目录
[一、Splash 对象方法(后续)](#一、Splash 对象方法(后续))
[二、Splash HTTP API 调用](#二、Splash HTTP API 调用)
[三、Splash 负载均衡配置](#三、Splash 负载均衡配置)
前言
在网页数据抓取过程中,面对动态渲染的页面,Splash 工具凭借其强大的功能和灵活性,成为了开发者的得力助手。本文将继续上节的讲解,详细介绍 Splash 的对象方法、HTTP API 调用以及负载均衡配置,帮助你更好地利用 Splash 实现高效的页面抓取。
一、Splash 对象方法(后续)
(一)内容与资源操作
- `set_content`:该方法可直接设置页面内容,常用于测试或模拟特定页面结构。
Lua
function main(splash)
assert(splash:set_content("<html><body><h1>hello</h1></body></html>"))
return splash:png()
end运行此脚本会生成包含 `<h1>hello</h1>` 的页面截图。
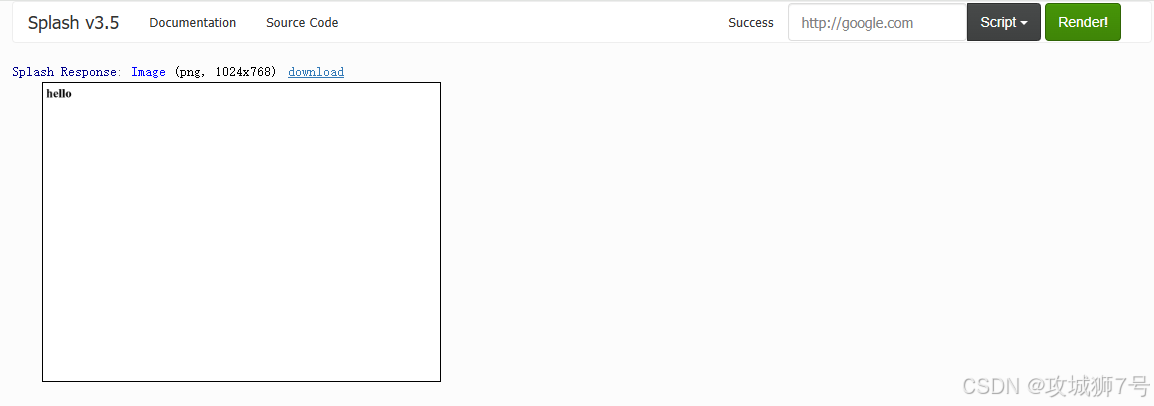
- `html`:用于获取渲染后的页面源代码。
Lua
function main(splash, args)
splash:go("https://httpbin.org/get")
return splash:html()
end返回的是包含请求头、响应数据的 HTML 文本。
- `png`/`jpeg`:分别用于获取页面的 PNG 和 JPEG 格式截图。JPEG 格式还支持设置质量参数。
Lua
-- PNG 截图
function main(splash, args)
splash:go("https://www.taobao.com")
return splash:png()
end
-- JPEG 截图(支持质量参数)
function main(splash, args)
splash:go("https://www.taobao.com")
return splash:jpeg{quality=80}
end- `har`:获取页面加载过程的 HAR 格式日志,包含资源请求详情,如 CSS、JS 等资源的加载时间、状态码等。
Lua
function main(splash, args)
splash:go("https://www.baidu.com")
return splash:har()
end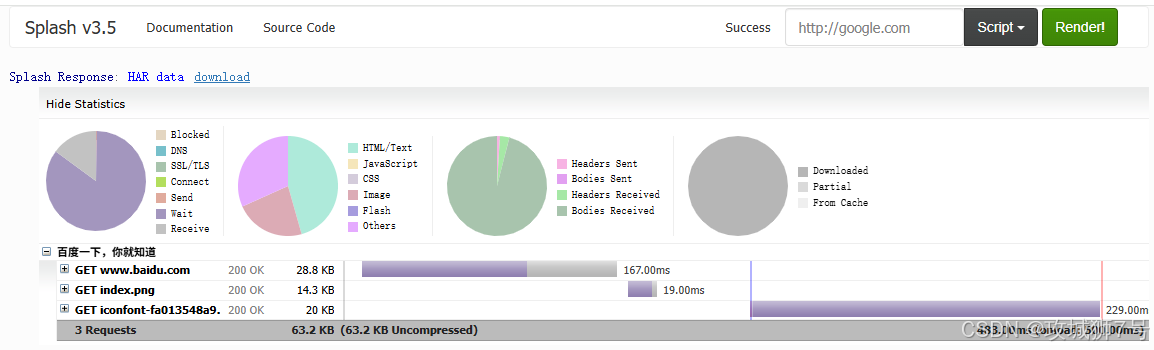
(二)浏览器状态操作
- `url`:获取当前页面的 URL。
Lua
function main(splash, args)
splash:go("https://www.baidu.com")
return splash:url()
end- `get_cookies`/`add_cookie`/`clear_cookies`
- `get_cookies`:获取当前页面的 Cookies。
Lua
function main(splash, args)
splash:go("https://www.baidu.com")
return splash:get_cookies()
end- `add_cookie`:添加自定义 Cookie。
Lua
function main(splash)
splash:add_cookie{
name="sessionid",
value="237465ghgfsd",
path="/",
domain="http://example.com"
}
splash:go("http://example.com/")
return splash:html()
end- `clear_cookies`:清空所有 Cookies。
Lua
function main(splash)
splash:go("https://www.baidu.com/")
splash:clear_cookies()
return splash:get_cookies()
end(三)浏览器配置操作
- `get_viewport_size`/`set_viewport_size`/`set_viewport_full`
- `get_viewport_size`:获取当前视口尺寸(宽高)。
Lua
function main(splash)
splash:go("https://www.baidu.com/")
return splash:get_viewport_size()
end- `set_viewport_size`:设置视口尺寸。
Lua
function main(splash)
splash:set_viewport_size(400, 700)
assert(splash:go("https://linshantang.blog.csdn.net/"))
return splash:png()
end- `set_viewport_full`:设置全屏视口。
Lua
function main(splash)
splash:set_viewport_full()
assert(splash:go("https://linshantang.blog.csdn.net/"))
return splash:png()
end- `set_user_agent`/`set_custom_headers`
- `set_user_agent`:设置请求的 User - Agent。
Lua
function main(splash)
splash:set_user_agent('Splash')
splash:go("http://httpbin.org/get")
return splash:html()
end- `set_custom_headers`:设置任意请求头字段。
Lua
function main(splash)
splash:set_custom_headers{
["User-Agent"] = "Splash",
["Site"] = "Splash"
}
splash:go("http://httpbin.org/get")
return splash:html()
end(四)页面元素操作
- `select`/`select_all`
- `select`:通过 CSS 选择器选取首个匹配元素。
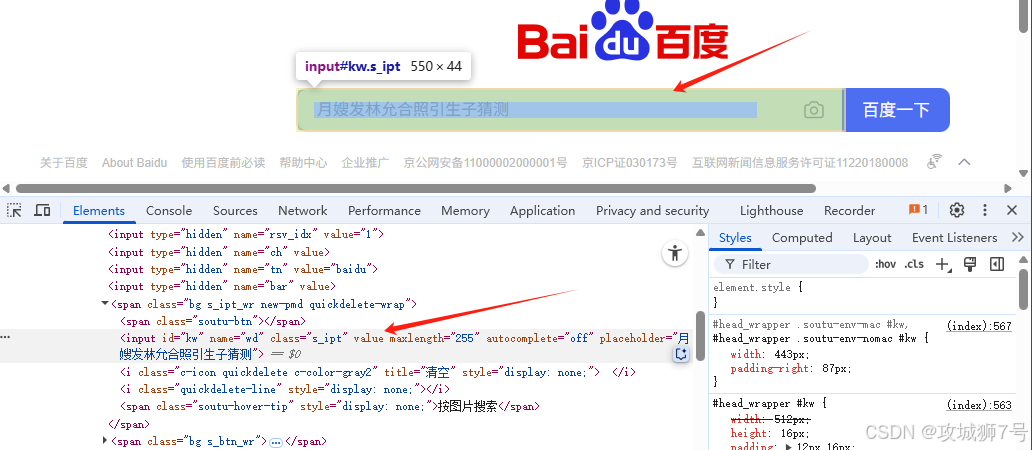
Lua
function main(splash)
splash:go("https://www.baidu.com/")
local input = splash:select("#kw")
input:send_text('Splash')
splash:wait(3)
return splash:png()
end- `select_all`:选取所有匹配元素并遍历。
Lua
function main(splash)
local treat = require('treat')
assert(splash:go("http://quotes.toscrape.com/"))
local texts = splash:select_all('.quote .text')
local results = {}
for index, text in ipairs(texts) do
results[index] = text.node.innerHTML
end
return treat.as_array(results)
end- `mouse_click`:模拟鼠标点击元素,支持坐标或元素对象。
Lua
function main(splash)
splash:go("https://www.baidu.com/")
local input = splash:select("#kw")
input:send_text('Splash')
local submit = splash:select('#su')
submit:mouse_click()
splash:wait(3)
return splash:png()
end二、Splash HTTP API 调用
(一)基础接口:获取渲染结果
- `render.html`:获取渲染后的 HTML 源码。
bash
curl http://localhost:8050/render.html?url=https://www.baidu.com&wait=2
python
import requests
url = "http://localhost:8050/render.html?url=https://www.taobao.com&wait=5"
print(requests.get(url).text)- `render.png`/`render.jpeg`:获取截图,支持尺寸和质量参数。
python
response = requests.get("http://localhost:8050/render.png?url=https://www.jd.com&width=1000&height=700")
with open("jd.png", "wb") as f:
f.write(response.content)
- `render.har`/`render.json`
- `render.har`:获取 HAR 格式的加载日志。
bash
curl http://localhost:8050/render.har?url=https://www.jd.com&wait=5
- `render.json`**:获取综合 JSON 数据,支持 `html`、`png`、`har` 等参数。
bash
curl http://localhost:8050/render.json?url=https://httpbin.org&html=1&har=1(二)高级接口:执行 Lua 脚本
`execute`:通过 URL 传递 Lua 脚本,实现复杂交互逻辑。
bash
curl "http://localhost:8050/execute?lua_source=$(echo 'function main(splash) return \"hello\" end' | urlencode)"
python
import requests
from urllib.parse import quote
lua_script = """
function main(splash, args)
local response = splash:http_get("http://httpbin.org/get")
return {status=response.status, url=response.url}
end
"""
url = f"http://localhost:8050/execute?lua_source={quote(lua_script)}"
print(requests.get(url).json())(三)核心优势与适用场景
- 优势
-
异步处理提升效率,支持分布式部署。
-
轻量级架构,资源占用低于 Selenium。
-
灵活的 Lua 脚本控制,支持复杂交互。
- 场景
-
动态数据抓取(如电商价格、社交媒体动态)。
-
单页应用(SPA)爬取。
-
性能分析与资源加载优化。
三、Splash 负载均衡配置
(一)准备多个 Splash 服务节点
当爬取任务量较大时,单节点 Splash 服务可能面临性能瓶颈。此时需要搭建负载均衡集群,将请求分发到多个 Splash 实例。示例中使用 4 个节点,服务地址分别为 41.159.27.223:8050、41.159.27.221:8050、41.159.27.9:8050 和 41.159.117.119:8050,通过 Docker 运行 Splash 镜像启动服务,确保各节点服务完全一致。
(二)配置 Nginx 负载均衡器
选择一台具有公网 IP 的主机作为负载均衡节点,安装并配置 Nginx。修改 Nginx 配置文件 `nginx.conf`,在 `http` 块中定义上游服务集群(`upstream`),可根据不同场景选择不同的负载均衡策略。
- 最少连接数(`least_conn`):适用于请求处理时间不均的场景,优先分配给当前连接数最少的节点。
nginx配置:
bash
http {
upstream splash_cluster {
least_conn;
server 41.159.27.223:8050;
server 41.159.27.221:8050;
server 41.159.27.9:8050;
server 41.159.117.119:8050;
}
server {
listen 8050;
location / {
proxy_pass http://splash_cluster;
}
}
}- 轮询(默认策略):无状态且服务器配置相同时使用,请求按顺序均匀分配。
nginx 配置:
bash
upstream splash_cluster {
server 41.159.27.223:8050;
server 41.159.27.221:8050;
server 41.159.27.9:8050;
server 41.159.117.119:8050;
}- 权重分配(`weight`):根据服务器性能分配请求比例,`weight` 越高分配越多。
nginx 配置:
bash
upstream splash_cluster {
server 41.159.27.223:8050 weight=4;
server 41.159.27.221:8050 weight=2;
server 41.159.27.9:8050 weight=2;
server 41.159.117.119:8050 weight=1;
}- IP 散列(`ip_hash`):根据客户端 IP 地址哈希分配,确保同一客户端始终访问同一节点,适用于有状态服务。
nginx 配置:
bash
upstream splash_cluster {
ip_hash;
server 41.159.27.223:8050;
server 41.159.27.221:8050;
server 41.159.27.9:8050;
server 41.159.117.119:8050;
}配置完成后,执行 `sudo nginx -s reload` 重新加载配置。访问 Nginx 服务器的 8050 端口,请求将自动分发到后端 Splash 节点。
(三)配置访问认证(可选)
为避免公开访问,可通过 Nginx 配置 Basic Auth 认证。在 `server` 块的 `location` 中添加认证字段:
nginx 配置:
bash
server {
listen 8050;
location / {
proxy_pass http://splash_cluster;
auth_basic "Restricted Access";
auth_basic_user_file /etc/nginx/conf.d/.htpasswd;
}
}使用 `htpasswd` 工具生成用户密码:
bash
sudo apt-get install apache2-utils
htpasswd -c /etc/nginx/conf.d/.htpasswd admin按提示输入密码,生成 `.htpasswd` 文件。执行 `sudo nginx -s reload` 使认证生效,访问时需提供用户名和密码。
(四)负载均衡测试
通过代码验证请求是否均匀分发到不同 Splash 节点。
python
import requests
import re
from urllib.parse import quote
lua_script = """
function main(splash, args)
local response = splash:http_get("http://httpbin.org/get")
return response.body
end
"""
nginx_ip = "192.168.1.100"
url = f"http://{nginx_ip}:8050/execute?lua_source={quote(lua_script)}"
response = requests.get(url, auth=("admin", "your-password"))
ip = re.search(r'"origin": "(\d+\.\d+\.\d+\.\d+)"', response.text).group(1)
print(f"当前请求节点 IP:{ip}")多次运行脚本,输出的 `ip` 应随机或按策略分布在不同 Splash 节点,证明负载均衡生效。
(五)总结
负载均衡配置具有分散单节点压力、提升并发处理能力、支持动态扩展节点数量以及结合 Nginx 实现高可用性和灵活策略等优势。但需注意确保所有 Splash 节点配置一致,根据业务场景选择合适的负载均衡策略,生产环境建议搭配监控工具实时监测节点状态。
通过以上介绍的 Splash 对象方法、HTTP API 调用以及负载均衡配置,开发者可以结合 Python 和 Splash 实现高效的动态页面抓取,满足从简单渲染到复杂交互的各类需求。同时,官方文档 Splash Lua API 文档(https://splash.readthedocs.io/en/stable/scripting-ref.html)、页面元素操作指南(https://splash.readthedocs.io/en/stable/scripting-element-object.html) 和 HTTP API 详细说明(https://splash.readthedocs.io/en/stable/api.html) 提供了更详细和权威的信息,可进一步参考。