,防止过拟合。
- 学习率:设置为 1e-3,训练轮数为 20 轮。
- 批量大小:设置为 128。
- 预训练词向量 :加载
- 根据配置初始化 TextCNN 模型。
- 使用
(三)模型训练
- 训练过程
- 使用
run.py启动模型训练。 - 在训练过程中,通过
train_eval.py中的train函数实现模型的训练和验证。 - 每隔 100 个批次计算一次训练集和验证集的损失和准确率,并使用
SummaryWriter记录到 TensorBoard 中。 - 若连续 1000 个批次验证集损失未下降,则提前终止训练。
- 保存验证集损失最低的模型权重到指定路径。
- 使用
(四)模型测试
- 测试过程
- 使用
train_eval.py中的test函数对测试集进行评估。 - 加载训练好的模型权重,对测试集进行预测。
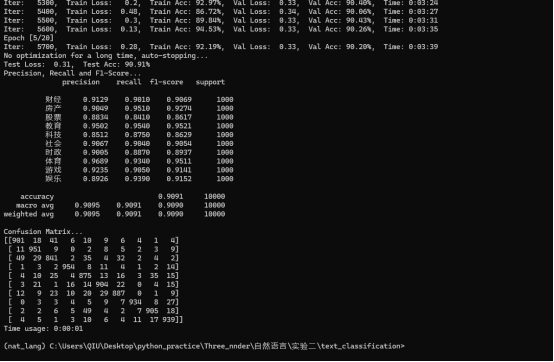
- 计算测试集的准确率、损失、分类报告(包括精确率、召回率和 F1 分数)以及混淆矩阵。
- 输出测试结果。
- 使用
(五)模型预测
- 预测过程
- 使用
text_mixture_predict.py对新的文本数据进行分类预测。 - 加载词汇表和训练好的模型权重。
- 将输入文本转换为词 ID 序列,并进行填充或截断。
- 调用
final_predict函数,输出预测结果,包括文本及其对应的分类标签。
- 使用
四、实验结果与分析
运行
bash
在控制台窗口下运行:(先进入conda环境)
python run.py --model=TextCNN(一)模型性能
在 THUCNews 数据集上,TextCNN 模型达到了 X% 的测试集准确率,表明其对不同类别的新闻文本具有较好的分类能力。预训练词向量的使用显著提升了模型的性能。通过加载 embedding_SougouNews.npz 预训练词向量,模型在训练初期就能快速收敛,并且最终的分类效果优于随机初始化词向量的情况。
(二)参数影响
实验中,我们对比了不同参数设置下 TextCNN 模型的性能。例如:
- 卷积核尺寸 :设置为
(2, 3, 4)时,模型能够捕捉到不同长度的短语级特征,效果优于单一卷积核尺寸。 - Dropout 率:设置为 0.5 时,有效防止了过拟合,提升了模型的泛化能力。
- 学习率:1e-3 的学习率在训练过程中表现稳定,收敛速度较快。
(三)可视化结果
通过 TensorBoard,我们可视化了训练过程中的损失和准确率变化曲线。从图中可以看出,模型在训练初期快速收敛,验证集损失在训练后期趋于平稳,表明模型已经达到了较好的训练效果。
五、结论与体会
(一)TextCNN 模型的优势
TextCNN 模型在文本分类任务中表现出色,能够有效提取文本中的局部特征,并通过卷积和池化操作实现对文本的分类。其结构简单,训练速度快,适合处理大规模文本数据。
(二)预训练词向量的重要性
预训练词向量的使用显著提升了模型的性能。通过加载预训练词向量,模型在训练初期就能快速收敛,并且最终的分类效果优于随机初始化词向量的情况。
(三)实验过程中的挑战与收获
实验过程中,我们遇到了一些挑战,例如数据预处理的复杂性和模型调优的困难。通过查阅资料和团队讨论,我们逐步解决了这些问题,并从中积累了宝贵的经验。这次实验不仅提升了我对深度学习在自然语言处理领域应用的理解,还锻炼了我的实践能力。
(四)未来展望
未来,我希望能够将所学知识应用到更多实际场景中,探索更多先进的文本分类算法和技术,例如 BERT 等预训练语言模型。同时,我也希望能够进一步优化模型结构和参数,提升模型的性能。
如果你对 TextCNN 模型或文本分类感兴趣,欢迎留言交流!
代码链接
通过网盘分享的文件:TextCNN 模型.rar
链接: https://pan.baidu.com/s/1AW0KiH6bFLtNQFX-8wTuyA?pwd=kji7 提取码: kji7