
本篇博客给大家带来的是网络原理的相关知识.其中传输层这一部分非常重要,面试中只要是涉及到网络这一部分知识,几乎是必定会考传输层TCP的.
🐎文章专栏: JavaEE初阶
🚀若有问题 评论区见
❤ 欢迎大家点赞 评论 收藏 分享
如果你不知道分享给谁,那就分享给薯条.
你们的支持是我不断创作的动力 .
王子,公主请阅🚀
- 要开心
- [1. 应用层](#1. 应用层)
- [★2. 传输层](#★2. 传输层)
-
- [2.1 端口号](#2.1 端口号)
- [2.2 UDP协议](#2.2 UDP协议)
- [2.3 TCP协议](#2.3 TCP协议)
-
- [2.3.1 TCP协议格式](#2.3.1 TCP协议格式)
- [2.3.2 TCP的特点](#2.3.2 TCP的特点)
- [★2.3.3 TCP传输数据时的重要过程](#★2.3.3 TCP传输数据时的重要过程)
-
-
要开心
要快乐
顺便进步
1. 应用层
应用层和程序员接触最密切, 上一篇文章写回显TCP代码,其实就是应用层中的应用程序.
在应用层这里,很多时候都是程序员"自定义"应用层协议.
比如: 客户端向服务器发送请求时,要按程序员约定好的格式发送.
服务器向客户端发送响应时要按程序员约定好的格式发送.
发送的格式就是程序员自定义的应用层协议.
当然,也有一些现成的应用层协议:
① xml 这是"上古时期"的组织数据的格式了,通过标签来组织数据. 目前很少用于网络通信.
优点: 数据可读性强
劣势: 标签写起来非常繁琐,传输的时候也占用更多的网络带宽.
具体格式如下:

② json 当下最流行的一种数据组织格式,通过键值对结构来组织数据.
优点: 可读性高,比 xml 更加简洁.
劣势: 在网络传输中,同样会消耗额外的带宽.
具体格式如下:

③ protobuffer 使用二进制的方式来组织数据.
优势: 占用带宽最低,传输效率最高, 非常适合性能要求高的场景.
劣势: 可读性非常弱, 影响开发效率.
注意: 影响开发效率这一缺点是非常致命的 ,相较于计算机的执行效率来说, 程序员的开发效率是更重要的.
★2. 传输层
传输层这一部分,既是面试的考点,也是工作中的常用内容. 非常重要.
UDP: 无连接,不可靠,面向数据报,全双工.
TCP: 有连接,可靠传输,面向字节流,全双工 .
2.1 端口号
端口号(Port)标识了一个主机上进行通信的不同的应用程序;
写一个服务器,必须手动指定一个端口号,通过端口来区分当前这个主机上的不同的应用程序.
写一个客户端,客户端在通信的时候也会有一个端口号,该端口号由系统自动分配的.
在TCP/IP协议中, 用 "源IP", "源端口号", "目的IP", "目的端口号", "协议号" 这样一个五元组来标识一个通信.
Ⅰ 端口号范围划分
① 0 - 1023: 知名端口号, HTTP, FTP, SSH等这些广为使用的应用层协议, 他们的端口号都是固定的.
② 1024 - 65535: 操作系统动态分配的端口号. 客户端程序的端口号, 就是由操作系统从这个范围分配的.
Ⅱ 认识知名端口号
① ssh服务器, 使用22端口.
② http服务器, 使用80端口.
③ https服务器, 使用443端口.
④ ftp服务器, 使用21端口.
⑤ telnet服务器, 使用23端口.
我们自己写一个程序使用端口号时, 要避开这些知名端口号.
Ⅲ 关于端口号的两个问题
① 一个进程是否可以bind多个端口号?
② 一个端口号是否可以被多个进程bind?
2.2 UDP协议
Ⅰ UDP协议端格式:详细见-> RFC标准文档
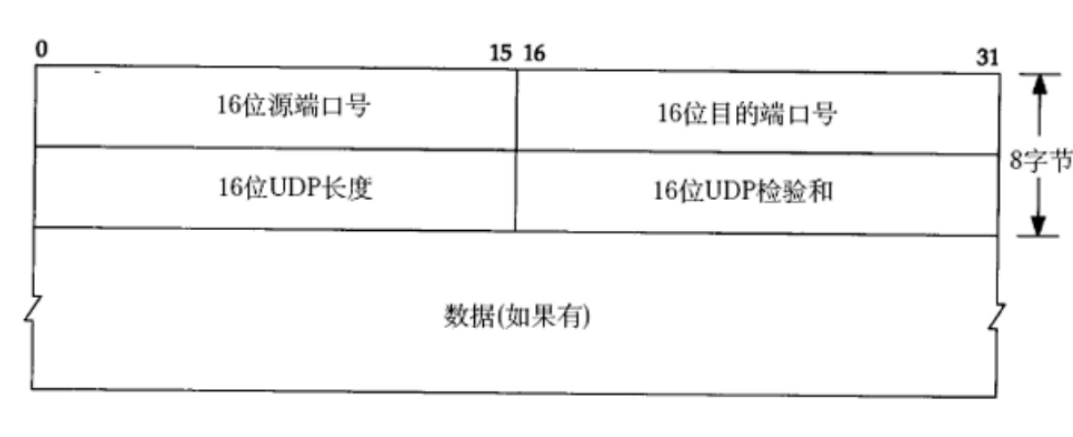
这样来看更加直观:
注意: 端口号和 ip 虽然写代码的时候总是一起用,但它们并不在同一层, 源 ip 和 目的 ip 在网络层的ip协议中
① 16位UDP长度, 表示整个数据报(UDP首部+UDP数据)的最大长度.
2个字节的长度大概就是64kb,这在上个世纪80年代,确实不算少, 但是现在64kb是很小的.
所以使用 UDP协议 的时候,难以表示一个很大的数据报
② 如何基于校验和来完成数据校验?
- 发送方,把要发送的数据整理好(称为 data1),通过一定的算法,计算出校验和 checksum1.
- 发送方把 data1 和 checksum1 一起通过网络发送出去.
- 接收方收到数据,收到的数据称为 data2(数据可能和 data1 就不-样了),收到数据 checksum1.
- 接收方再根据 data2 重新计算校验和(按照相同的算法),得到 checksum2.
- 对比 checksum1 和 checksum2 是否相同.如果不同,则认为 dat2 和 data1 一定不相同.
③ 计算校验和的算法,本文只介绍两种:
-
UDP中使用的是CRC算法(循环冗余算法).
把当前要计算校验和的数据,每个字节,都进行累加,把结果保存到这个 两个字节的 变量中,累加过程中如果溢出,也没关系,
如果中间某个数据,出现传输错误,第二次计算的校验和就会和第一次不同.
CRC 这个算法其实不是特别的靠谱,导致两个不同的数据,得到相同的 CRC 校验和的概率比较大.例如: 前一个字节 少 1,后一个字节恰好 多 1. -
md5算法.(md5在线加密文档 )
md5是利用一系列的公式, 来完成计算的. 此处只需知道md5算法的特点即可.
第一点: 加密结果定长. 无论原始数据多长,计算得到的 md5结果都是固定长度, 校验和短才方便网络传输.
第二点: 加密结果分散. 给定两个原始数据,哪怕绝大部分内容都一样,只要其中一个字节不同,得到的 md5 值都会差异很大. 这一特点,也说明了md5 非常适合作为 hash 算法.
第三点: md5算法不可逆. 给你一个原始数据,计算 md5非常容易. 给你 md5,还原出原始数据,计算量非常庞大,以至于超出了现有计算机的算力极限,理论上是不可行的.
Ⅱ UDP 的特点
① 无连接.
UDP 协议本身不会存储对端的信息. 要在发送数据的时候,显式指定要传输给谁.
java
//3. 把响应写回客户端.
// 搞一个响应对象,DatagramPacket
// 往DatagramPacket里构造刚才的数据,再通过send返回
DatagramPacket responsePacket = new DatagramPacket(response.getBytes(),response.getBytes().length,
requestPacket.getSocketAddress());
socket.send(responsePacket);上述代码是 【网络编程】从零开始彻底了解网络编程(二) 这篇文章中第五节 使用UDP写回显服务器的一段代码,详细可看这篇文章.
② 不可靠传输. 在代码中体现不出来, 后面介绍TCP 协议的可靠传输一对比就能感知到.
③ 面向数据报, UDP是以DatagramPacket为单位进行传输的. 上述代码同样可以说明这一特点.
java
//3. 把响应写回客户端.
// 搞一个响应对象,DatagramPacket
// 往DatagramPacket里构造刚才的数据,再通过send返回
DatagramPacket responsePacket = new DatagramPacket(response.getBytes(),response.getBytes().length,
requestPacket.getSocketAddress());
socket.send(responsePacket);④ 全双工, 通过一个socket,即可接收,又可发送.
java
//1. 读取请求并解析
DatagramPacket requestPacket = new DatagramPacket(new byte[4096],4096);
socket.receive(requestPacket);
//3. 把响应写回客户端.
// 搞一个响应对象,DatagramPacket
// 往DatagramPacket里构造刚才的数据,再通过send返回
DatagramPacket responsePacket = new DatagramPacket(response.getBytes(),response.getBytes().length,
requestPacket.getSocketAddress());
socket.send(responsePacket);Ⅲ 基于UDP的应用层协议:
① NFS: 网络文件系统.
② TFTP: 简单文件传输协议.
③ DHCP: 动态主机配置协议.
④ BOOTP: 启动协议(用于无盘设备启动).
⑤ DNS: 域名解析协议.
2.3 TCP协议
2.3.1 TCP协议格式
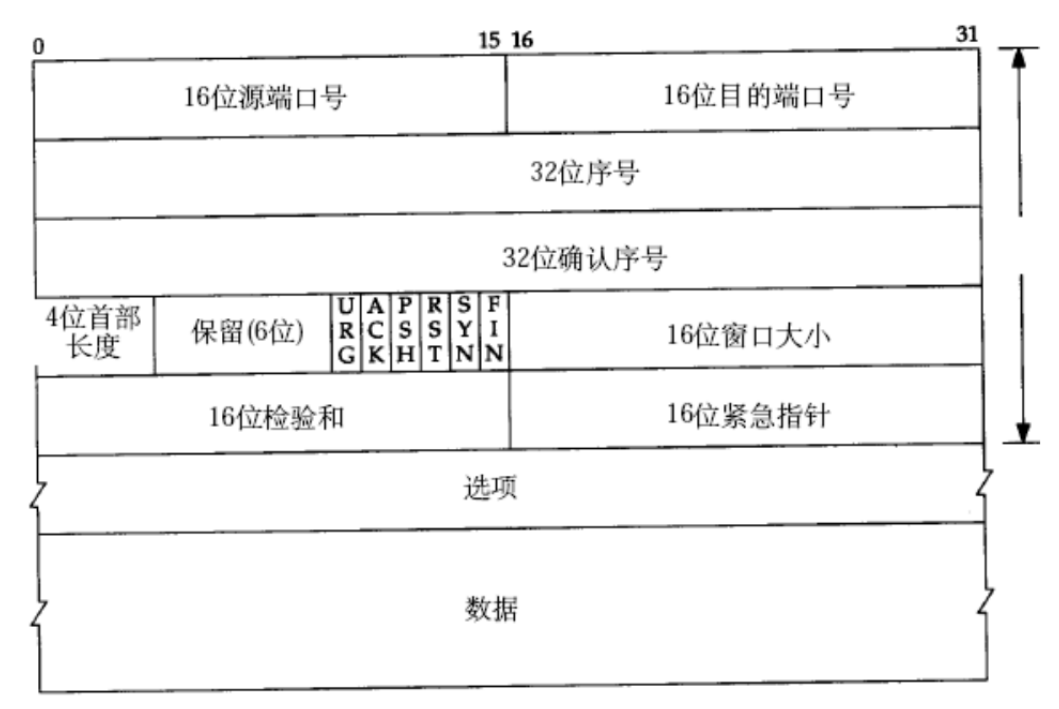
16位源端口号和目的端口号和UDP相同,不再多说. 直接看到第四行:
TCP报头长度不是固定不变的,其中还保留了6位,这是TCP大佬设计时的一点小细节, 改进了UDP固定长度无法扩展的问题.
2.3.2 TCP的特点
① 有连接
java
//1. 通过accept方法,把内核中已经建立好的连接拿到应用程序.
Socket clientSocket = serverSocket.accept();② 可靠传输, TCP最最核心的特性,也是TCP设计的初心.
③ 面向字节流 ,inputStream和outputStream就是字节流对象.
java
try(InputStream inputStream = clientSocket.getInputStream();
OutputStream outputStream = clientSocket.getOutputStream())④全双工, 一个serverSocket即可接收信息,又可发送信息.
★2.3.3 TCP传输数据时的重要过程
可靠传输不是说发送方把数据能够100%的传输给接收方,而是:
发送方发出数据之后,能够知道接收方是否收到了数据,如果发现对方没收到,就可以通过一些手段来补救.
Ⅰ 确认应答
发送方把数据发给接收方之后,接收方收到数据就会给发送方返回一个 应答报文 (acknowledge, 简称ack).发送方,如果收到这个应答报文了,就知道自己的数据发送成功了.
我们来考虑数据接收的顺序问题. 假设有以下场景:

如果无法保证数据传输的顺序,就有可能出现下面情况:
好在上述问题TCP本身就能解决, TCP格式中序号的大小关系就决定了数据的先后顺序.
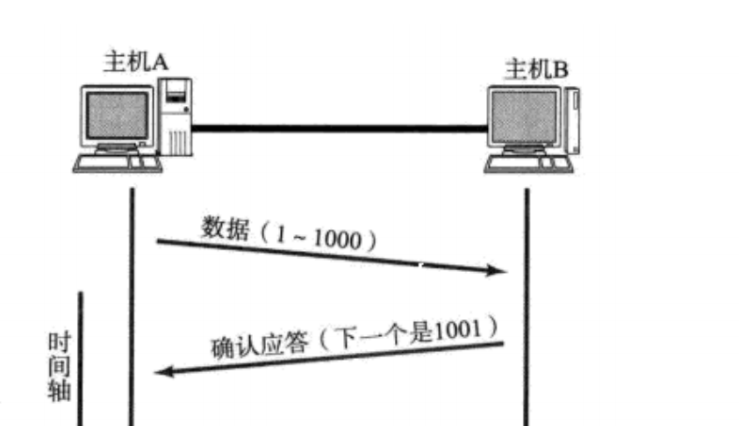
① 上述 TCP 数据包里一共有 1000 个字节的载荷数据.其中第一个字节的序号是1,就在 TCP 报头的序号字段中,写"1" . 由于一共是 1000 个字节,此时最后一个字节的序号自然就是1000 了. 但是 1000 这样的数据并没有在 TCP 报头中记录.
TCP 报头中记录的序号,是这一次传输的载荷数据中第一个字节的序号剩下其他字节的序号都需要依次推出. 在应答报文中, 就会在确认序号 字段中填写 1001.
② 通过特殊的 ack 数据包,里面携带的"确认序号"告诉发送方,哪些数据已经被确认收到了此时发送方,就心中有数了,就知道了自己刚发的数据是到了还是没到. (这其实就是可靠传输的体现).
③ 怎么确定主机B发过来的是ack数据包呢?

红圈中ack这一位如果是1,就表示当前数据包是一个应答报文,此时该数据包中的"确认序号子段"就能生效.
再多提一嘴:
TCP能够保证可靠传输,主要是以确认应答为主,其他机制为辅来实现可靠传输的.
Ⅱ 超时重传
确认应答描述的是一个比较理想的情况, 如果网络传输过程中出现丢包了, 发送方就势必无法收到 ack 了. 超时重传机制,针对确认应答,进行补充
① 为什么会出现丢包?
把网络想象成公路,全国公路组成一张公路网,错综复杂,在公路上有很多的收费站. 正常情况下,公路上很少出现堵车的情况, 但在一些节假日时(国庆)收费站这就会堵车. 可以把收费站理解成路由器/交换机. 一旦数据包太多就会堵在路由器/交换机上. 路由器处理"堵车"问题比较粗暴, 它不会把所有数据包都保存下来,而是保存一部分, 然后把大部分数据包直接丢掉.此时就出现了丢包的情况.
② 丢包了之后怎么办呢?
重传一下试试呗.无论是传输数据丢了还是返回的 ack 丢了,对于发送方来说虽然无法区分这两种情况,但是只要没收到接收方的 ack , 就会重传数据包.
假设每次发送数据包的丢包概率为10%, 那么两次传输都丢包的概率是1%.可以看到重传操作能大幅度地提升数据成功传输的概率.
③ 超时重传能够进一步保证可靠性,但同时也付出了代价:
重传会降低传输效率,同时TCP的复杂程度也变高了.
④ 发送方没收到接收方的ack, 何时进行重传?
发送方发出去数据之后, 会等待一段时间. 如果这个时间之内,ack 来了,自然就视为正常传输.如果到达这个时间之后,数据还没到,就会触发重传机制.
初始的等待时间,是可配置的.不同的系统上都不一定一样,也可以通过修改一些内核参数来引起这里的时间变化.
当 主机A 重传了数据后,还是没有收到 ack,第二次等待的时间就会比第一次更长.
⑤ 重传了数据包给B, 对于主机B来说,收到了两条一样的数据,inputStream.read,读出来的是两条一样的数据,必然会有问题.
就好像A转账给B两次50块, 第一次没成功,第二次成功了, B收到了50块,A扣款100块.
TCP 已经非常贴心的帮我们把这个问题解决了,TCP 会有一个"接收缓冲区"就是一个内存空间,会保存当前已经收到的数据,以及数据的序号. 接收方如果发现,当前发送方发来的数据,是已经在接收缓冲区中存在的,接收方就会直接把这个后来的数据给丢弃掉.确保应用程序进行 read 的时候,读到的是只有一条数据.
Ⅲ 连接管理
建立连接+断开连接
这部分知识就是面试中最经典的问题三次握手和四次挥手问题.
① TCP的三次握手
TCP 在建立连接的过程中,需要通信双方"打三次招呼"才能够完成建立连接.
实际开发中,主动发起连接的一方,就是客户端,被动接受的一方就是服务器.
三次握手过程,需要用到syn(同步报文段), 什么是同步报文段,怎么判断?
同步报文段也是一个特殊的 TCP 数据包,没有载荷,意味着它不携带业务数据.

当上述syn这一位为1时, 表示这个报文是一个同步报文段.如果这一位为0,则说明不是.
三次握手过程如下图:
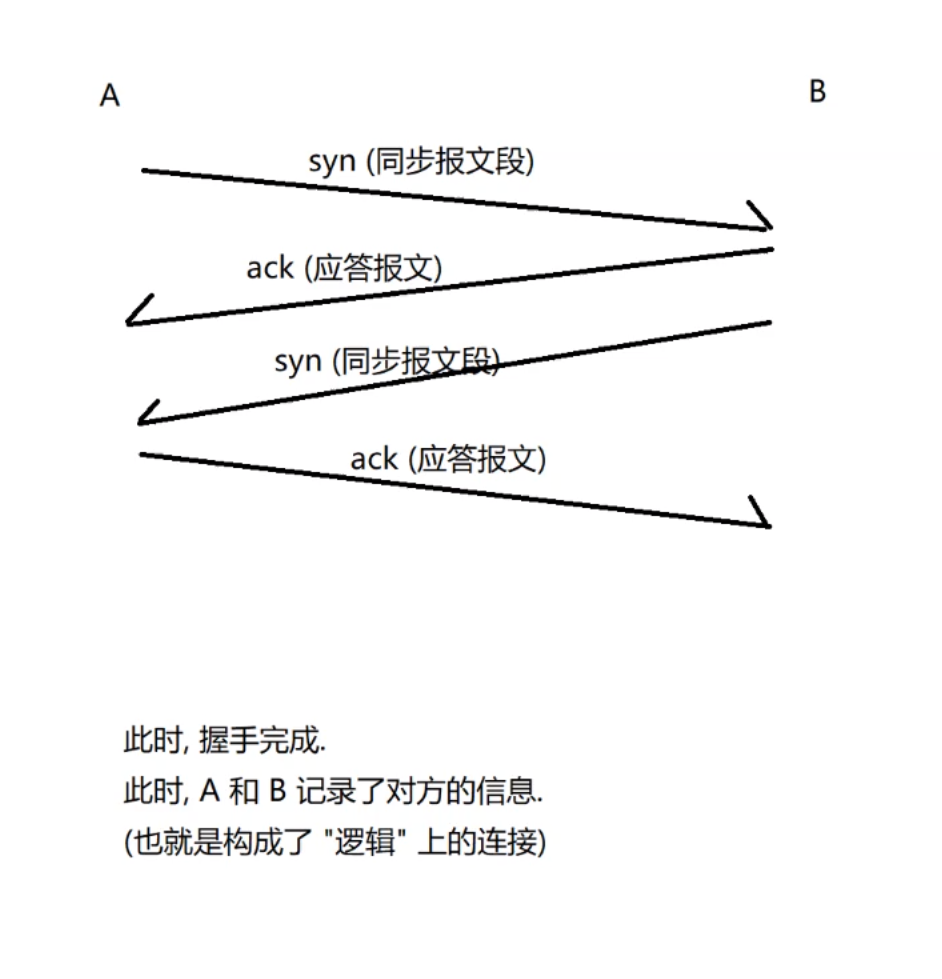
看到上图问题就来了, 不是总共发送了四次数据包吗? 怎么才握手三次呢?
实际上,是因为B给A发送的 ack 和 syn 这两次可以合并成一次, 因为这两次传输都是内核响应的.
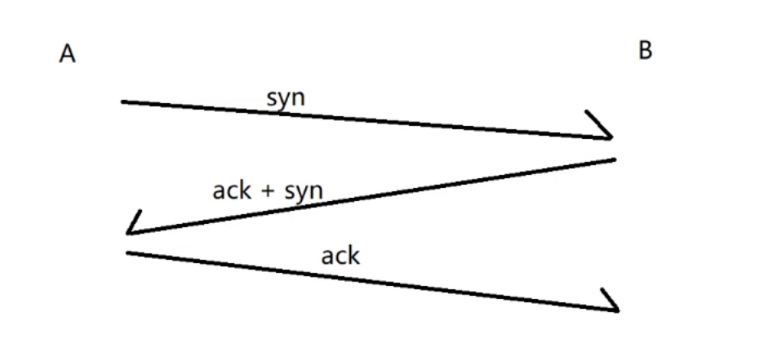
三次握手的三个重要作用
- 投石问路, 确认当前网络是否畅通.
- 让发送方和接收方都能确认自己的发送能力和接收能力是否正常.
- 让通信双方针对一些重要的参数进行协商.
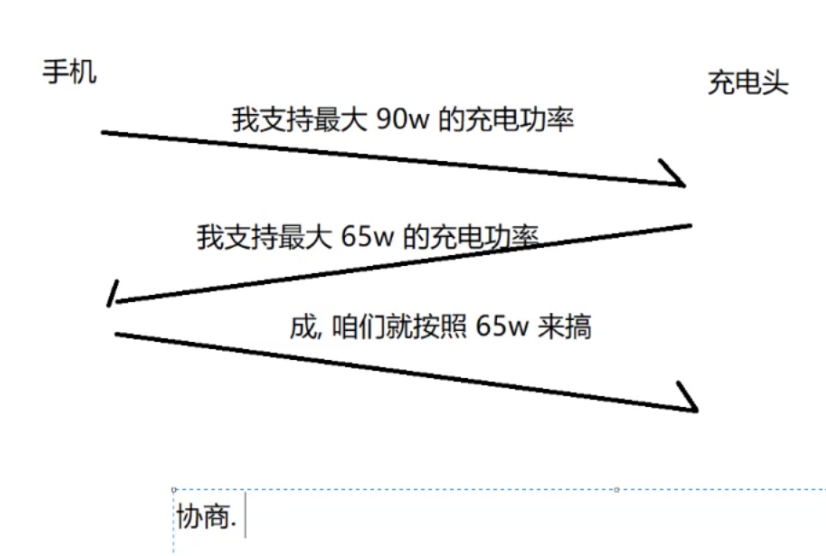
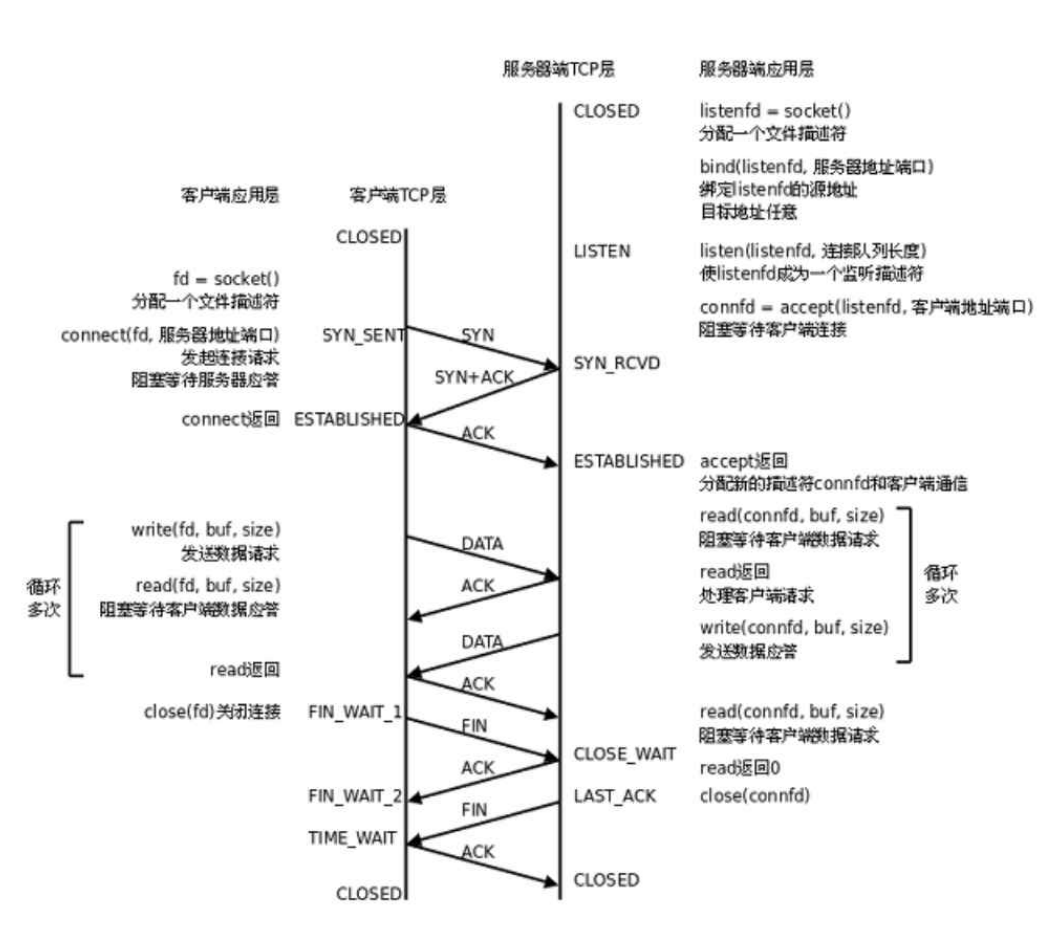
只看三次握手的部分:

② 断开连接: TCP的四次挥手
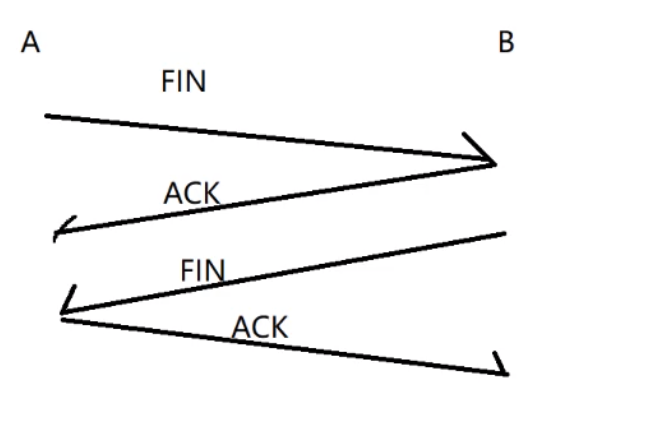
FIN是结束报文段

同样的如果红圈这一位是1,说明该数据包是结束数据包.
和 三次握手不同, 此处的四次挥手,能否把中间的两次交互合二为一呢? 不一定能,但正常情况下不能合并.
不能合并的原因是ACK 和 第二个 FIN 的触发时机是不同的.
ACK 是内核响应的.B 收到第一个 FIN,就会立即返回 ACK. 第二个 FIN 是应用程序的代码触发.B 这边调用了 close 方法才会触发 FIN.
从服务器收到 FIN(同时返回 ACK),再到执行到 close发起 FIN, 这中间要经历多少时间,经历多少代码,是不确定的,主要还是要看代码是怎么写的.
所以 前面的三次握手, ACK 和 第二个 syn 都是内核触发的. 同一个时机可以合并. 这里的四次挥手,ACK 是内核触发的,第二个 FIN 是应用程序执行 close 触发的.时机不相同,不能合并. 如果我这边代码 close 没写/没执行到, 第二个 FIN 就有可能一直发不出去的. 这个时候就是异常断开连接(没有挥完四次).
TCP 中还有一个机制,延时应答(下篇文章再说),能够拖延 ACK 的回应时间,一旦 ACK 滞后了,就有机会和下一个 FIN 合并在一起了.
四次挥手的详图如下:
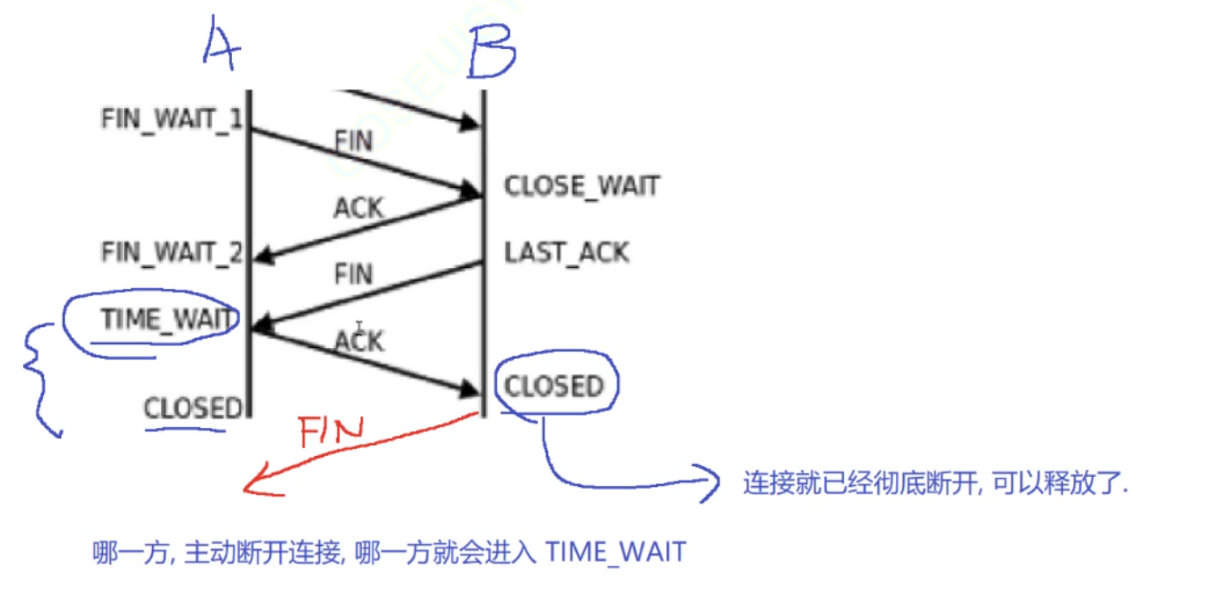
TIME WAIT 状态存在的主要意义就是为了防止最后一个 ACK 丢失.
如果最后一个 ACK 丢了,站在 B 的角度,B 就会触发超时重传重新把刚才的 FIN 给传一遍.如果 A 没有进入 TIME WAIT 状态, 就意味着 A 这个时候就已经真的释放连接了此时重传的 FIN 也就没人能处理, 没人能返回 ACK 了.B 永远也收不到 ACK 了.
本篇博客到这里就结束啦, 感谢观看 ❤❤❤
🐎期待与你的下一次相遇😊😊😊