🚀 封装通用线程池 + Prometheus 可视化任务耗时与成功率(实战记录)
在实际系统开发中,随着业务复杂度的不断提升,简单的同步处理模式往往难以支撑高并发与高可靠性的要求。
为了提升整体性能和系统稳定性,引入异步处理机制,并辅以实时监控体系,成为了常见的工程实践。
本文以审计日志系统为例,分享如何通过封装统一的异步处理服务(AsyncLogService),并结合 Prometheus + Grafana,实现异步任务的规范管理与可观测性保障。
🚀 为什么要封装线程池并做监控?
在我们的审计日志系统中,每次用户请求都会异步写入 MongoDB + Elasticsearch。如果直接在 Kafka 消费线程中完成所有操作,存在几个问题:
- ❌ 主线程被次要流程阻塞:Elasticsearch 写入是辅助操作(相比 MongoDB 写入的重要性较低),直接在 Kafka 消费主线程执行,容易因为 IO 延迟拖慢整体消费速率。
- ❌ 缺乏监控手段:任务失败、延迟情况难以及时发现。
- ❌ 可维护性差:每个模块都需要手动编写线程池执行 + 异常捕获逻辑,重复且容易出错
为了让系统更稳定、更可观察,我们做了两件事:
✅ 封装统一的 AsyncLogService
- 所有异步任务统一通过
AsyncLogService.submit(String taskName, Runnable task)方法提交 - 自动打点:成功次数、失败次数、执行耗时(支持 p95/p99)
✅ 接入 Prometheus + Grafana 可视化
- 实时观察异步任务的执行健康状况
- 快速定位慢任务或异常任务
- 支持基于指标设置自动告警
在实际工程中,我们经常需要将一些耗时较长或 I/O 密集型操作放入线程池中异步处理,以避免阻塞主业务流程。 但如果直接每次手写 executor.execute(() -> { ... }),实现虽然简单,但是:
- 没有完整的异步失败捕获
- 没有成功/失败统计
- 没有耗时监控,很难分析性能问题
因此,我们实现了一套自动打点(MeterRegistry)的通用异步扩展,并搭配 Prometheus + Grafana 实时可视化。
✨ 总体效果
- ✅ 通过统一的
AsyncLogService.submit()方法提交异步任务 - ✅ 自动打点:成功次数,失败次数,耗时指标
- ✅ 支持 p95 / p99 耗时分析
- ✅ Prometheus 抓取 + Grafana 演示
👨💻 实现详细
1. 线程池配置
为了支持异步任务执行,我们首先需要配置一个专用的线程池:
- 使用
ThreadPoolTaskExecutor创建异步线程池 - 设置合理的核心线程数、最大线程数、队列容量
- 给线程设置统一的命名前缀,方便排查问题
- 通过
@Bean注册到 Spring 容器,供AsyncLogService注入使用
下面是具体配置代码:
java
@Configuration
public class AsyncExecutorConfig {
@Bean("logExecutor")
public Executor taskExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(4); // 核心线程数
executor.setMaxPoolSize(8); // 最大线程数
executor.setQueueCapacity(100); // 任务队列容量
executor.setThreadNamePrefix("log-async-"); // 线程名称前缀,便于排查
executor.initialize(); // 初始化线程池
return executor;
}
}2. 封装 AsyncLogService
为了统一管理异步任务、自动打点监控,我们封装了 AsyncLogService:
- 所有异步任务通过
submit(taskName, task)提交 - 自动记录:
- 成功次数 (
_success_total) - 失败次数 (
_failure_total) - 执行耗时(支持 p95/p99 百分位统计)
- 成功次数 (
- 方便 Prometheus 抓取指标,Grafana 可视化分析
下面是具体实现:
java
@Slf4j
@Component
@RequiredArgsConstructor
public class AsyncLogService {
// 引入自定义的线程池
@Qualifier("logExecutor")
private final Executor executor;
// Micrometer 指标收集器
private final MeterRegistry meterRegistry;
public void submit(String taskName, Runnable task) {
executor.execute(() -> {
Timer.Sample sample = Timer.start(meterRegistry);
try {
// 执行真正的业务逻辑
task.run();
// 对成功打点
meterRegistry.counter(taskName + "_success_total").increment();
} catch (Exception e) {
// 对失败打点
meterRegistry.counter(taskName + "_failure_total").increment();
log.error("\u274c Async log task failed", e);
} finally {
// 记录耗时,并支持 p95/p99 百分位分析
sample.stop(
Timer.builder(taskName + "_duration_seconds")
.description("Time taken for async task: " + taskName)
.publishPercentiles(0.5, 0.95, 0.99)
.publishPercentileHistogram()
.register(meterRegistry)
);
}
});
}
}🔥 小总结
AsyncLogService简化了异步任务开发,避免每次手动写线程池执行 + try-catch 异步流程- 默认埋点成功率、失败率、耗时,支持 Prometheus 自动采集
- 后续扩展更多任务监控也很方便,只需统一 submit
3. 使用示例
在 Kafka 消费逻辑中,我们:
- 同步写入 MongoDB(主流程)
- 异步提交 Elasticsearch(副流程,不阻塞主线程)
- Kafka 的 offset 只有在 MongoDB 成功后才提交,确保数据可靠性
- Elasticsearch 异常不会影响主流程,保证高可用性
java
@KafkaListener(
topics = "audit-log-topic",
groupId = "audit-consumer-group",
containerFactory = "kafkaListenerContainerFactory"
)
public void consume(AuditLogEvent event, Acknowledgment ack) {
printLog(event);
try {
// ✅ 1. 保存审计日志到 MongoDB(同步处理)
AuditLogDocument doc = new AuditLogDocument();
doc.setAction(event.getAction());
doc.setEntity(event.getEntity());
doc.setPayload(event.getPayload());
doc.setTimestamp(event.getTimestamp());
auditLogRepository.save(doc);
// ✅ 2. MongoDB 成功后提交 Kafka offset
ack.acknowledge();
log.info("✅ Saved to MongoDB: {}", doc);
// ✅ 3. 将日志异步写入 Elasticsearch(异步处理,不影响主线程)
asyncLogService.submit(LOG_TASK_PREFIX,() -> {
try {
String json = objectMapper.writeValueAsString(event);
Map<String, Object> jsonMap = objectMapper.readValue(json, new TypeReference<>() {
});
IndexRequest<Map<String, Object>> request = IndexRequest.of(b -> b.index("audit-logs").document(jsonMap));
IndexResponse response = elasticsearchClient.index(request);
log.info("✅ Indexed to Elasticsearch with ID: {}", response.id());
} catch (Exception esEx) {
// ❌ Elasticsearch 写入失败,记录日志,但不抛异常影响主流程
log.error("❌ Failed to index to Elasticsearch", esEx);
}
});
} catch (Exception e) {
// ❌ MongoDB 保存失败,抛出异常,Kafka 进行重试或进入死信队列(DLQ)
log.error("❌ MongoDB insert failed - will retry or send to DLQ", e);
throw e;
}
}📊 Prometheus + Grafana 可视化
完整的 Prometheus + Grafana 配置(包括 POM 依赖、application.yml、docker-compose) ,可以参考我之前整理的这篇文章 👉 juejin.cn/post/749553...
然后确保 Docker 环境启动正常,执行:
bash
docker-compose up -d1. 确保 Prometheus 抓取
在 http://localhost:8080/actuator/prometheus 可查看:
ini
# HELP log_task_duration_seconds Time taken for async task: log_task
# TYPE log_task_duration_seconds histogram
log_task_duration_seconds_bucket{application="generator",le="0.001"} 0
log_task_duration_seconds_bucket{application="generator",le="0.001048576"} 0
log_task_duration_seconds_bucket{application="generator",le="0.001398101"} 02. 手动创建三个 Grafana Panel
| 面板 | 表达式 |
|---|---|
| log_task_success_rate | rate(log_task_success_total[1m]) |
| log_task_failure_rate | rate(log_task_failure_total[1m]) |
| log_task_p95_latency | histogram_quantile(0.95, sum by(le) (rate(log_task_duration_seconds_bucket[1m]))) |
🧭 Grafana 操作步骤指引(新手友好)
假设你已经启动了 Prometheus + Grafana 的 docker-compose,可以通过浏览器访问 http://localhost:3000
✅ Step 1: 添加 Prometheus 数据源
- 左侧点击 Connections → Data sources
- 出现 Add new connection
- 在数据源列表中选择 Prometheus ,点击
Add new data source
- 在 URL 一栏填入:
http://prometheus:9090(默认 Docker 网络) - 点击页面底部 「Save & Test」,出现绿色提示表示连接成功 ✅
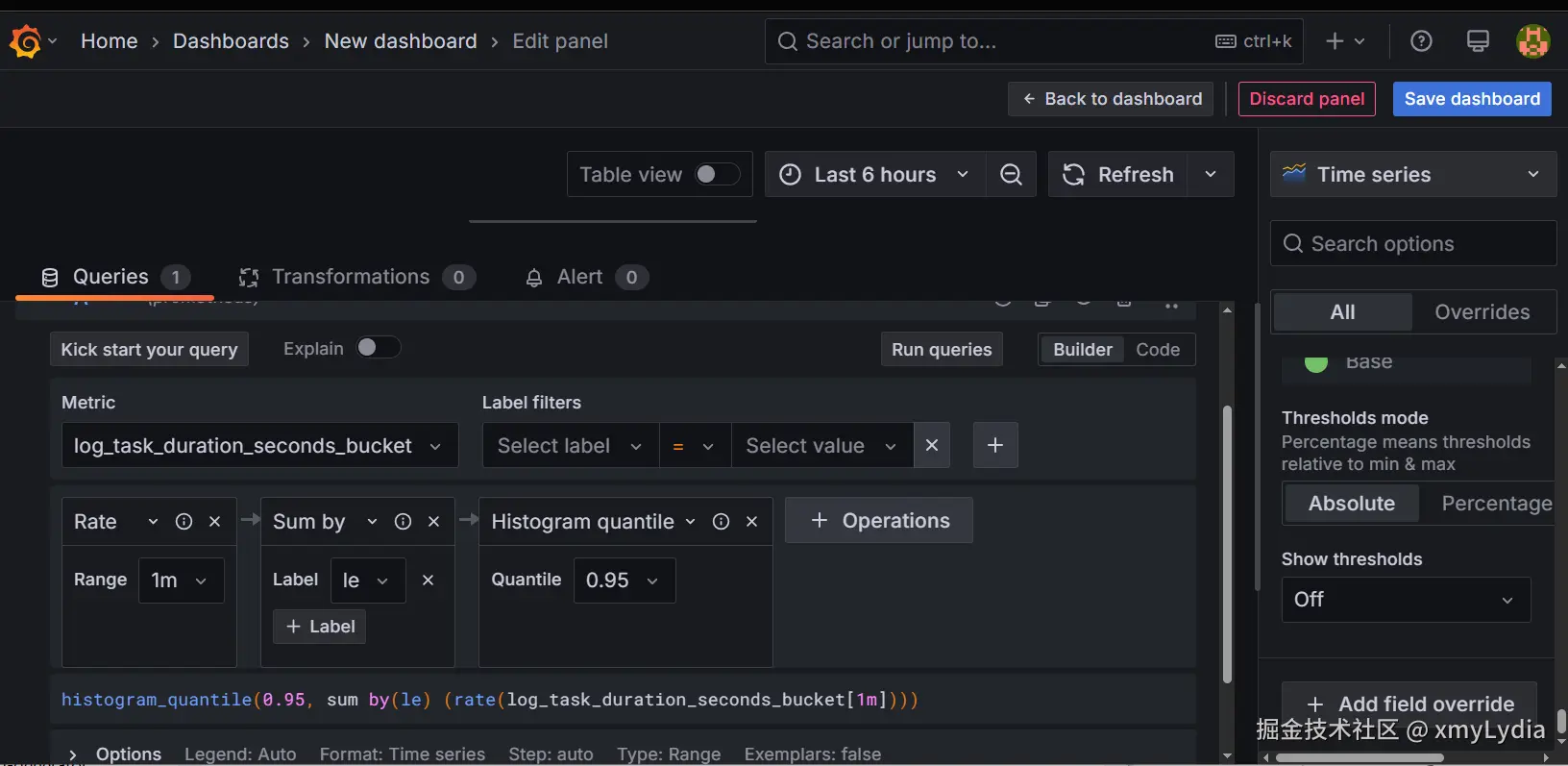
✅ Step 2: 创建 Dashboard 和 Panel
-
左侧菜单点击 📊 Dashboards → New → New Dashboard
-
页面弹出后,点击 「Add visualization」
-
在右侧选择数据源(Data source),如
Prometheus -
在下方 Query 编辑区 :
-
点击 「Kick start your query」
-
选择适合的模板,例如:
Rate query starter(适用于成功率、失败率)Histogram query starter(适用于 p95 耗时)
-
选择 Metric 为:
- ✅ 成功率:
log_task_success_total - ✅ 失败率:
log_task_failure_total - ✅ p95 耗时:
log_task_duration_seconds_bucket
- ✅ 成功率:
-
自动生成的表达式,分别为:
prometheus# 成功率 rate(log_task_success_total[1m]) # 失败率 rate(log_task_failure_total[1m]) # p95 耗时 histogram_quantile(0.95, sum by (le) (rate(log_task_duration_seconds_bucket[1m]))) -
设置查询间隔(Interval)为
1m -
点击 「Run queries」 运行预览
-
-
可视化设置区(右上角)选择图表类型:推荐使用
Time series -
点击右上角 「Apply」 应用面板
-
点击右上角 「Save dashboard」 ,为当前 Dashboard 命名,例如
Async Tasks Metrics -
重复以上步骤,添加多个面板监控不同指标
🎯 小贴士
- 默认抓取间隔为 15s,可以在
prometheus.yml中配置 - 数据量少时,图表可能开始很平静,等待 5~10 分钟更清晰
3. 演示效果例如p95 耗时监控
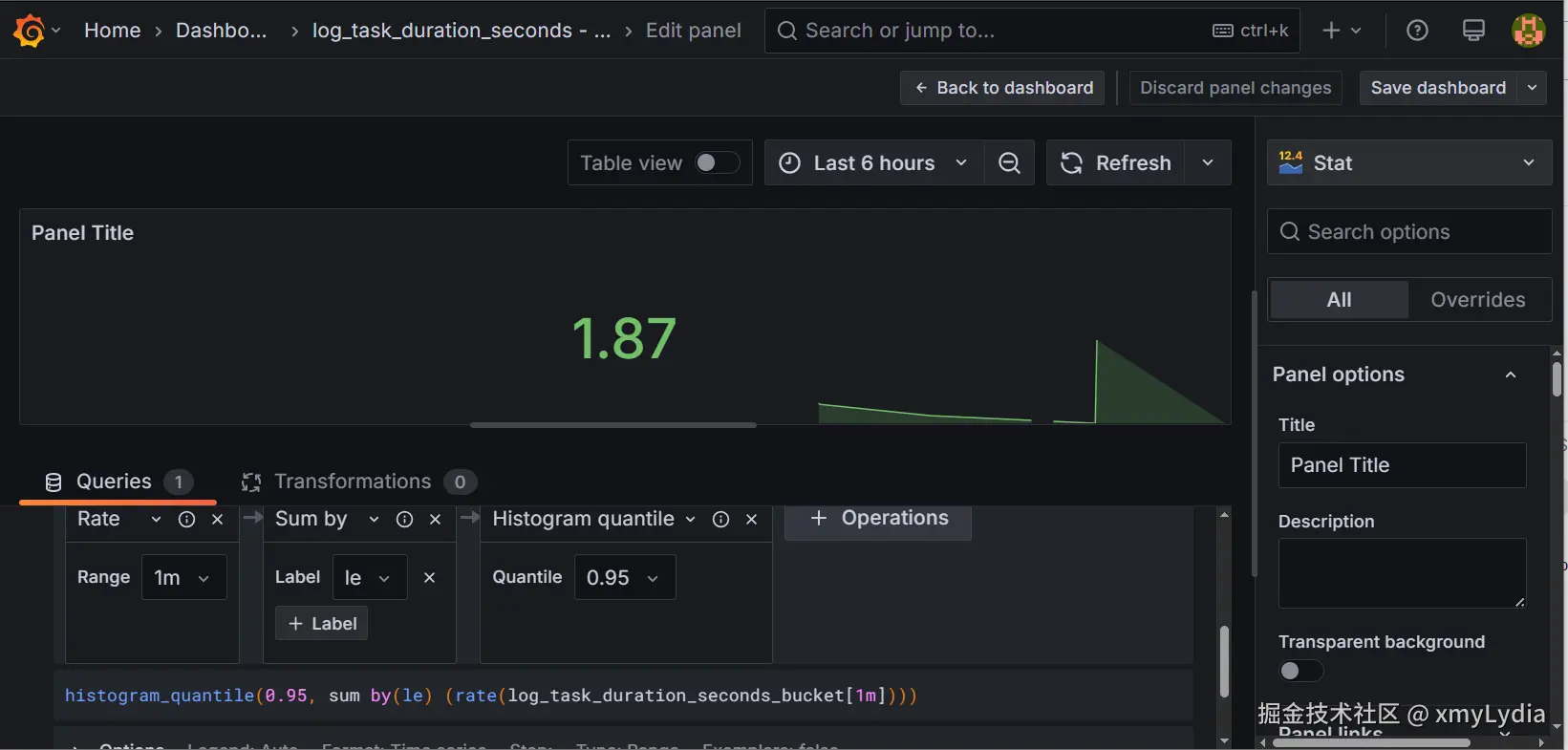
📈 说明:由于初始化数据量少,指标曲线在 Prometheus 中进入稳定趋势通常需要等待约 5 ~ 10 分钟。
🔗 小结
-
通过使用线程池,我们避免了可以异步执行的逻辑被阻塞,增加效率
-
通过封装线程池扩展,我们做到了:
- ✅ 封装异步处理,跨模块处理简单符合规范
- ✅ 失败时有统计,日志有管控
- ✅ 性能指标可视,便于后期分析
- ✅ 通过接入 Prometheus + Grafana,实现异步任务的实时可观测性和异常预警,提升系统稳定性
同时打了好基础,以后做多流程扩展,高并发性能优化,都有整齐工具基础。
💼 项目源码
项目:rapid-crud-generator
- Kafka 异步日志系统
- MongoDB + Elasticsearch 双通道持久化
- Prometheus + Grafana 指标监控
- Swagger UI 自动化
- 一键打包下载 (backend + frontend)
▶️ GitHub:github.com/xmyLydia/ra...
欢迎 Star / Fork / 留言交流!👋