目录
[一. JDBC批量添加数据](#一. JDBC批量添加数据)
[1. 什么是批量添加数据](#1. 什么是批量添加数据)
[2. 实现数据的批量添加](#2. 实现数据的批量添加)
[a. 方式一:不分块](#a. 方式一:不分块)
[二. JDBC事务处理](#二. JDBC事务处理)
[1. 什么是事务](#1. 什么是事务)
[2. JDBC事务处理实现](#2. JDBC事务处理实现)
[三. 总结](#三. 总结)
前言
本文来讲解JDBC的批处理和事务处理
这对数据的安全性和准确性以及高效率提供很好的办法
话不多说,即刻发车~
个人主页:艺杯羹
系列专栏:JDBC
一. JDBC批量添加数据
1. 什么是批量添加数据
在JDBC中通过PreparedStatement的对象的addBatch()和executeBatch()方法进行数据的批量插入
- addBatch():把若干SQL语句装载到一起 ,然后一次性传送到数据库执行
即是批量处理sql数据的。做数据的缓存 - executeBatch():会将装载到一起的SQL语句执行
注意:
MySql默认 情况下是不开启批处理的
数据库驱动从5.1.13开始添加了一个对rewriteBatchStatement的参数的处理,该参数能够让MySql开启批处理。在url中添加该参数:rewriteBatchedStatements=true
Mysql的URL参数说明
|--------------------------|-------------------------|------------------------------------|
| 参数名 | 取值范围 | 作用说明 |
| useUnicode | true \| false | 是否使用编码集,需配合 characterEncoding 参数使用 |
| characterEncoding | utf-8 \| gbk \| ... | 编码类型 |
| useSSL | true \| false | 是否使用SSL协议 |
| rewriteBatchedStatements | true \| false | 可以重写向数据库提交的SQL语句(开启批处理) |
这些参数都是添加在如下图的这个 连接数据库的URL当中
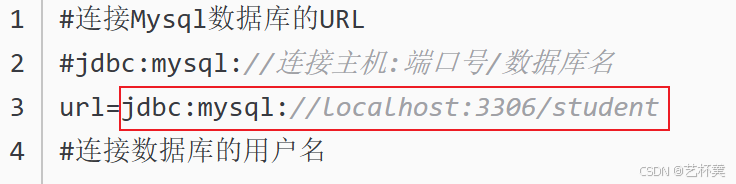
添加参数的格式:使用 ?来开始,之后的元素用 & 来添加
例如:
jdbc:mysql://localhost:8080/students ? useSSL=false**&**rewriteBatchedStatements = true
这样就开启了批处理
2. 实现数据的批量添加
像没有学批处理的话,一般是的思路是,去使用for循环去和数据库交互n次,批量添加1000条数据,就会执行1000次executeUpdate(),交互数据库1000次,交互的次数越多,效率和性能就越低
因此,我们批处理,先进行缓存,最后再进行一个执行,那么这样就和数据库交互的次数就很少了,效率和性能也就随之大大增强了
a. 方式一:不分块
java
public void addBatch1(){
Connection connection = null;
PreparedStatement ps = null;
try{
// 建立连接
connection = JdbcUtils.getConnection();
// 创建PreparedStatement
ps = connection.prepareStatement("insert into students values(default, ?, ?)");
for(int i = 0; i < 100; i++){
// 绑定studentname
ps.setString(1, "studentname"+i);
// 绑定studentage
ps.setInt(2, 18);
// 缓存
ps.addBatch();
}
// 执行sql
ps.executeBatch();
}catch(Exception e){
e.printStackTrace();
}finally{
JdbcUtils.closeResource(ps, connection);
}
}这里批处理是,所有的全部缓存完后才开始执行SQL语句。例如,这里是添加一百个学生信息,那么是一次性添加完,最后来执行。这就是不分块,而是整块
但是如果数据量太大,例如百万条数据,JVM的内存肯定是会耗尽的,为了避免,就可以使用分块的逻辑来写,也就是,到达了某一个数量,就要执行一次addBatch缓存中的数据
b. 方式二:分块
java
public void addBatch1(){
Connection connection = null;
PreparedStatement ps = null;
try{
// 建立连接
connection = JdbcUtils.getConnection();
// 创建PreparedStatement
ps = connection.prepareStatement("insert into students values(default, ?, ?)");
for(int i = 1; i <= 10000; i++){
// 绑定studentname
ps.setString(1, "studentname"+i);
// 绑定studentage
ps.setInt(2, 18);
// 缓存
ps.addBatch();
// 如果缓存了100条数据,就执行
if(i % 100 == 0){
// 执行sql
ps.executeBatch();
//清除缓存
ps.clearBatch();
}
}
}catch(Exception e){
e.printStackTrace();
}finally{
JdbcUtils.closeResource(ps, connection);
}
}二. JDBC事务处理
1. 什么是事务
事务是指作为单个逻辑工作单元执行的一系列操作,要么完全地执行,要么完全地不执行 。
只要有一方出错,都不执行,这样就确保了业务的正确性
事务操作流程:
- 开启事务
- 提交事务
- 回滚事务(撤销)
JDBC中事务处理特点
在JDBC中,使用Connection对象来管理事务,默认为自动提交事务。可以通过setAutoCommit(boolean autoCommit) 方法设置事务是否自动提交,参数为boolean类型,默认值为true,表示自动提交事务,如果值为false则表示不自动提交事务,需要通过commit方法手动提交事务 或者通过rollback方法回滚事务
2. JDBC事务处理实现
注:因为第一篇文章里已经用JDBC工具类里封装了提交和回滚事务的方法,如果不清楚的话,来看第一篇文章
传送门:JDBC
java
public void addBatch1(){
Connection connection = null;
PreparedStatement ps = null;
try{
// 建立连接
connection = JdbcUtils.getConnection();
// 设置事务的提交方式,将自动提交修改为手动提交
connection.setAutoCommit(false);
// 创建PreparedStatement
ps = connection.prepareStatement("insert into students values(default, ?, ?)");
for(int i = 0; i < 100; i++){
// 绑定studentname
ps.setString(1, "studentname"+i);
// 绑定studentage
ps.setInt(2, 18);
// 加入缓存
ps.addBatch();
}
// 提交事务
JdbcUtils.commit(connection);
}catch(Exception e){
e.printStackTrace();
// 如果出现错误就执行回滚数据
JdbcUtils.rollback(connection);
}finally{
JdbcUtils.closeResource(ps, connection);
}
}三. 总结
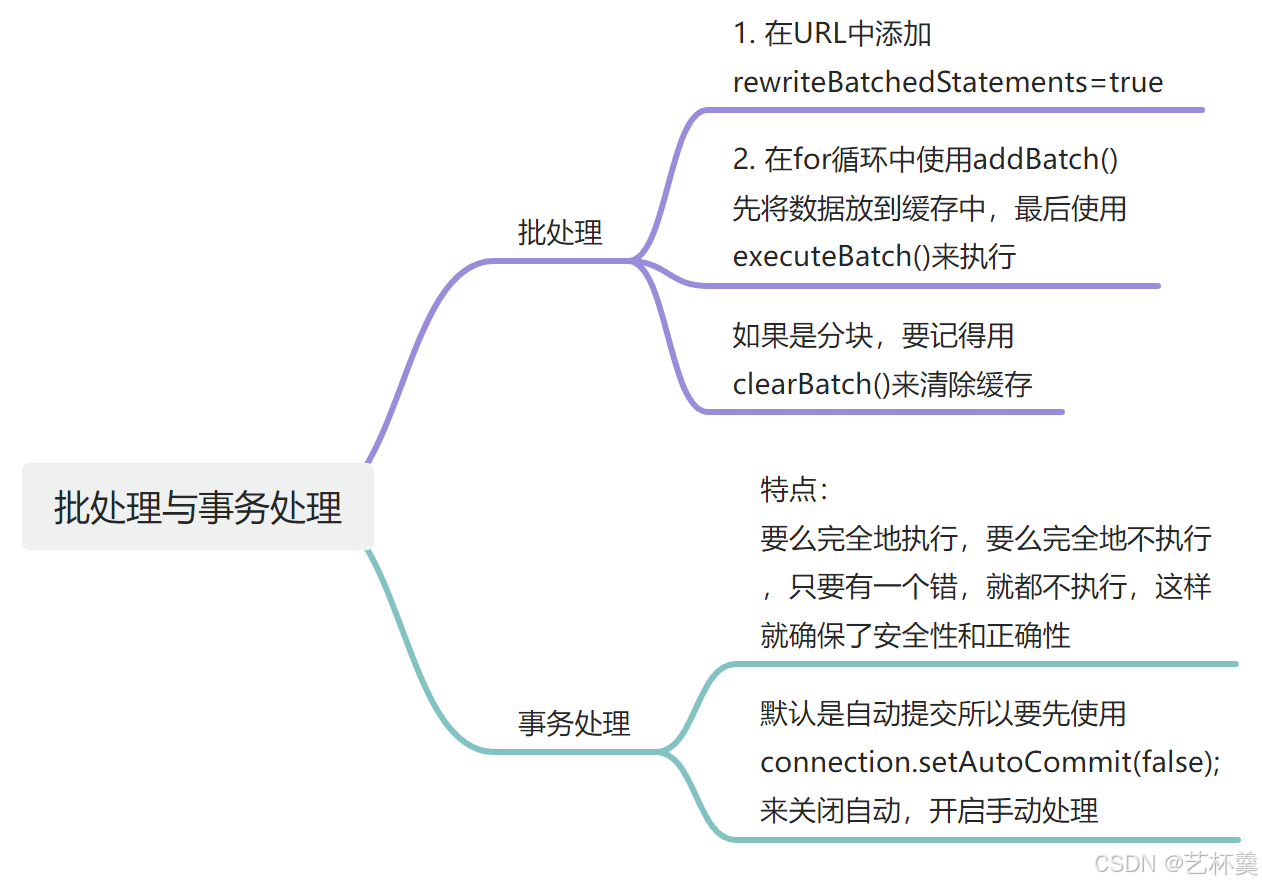
希望本文能够对你有所帮助😊