🧑 博主简介:曾任某智慧城市类企业
算法总监,目前在美国市场的物流公司从事高级算法工程师一职,深耕人工智能领域,精通python数据挖掘、可视化、机器学习等,发表过AI相关的专利并多次在AI类比赛中获奖。CSDN人工智能领域的优质创作者,提供AI相关的技术咨询、项目开发和个性化解决方案等服务,如有需要请站内私信或者联系任意文章底部的的VX名片(ID:xf982831907)
💬 博主粉丝群介绍:① 群内初中生、高中生、本科生、研究生、博士生遍布,可互相学习,交流困惑。② 热榜top10的常客也在群里,也有数不清的万粉大佬,可以交流写作技巧,上榜经验,涨粉秘籍。③ 群内也有职场精英,大厂大佬,可交流技术、面试、找工作的经验。④ 进群免费赠送写作秘籍一份,助你由写作小白晋升为创作大佬。⑤ 进群赠送CSDN评论防封脚本,送真活跃粉丝,助你提升文章热度。有兴趣的加文末联系方式,备注自己的CSDN昵称,拉你进群,互相学习共同进步。

【数据可视化-21】水质安全数据可视化:探索化学物质与水质安全的关联
一、项目背景与目标
水质安全是一个全球性问题,影响着数十亿人的健康。通过分析水质数据中的化学物质含量,我们可以识别潜在的危险因素,为水质管理和政策制定提供科学依据。
二、数据集介绍
本数据集包含7999条模拟水质记录,涵盖多种化学物质的浓度测量值,以及一个指示水样是否安全的分类变量。化学物质包括铝、氨、砷、钡、镉等,每种物质都有对应的安全阈值。
三、完整代码实现
1. 环境准备与数据加载
python
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# 配置可视化样式
plt.style.use('ggplot')
%matplotlib inline
# 加载数据
df = pd.read_csv('/path/to/water_quality.csv')2. 数据预处理
python
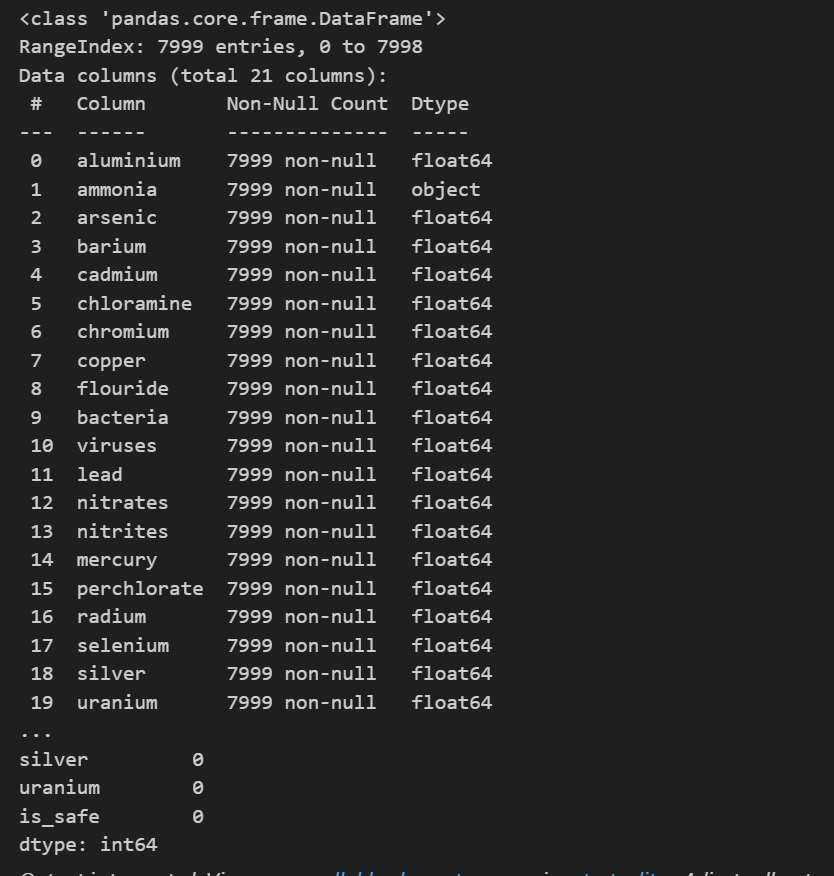
# 查看数据基本信息
print(df.info())
print(df.describe())
# 检查缺失值
print(df.isnull().sum())
# 数据重命名,方便后续处理
df = df.rename(columns={
'aluminium': 'Al',
'ammonia': 'NH3',
'arsenic': 'As',
'barium': 'Ba',
'cadmium': 'Cd',
'chloramine': 'ClNH2',
'chromium': 'Cr',
'copper': 'Cu',
'flouride': 'F',
'bacteria': 'Bacteria',
'viruses': 'Viruses',
'lead': 'Pb',
'nitrates': 'NO3',
'nitrites': 'NO2',
'mercury': 'Hg',
'perchlorate': 'ClO4',
'radium': 'Ra',
'selenium': 'Se',
'silver': 'Ag',
'uranium': 'U'
})
3. 探索性分析(EDA)
3.1 化学物质含量与水质安全性的关联
python
# 计算相关系数矩阵(皮尔逊相关系数)
corr_matrix = df.corr()
# 绘制热力图
plt.figure(figsize=(15, 10))
sns.heatmap(corr_matrix, annot=True, cmap='coolwarm', fmt=".2f")
plt.title('化学物质含量与水质安全性的相关性热力图')
plt.show()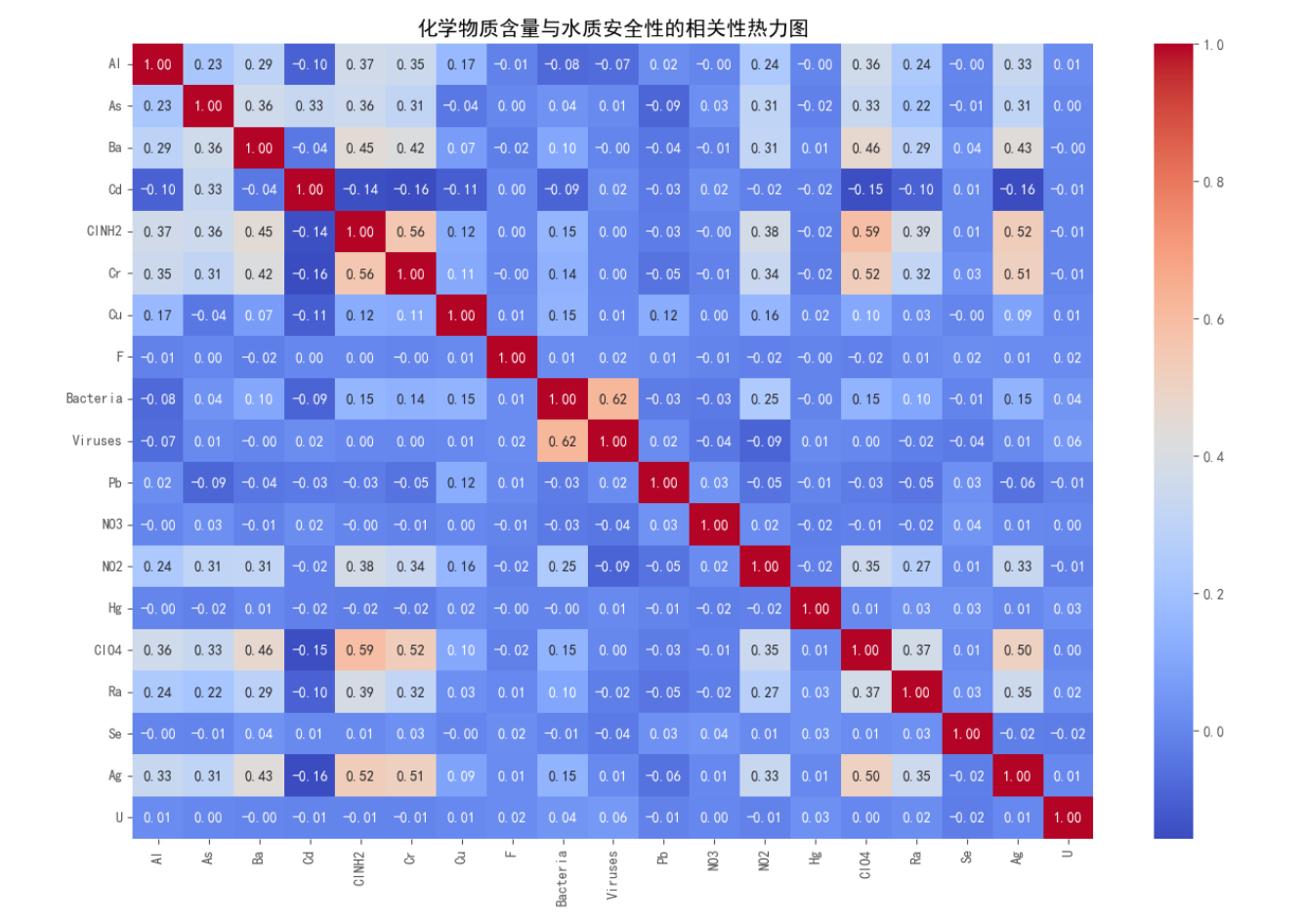
python
# 绘制关键化学物质与安全性的散点图
key_substances = ['Al', 'NH3', 'As', 'Ba', 'Cd', 'ClNH2', 'Cr', 'Cu', 'F', 'Bacteria', 'Viruses', 'Pb', 'NO3', 'NO2', 'Hg', 'ClO4', 'Ra', 'Se', 'Ag', 'U']
for substance in key_substances:
plt.figure(figsize=(10, 6))
sns.scatterplot(x=substance, y='is_safe', data=df, hue='is_safe', palette='viridis')
plt.title(f'{substance} 含量与水质安全性关系')
plt.xlabel(f'{substance} 浓度')
plt.ylabel('是否安全')
plt.grid(True)
plt.show()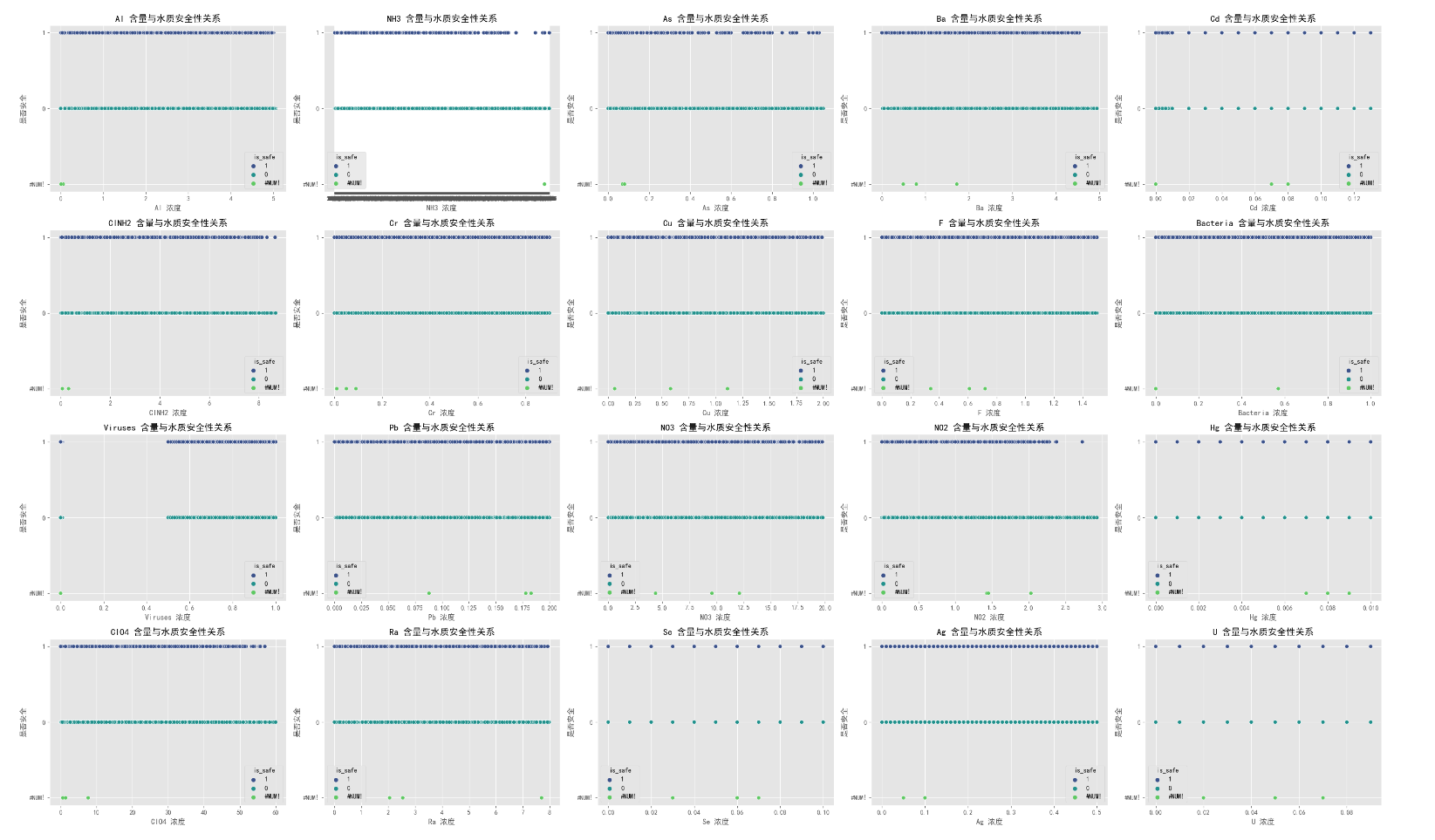
3.2 安全与不安全水样的特性
python
# 绘制关键化学物质在安全与不安全水样中的分布
fig, axes = plt.subplots(4, 5, figsize=(30, 18)) # 创建一个5行4列的画布
axes = axes.flatten() # 将2D的axes数组转换为1D
for idx, substance in enumerate(key_substances):
# 在指定的子图上绘制散点图
sns.boxplot(x='is_safe', y=substance, data=df, ax=axes[idx])
#sns.scatterplot(x=substance, y='is_safe', data=df, hue='is_safe', palette='viridis', ax=axes[idx])
axes[idx].set_title(f'{substance} 在安全与不安全水样中的分布')
axes[idx].set_xlabel(f'{substance} 浓度')
axes[idx].set_ylabel('是否安全')
axes[idx].grid(True)
plt.tight_layout() # 自动调整子图参数,防止重叠
plt.show()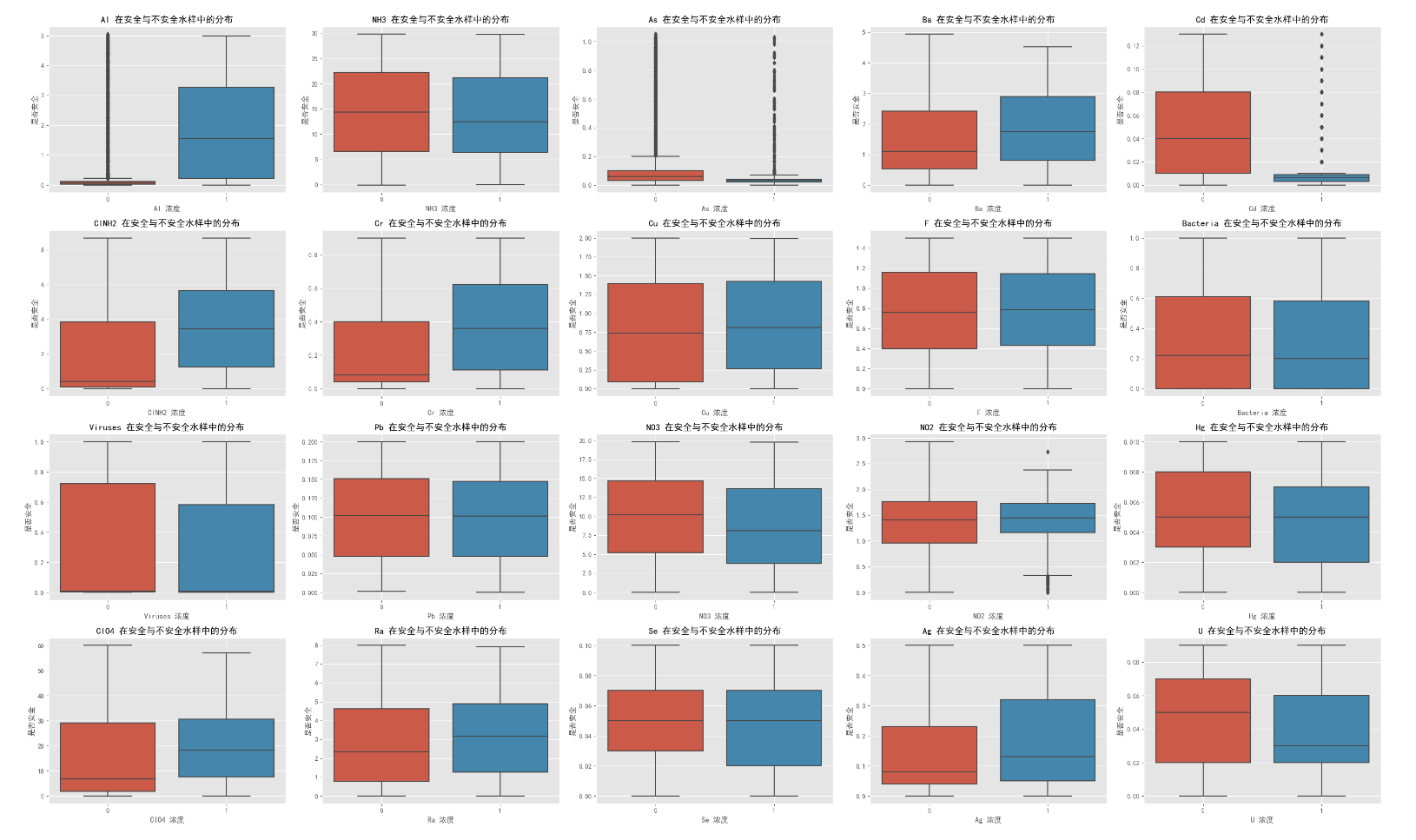
3.3 识别潜在的危险化学物质
python
# 绘制箱线图识别各化学物质中的异常值
fig, axes = plt.subplots(4, 5, figsize=(30, 18)) # 创建一个5行4列的画布
axes = axes.flatten() # 将2D的axes数组转换为1D
# 绘制箱线图识别各化学物质中的异常值
for idx, substance in enumerate(key_substances):
# plt.figure(figsize=(10, 6))
sns.boxplot(x=df[substance],ax=axes[idx])
axes[idx].set_title(f'{substance} 含量的异常值分析')
axes[idx].set_xlabel(f'{substance} 浓度')
axes[idx].set_ylabel('是否安全')
axes[idx].grid(True)
plt.tight_layout() # 自动调整子图参数,防止重叠
plt.show()
4. 分析结论与洞见
关键发现
- 砷 (As) 、铅 (Pb) 和 镉 (Cd) 与水质安全性呈现显著负相关,浓度越高,水质越可能不安全。
- 细菌 (Bacteria) 和 病毒 (Viruses) 的存在显著降低了水质安全性。
- 硝酸盐 (NO3) 和 亚硝酸盐 (NO2) 的浓度升高与水质不安全存在关联。
业务建议
- 加强砷、铅和镉的监测:重点关注这些化学物质的排放源和处理过程。
- 改善微生物污染控制:加强对水体中细菌和病毒的处理,确保微生物指标达标。
- 综合水质管理:结合多种化学和生物指标,制定全面的水质安全标准。
五、优化方向与思考
数据深化
- 整合时空数据:结合水质数据的时空信息,分析污染源的扩散路径。
- 引入外部数据:如气象数据、工业活动数据等,探索更广泛的水质影响因素。
模型构建
- 构建预测模型:使用机器学习算法预测水质安全趋势。
- 开发预警系统:实时监控关键指标,及时发出水质安全预警。
通过数据可视化,我们能够清晰地看到化学物质含量与水质安全性的关系,为水质管理和政策制定提供有力支持。希望本文能为相关领域的研究和实践提供有价值的参考。
六、完整代码
python
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# 配置可视化样式
plt.style.use('ggplot')
%matplotlib inline
# 加载数据
df = pd.read_csv('/path/to/water_quality.csv')
# 查看数据基本信息
print(df.info())
print(df.describe())
# 检查缺失值
print(df.isnull().sum())
# 数据重命名,方便后续处理
df = df.rename(columns={
'aluminium': 'Al',
'ammonia': 'NH3',
'arsenic': 'As',
'barium': 'Ba',
'cadmium': 'Cd',
'chloramine': 'ClNH2',
'chromium': 'Cr',
'copper': 'Cu',
'flouride': 'F',
'bacteria': 'Bacteria',
'viruses': 'Viruses',
'lead': 'Pb',
'nitrates': 'NO3',
'nitrites': 'NO2',
'mercury': 'Hg',
'perchlorate': 'ClO4',
'radium': 'Ra',
'selenium': 'Se',
'silver': 'Ag',
'uranium': 'U'
})
# 计算相关系数矩阵(皮尔逊相关系数)
corr_matrix = df.corr()
# 绘制热力图
plt.figure(figsize=(15, 10))
sns.heatmap(corr_matrix, annot=True, cmap='coolwarm', fmt=".2f")
plt.title('化学物质含量与水质安全性的相关性热力图')
plt.show()
# 绘制关键化学物质与安全性的散点图
key_substances = ['Al', 'NH3', 'As', 'Ba', 'Cd', 'ClNH2', 'Cr', 'Cu', 'F', 'Bacteria', 'Viruses', 'Pb', 'NO3', 'NO2', 'Hg', 'ClO4', 'Ra', 'Se', 'Ag', 'U']
for substance in key_substances:
plt.figure(figsize=(10, 6))
sns.scatterplot(x=substance, y='is_safe', data=df, hue='is_safe', palette='viridis')
plt.title(f'{substance} 含量与水质安全性关系')
plt.xlabel(f'{substance} 浓度')
plt.ylabel('是否安全')
plt.grid(True)
plt.show()
# 绘制关键化学物质在安全与不安全水样中的分布
fig, axes = plt.subplots(4, 5, figsize=(30, 18)) # 创建一个5行4列的画布
axes = axes.flatten() # 将2D的axes数组转换为1D
for idx, substance in enumerate(key_substances):
# 在指定的子图上绘制散点图
sns.boxplot(x='is_safe', y=substance, data=df, ax=axes[idx])
#sns.scatterplot(x=substance, y='is_safe', data=df, hue='is_safe', palette='viridis', ax=axes[idx])
axes[idx].set_title(f'{substance} 在安全与不安全水样中的分布')
axes[idx].set_xlabel(f'{substance} 浓度')
axes[idx].set_ylabel('是否安全')
axes[idx].grid(True)
plt.tight_layout() # 自动调整子图参数,防止重叠
plt.show()
# 绘制箱线图识别各化学物质中的异常值
fig, axes = plt.subplots(4, 5, figsize=(30, 18)) # 创建一个5行4列的画布
axes = axes.flatten() # 将2D的axes数组转换为1D
# 绘制箱线图识别各化学物质中的异常值
for idx, substance in enumerate(key_substances):
# plt.figure(figsize=(10, 6))
sns.boxplot(x=df[substance],ax=axes[idx])
axes[idx].set_title(f'{substance} 含量的异常值分析')
axes[idx].set_xlabel(f'{substance} 浓度')
axes[idx].set_ylabel('是否安全')
axes[idx].grid(True)
plt.tight_layout() # 自动调整子图参数,防止重叠
plt.show()