一、理论介绍
1.1、3W 法则
1、是什么?
- Service 是一种为一组功能相同的 pod 提供单一不变的接入点的资源。当 Service 存在时,它的IP地址和端口不会改变。客户端通过IP地址和端口号与 Service 建立连接,这些连接会被路由到提供该 Service 的任意一个pod上。通过这种方式,客户端不需要知道每个单独的pod的地址,这样这些pod就可以在集群中随时被创建或移除。
2、为什么需要?
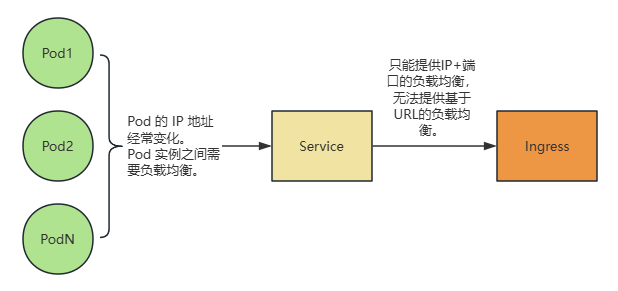
- Pod 的 IP 地址经常变化。
- Pod 的 IP 在集群外无法访问。
- Pod 实例之间的负载均衡。
3、局限性
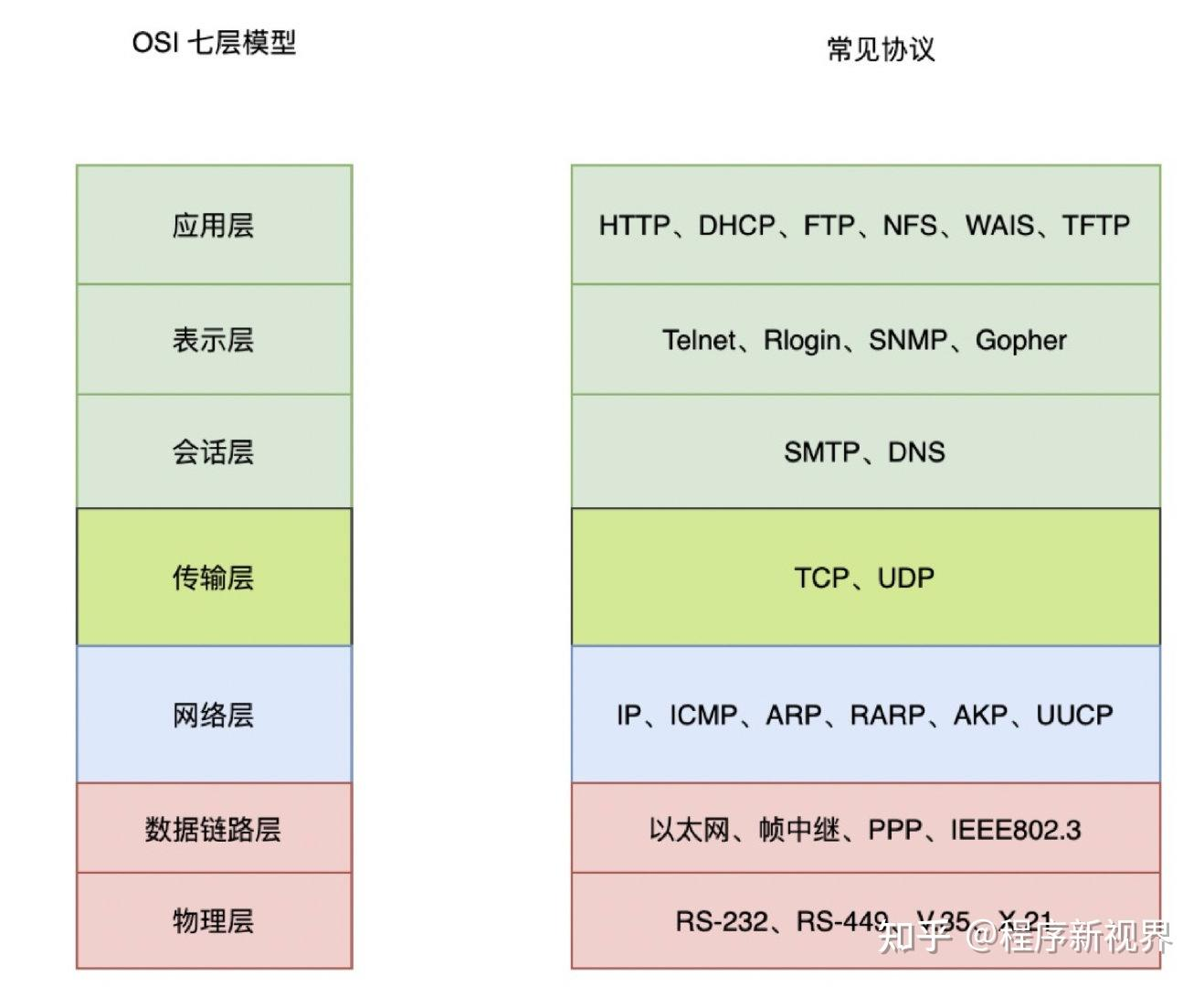
- Service 是一种四层代理。
- 所谓四层,是针对 OSI 七层网络模型来说的。四层对应的是TCP/UDP协议,也就常说的IP+端口。
- 因此,所谓四层代理就是基于IP+端口的负载均衡;七层就是基于URL等应用层信息的负载均衡。
1.2、基础信息
bash
kubectl explain svc
# svc 是 service 的缩写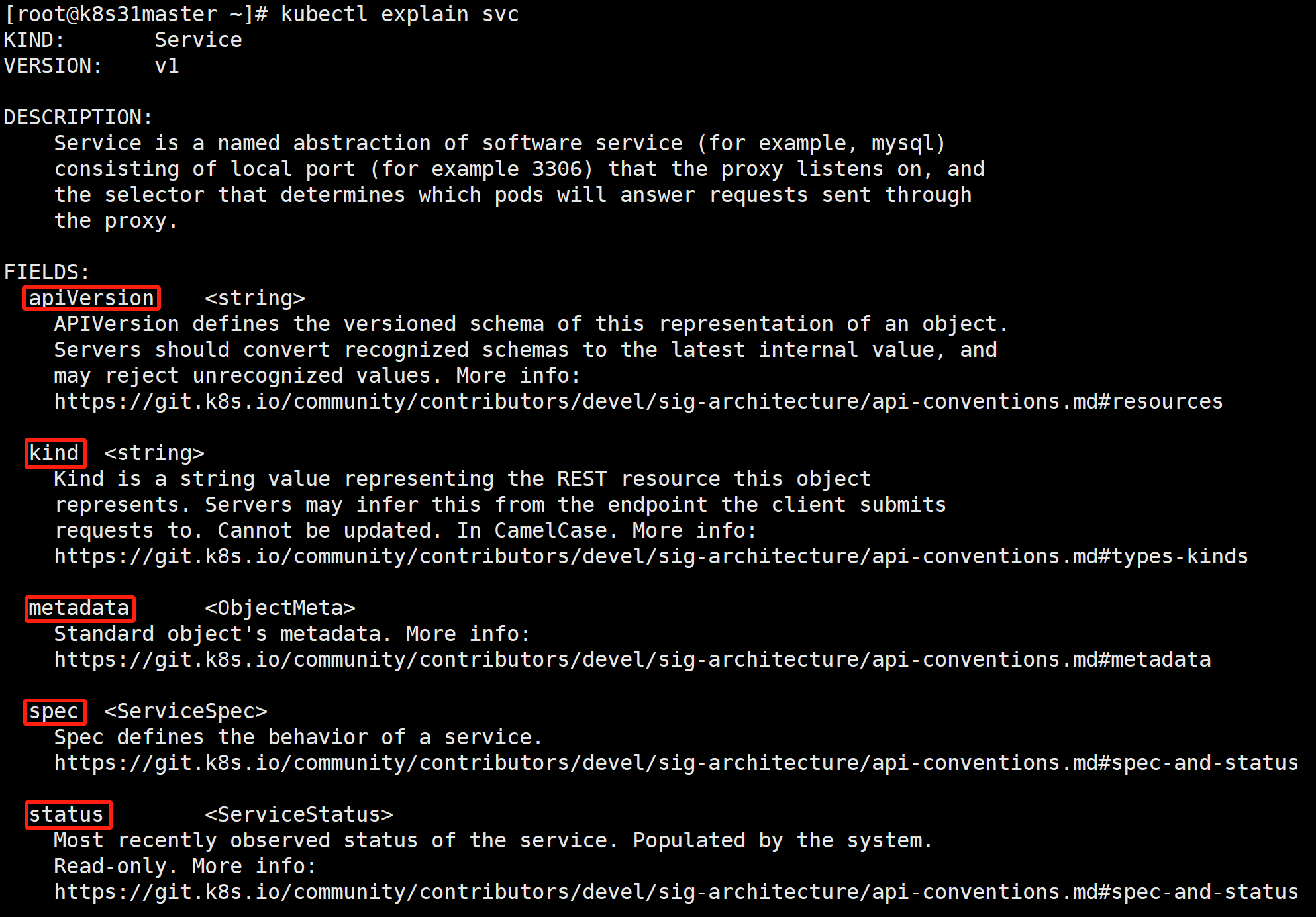
- apiVersion:当前资源使用的 api 版本,与 VERSION 一致。
- kind:资源类型,跟 KIND 保持一致。
- metadata:元数据。定义资源名称、标签、注解等。
- spec:规范、规约。
- status:最近观察到的 Service 状态。由系统填充。只读。
1.3、ServiceSpec 规约
bash
kubectl explain svc.spec|-------------------------------------------------|-------|
| allocateLoadBalancerNodePorts <boolean> | |
| clusterIP <string> | |
| clusterIPs <\[\]string> | |
| externalIPs <\[\]string> | |
| externalName <string> | |
| externalTrafficPolicy <string> | |
| healthCheckNodePort <integer> | |
| internalTrafficPolicy <string> | |
| ipFamilies <\[\]string> | |
| ipFamilyPolicy <string> | |
| loadBalancerClass <string> | |
| loadBalancerIP <string> | |
| loadBalancerSourceRanges <\[\]string> | |
| ports <\[\]ServicePort> | 端口 |
| publishNotReadyAddresses <boolean> | |
| selector <mapstringstring> | 标签选择器 |
| sessionAffinity <string> | |
| sessionAffinityConfig <SessionAffinityConfig> | |
| trafficDistribution <string> | |
| type <string> | 类型 |
1.4、Service 类型
bash
kubectl explain svc.spec.type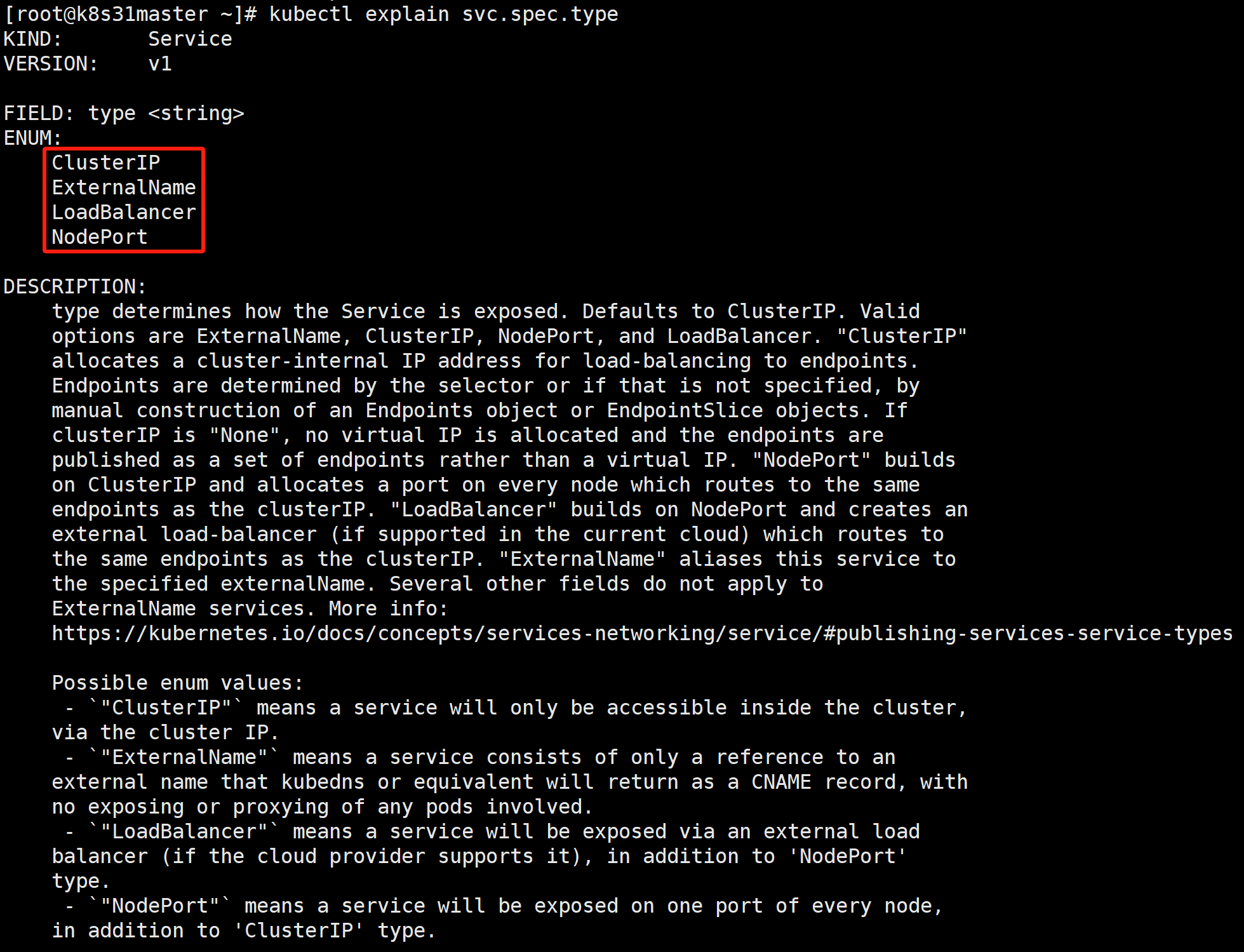
type 类型有四种:
- ClusterIP:虚拟集群IP。 通过集群的内部 IP 暴露服务,选择该值时服务只能够在集群内部访问。默认类型。
- NodePort:**节点端口。**通过每个节点上的 IP 和静态端口(NodePort)暴露服务。 NodePort 服务会路由到自动创建的 ClusterIP 服务。 通过请求 <节点 IP>:<节点端口>,你可以从集群的外部访问一个 NodePort 服务。
- ExternalName:**外部命名空间。**通过返回 CNAME 和对应值,可以将服务映射到 externalName 字段的内容(例如,foo.bar.example.com)。 无需创建任何类型代理。
- LoadBalancer:**负载均衡。**使用云提供商的负载均衡器向外部暴露服务。 外部负载均衡器可以将流量路由到自动创建的 NodePort 服务和 ClusterIP 服务上。Kubernetes 不直接提供负载均衡组件; 你必须提供一个,或者将你的 Kubernetes 集群与某个云平台集成。
其中 ClusterIP 为默认方式,只能集群内部访问。NodePort、LoadBalancer 则是向外暴露服务的同时将流量路由到 ClusterIP服务。ExternalName 则是CNAME方式进行服务映射。
1.5、Service 端口
bash
kubectl explain svc.spec.ports|-----------------------------|-----------------------------------------------------------------------------------------------|
| appProtocol <string> | |
| name <string> | |
| nodePort <integer> | service 在节点映射的端口。 type 类型是 NodePort 或 LoadBalancer 时才指定。 通常是系统分配,也可以自己指定,范围在 30000-32767。 |
| port <integer> -required- | Service 将公开的端口。 |
| protocol <string> | 协议。协议类型有 SCTP, TCP, UDP。默认 TCP。 |
| targetPort <IntOrString> | pod 端口 |
二、镜像准备
2.1、镜像准备
bash
docker pull mirrorgooglecontainers/serve_hostname:latest
docker pull alpine:latest
docker pull curlimages/curl2.2、镜像导出
bash
docker save -o serve_hostname.tar.gz mirrorgooglecontainers/serve_hostname:latest
docker save -o alpine.tar.gz alpine:latest
docker save -o curl.tar.gz curlimages/curl2.3、镜像导入工作节点 containerd
bash
# k8s31node1 执行
[root@k8s31node1 ~]# ctr -n=k8s.io images import serve_hostname.tar.gz
[root@k8s31node1 ~]# ctr -n=k8s.io images ls|grep serve_hostname
[root@k8s31node1 ~]# ctr -n=k8s.io images import alpine.tar.gz
[root@k8s31node1 ~]# ctr -n=k8s.io images ls|grep alpine
[root@k8s31node1 ~]# ctr -n=k8s.io images import curl.tar.gz
[root@k8s31node1 ~]# ctr -n=k8s.io images ls|grep curl
# k8s31node2 执行
[root@k8s31node2 ~]# ctr -n=k8s.io images import serve_hostname.tar.gz
[root@k8s31node2 ~]# ctr -n=k8s.io images ls|grep serve_hostname
[root@k8s31node2 ~]# ctr -n=k8s.io images import alpine.tar.gz
[root@k8s31node2 ~]# ctr -n=k8s.io images ls|grep alpine
[root@k8s31node2 ~]# ctr -n=k8s.io images import curl.tar.gz
[root@k8s31node2 ~]# ctr -n=k8s.io images ls|grep curl





2.4、环境准备
假设有如下三个节点的 K8S 集群:
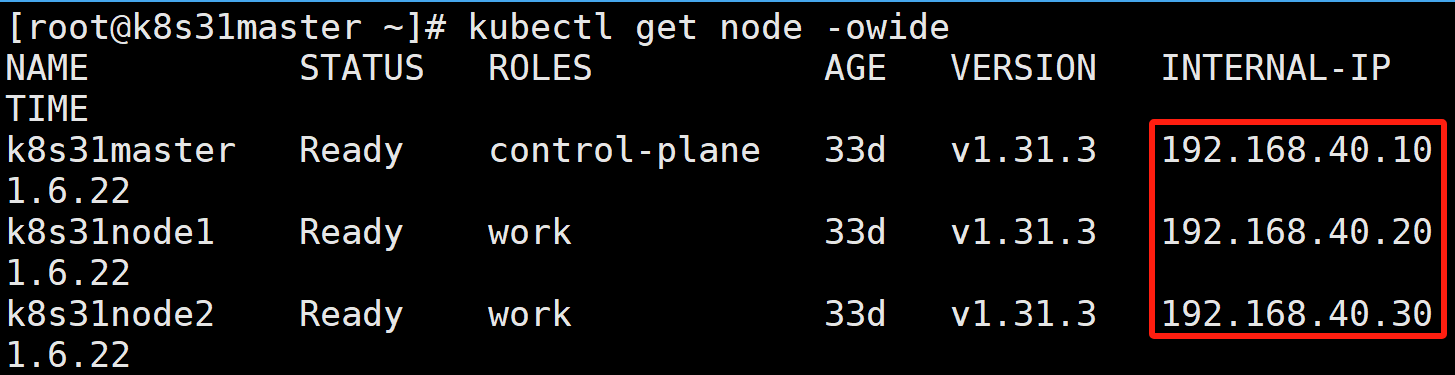
k8s31master 是控制节点
k8s31node1、k8s31node2 是工作节点
容器运行时是 containerd
三、实践
3.1、创建 ClusterIP 类型 Service
假设有这么一个部署:
objectivec
apiVersion: apps/v1
kind: Deployment
metadata:
name: hostnames
spec:
selector:
matchLabels:
app: hostnames
replicas: 3
template:
metadata:
labels:
app: hostnames
spec:
containers:
- name: hostnames
image: mirrorgooglecontainers/serve_hostname
imagePullPolicy: IfNotPresent
ports:
- containerPort: 9376
protocol: TCPmirrorgooglecontainers/serve_hostname 这个应用的作用,就是每次访问 9376 端口时,返回它自己的 hostname。

3.1.1、在不同的节点上访问 podIP:port
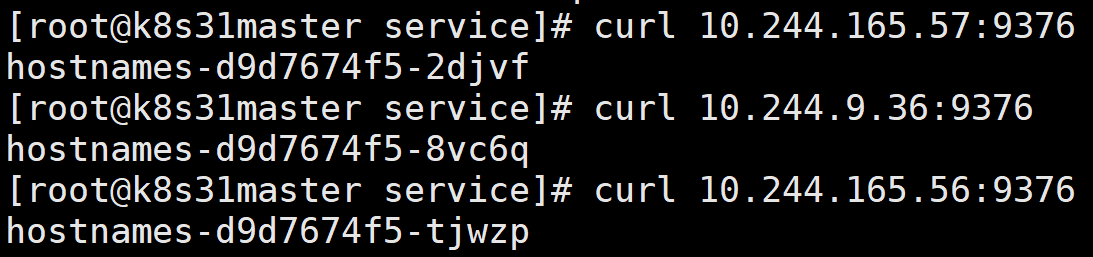
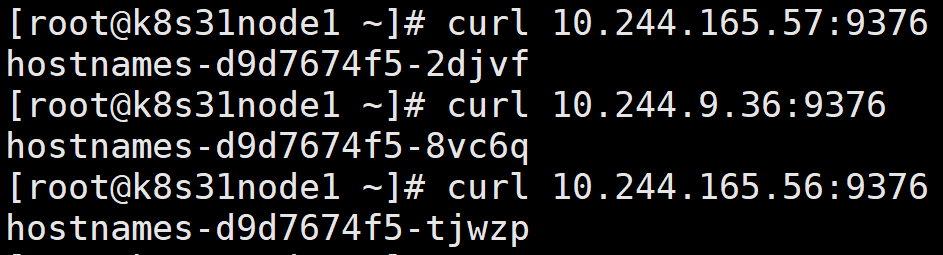
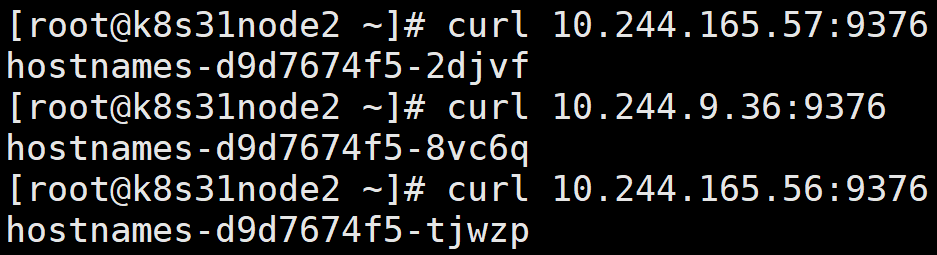
返回了各个 pod 自己的 hostname。
可以看到,在集群内的不同节点上, Pod IP 都能访问。
3.1.2、在不同的容器内访问 podIP:port
假设现在新起一个 pod:
bash
apiVersion: v1
kind: Pod
metadata:
name: curl-tools
spec:
containers:
- name: curl-tools
image: curlimages/curl:latest
imagePullPolicy: IfNotPresent
command: ["/bin/sh", "-c", "while true; do echo 'Hello from curl-tools'; sleep 30; done"]
- curlimages/curl 是一个 curl 调试工具。
- command:容器启动后执行的命令,这里使用一个无限循环,每隔 30 秒输出一次
Hello from curl-tools。- 像 Alpine 镜像,或者基于 Alpine 制作的工具镜像,容器内没有运行服务,需要启动后运行一个无限循环,防止容器被 K8S 杀掉。
进入容器访问 hostnames 服务:
bash
kubectl exec -it curl-tools -- curl 10.244.165.57:9376
可以看到,在集群内的容器之间,Pod IP 都能访问。
3.1.3、在集群外访问 podIP:port
我们再起一台虚拟机 docker1,IP 地址跟 K8S 集群在一个网段。
访问 hostnames 服务:

可以看到,即使 docker1 的 IP 地址跟 K8S 集群在一个网段,但 docker1 没有用类似 kubeadm join 加入过集群,Pod IP 是不能访问的。
3.1.4、误删一个 pod

bash
kubectl delete pod hostnames-d9d7674f5-2djvf
可以看到,K8S 又帮我们重新拉起了一个新 pod:hostnames-d9d7674f5-n7mtn,以维持我们 Deployment 控制器希望的副本数 replicas: 3。但是这个新 pod 的 IP,跟原来旧 pod 的 IP 是不一样的。
倘若我们是调用这些 pod 服务的客户端,在 pod 扩缩容期间,维护这些 pod IP 的代价是非常大的。所以我们需要一个稳定的接入层,它的 IP 地址、端口不变,让它来代理后端的一组 pod,而我们程序只需要跟这个接入层打交道就可以。这个接入层,就是 Service。
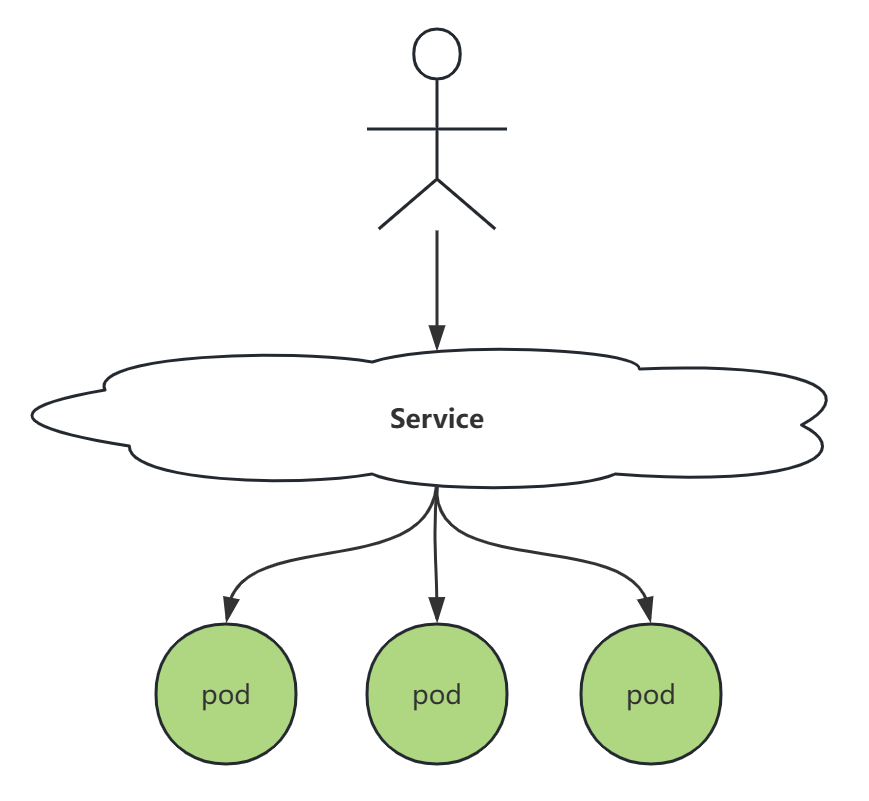
3.1.5、新建一个 ClusterIP 类型 Service
bash
apiVersion: v1
kind: Service
metadata:
name: hostnames-svc
spec:
type: ClusterIP
selector:
app: hostnames
ports:
- port: 80
protocol: TCP
targetPort: 9376
- spec.selector:Service 通过标签选择器来查找 app=hostnames 标签的 Pod。
- port: 80 表示该服务的可用端口。
- targetPort: 9376 表示服务将连接转发的 Pod 端口。
- port 跟 targetPort 配合起来表示 这个 Service 的 80 端口,代理的是 Pod 的 9376 端口。
- 查看 service
bash
kubectl get svc
- 访问 service
连续三次不断地访问 Service 的 CLUSTER-IP 和 端口 80:
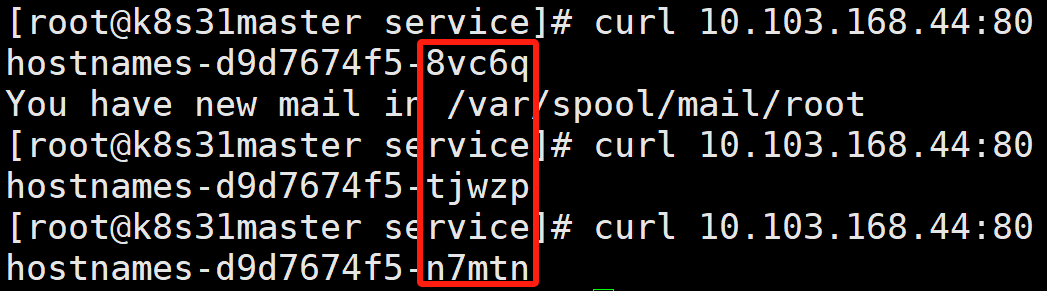
- 依次返回了三个 Pod 的 hostname。
- 请求 Service IP:port 跟直接访问 Pod IP:port 的结果一样,这说明 Service 可以把请求代理到它所关联的后端 Pod。
- 这也印证了 Service 提供的是 Round Robin (轮询) 方式的负载均衡。
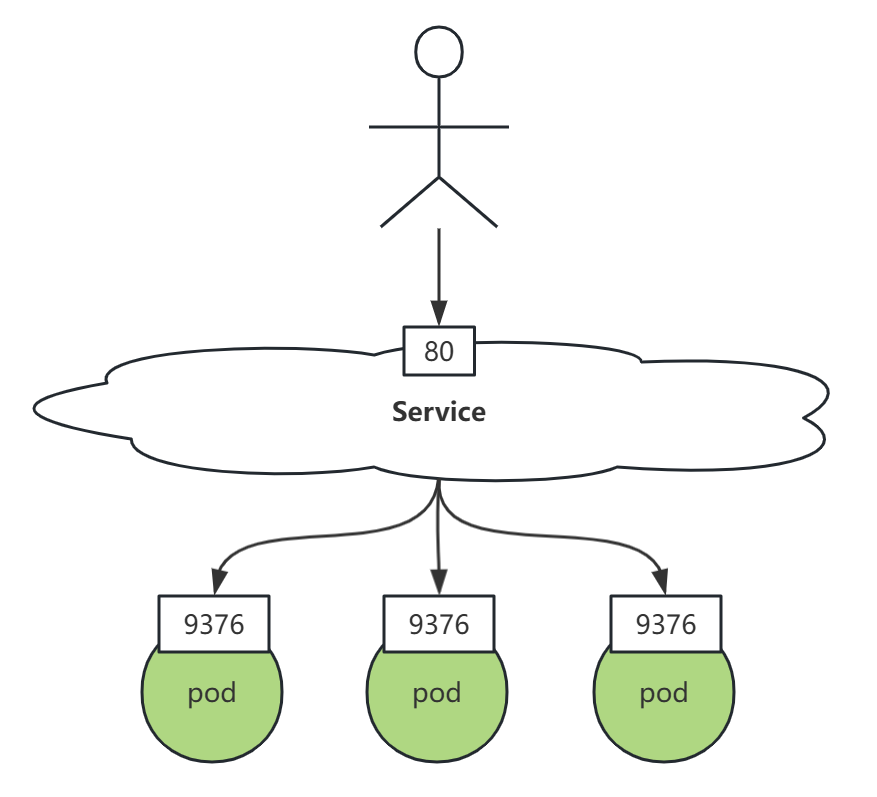
- 查看 endpoints
K8S 创建 Service 的时候,如果 Service 带有 selector 选择器,则 K8S 会创建一个与 Service 同名的 Endpoints 对象。selector 选中的 Pod 的 IP 和 端口,都会记录在 Endpoints 中。当一个新的 Pod 被创建并且它的标签匹配了某个 Service 的选择器时,该 Pod 的 IP 和端口会被添加到对应的 Endpoints 对象中;同样地,当 Pod 被删除时,它也会从 Endpoints 中移除。Endpoints 通常由 Service 引用, 以定义可以将流量发送到哪些 Pod。
bash
kubectl get ep hostnames-svc
# ep endpoints 缩写
kubectl get ep hostnames-svc -oyaml
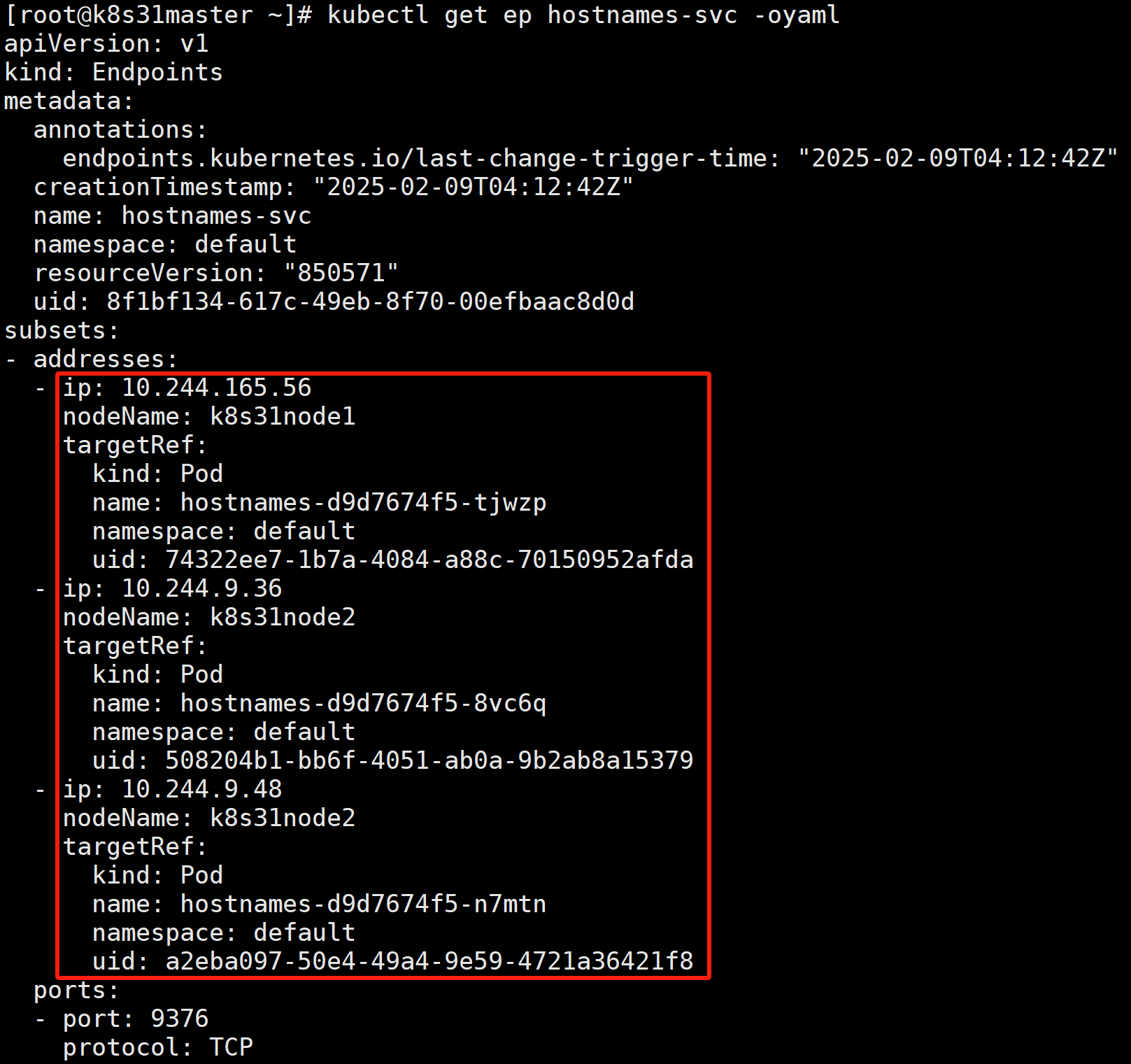
需要注意的是,只有处于 Running 状态,且 readinessProbe 检查通过的 Pod,才会出现在 Service 的 Endpoints 列表里。并且,当某一个 Pod 出现问题时,Kubernetes 会自动把它从 Service 里摘除掉。
3.1.6、集群外访问 Service ClusterIP:port
在集群外的虚拟机 192.168.40.111 访问 10.103.168.44:80

可以看到,访问不到 Service。如果希望集群外的机器能访问,需要创建 NodePort 类型的 Service 或 LoadBalancer 类型的 Service。
3.1.7、通过 FQDN 访问服务
在 Kubernetes (K8S) 环境中,FQDN(Fully Qualified Domain Name,完全限定域名)是指集群内部服务的完整域名,它包含了服务名、命名空间以及可选的服务后缀,用于唯一标识集群中的一个服务。
当你在 Kubernetes 中创建一个服务时,Kubernetes 会为该服务分配一个 FQDN。这个 FQDN 的格式通常是:
java
<service-name>.<namespace>.svc.cluster.local
- service-name 是你给服务起的名字。
- namespace 是服务所在的命名空间,默认是 default,除非你在创建服务时指定了不同的命名空间。
- svc 是固定的,代表这是一个服务。
- cluster.local 是集群的默认域,大多数情况下是这个值,但如果你的集群配置了不同的域名,则会有所不同。
例如,我们上面 hostnames-svc 服务,它的完整域名是:
java
hostnames-svc.default.svc.cluster.local我们在集群的其他 pod 中,就可以使用这个域名访问服务:
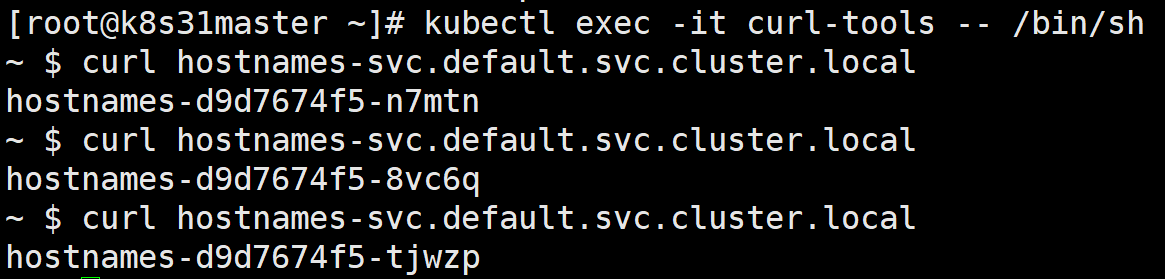
可以省略命名空间和 svc.cluster.local,因为已经帮我们解析了。
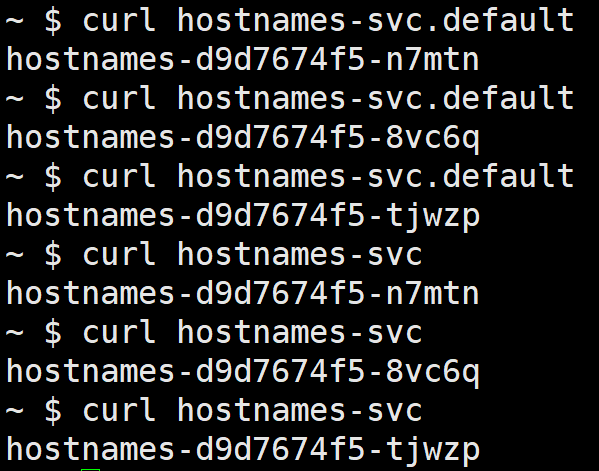

在节点上不能解析这个域名,Kubernetes 的 DNS 服务通常只服务于集群中的 Pod,而节点本身并不自动配置为使用它:

使用 FQDN 可以让 Kubernetes 集群中的其他服务通过 DNS 解析来找到并访问你的服务,而不需要知道服务的具体 IP 地址。这有助于实现服务发现和服务间的通信,并且提高了服务部署的灵活性和可移植性。在 Kubernetes 中,CoreDNS 通常被用来提供这种 DNS 服务发现的功能。
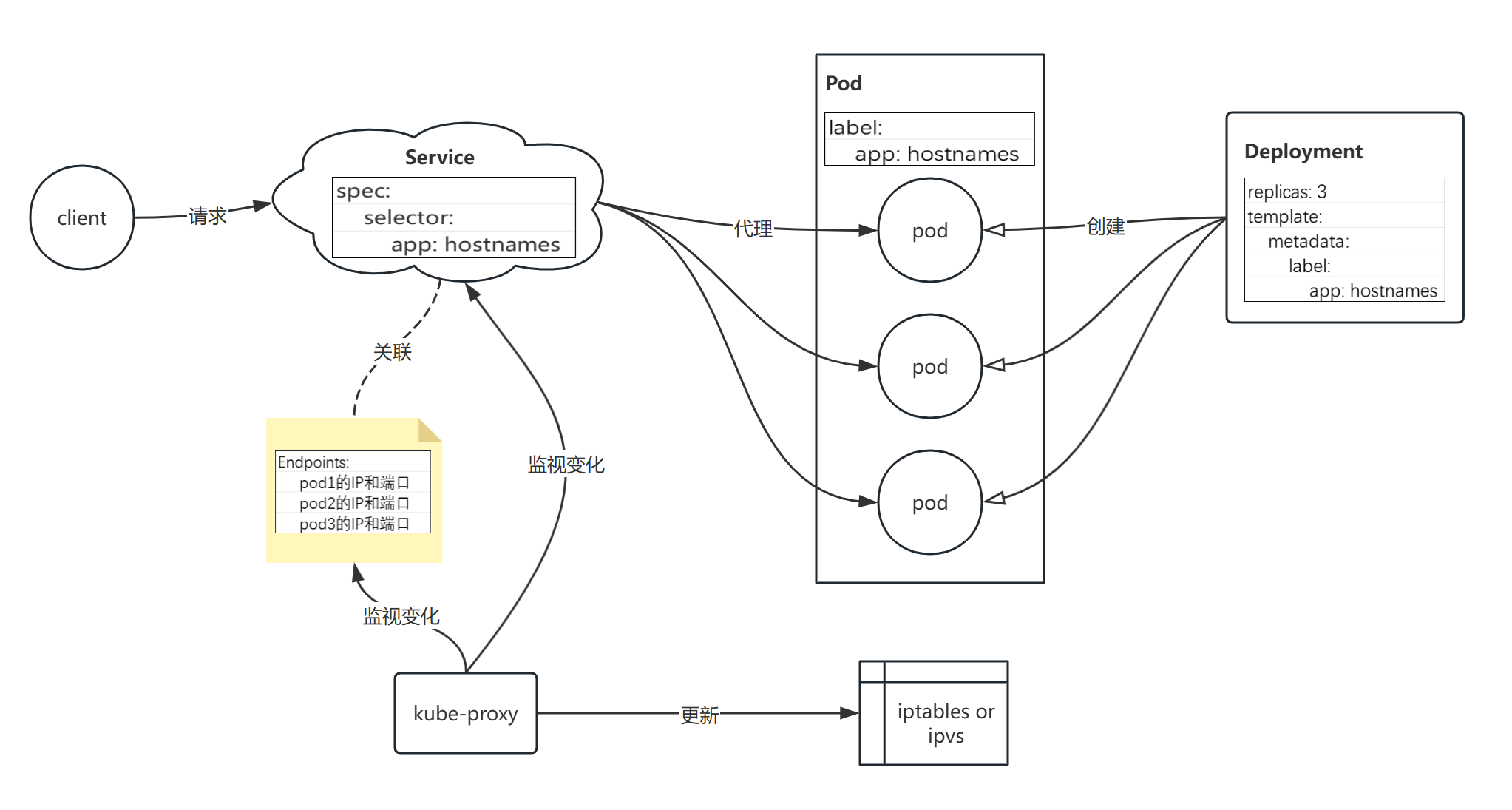
3.1.8、Service 原理
我们以 3.1.2 小节 curl-tools 容器(假设运行在 node2 上)访问 Service Cluster_IP : port 为例,来讲解 Service 的工作原理。
首先介绍一下几个组件:
- kube - proxy:是 Kubernetes 集群中每个节点上运行的一个组件。它负责在节点上维护网络规则,实现了 Service 的代理和负载均衡功能,确保客户端可以通过 Service 的 IP 和端口访问到对应的后端 Pod。kube-proxy 会监视 API Server 中 Service 和 Endpoints 对象的变化。当有新的 Service 或 Endpoints 对象创建、更新或删除时,kube-proxy 会收到通知,并相应地更新节点上的网络规则(iptables)。kube-proxy 有 iptables 模式跟 ipvs 模式。
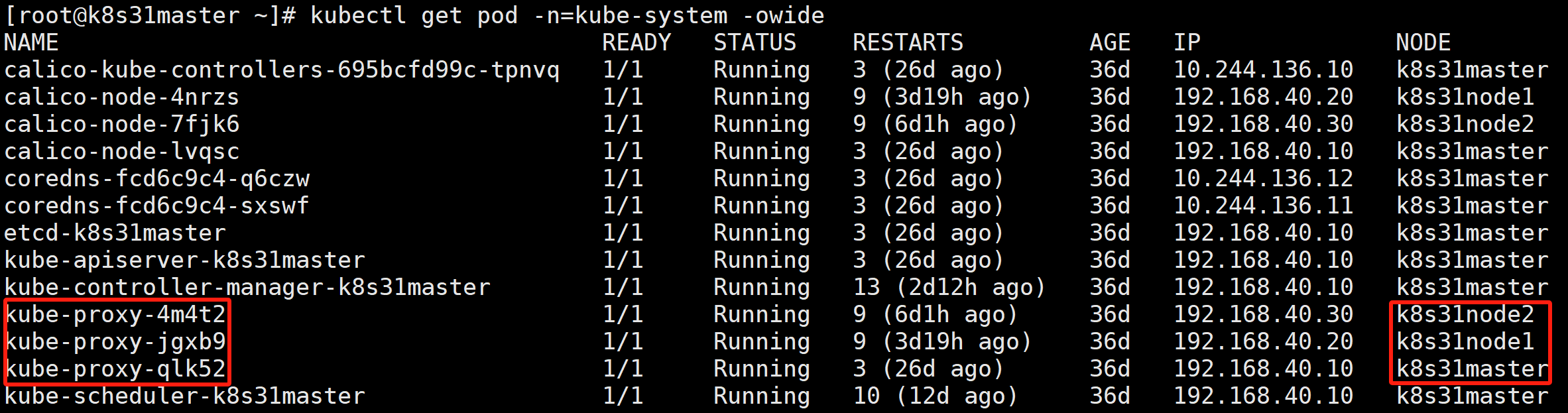
- Service:是 Kubernetes 提供的一种抽象层,它定义了一组 Pod 的逻辑集合以及访问这些 Pod 的策略。Service 为 Pod 提供了一个稳定的 IP 地址(ClusterIP)和端口号,使得客户端可以通过这个稳定的地址来访问后端的 Pod,而不需要关心具体 Pod 的 IP 地址和生命周期。
- Endpoints:是 Kubernetes 中的一个资源对象,它记录了 Service 对应的所有后端 Pod 的 IP 地址和端口信息。每当 Pod 的数量或状态发生变化时,Endpoints 对象会自动更新。
curl-tools 容器内访问 Service IP : port 流程:
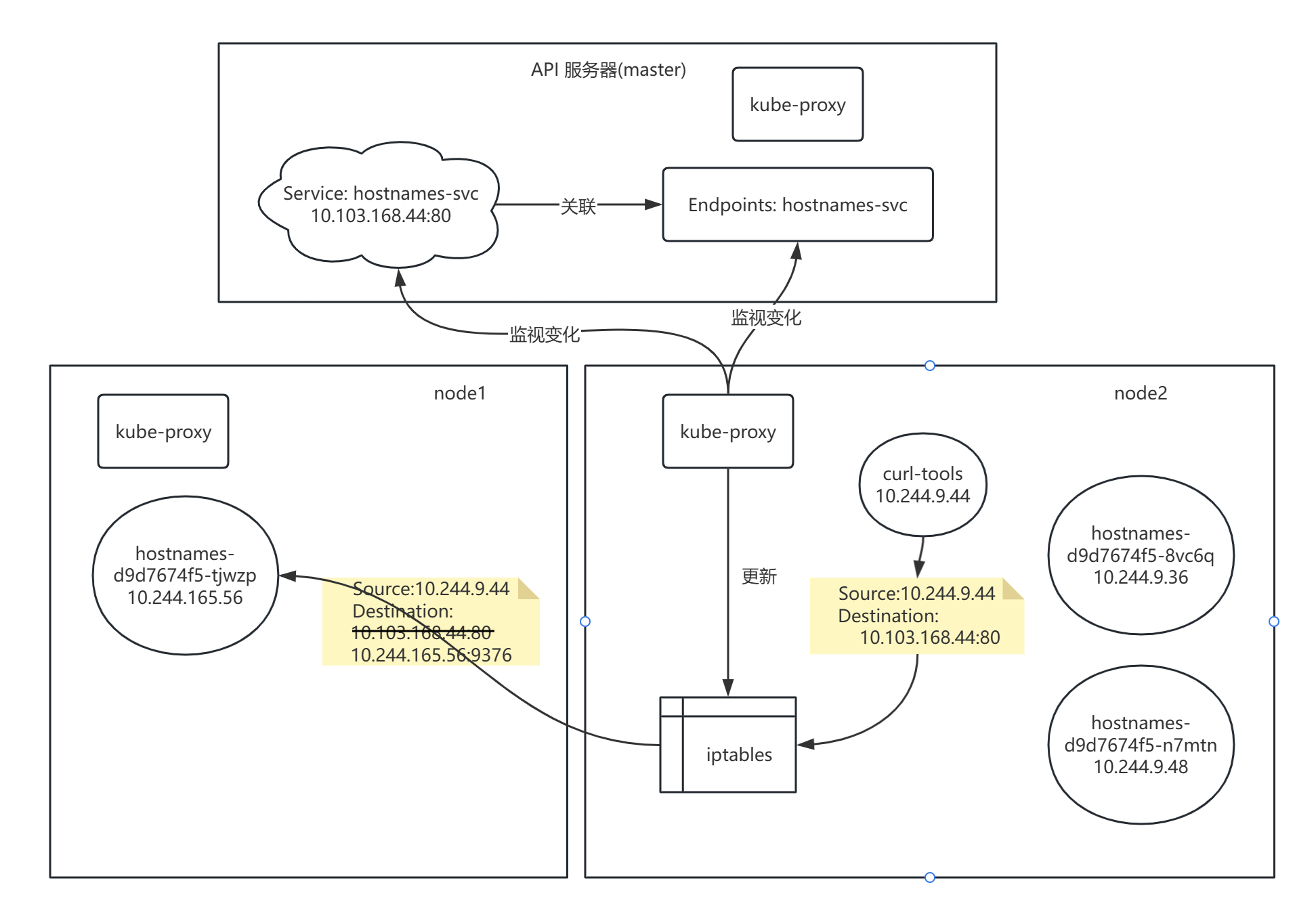
- node2 上的 kube-proxy 监视 API Server 中 Service 和 Endpoints 对象的变化,更新节点上的网络规则(iptables)。
- 客户端 curl-tools 请求 Service IP : port,请求包目的地 Destination 初始设置为服务的IP和端口(10.103.168.44:80)。发送到网络之前,node2 的内核会根据配置在该节点上的 iptables 规则处理数据包。内核会检查数据包是否匹配任何这些 iptables 规则。其中有个规则规定如果有任何数据包的目的地IP等于10.103.168.44、目的地端口等于80,那么数据包的目的地IP和端口应该被替换为随机选中的 hostnames pod的IP和端口。
- 本例中的数据包满足规则,故而它的IP:端口被改变了。假设 pod hostnames-d9d7674f5-tjwzp 被轮询算法随机选中了,所以数据包的目的地IP变更为 10.244.165.56,端口改为9376(Service中定义的目标端口)。就好像是客户端 curl-tools 直接发送数据包给 hostnames-d9d7674f5-tjwzp 而不是通过 Service。
3.1.9、iptables Or IPVS
kube-proxy 通过 iptables 处理 Service 的过程,其实需要在宿主机上设置相当多的 iptables 规则。而且,kube-proxy 还需要在控制循环里不断地刷新这些规则来确保它们始终是正确的。
当宿主机上有大量 Pod 的时候,成百上千条 iptables 规则不断地被刷新,很明显会影响到整体性能。
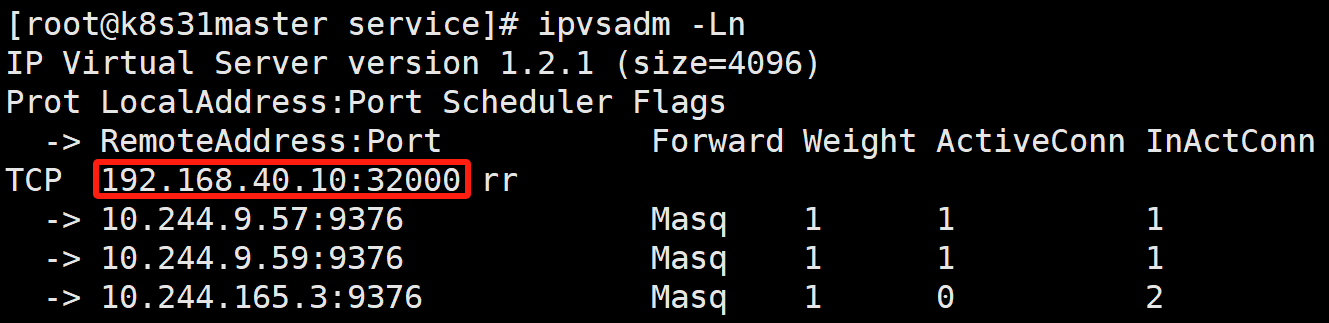
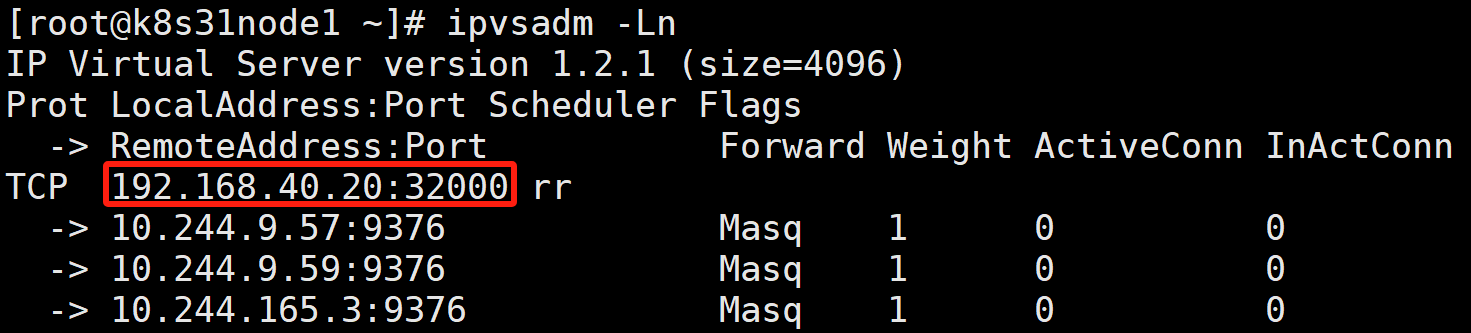
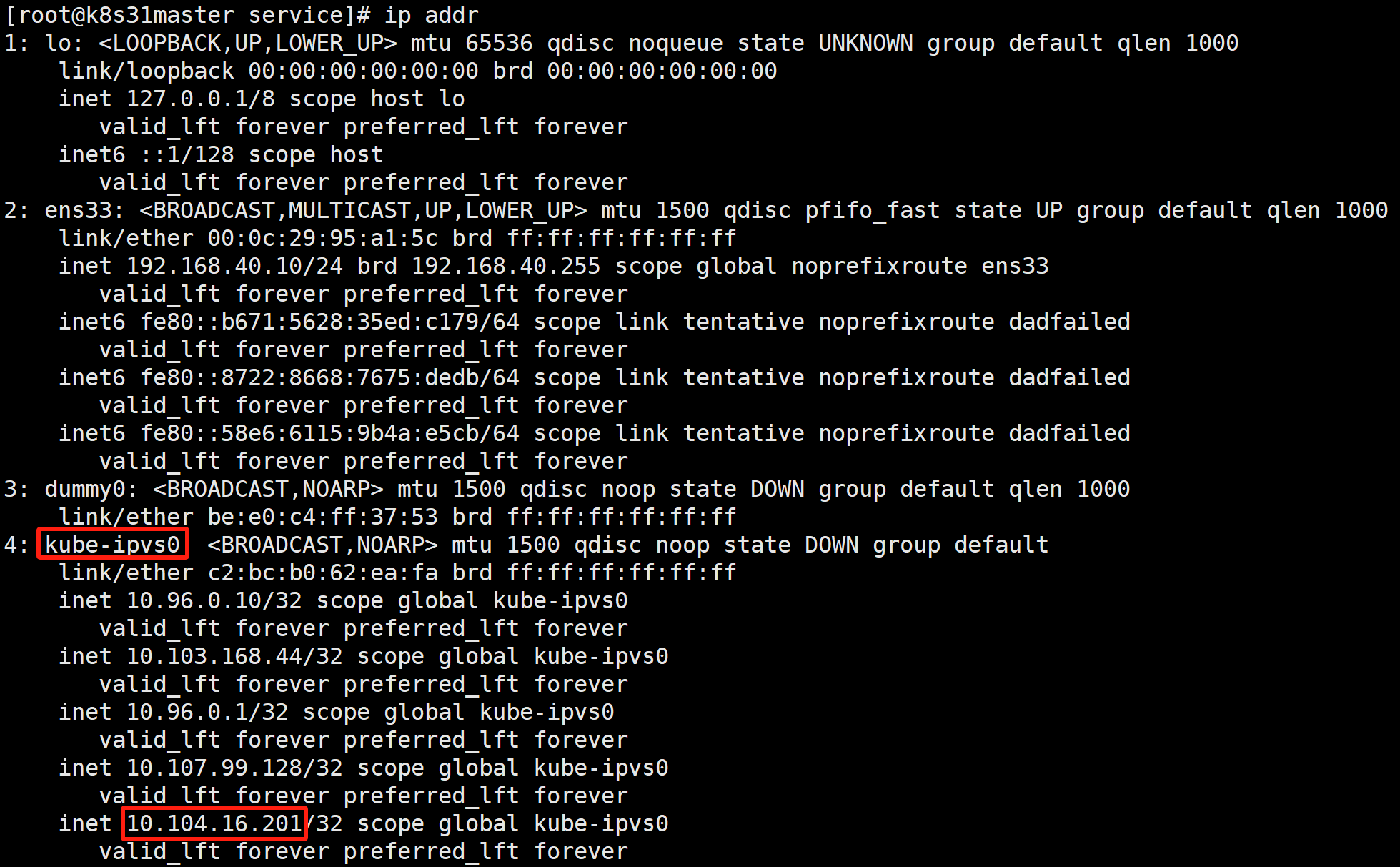
IPVS 模式的工作原理,其实跟 iptables 模式类似。区别只在于当我们创建了前面的 Service 之后,kube-proxy 首先会在宿主机上创建一个虚拟网卡(叫作:kube-ipvs0),并为它分配 Service VIP 作为 IP 地址,如下所示:
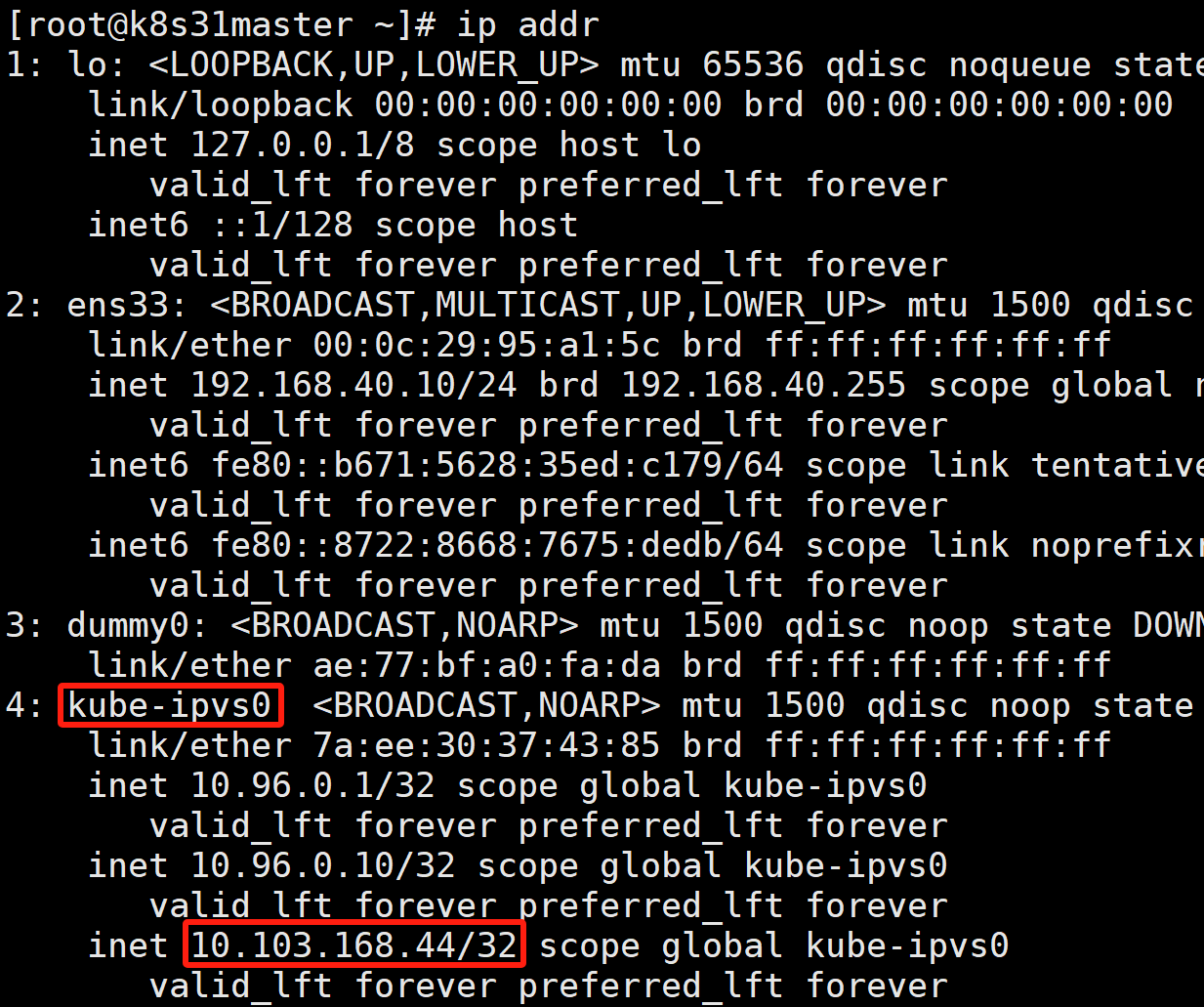
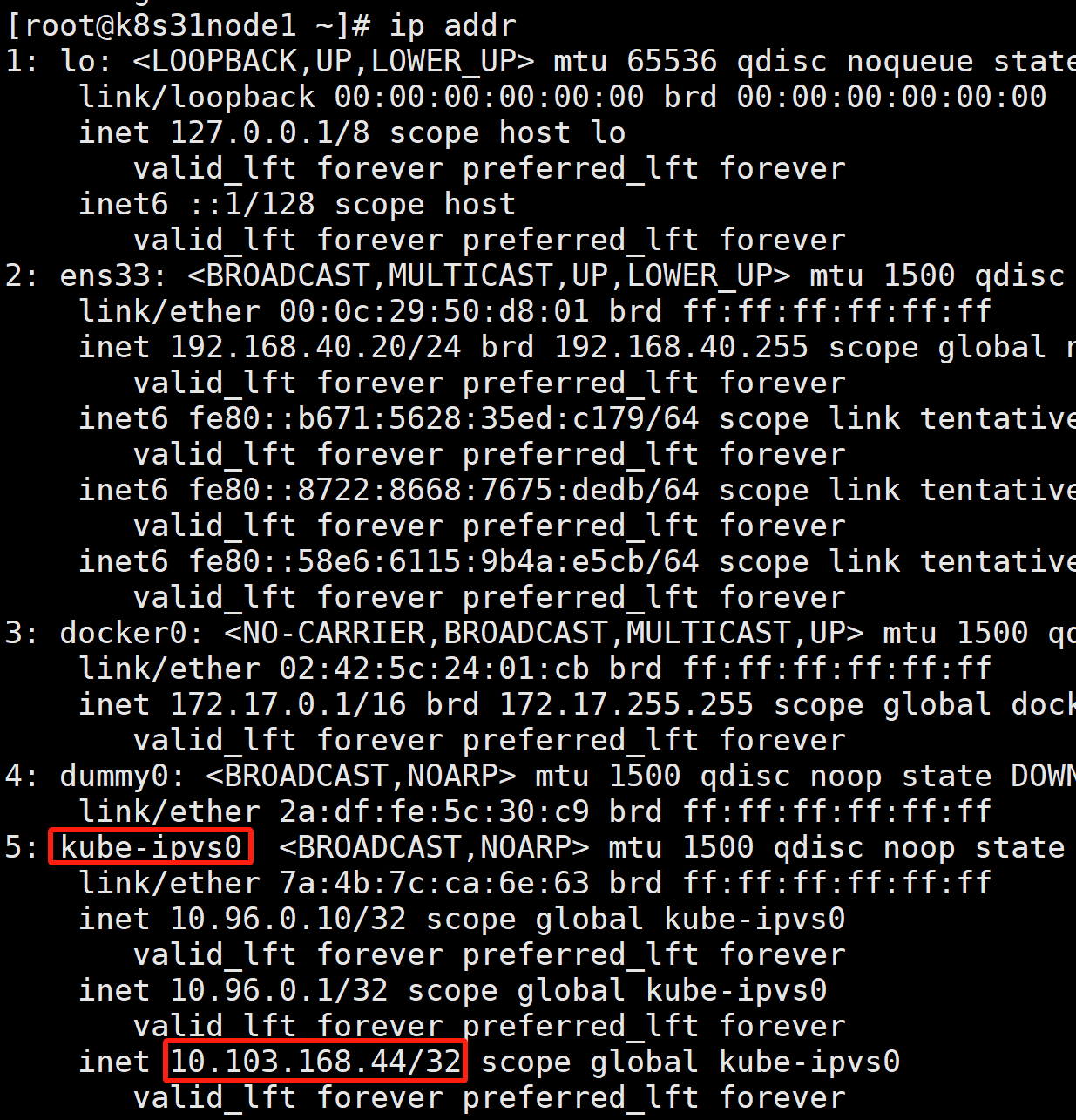
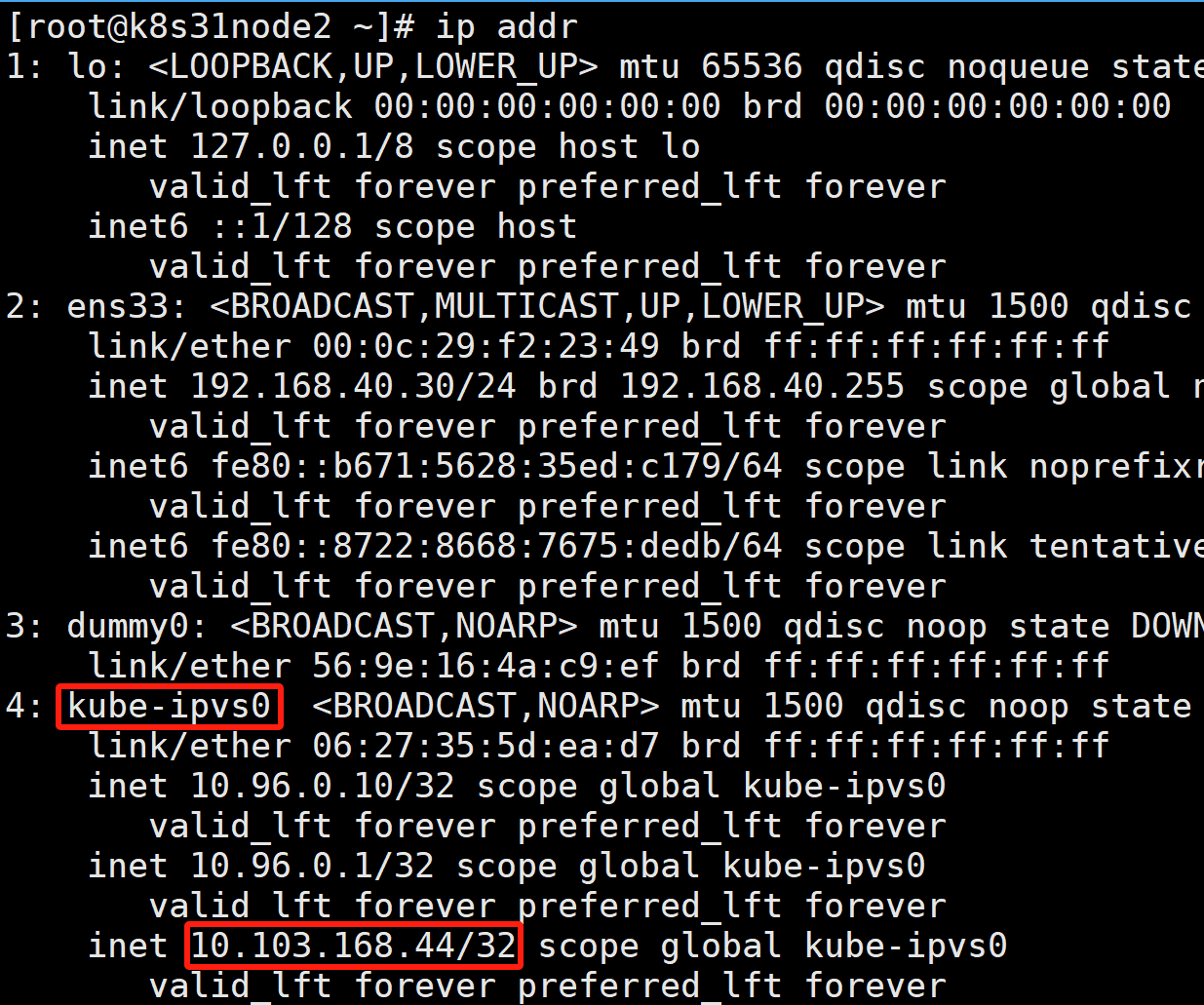
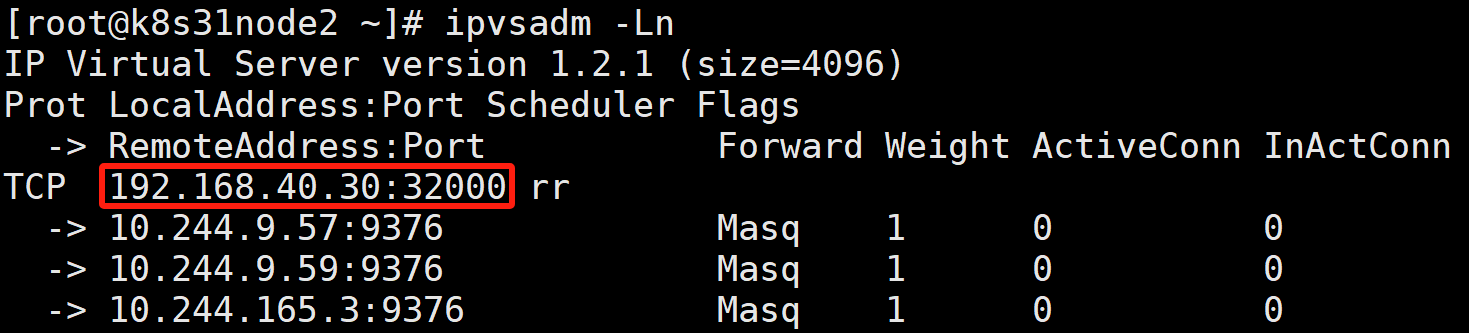
而接下来,kube-proxy 就会通过 Linux 的 IPVS 模块,为这个 IP 地址设置三个 IPVS 虚拟主机,并设置这三个虚拟主机之间使用轮询模式 (rr) 来作为负载均衡策略。我们可以通过 ipvsadm 查看到这个设置,如下所示:
bash
ipvsadm -ln
-l:这是 ipvsadm 命令的一个选项,代表 "list",即列出当前 IPVS 规则。使用该选项可以查看已经配置的虚拟服务器(Virtual Server)及其对应的真实服务器(Real Server)信息。
-n:同样是 ipvsadm 命令的选项,代表 "numeric",表示以数字形式显示地址和端口,而不是将 IP 地址解析为域名、端口号解析为服务名。使用这个选项可以避免 DNS 解析和服务名查找的过程,更直观地显示规则信息。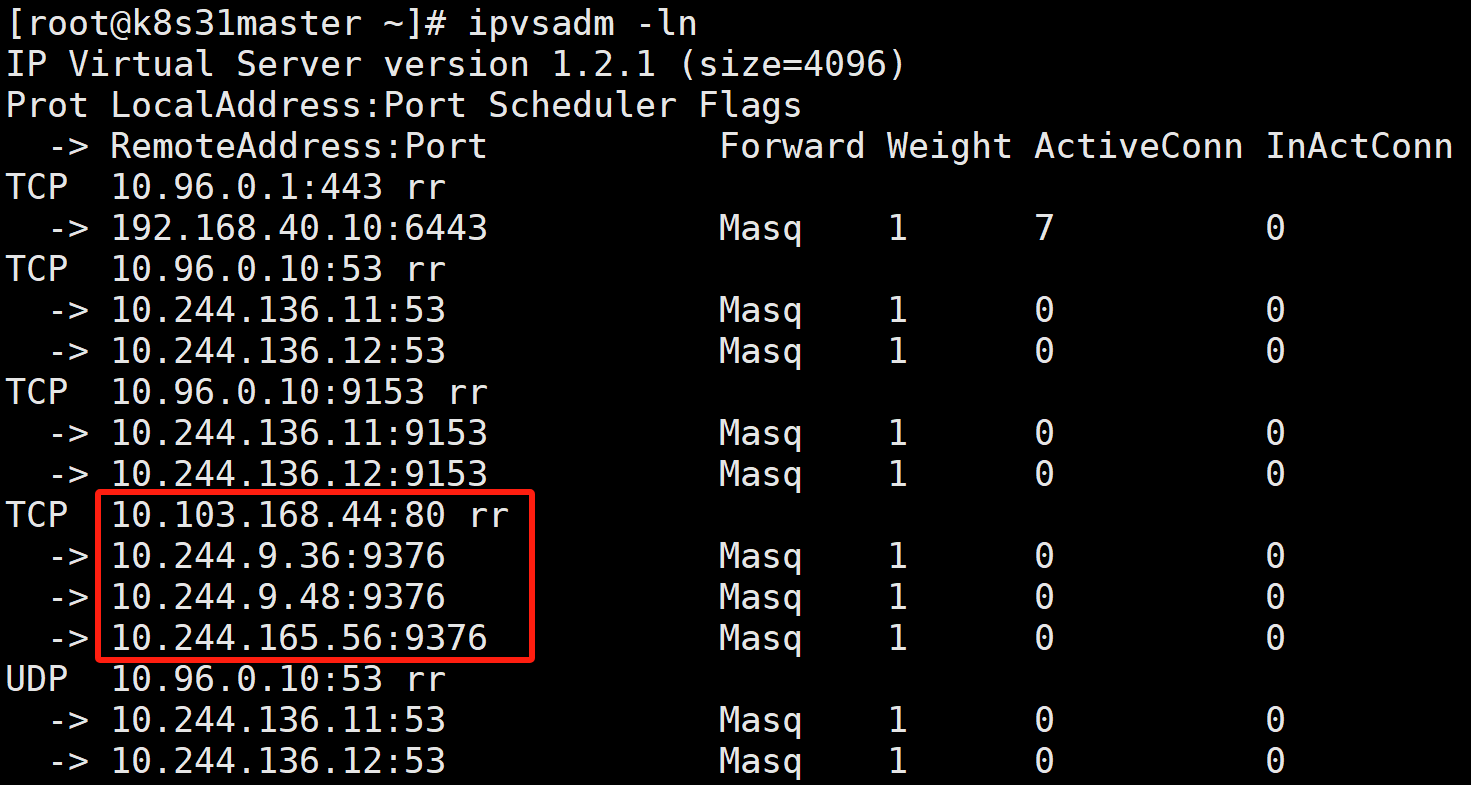
可以看到,这三个 IPVS 虚拟主机的 IP 地址和端口,对应的正是三个被代理的 Pod。rr 表示轮询 round robin。
这时候,任何发往 10.103.168.44:80 的请求,就都会被 IPVS 模块转发到某一个后端 Pod 上了。 而相比于 iptables,IPVS 在内核中的实现其实也是基于 Netfilter 的 NAT 模式,所以在转发这一层上,理论上 IPVS 并没有显著的性能提升。但是,IPVS 并不需要在宿主机上为每个 Pod 设置 iptables 规则,而是把对这些"规则"的处理放到了内核态,从而极大地降低了维护这些规则的代价。
不过需要注意的是,IPVS 模块只负责上述的负载均衡和代理功能。而一个完整的 Service 流程正常工作所需要的包过滤、SNAT 等操作,还是要靠 iptables 来实现。
3.1.10、Endpoints 与 readinessProbe 就绪探针
- 编写服务 svc-hellok8s.yaml
bash
apiVersion: v1
kind: Service
metadata:
name: hellok8s-svc
spec:
type: ClusterIP
selector:
app: hellok8s
ports:
- port: 80
protocol: TCP
targetPort: 8080- 执行并监控
bash
kubectl apply -f svc-hellok8s.yaml
# -w 表示持续监控,注意这个时候不要关闭终端
kubectl get ep hellok8s-svc -w
- 编写部署 deploy-hellok8s.yaml
bash
apiVersion: apps/v1
kind: Deployment
metadata:
name: hellok8s
spec:
replicas: 3
selector:
matchLabels:
app: hellok8s
version: "1.0"
template:
metadata:
labels:
app: hellok8s
version: "1.0"
spec:
containers:
- name: hellok8s
image: hellok8s:1.0
imagePullPolicy: IfNotPresent
ports:
- containerPort: 8080
readinessProbe:
httpGet:
path: /
port: 8080
initialDelaySeconds: 15
periodSeconds: 10initialDelaySeconds: 表示容器启动后延迟多少秒,开始就绪探测。这里特意设置成 15 秒,为了观察就绪探针没有完成时, Endpoints 的列表里,会不会有 pod 的 IP。
- 在另一个终端运行部署
bash
kubectl apply -f deploy-hellok8s.yaml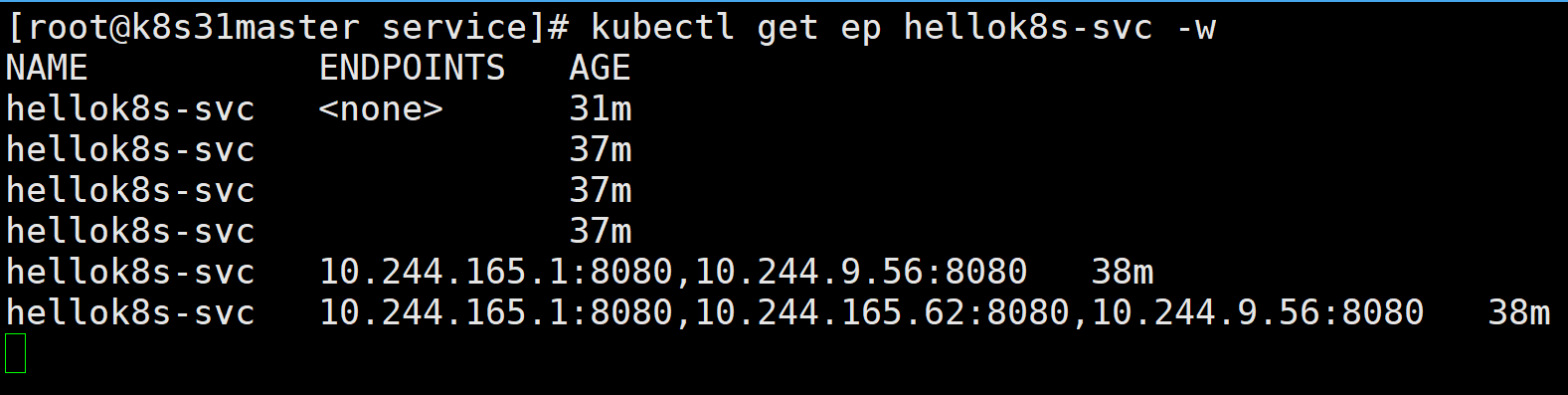

可以看到,在 pod 还没就绪前,endpoints 列表里面是不会有 pod IP 的。
- 删除部署
bash
kubectl delete -f deploy-hellok8s.yaml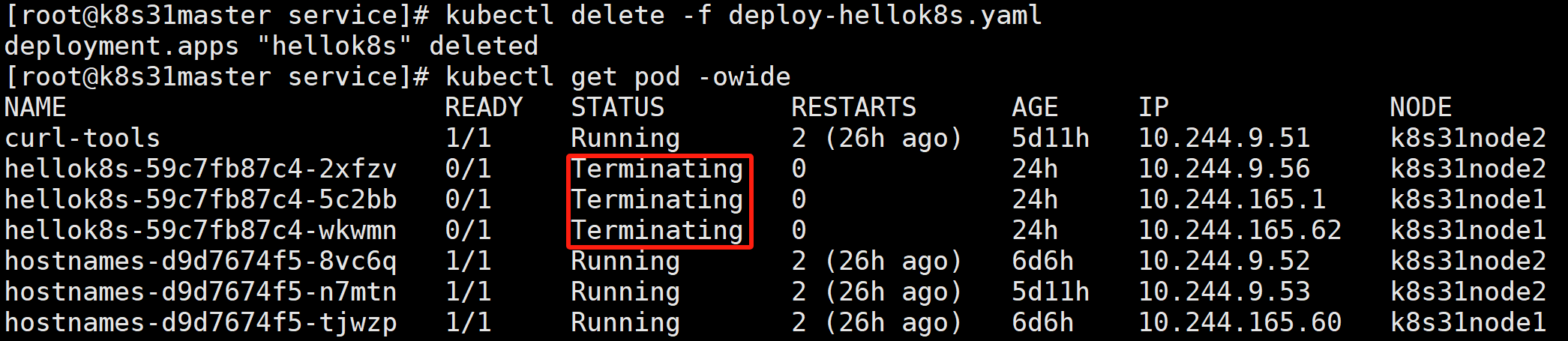

可以看到 pod 被删除,endpoints 列表也会移除 pod IP。
3.1.11、原理图
3.2、创建 NodePort类型 Service
假设我们现在有如下 三个 pod:
java
kubectl get pod -l app=hostnames -owide
IP 分别是 10.244.9.57、10.244.9.59、10.244.165.3
3.2.1、编写服务
XML
apiVersion: v1
kind: Service
metadata:
name: hostnames-nodeport
spec:
type: NodePort
selector:
app: hostnames
ports:
- port: 80
protocol: TCP
targetPort: 9376
nodePort: 32000
- spec.type:NodePort 通过每个节点上的 IP 和静态端口(NodePort)暴露服务。
- spec.ports.nodePort:指定节点上暴露的端口 32000。
3.2.2、访问服务
在浏览器中、或者任何能访问到集群三个节点的机器上,访问 节点IP:32000
bash
curl 192.168.40.10:32000
curl 192.168.40.20:32000
curl 192.168.40.30:32000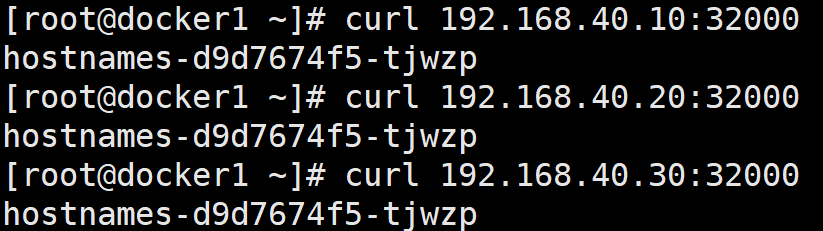
3.2.3、原理
每一个节点的防火墙规则里面,都有一条 节点IP:32000 的转发规则。转发到三个 pod上。
创建 NodePort 类型的 Service 会默认帮我们创建 Cluster_IP
它的数据转发方式,跟 3.1 节讲的是一样的,走 kube-ipvs0 虚拟网桥。
如果节点上有安装 docker,NodePort 不会走节点IP端口,会默认走 docker0 网桥,然后数据再通过 docker0 转发给 pod。

3.3、创建 ExternalName 类型 Service
3.3.1、场景分析
Service,是无法代理到不同名称空间下的 Pod 的。
假设我们默认名称空间下,有三个这样的 Pod:
bash
kubectl get pod -l app=hostnames -A --show-labels
在名称空间 external-demo 下,有这样一个 Service:
XML
apiVersion: v1
kind: Service
metadata:
name: external-svc-a
namespace: external-demo
spec:
type: ClusterIP
selector:
app: hostnames
ports:
- port: 80
protocol: TCP
targetPort: 9376Service 在 external-demo 名称空间下,它的标签选择器选择了上面的三个 Pod。
查看 Service 详情:
XML
kubectl describe svc external-svc-a -n=external-demo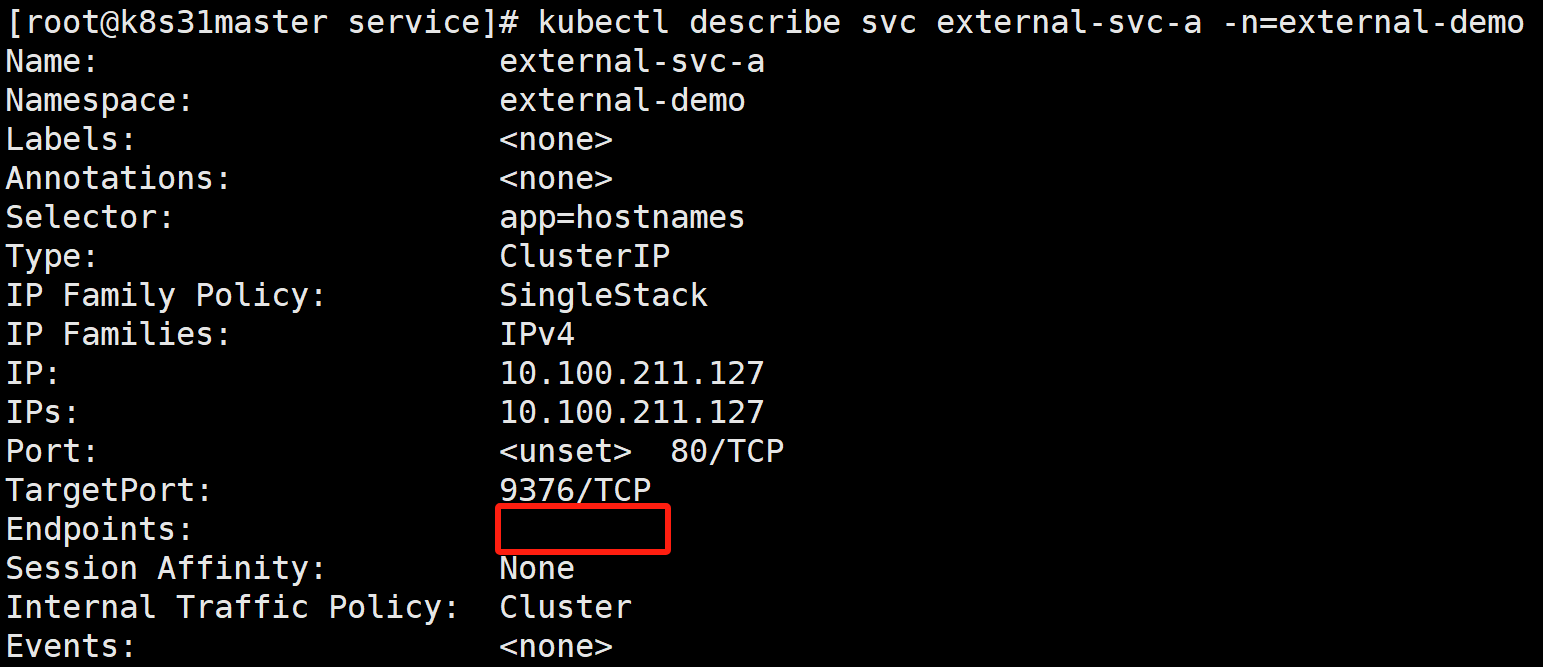
可以看到它并没有代理到任何 Pod。
此时,不管是在节点上直接访问 Service ClusterIP 10.100.211.127:80

还是在 external-demo 名称空间下的 Pod:
XML
apiVersion: v1
kind: Pod
metadata:
name: curl-tools
namespace: external-demo
spec:
containers:
- name: curl-tools
image: curlimages/curl:latest
imagePullPolicy: IfNotPresent
command: ["/bin/sh", "-c", "while true; do echo 'Hello from curl-tools'; sleep 30; done"]
bash
kubectl exec -it -n=external-demo curl-tools -- /bin/sh
都访问不到任何 Pod。
那么,external-demo 名称空间下的 Pod 要如何通过 Service 访问 default 名称空间下的 Pod 呢?
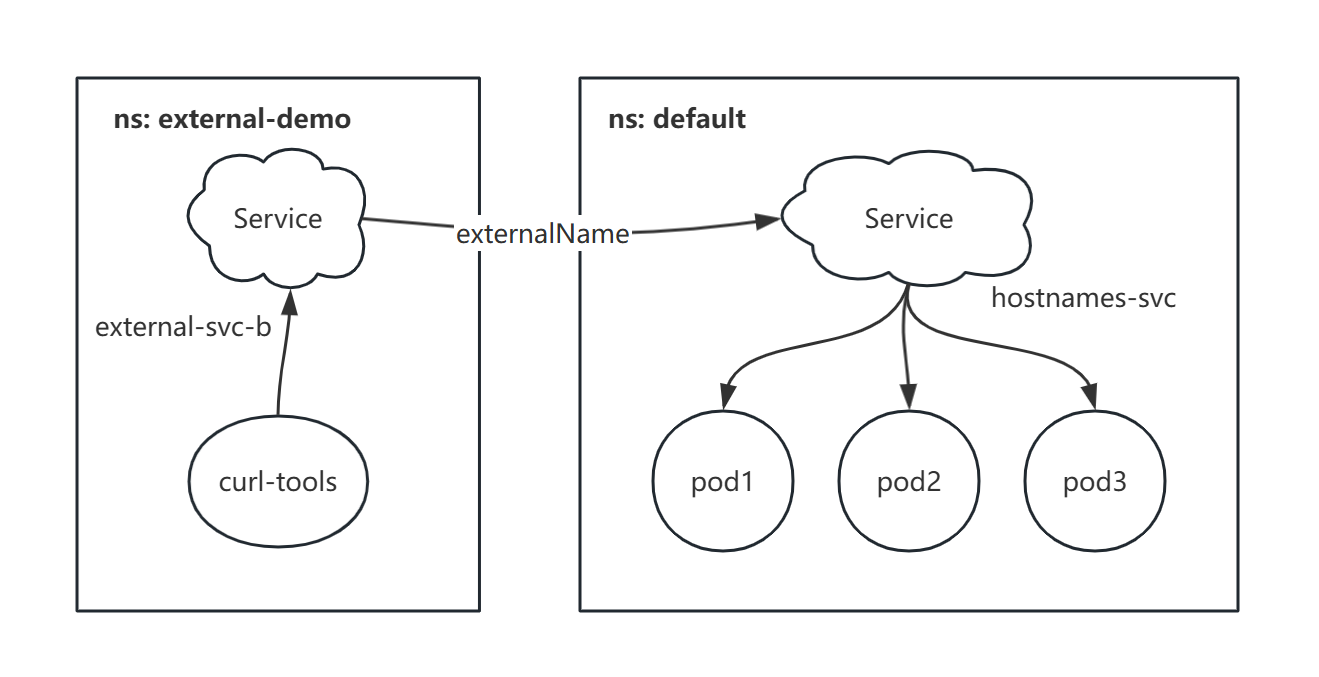
3.3.2、ExternalName 类型 Service
在 external-demo 名称空间下新建一个 Service:
XML
apiVersion: v1
kind: Service
metadata:
name: external-svc-b
namespace: external-demo
spec:
type: ExternalName
externalName: hostnames-svc.default.svc.cluster.local
selector:
app: hostnames
ports:
- port: 80
protocol: TCP
- type: ExternalName。
- externalName:指定 default 名称空间下的完全限定服务名。
相当于给 hostnames-svc 服务创建了一个软连接。
- targetPort:在这种情况下可以忽略。
bash
kubectl get svc -n=external-demo
此时,在 external-demo 名称空间下的 curl-tools 就可以直接访问这个服务,请求会被代理到 default 名称空间下的 Pod: