序列建模的演进之路
一、RNN( Recurrent Neural Networks):序列处理的开拓者
循环神经网络(RNN)是最早处理序列数据的深度学习结构。RNN的核心思想是在处理序列的每个时间步时保持一个"记忆"状态。
python
h_t = tanh(W_x * x_t + W_h * h_{t-1} + b)这里,h_t是当前时间步的隐藏状态,x_t是当前输入,而h_{t-1}是上一时间步的隐藏状态。这种结构允许RNN理论上能够捕获任意长度的上下文信息。
局限性:然而,由于梯度消失问题,普通RNN很难学习长距离依赖。随着序列长度增加,早期输入的信息会迅速衰减或爆炸。
RNN的深层原理解析
RNN的核心思想是将序列信息压缩到一个固定维度的向量中。从计算图的角度看,
RNN可以展开成一个深层前馈网络,每一层对应序列的一个时间步:
#####RNN 的"循环"机制详解
RNN 的精髓在于:循环地使用相同的网络结构来处理序列中的每一个元素。
比如处理一句话 "我 → 爱 → AI":
-
第一步:读到"我",生成 h₁(初始状态 h₀ 为0)
-
第二步:读到"爱",用"我"的状态 h₁ + "爱"作为输入
-
第三步:读到"AI",继续传播状态...
这个机制就像人类阅读------当前词的理解,受到前面词语的影响。x_1 → RNN → h_1 → RNN → h_2 → ... → h_n
↑ ↑ ↑
x_1 x_2 x_n
当我们展开这个计算过程并应用反向传播算法时,梯度需要通过所有时间步传播,从而导致两个根本问题:
- 梯度消失:由于重复乘以权重矩阵W_h,如果其特征值小于1,梯度会呈指数衰减
- 梯度爆炸:相反,如果特征值大于1,梯度会呈指数增长
这导致了RNN在实践中面临的两难选择:
- 如果保持稳定的梯度流,就难以学习长距离依赖
- 如果允许梯度自由流动,模型又难以训练稳定
二、LSTM(Long short-term memory networks):记忆的守卫者
🔁 LSTM 的循环图解:
diff
xₜ
↓
+---------------------+
| 输入门 / 遗忘门 / 输出门 |
+---------------------+
↓
cₜ₋₁ →→→→→→→→ cₜ ←(记忆传递)
↓
hₜ → 输出长短期记忆网络(LSTM)通过引入门控机制来解决RNN的梯度问题:
- 输入门:控制新信息添加到单元状态
- 遗忘门:控制丢弃哪些信息
- 输出门:控制输出哪部分单元状态
python
# 遗忘门
f_t = σ(W_f · [h_{t-1}, x_t] + b_f)
# 输入门
i_t = σ(W_i · [h_{t-1}, x_t] + b_i)
# 候选状态
C̃_t = tanh(W_C · [h_{t-1}, x_t] + b_C)
# 单元状态更新
C_t = f_t * C_{t-1} + i_t * C̃_t
# 输出门
o_t = σ(W_o · [h_{t-1}, x_t] + b_o)
# 隐藏状态
h_t = o_t * tanh(C_t)LSTM的设计使其能够更好地处理长期依赖问题,但序列处理本质上仍是顺序的,这限制了并行计算能力。
LSTM的信息流与梯度路径
LSTM通过细胞状态(cell state)C_t提供了一条梯度高速公路(gradient highway)。从数学角度分析,当遗忘门f_t接近1时,梯度可以几乎无损地流过许多时间步:
∂C_t/∂C_{t-k} = ∏_{i=t-k+1}^t f_i
这意味着即使序列很长,重要信息仍可以从早期时间步传递到后面的时间步,同时允许模型有选择地丢弃不相关信息。
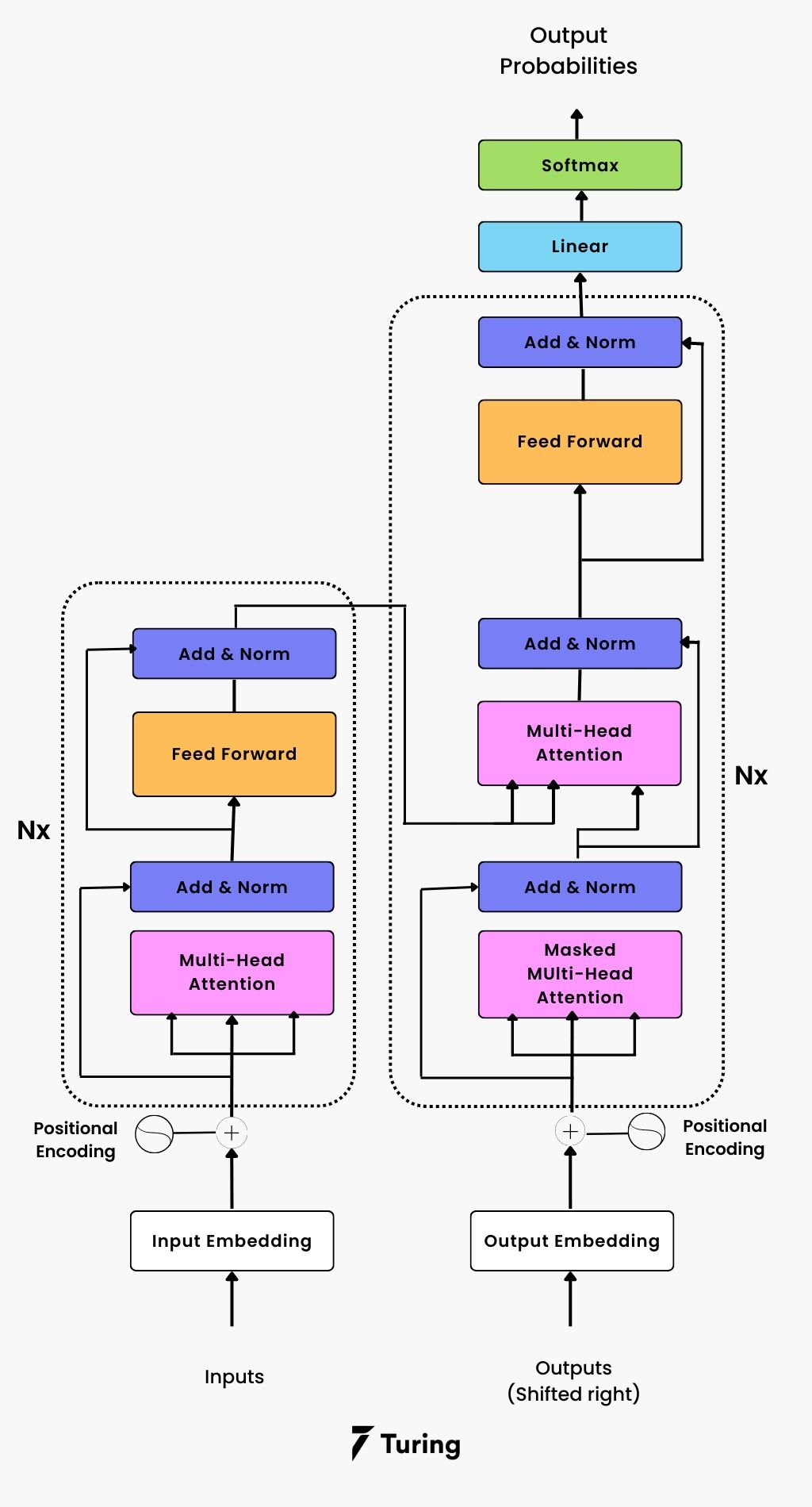
三、Transformer:注意力改变一切
2017年,Google提出的论文《Attention Is All You Need》引入了Transformer架构,彻底改变了序列建模范式。
核心创新:摒弃了递归结构,完全依赖注意力机制并行处理序列。
3.1、Transformer的设计哲学
Transformer架构的设计体现了几个关键思想:
- 并行计算优先:放弃顺序处理,使模型能够大规模并行训练
- 全局上下文访问:每个位置都可以直接访问所有其他位置
- 模块化与层次化:通过堆叠相同的组件构建深层网络
- 可解释性:注意力权重提供了模型决策过程的直观解释
这些设计选择使得Transformer不仅性能优越,而且在计算效率和可扩展性方面都超越了RNN类模型。
核心原理图:
Self-Attention:长依赖问题的解决方案
直接建立全局连接
Self-Attention机制允许序列中的每个元素直接关注序列中的所有其他元素,
从而建立全局依赖关系。
数学表达
- 首先,对每个输入向量计算三种不同的投影:Query(Q)、Key(K)和Value(V)
python
Q = X·W^Q
K = X·W^K
V = X·W^V- 计算注意力分数并应用Softmax获取权重
python
Attention(Q, K, V) = softmax(QK^T/√d_k)·V其中√d_k是缩放因子,防止梯度过大。
为什么Self-Attention解决了长依赖问题?
- 并行计算:不像RNN需要顺序处理,Self-Attention可以并行计算所有位置
- 路径长度恒定:任意两个位置之间的信息传递只需一步操作
- 加权求和:通过自适应权重聚合所有位置的信息
Self-Attention的计算复杂度分析
对于长度为n的序列和维度为d的特征,Self-Attention的计算复杂度为:
- 时间复杂度:O(n²·d),主要来自于计算注意力矩阵QK^T
- 空间复杂度:O(n²),需要存储n×n的注意力权重矩阵
虽然RNN的复杂度为O(n·d²),对较长序列看似更有优势,但Self-Attention具有两个关键优点:
- 并行计算:RNN必须顺序计算n步,而Self-Attention可以一次性计算
- 优化友好:矩阵乘法高度优化,在现代GPU/TPU上执行效率远高于递归操作
注意力机制的信息论解释
从信息论角度看,Self-Attention可以理解为一种自适应信息流控制机制。
如果将输入序列视为信息源,注意力权重可以看作是一种动态路由策略,根据当前查询(query)将信息从相关位置(key)传递到当前位置。
这种机制的信息熵(entropy)远低于固定模式的信息传递(如RNN),因为它可以根据内容自适应地选择信息流路径。
多头注意力(Multi-Head Attention)的深层原理
多头注意力是Self-Attention的一个关键扩展,其核心思想是允许模型同时在不同表示子空间中学习不同类型的关系模式:
python
MultiHead(Q, K, V) = Concat(head_1, head_2, ..., head_h)·W^O
where head_i = Attention(Q·W_i^Q, K·W_i^K, V·W_i^V)多头机制可以从多个角度解释:
- 集成学习视角:每个头可以看作是一个独立的"弱学习器",共同形成一个"强学习器"
- 特征工程视角:不同的头学习捕获不同类型的特征和关系
- 优化视角:多头结构提供了更丰富的梯度流路径,减轻了优化困难
- 表示学习视角:增加了模型的表达能力,可以捕获更复杂的序列模式
实验表明,在Transformer中,不同的注意力头确实学习到了不同类型的语言关系,包括:
- 语法依赖关系
- 共指关系
- 语义相似性
- 实体关系
- 层次结构关系
Transformer架构概览
Transformer由编码器和解码器组成:
编码器
- 多头自注意力层:允许模型同时关注不同位置的不同表示子空间
- 前馈神经网络:对每个位置独立应用相同的FFN
- 残差连接与层归一化:稳定训练并促进梯度流动
解码器
- 多头自注意力层:处理已生成的输出序列
- 多头交叉注意力层:将解码器的查询与编码器的键和值结合
- 前馈神经网络:与编码器类似
位置编码
由于Self-Attention没有序列位置的概念,Transformer引入位置编码:
PE_(pos,2i) = sin(pos/10000^(2i/d_model))
PE_(pos,2i+1) = cos(pos/10000^(2i/d_model))Transformer编码器的深度解析
Transformer编码器由N个相同的层堆叠而成,每个层包含两个子层:
- 多头自注意力层
- 前馈神经网络
每个子层都应用了残差连接和层归一化:
python
LayerNorm(x + Sublayer(x))这种设计使得信息可以在不同层之间有效流动,减轻了深层网络训练的困难。
前馈神经网络(FFN)的作用
FFN子层是Transformer中常被忽视但非常重要的组件:
python
FFN(x) = max(0, x·W_1 + b_1)·W_2 + b_2从功能角度看,FFN可以理解为:
- 特征变换:将注意力机制获得的上下文信息进一步变换
- 非线性引入:通过ReLU激活函数引入非线性,增强模型表达能力
- 参数容量:FFN通常占据模型大部分参数,提供了主要的模型容量
层归一化(Layer Normalization)的重要性
层归一化对每个样本独立地进行归一化处理:
python
LayerNorm(x) = γ · (x - μ) / (σ + ε) + β这一操作带来几个关键好处:
- 稳定训练过程,允许使用更高的学习率
- 减少内部协变量偏移(internal covariate shift)
- 使模型对输入规模不敏感
- 帮助梯度平稳流动,尤其在与残差连接结合时
Transformer解码器的特殊设计
解码器在编码器基础上增加了一个关键组件:掩码自注意力(Masked Self-Attention)。
掩码自注意力通过在注意力分数矩阵中添加一个掩码,确保位置i只能关注位置0到i-1的信息:
python
Mask = np.triu(np.ones((seq_len, seq_len)), k=1) * (-1e9)
Attention = softmax((QK^T/√d_k) + Mask)·V这一设计使得解码器成为一个自回归(autoregressive)模型,适合生成任务。解码器还包含交叉注意力层,将解码器的查询与编码器的键和值结合,实现编码器-解码器的信息流动。
🧪 Self-Attention可视化实现
下面我们用PyTorch实现一个简单的Self-Attention模块并可视化其注意力权重:
python
import streamlit as st
import torch
import torch.nn as nn
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
# ===== Self-Attention 模块 =====
class SelfAttention(nn.Module):
def __init__(self, embed_size, heads):
super(SelfAttention, self).__init__()
self.embed_size = embed_size
self.heads = heads
self.head_dim = embed_size // heads
assert self.head_dim * heads == embed_size, "Embed size needs to be divisible by heads"
self.values = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.keys = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.queries = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.fc_out = nn.Linear(heads * self.head_dim, embed_size)
def forward(self, values, keys, query):
N = query.shape[0]
value_len, key_len, query_len = values.shape[1], keys.shape[1], query.shape[1]
# 多头分割
values = values.reshape(N, value_len, self.heads, self.head_dim)
keys = keys.reshape(N, key_len, self.heads, self.head_dim)
query = query.reshape(N, query_len, self.heads, self.head_dim)
values = self.values(values)
keys = self.keys(keys)
queries = self.queries(query)
energy = torch.einsum("nqhd,nkhd->nhqk", [queries, keys])
attention = torch.softmax(energy / (self.head_dim ** 0.5), dim=3)
self.attention_weights = attention.detach().cpu().numpy()
out = torch.einsum("nhql,nlhd->nqhd", [attention, values])
out = out.reshape(N, query_len, self.heads * self.head_dim)
out = self.fc_out(out)
return out
# ===== Streamlit 界面 =====
st.title("🧠 Multi-Head Self-Attention 可视化")
st.markdown("输入一个句子,查看每个 Attention Head 的注意力分布。")
sentence = st.text_input("输入一句话(空格分词)", "The cat sat on the mat")
embed_size = st.sidebar.slider("嵌入维度 (embed_size)", 64, 512, 256, step=64)
heads = st.sidebar.slider("注意力头数 (heads)", 1, 8, 4)
tokens = sentence.strip().split()
seq_len = len(tokens)
if seq_len < 2:
st.warning("请输入至少两个词。")
st.stop()
model = SelfAttention(embed_size, heads)
x = torch.randn(1, seq_len, embed_size) # 模拟输入
with torch.no_grad():
_ = model(x, x, x)
# ===== 可视化 Attention Head =====
st.subheader("🎯 注意力热图")
fig, axes = plt.subplots(1, heads, figsize=(4 * heads, 4))
if heads == 1:
axes = [axes]
for h in range(heads):
attn = model.attention_weights[0, h]
ax = axes[h]
sns.heatmap(attn, ax=ax, cmap="viridis", xticklabels=tokens, yticklabels=tokens)
ax.set_title(f"Head {h+1}")
ax.set_xlabel("Keys")
ax.set_ylabel("Queries")
st.pyplot(fig)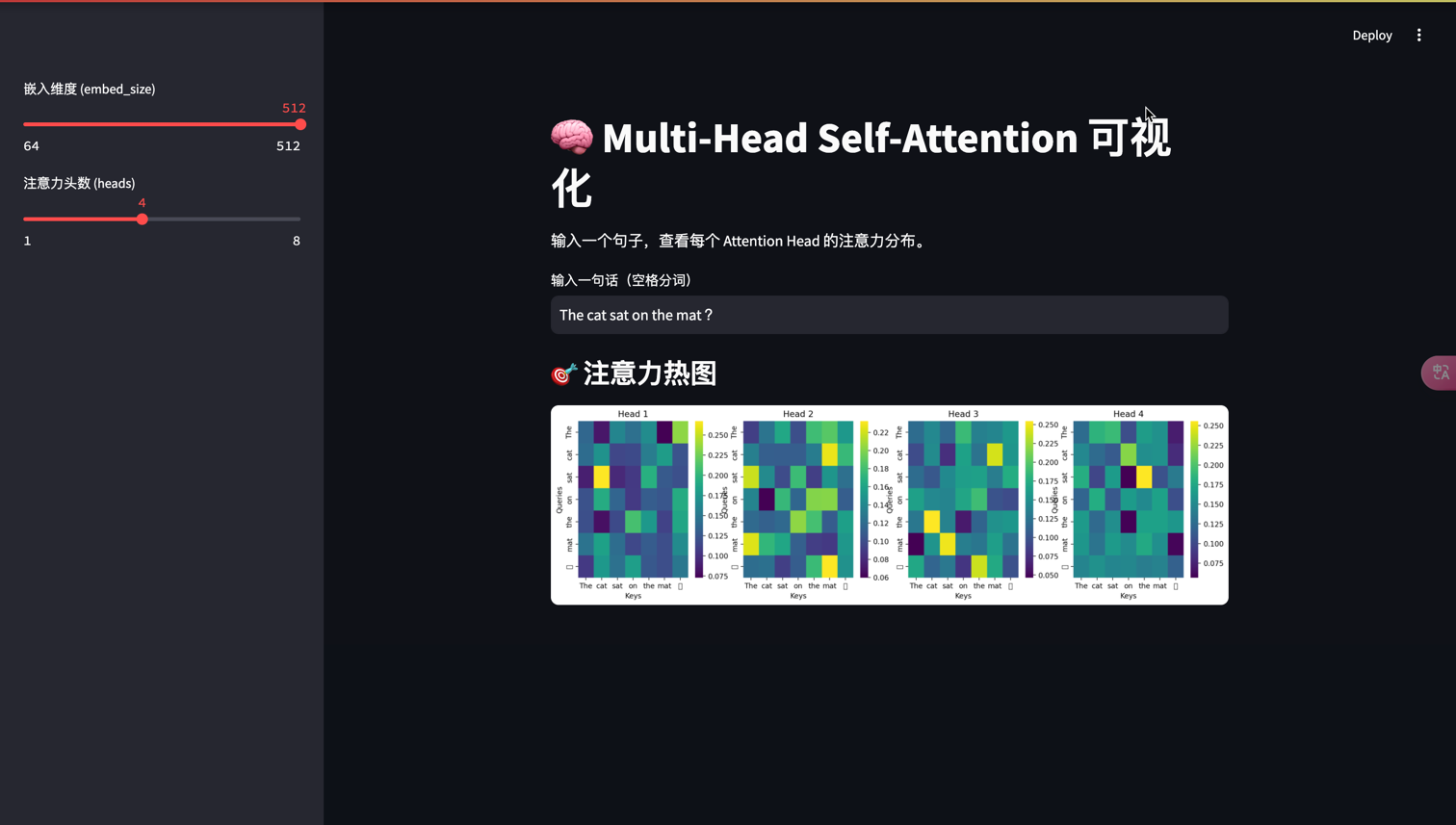
Self-Attention代码解析
我们的实现包含了Self-Attention的核心组件,让我们逐步分析其工作原理:
-
初始化:创建Q、K、V的线性投影和输出的全连接层
pythonself.values = nn.Linear(self.head_dim, self.head_dim, bias=False) self.keys = nn.Linear(self.head_dim, self.head_dim, bias=False) self.queries = nn.Linear(self.head_dim, self.head_dim, bias=False) self.fc_out = nn.Linear(heads * self.head_dim, embed_size) -
多头分割:将输入张量分割成多个头
pythonvalues = values.reshape(N, value_len, self.heads, self.head_dim)这使得每个头可以专注于学习不同类型的关系。
-
注意力分数计算:使用爱因斯坦求和约定高效计算注意力分数
pythonenergy = torch.einsum("nqhd,nkhd->nhqk", [queries, keys])einsum允许我们以简洁方式表达复杂的张量运算,大大提高代码可读性。 -
缩放与Softmax:缩放注意力分数并应用Softmax
pythonattention = torch.softmax(energy / (self.head_dim ** (1/2)), dim=3)缩放因子防止梯度在大维度下消失。
-
加权聚合:使用注意力权重聚合Value值
pythonout = torch.einsum("nhql,nlhd->nqhd", [attention, values])这是Self-Attention的核心步骤,每个位置通过加权组合获得上下文信息。
-
拼接与线性变换:合并多头注意力结果
pythonout = out.reshape(N, query_len, self.heads * self.head_dim) out = self.fc_out(out)将多头结果拼接并通过线性变换映射回原始维度。
可视化方法解析
visualize_attention方法展示了不同注意力头的权重分布:
python
def visualize_attention(self, words=None):
# ... existing code ...通过热力图,我们可以直观观察到:
- 哪些单词之间有强相互作用
- 不同注意力头关注的不同模式
- 模型如何捕获句法和语义关系
完整Transformer架构实现
下面我们实现一个完整的Transformer编码器架构,包括多头注意力、前馈网络、残差连接和层归一化:
python
import streamlit as st
import torch
import torch.nn as nn
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
# ===== Self-Attention 模块 =====
class SelfAttention(nn.Module):
# 多头自注意力机制实现
def __init__(self, embed_size, heads):
super(SelfAttention, self).__init__()
self.embed_size = embed_size
self.heads = heads
self.head_dim = embed_size // heads
assert self.head_dim * heads == embed_size, "Embed size needs to be divisible by heads"
# Q, K, V线性变换
self.values = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.keys = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.queries = nn.Linear(self.head_dim, self.head_dim, bias=False)
# 多头输出合并变换
self.fc_out = nn.Linear(heads * self.head_dim, embed_size)
def forward(self, values, keys, query):
N = query.shape[0] # 批次大小
value_len, key_len, query_len = values.shape[1], keys.shape[1], query.shape[1]
# 重塑为多头格式 [批次, 序列长, 头数, 头维度]
values = values.reshape(N, value_len, self.heads, self.head_dim)
keys = keys.reshape(N, key_len, self.heads, self.head_dim)
query = query.reshape(N, query_len, self.heads, self.head_dim)
# 线性投影
values = self.values(values)
keys = self.keys(keys)
queries = self.queries(query)
# 计算注意力分数 (Q·K^T)
energy = torch.einsum("nqhd,nkhd->nhqk", [queries, keys])
# 应用缩放和softmax
attention = torch.softmax(energy / (self.head_dim ** 0.5), dim=3)
# 保存权重用于可视化
self.attention_weights = attention.detach().cpu().numpy()
# 注意力加权求和 (Attention·V)
out = torch.einsum("nhql,nlhd->nqhd", [attention, values])
out = out.reshape(N, query_len, self.heads * self.head_dim)
out = self.fc_out(out)
return out
# ===== Transformer Block =====
class TransformerBlock(nn.Module):
# Transformer基本构建块:自注意力+前馈网络
def __init__(self, embed_size, heads, dropout, forward_expansion):
super(TransformerBlock, self).__init__()
self.attention = SelfAttention(embed_size, heads)
self.norm1 = nn.LayerNorm(embed_size) # 第一层归一化
self.norm2 = nn.LayerNorm(embed_size) # 第二层归一化
# 前馈神经网络
self.feed_forward = nn.Sequential(
nn.Linear(embed_size, forward_expansion * embed_size),
nn.ReLU(),
nn.Linear(forward_expansion * embed_size, embed_size)
)
self.dropout = nn.Dropout(dropout)
def forward(self, value, key, query, mask=None):
# 自注意力计算
attention = self.attention(value, key, query)
# 第一个残差连接
x = self.norm1(attention + query)
x = self.dropout(x)
# 前馈网络
forward = self.feed_forward(x)
# 第二个残差连接
out = self.norm2(forward + x)
out = self.dropout(out)
return out
# ===== Encoder =====
class Encoder(nn.Module):
# Transformer编码器
def __init__(self, src_vocab_size, embed_size, num_layers, heads, device, forward_expansion, dropout, max_length):
super(Encoder, self).__init__()
self.embed_size = embed_size
self.device = device
# 词嵌入和位置编码
self.word_embedding = nn.Embedding(src_vocab_size, embed_size)
self.position_embedding = nn.Embedding(max_length, embed_size)
# 堆叠多层Transformer块
self.layers = nn.ModuleList([
TransformerBlock(embed_size, heads, dropout, forward_expansion)
for _ in range(num_layers)
])
self.dropout = nn.Dropout(dropout)
def forward(self, x, mask=None):
N, seq_length = x.shape
# 生成位置编码
positions = torch.arange(0, seq_length).expand(N, seq_length).to(self.device)
# 词嵌入+位置编码
out = self.word_embedding(x) + self.position_embedding(positions)
out = self.dropout(out)
# 通过每个Transformer层
for layer in self.layers:
out = layer(out, out, out, mask)
return out
# ===== Transformer Encoder 顶层封装 =====
class TransformerEncoder(nn.Module):
# Transformer编码器封装类
def __init__(self, src_vocab_size, embed_size, num_layers, heads, forward_expansion, dropout, max_length, device="cpu"):
super(TransformerEncoder, self).__init__()
self.encoder = Encoder(src_vocab_size, embed_size, num_layers, heads, device, forward_expansion, dropout, max_length)
self.device = device
def forward(self, src, src_mask=None):
src = src.to(self.device)
return self.encoder(src, src_mask)
# ===== Streamlit 页面展示 =====
st.title("📚 Transformer Encoder - 多头注意力可视化")
st.markdown("输入一个句子(以空格分词),查看 Transformer 编码器的注意力图。")
# 用户输入
sentence = st.text_input("输入句子", "The cat sat on the mat")
# 模型参数设置
embed_size = st.sidebar.slider("嵌入维度", 64, 512, 256, step=64)
heads = st.sidebar.slider("注意力头数", 1, 8, 4)
num_layers = st.sidebar.slider("编码器层数", 1, 6, 2)
forward_expansion = st.sidebar.slider("前馈扩展比例", 2, 8, 4)
dropout = st.sidebar.slider("Dropout", 0.0, 0.5, 0.1)
# 处理输入文本
words = sentence.strip().split()
vocab = {word: i + 1 for i, word in enumerate(set(words))} # 词到索引映射
reverse_vocab = {v: k for k, v in vocab.items()}
# 输入校验
if len(words) < 2:
st.warning("请输入不少于两个词。")
st.stop()
# 准备输入数据
x = torch.tensor([[vocab[w] for w in words]])
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 初始化模型
model = TransformerEncoder(len(vocab) + 1, embed_size, num_layers, heads, forward_expansion, dropout, max_length=100, device=device).to(device)
# 前向传播
with torch.no_grad():
_ = model(x.to(device))
# 获取注意力权重
last_attn_layer = model.encoder.layers[-1].attention
attn_weights = last_attn_layer.attention_weights[0] # shape: [heads, seq_len, seq_len]
# 绘制注意力热力图
fig, axes = plt.subplots(1, heads, figsize=(4 * heads, 4))
if heads == 1:
axes = [axes] # 处理单头情况
# 为每个头绘制热力图
for h in range(heads):
ax = axes[h]
sns.heatmap(attn_weights[h], ax=ax, cmap="viridis", xticklabels=words, yticklabels=words)
ax.set_title(f"Head {h+1}")
ax.set_xlabel("Keys")
ax.set_ylabel("Queries")
# 显示图表
st.pyplot(fig)
st.success("🎉 可视化完成!")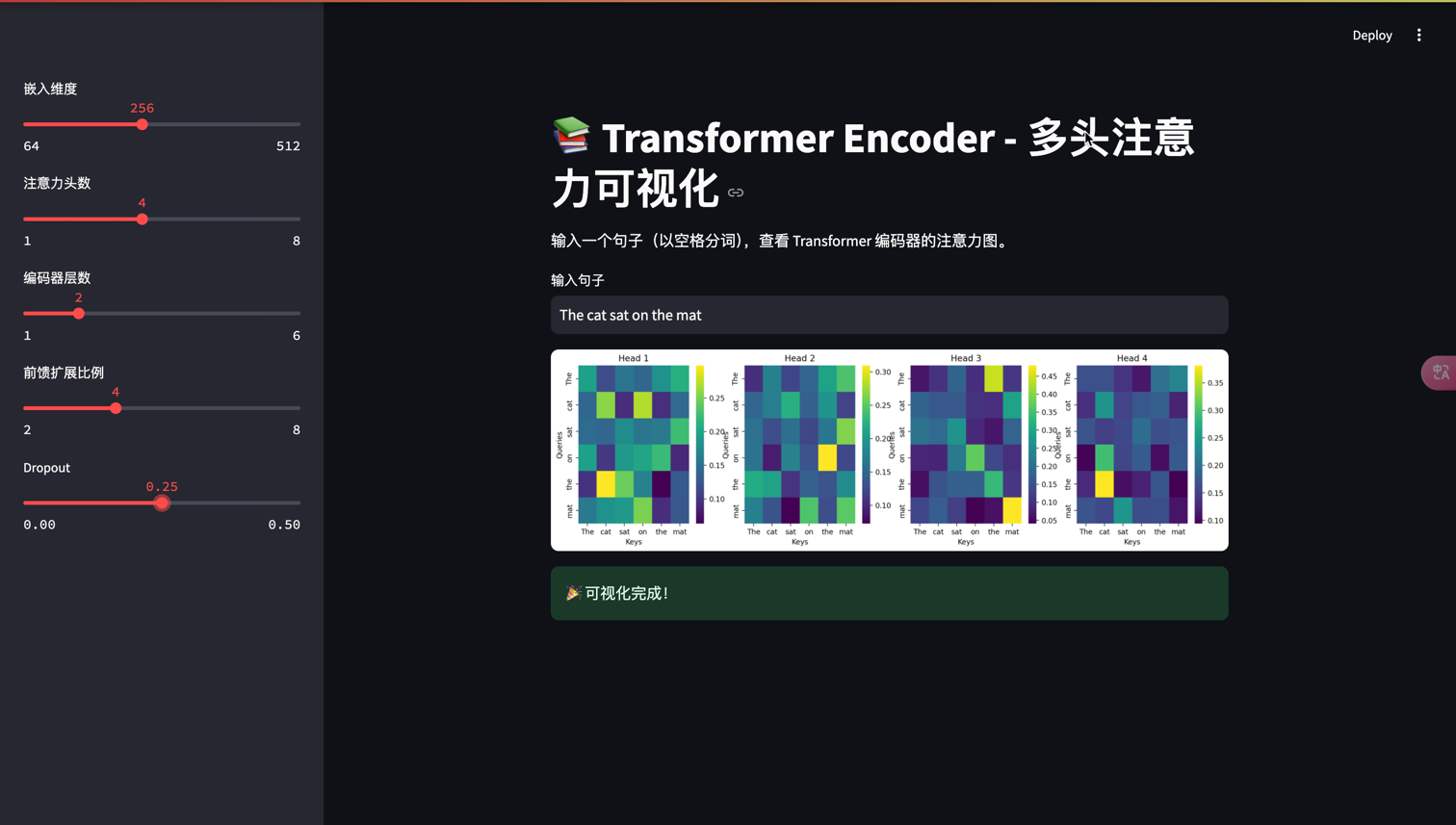
实现要点解析
-
TransformerBlock类实现了注意力层与前馈网络的组合:
- 使用残差连接保持信息流动
- 应用层归一化稳定训练
- 包含dropout降低过拟合风险
-
Encoder类实现了完整的编码器:
- 词嵌入和位置嵌入的组合
- 多个Transformer层的堆叠
- 可选的掩码机制支持
-
位置编码的实现:
pythonpositions = torch.arange(0, seq_length).expand(N, seq_length).to(self.device) out = self.word_embedding(x) + self.position_embedding(positions)虽然原论文使用正弦余弦函数生成位置编码,但可学习的位置嵌入通常在实践中表现更好。
-
多层堆叠:
pythonself.layers = nn.ModuleList([TransformerBlock(...) for _ in range(num_layers)])这种设计允许信息在多个层之间流动,逐步提炼出更复杂的特征表示。
训练与优化技巧
Transformer的训练有许多关键技巧:
-
学习率预热(Warmup):
pythondef get_lr(step, d_model, warmup_steps): return d_model**(-0.5) * min(step**(-0.5), step * warmup_steps**(-1.5))在最初几步使用较小学习率,然后逐步增大,最后按步数的平方根衰减。
-
标签平滑(Label Smoothing):
pythondef loss_with_label_smoothing(logits, targets, smoothing=0.1): log_probs = F.log_softmax(logits, dim=-1) targets = torch.zeros_like(log_probs).scatter_(-1, targets.unsqueeze(-1), 1) targets = (1 - smoothing) * targets + smoothing / logits.size(-1) return -torch.sum(targets * log_probs, dim=-1).mean()通过将硬标签转换为软标签,提高模型泛化能力。
-
梯度裁剪(Gradient Clipping):
pythontorch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)防止梯度爆炸,特别是在训练深层Transformer时。
-
大批量训练(Large Batch Training):使用累积梯度技术模拟大批量训练:
pythonfor i, batch in enumerate(dataloader): outputs = model(batch) loss = criterion(outputs, targets) / accumulation_steps loss.backward() if (i + 1) % accumulation_steps == 0: optimizer.step() optimizer.zero_grad()
小结
从RNN到Transformer的演进代表了序列建模的范式转变:
- RNN依赖顺序处理,难以捕获长距离依赖
- LSTM通过门控机制改善记忆能力,但仍受限于顺序处理
- Transformer利用Self-Attention建立全局连接,彻底解决长依赖问题
Transformer的成功不仅在于其强大的性能,也在于其可并行化的设计,这使得训练更大规模的模型成为可能,
为后续GPT、BERT等大型语言模型奠定了基础。
Transformer的影响与扩展
Transformer架构已经催生了多个重要的模型家族:
- 编码器类模型:以BERT为代表,专注于理解任务
- 解码器类模型:以GPT为代表,专注于生成任务
- 编码器-解码器模型:以T5为代表,适用于翻译、摘要等序列转换任务
这些模型通过预训练-微调范式,在各自领域取得了突破性进展,彻底改变了NLP和其他序列建模任务的研究与应用格局。
在下一讲中,我们将更深入探讨Transformer的架构细节、训练技巧和最新变体,包括Transformer-XL、Reformer等针对长序列建模的优化方案。