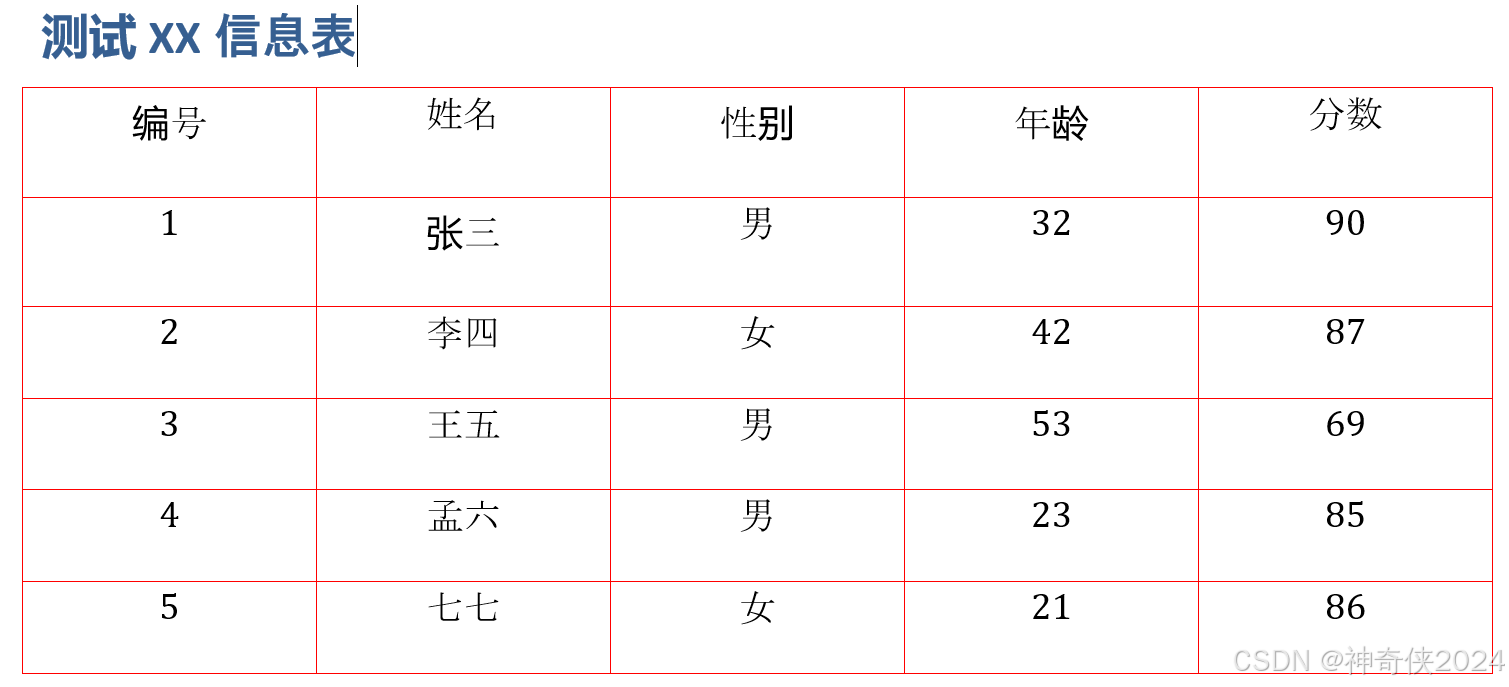
1、excel图片
说明:表格要求必须都要剧中显示

2、完整代码
python
import cv2
from paddleocr import PaddleOCR
from docx import Document
from docx.shared import Pt, Inches
from docx.oxml.ns import qn
from docx.oxml import OxmlElement
# 初始化 PaddleOCR
ocr = PaddleOCR(use_angle_cls=True, lang="ch") # 使用中文语言模型
def recognize_text(image_path):
"""
使用 PaddleOCR 进行文字识别
:param image_path: 图像路径
:return: 识别结果
"""
image = cv2.imread(image_path)
result = ocr.ocr(image, cls=True)
return result
def extract_table_data(results):
"""
从识别结果中提取表格数据
:param results: 识别结果
:return: 表格数据
"""
table_data = []
for line in results:
row_data = []
for element in line:
text = element[1][0] # 识别的文本
row_data.append(text)
table_data.append(row_data)
return table_data
def set_cell_borders(cell, border_color="000000", row_height=None):
"""
设置单元格的边框颜色
:param cell: 单元格对象
:param border_color: 边框颜色,默认为黑色
"""
tc = cell._element
tcPr = tc.get_or_add_tcPr()
tcBorders = OxmlElement("w:tcBorders")
for border_name in ("top", "left", "bottom", "right"):
border = OxmlElement(f"w:{border_name}")
border.set(qn("w:val"), "single")
border.set(qn("w:sz"), "4") # 边框大小
border.set(qn("w:space"), "0")
border.set(qn("w:color"), border_color)
tcBorders.append(border)
tcPr.append(tcBorders)
# 设置内容居中显示
for paragraph in cell.paragraphs:
for run in paragraph.runs:
run.font.size = paragraph.style.font.size # 保持字体大小一致
paragraph.alignment = 1 # 1 表示居中对齐
# 设置行高
if row_height is not None:
tr = cell._element.getparent() # 获取行元素
trPr = tr.get_or_add_trPr()
trHeight = OxmlElement("w:trHeight")
trHeight.set(qn("w:val"), str(row_height))
trPr.append(trHeight)
def create_table_and_fill_data(data, output_file):
"""
在 Word 文档中插入表格并填充数据
:param data: 表格数据
:param output_file: 输出文件路径
"""
# 创建一个新的 Word 文档
doc = Document()
# 添加一个标题sss
doc.add_heading("测试XX信息表", level=1)
# 创建表格
table = doc.add_table(rows=len(data), cols=len(data[0]))
# 填充表格数据
for row_index, row_data in enumerate(data):
for col_index, cell_text in enumerate(row_data):
cell = table.cell(row_index, col_index)
cell.text = str(cell_text)
set_cell_borders(cell, border_color="FF0000", row_height=300)
# 设置表格边框颜色
# 保存 Word 文档
doc.save(output_file)
# 转换为二维数组
def convert_to_2d(data, num_columns):
"""
将一维数组转换为二维数组
:param data: 一维数组
:param num_columns: 每行的列数
:return: 二维数组
"""
# 提取表头
headers = data[:num_columns]
# 提取数据部分
rows = data[num_columns:]
# 按列数分组
table_data = [headers]
for i in range(0, len(rows), num_columns):
table_data.append(rows[i : i + num_columns])
return table_data
def find_intervals(data, threshold=2):
"""
计算数组中相邻数据的差值大于 threshold 的索引间的间隔
:param data: 数组
:param threshold: 差值阈值
:return: 索引间隔列表
"""
intervals = []
prev_index = 0 # 前一个索引
for i in range(1, len(data)):
if abs(data[i] - data[i - 1]) > threshold:
# intervals.append(i - prev_index)
intervals.append([prev_index, i - 1])
prev_index = i
else:
continue
return intervals
def find_common_difference(array):
"""
判断数组中每个元素的差值是否相等,并返回该差值
:param array: 二维数组,其中每个元素是一个包含两个整数的列表
:return: 如果所有差值相等,返回该差值;否则,返回 None
"""
# 计算每对相邻元素的差值
differences = [abs(pair[1] - pair[0]) for pair in array]
# 检查所有差值是否相等
if all(difference == differences[0] for difference in differences):
return differences[0]
else:
return None
def extract_column_count(results):
"""
每个元素的中心点X坐标计算
从识别结果中提取表格的列数
:param results: 识别结果
:return: 表格的列数
"""
cols = []
for line in results:
for element in line:
box = element[0] # 文本框坐标
text = element[1][0] # 识别的文本
confidence = element[1][1] # 置信度
# 提取文本框的坐标信息
x_coords = [point[0] for point in box]
# 计算文本框的中心点
center_x = sum(x_coords) / len(x_coords)
# 将中心点添加到列的列表中
cols.append(center_x)
# 去重并排序
# print("去重前:", cols)
cols = sorted(cols)
# print("排序重后:", cols)
return cols
def main(image_path, output_file):
# 识别图像中的文字
results = recognize_text(image_path)
print("table:", results)
x_cols = extract_column_count(results)
intervals = find_intervals(x_cols, 5)
rows = find_common_difference(intervals) + 1
num_columns = len(x_cols) / rows
print("表格有 {} 行 {} 列".format(rows, num_columns))
# 提取表格数据
table_data = extract_table_data(results)
table_data_val = convert_to_2d(table_data[0], int(num_columns))
print("table_data2:", table_data_val)
# 在 Word 文档中创建表格并填充数据
create_table_and_fill_data(table_data_val, output_file)
# 示例:识别图片中的 Excel 表格并保存到 Word 文档
image_path = "excel.jpg" # 替换为你的 Excel 图片路径
output_file = "outputword.docx" # 输出的 Word 文件路径
main(image_path, output_file)