文章目录
- 引言
- 一、自然语言处理的概念
- 二、语言转换的概念
-
- [1. 统计语言模型](#1. 统计语言模型)
-
- [(1) 词向量转换](#(1) 词向量转换)
- [(2) 统计语言模型的问题](#(2) 统计语言模型的问题)
- [2. 神经语言模型](#2. 神经语言模型)
-
- [(1) One-Hot编码。](#(1) One-Hot编码。)
- [(2) One-Hot编码的问题](#(2) One-Hot编码的问题)
- [(3) 解决维度灾难问题](#(3) 解决维度灾难问题)
- [(4) embedding词嵌入](#(4) embedding词嵌入)
- [(5) Word2Vec技术](#(5) Word2Vec技术)
- 总结
引言
NLP的全称是Natuarl Language Processing,中文意思是自然语言处理,是人工智能和计算语言学的一个分支,旨在使计算机能够理解和处理人类语言。NLP 涵盖了从文本分析到生成文本的广泛任务,其目标是让计算机能够像人类一样理解和交流。
一、自然语言处理的概念
自然语言处理就是一种利用计算机科学、人工智能和语言学理论来研究和实现计算机对人类自然语言进行理解和处理的技术。NLP就是人类和机器之间沟通的桥梁!
而想要机器能理解人类的语言,那就需要进行语言转换。
二、语言转换的概念
语言转换是指将一种语言表达的内容转换为另一种语言表达的过程,其核心目标是保持语义的等价性。根据转换的粒度和目的。
在自然语言处理中,语言转换方法由两个模型:
- 统计语言模型
- 神经语言模型
1. 统计语言模型
统计语言模型(Statistical Language Model, SM)是一种基于统计学的方法,用于描述和预测自然语言文本中的词汇或句子出现的概率。这种方法通过分析大量文本数据,学习词汇和句子的概率分布,从而能够预测给定上下文的下一个词或子词。
(1) 词向量转换
具体体现在机器学习中的词向量转换方法:
python
from sklearn.feature_extraction.text import CountVectorizer
texts = ['dog cat fish','dog cat cat','fish bird','bird']
cv = CountVectorizer(ngram_range=(1,3))
#结果是稀疏矩阵格式
cv_fit = cv.fit_transform(texts)
#表示每个字符串中,是否有cv中的词,有标记为1,反之为。
print(cv.get_feature_names_out())
print(cv_fit.toarray()) #参数- texts:定义文本数据集 - 4个简单的句子
- cv =CountVectorizer(ngram_range=(1,3)):创建CountVectorizer对象。
- ngram_range=(1,3) 的含义:提取1-gram(单词)、2-gram(相邻两词)、3-gram(相邻三词)的所有可能组合。
- 比如:'Python is useful' 中ngram_range(1,3)之后可得到
'Python' 、'is' 、'useful' 、'Python is' 、'is useful' 和 'Python is useful' ;
如果是ngram_range (1,1),则只能得到单个单词 'Python' 、'is' 和 'useful' - cv_fit = cv.fit_transform(texts): 拟合数据并转换为特征矩阵
输出结果:
python
['bird' 'cat' 'cat cat' 'cat fish' 'dog' 'dog cat' 'dog cat cat'
'dog cat fish' 'fish' 'fish bird']
[[0 1 0 1 1 1 0 1 1 0]
[0 2 1 0 1 1 1 0 0 0]
[1 0 0 0 0 0 0 0 1 1]
[1 0 0 0 0 0 0 0 0 0]]- 第一个输出 cv.get_feature_names_out() 输出的是提取出的n-gram特征(词汇表)。
- 第二个输出 cv_fit.toarray()
输出的是文档-词项矩阵,每行代表一个文档,每列代表一个n-gram特征,值表示该n-gram在文档中出现的次数。
例如第一行 0 1 0 1 1 1 0 1 1 0 对应第一个文档 'dog cat fish':
- 'bird'出现0次
- 'cat'出现1次
- 'cat cat'出现0次
- 'cat fish'出现1次
- 'dog'出现1次
- 'dog cat '出现1次
- 'dog cat cat'出现0次
- 'dog cat fish'出现1次
- 'fish'出现1次
- 'fish bird'出现0次
这样做的目的是将文本转换为机器学习模型可处理的数值形式。接着将词向量传进贝叶斯模型,计算概率,用以预测给定上下文的下一个词或子词。
(2) 统计语言模型的问题
(1) 由于参数空间的爆炸式增长,它无法处理 N(ngram_range)\>3 的数据 :
以上方的词向量转换方法为例,我们发现,若是我们的文本数量很多时,同时连续词的组合没有上限时,它的参数空间会很大很大,模型没有能力再处理了。
例如在统计语言模型中,假设句子S=w1,w2,...,wn。由于自然语言是上下文相关的信息传递方式,可以很自然地讲句子S出现的概率定义如下:
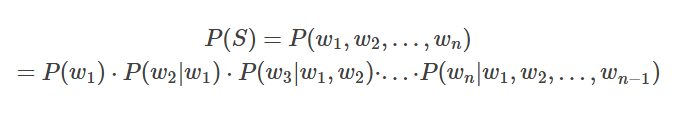
其中 P(w1)表示第一个词出现的概率, P(w2|w1) 表示w1已经出现的前提下, w2挨着它 出现的概率, 以此类推。前两个比较好算, 但第三个就涉及到了三个变量 w1,w2,w3再往后就更难算了.
说到这里,相信大家已经发现了一个很现实却很重要的问题:在这个模型中,参数的数量也太多了!
假设我们的统计基元个数为L(在这里可以将其理解为词汇表),那么一句话中的第 i 个基元就有 Li-1 种不同的历史情况。我们必须考虑到所有不同的历史情况下产生第 i 个基元的概率,于是,对于长度为m的句子,模型中有 Lm 个自由参数P(wm|w1...wm-1)。
这样算来,这会是一个很可怕的参数数量,假设L = 5000(词汇表中的词数有5000),m = 3,模型中的自由参数就达到了 50003=1250亿!这还仅仅是对应着一个三个词的句子,而汉语中平均每句话中有22个词,这将是一个天文数字。
(2) 没有考虑词与词之间内在的联系性
例如,考虑"the cat is walking in the bedroom"这句话。如果我们在训练语料中看到了很多类似"the dog is walking in the bedroom"或是"the cat is running in the bedroom"这样的句子;那么,哪怕我们此前没有见过这句话"the cat is walking in the bedroom",也可以从"cat"和"dog"("walking"和"running")之间的相似性,推测出这句话的概率。
于是为了解决这些问题,我们提出了神经语言模型
2. 神经语言模型
(1) One-Hot编码。
先来介绍一下词汇表的概念与作用:
词汇表是为语料库建立一个所有不重复词的列表,每个词对应一个索引值,并索引值不可以改变。词汇表的最大作用就是可以将词转化成一个向量,即One-Hot 编码。
假设我们有这样一个词汇表:
python
我
爱
自然
语言
处理那么,我们就可以得到如下的One-Hot编码:
python
我: [1, 0, 0, 0, 0]
爱: [0, 1, 0, 0, 0]
自然:[0, 0, 1, 0, 0]
语言:[0, 0, 0, 1, 0]
处理:[0, 0, 0, 0, 1]这样我们就可以简单的将词转化成了计算机可以直接处理的数值化数据了。虽然One-Hot编码可以较好的完成部分NLP任务,但它的问题还是不少的。
(2) One-Hot编码的问题
如果需要对语料库中的每个字进行one-hot编码如何实现?
下面我们举个例子:
假设语料库中共有4960个词,按顺序依次给每个词进行one-hot编码,例如第1个词为:1,0,0,0,0,0,0,....,0,最后1个词为: 0,0,0,0,0,0,0,....,1
这时,假使还是有句话"我爱自然语言处理",他们的编码就会变成:
python
我: [1, 0, 0, 0, 0, 0, 0..........0]
爱: [0, 1, 0, 0, 0, 0, 0..........0]
自然: [0, 0, 1, 0, 0, 0, 0..........0]
语言: [0, 0, 0, 1, 0, 0, 0..........0]
处理: [0, 0, 0, 0, 1, 0, 0..........0]
维度为5×4960那么这句话的维度大小就会变成 5×4960 。
如此编码的话,它的编码维度会非常的高,矩阵为非常稀疏,出现维度灾难。训练时维度堆积,随着维度的增加,计算复杂度也显著增加。同时One-Hot编码也缺少词的语义信息。由于这些问题,才有了后面大名鼎鼎的Word2vec。
维度灾难(Curse of Dimensionality)是一个在数据分析、机器学习和统计学中广泛讨论的概念。它描述的是当数据集的维度(即特征或变量的数量)增加时,数据分析和模型的复杂性急剧上升,导致一系列问题和挑战。
(3) 解决维度灾难问题
- 通过神经网络训练,将每个词都映射到一个较短的词向量上来。将高维映射到低维。
比如一个西瓜,它包含的特征有:可以吃的、圆的、绿色的、红色果肉等等;
再比如一个篮球,他办函的特征有:不能吃、圆的、褐色的、运动等等;
我们将它们的特征(假设300个),300个特征是可以能够描述出一个物体的,都放进神经网络训练,经过归一化的处理,维度中的数字就变成浮点数了。我们用这些浮点数来代表该物体,将维度变为300。
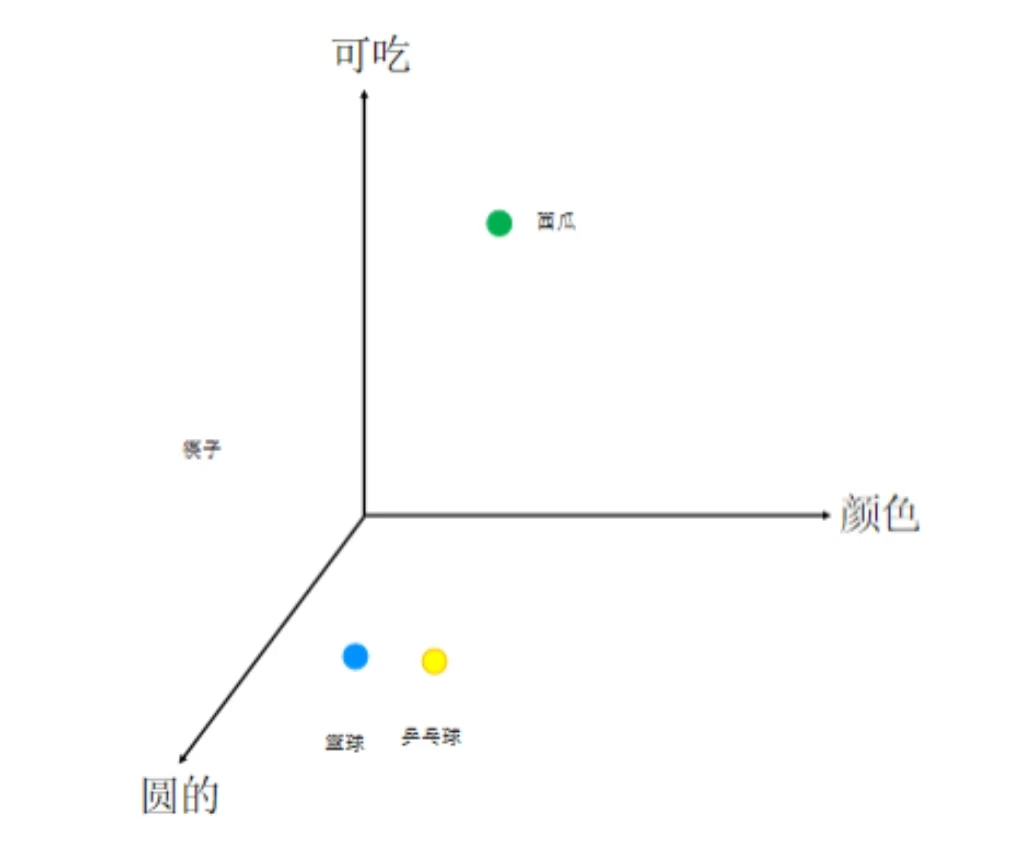
具体再比如之前的"我爱自然语言处理",放进神经网络模型训练后数据为:
python
我: [0.62, 0.12, 0.01, 0, 0, 0, 0..........0]
爱: [0.1, 0.12, 0.001, 0, 0, 0, 0..........0]
自然: [0, 0.01, 0.392, 0.39, 0, 0, 0..........0]
语言: [0, 0.1, 001, 0.123, 0.35, 0, 0..........0]
处理: [0.42, 0.28, 0.01, 0.37, 1, 0, 0..........0]
维度为5×300这时这句话的维度大小就会变成 5×300, 并且维度中的数字已经不再是0和1了,而是一些浮点数。与之前的维度对比,从4960到300,大大减小了特征维度,从而解决唯独灾难问题。
(4) embedding词嵌入
Embedding(嵌入)是一种将高维空间中的对象(如单词、短语、句子等)映射到低维、稠密、连续的向量空间中的技术。在NLP中,Word Embedding(词嵌入)是最常见的嵌入类型,它将词汇表中的每个单词映射到一个固定大小的向量。
词嵌入通过训练神经网络模型(如Word2Vec、GloVe、FastText等)在大量文本数据上学习得到每个单词的向量表示。这些向量能够捕捉单词之间的语义关系,使得在向量空间中相似的单词(如"猫"和"狗")具有相近的表示,而不相关的单词则具有较远的距离。
tText等)在大量文本数据上学习得到每个单词的向量表示。这些向量能够捕捉单词之间的语义关系,使得在向量空间中相似的单词(如"猫"和"狗")具有相近的表示,而不相关的单词则具有较远的距离。如上图中的篮球和乒乓球有相关性,因而距离比较近。对比可知西瓜与它们的相关性就比较小,所以距离比较远。
(5) Word2Vec技术
Word2Vec 是一种用于自然语言处理(NLP)的技术,特别是在将词汇或短语从词汇表映射到向量的实数空间 方面表现出色。这种映射使得相似的词在向量空间中具有较近的距离,从而捕捉到了词汇之间的语义和句法关系 。Word2Vec技术是由Google的研究人员Tomas Mikolov等人在2013年提出的,它主要包括两种训练模型:连续词袋模型(CBOW)和跳字模型(Skip-gram)

连续词袋模型(CBOW)
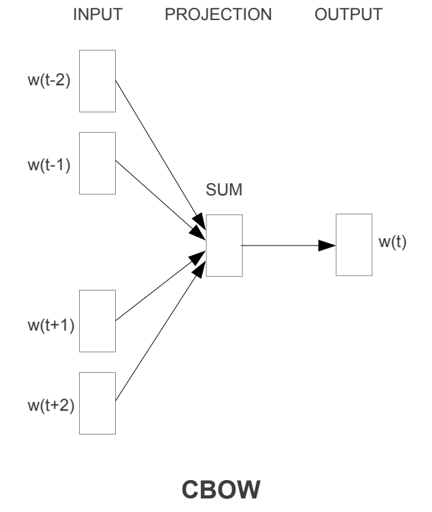
那么,低维度的词是在哪里体现的呢?
我们看模型的训练过程便能得到

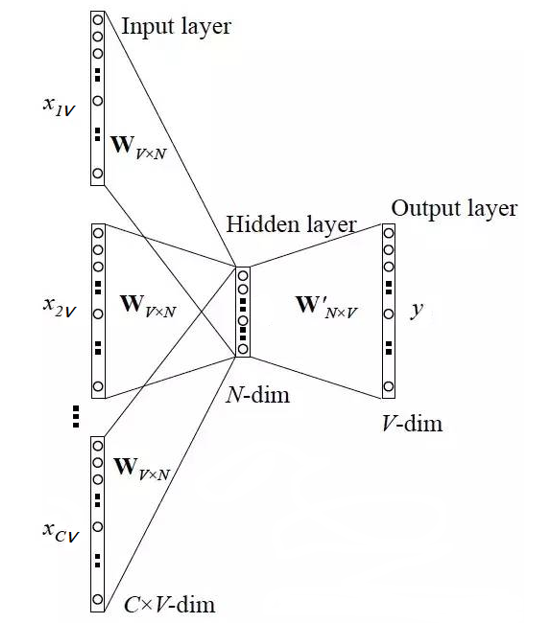
假定语料库中一共有4960个词,则词编码为4960个01组合现在压缩为300维:

如此,便将它特征压缩了,从而将词汇或短语从词汇表映射到向量的实数空间。
跳字模型(Skip-gram)
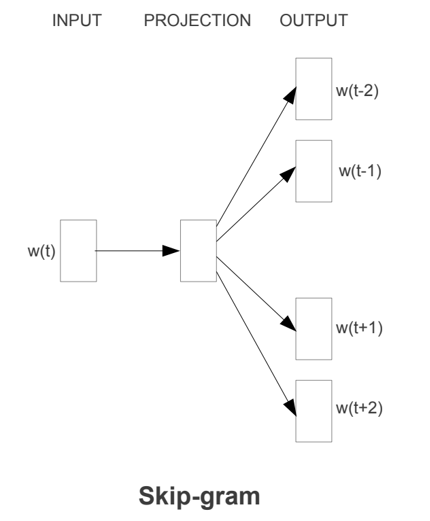
总结
本篇介绍了自然语言处理中,语言转换方法的两个模型:
- 统计语言模型:用于描述和预测自然语言文本中的词汇或句子出现的概率,但是没办法考虑词与词之间内在的联系 且参数空间会出现爆炸式增长的问题。
- 神经语言模型:通过神经网络训练,将每个词都映射到一个较短的词向量上来。将高维映射到低维 。通过embedding词嵌入技术捕捉词句之间的语义。
- Word2Vec技术技术 :有两个模型连续词袋模型(CBOW)和跳字模型(Skip-gram),用来将特征压缩,从而将词汇或短语从词汇表映射到向量的实数空间。