🚀 Ambari 集成 Hudi 成功,构建流批统一数据湖组件
近期我已完成 Apache Hudi 在 Ambari 体系下的服务集成,支持一键安装、全节点 CLI 部署、组件生命周期托管,标志着 Hudi 在大数据平台体系中的可控性进一步增强。
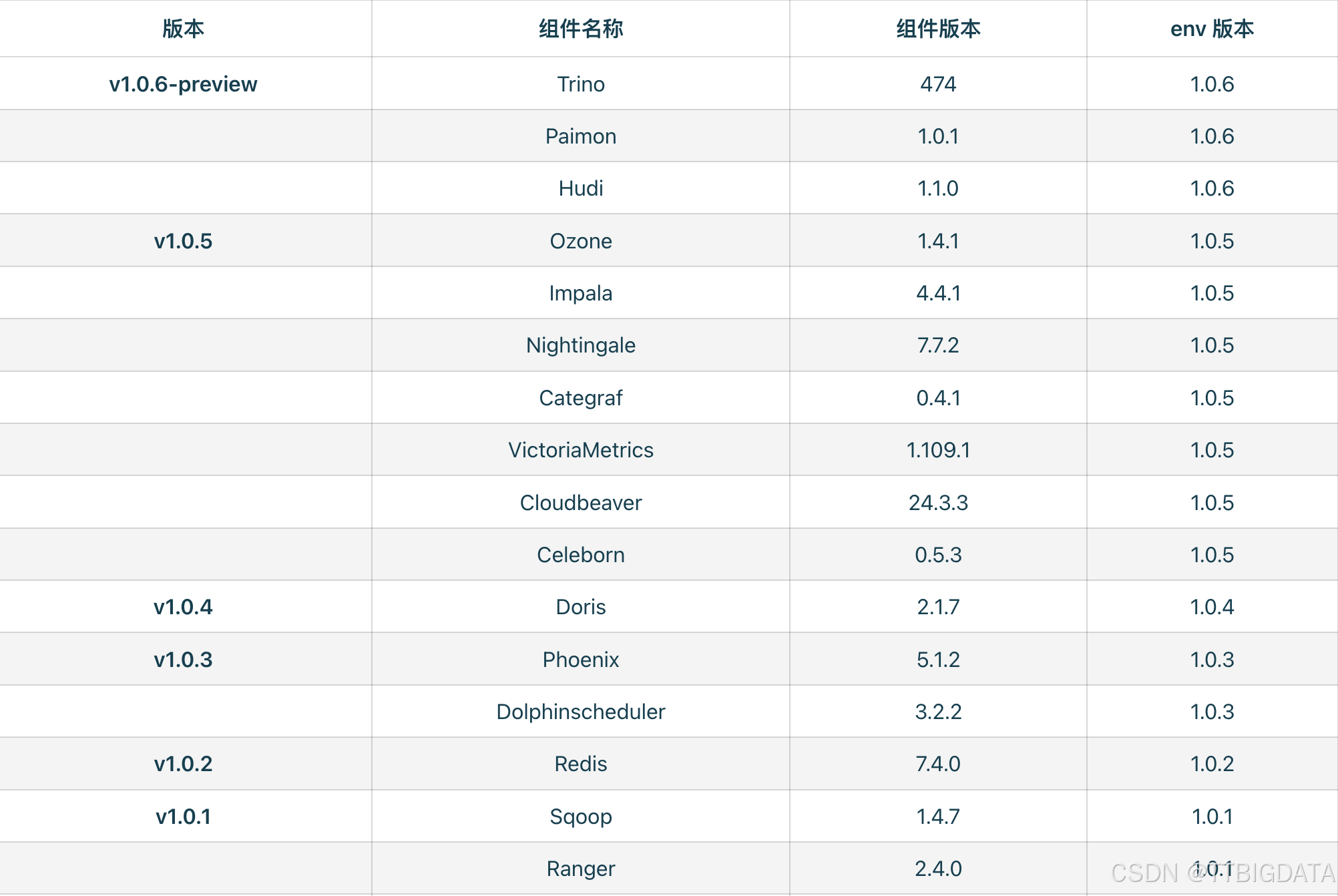
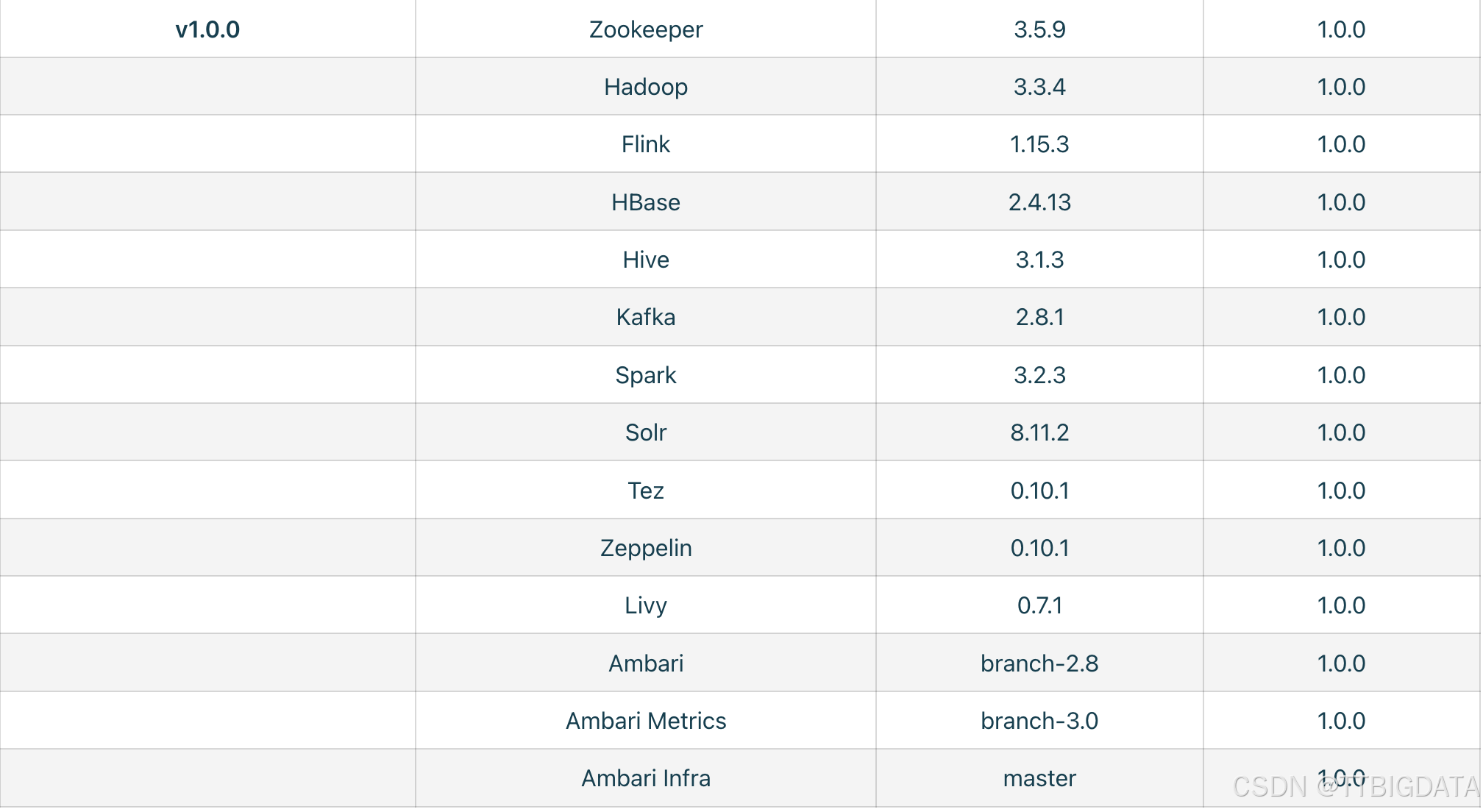
总的版本集成度可参考
🔍 为什么选择集成 Hudi?
Apache Hudi 作为数据湖领域的重要组件,提供了对 增量更新、批量插入、数据去重、流式写入 的完整支持,是构建湖仓一体化架构的关键拼图。
在实际项目中,我们经常面临如下场景:
- 用户行为日志持续写入,需要保留最新快照
- 实时任务希望与离线查询共享数据源
- Trino、Spark SQL 查询需无缝对接湖上数据
而 Hudi 恰好能提供:
- Copy-on-Write / Merge-on-Read 模式灵活切换
- 快速增量拉取(基于 commit timeline)
- 数据一致性保障 + 高效 compaction 支持
🔧 已完成哪些集成工作?
本次集成以 Ambari 为核心管理平台,基于 HDP/BIGTOP 架构,在原有组件体系下扩展了对 Hudi 的服务支持:
| 集成能力 | 实现说明 |
|---|---|
| 服务注册 | Hudi 以 Client 模式接入,无需 Master/Worker |
| 多节点部署 | 支持一键部署至任意节点,自动配置软链 |
| CLI 启动 | 支持通过 hudi-cli 执行元数据调试、Compaction 操作等 |
| 配置模板化 | hudi-env.sh、日志、lib 目录规范化 |
| 控制台集成 | 状态可视化、安装进度可视化、失败日志可回溯 |
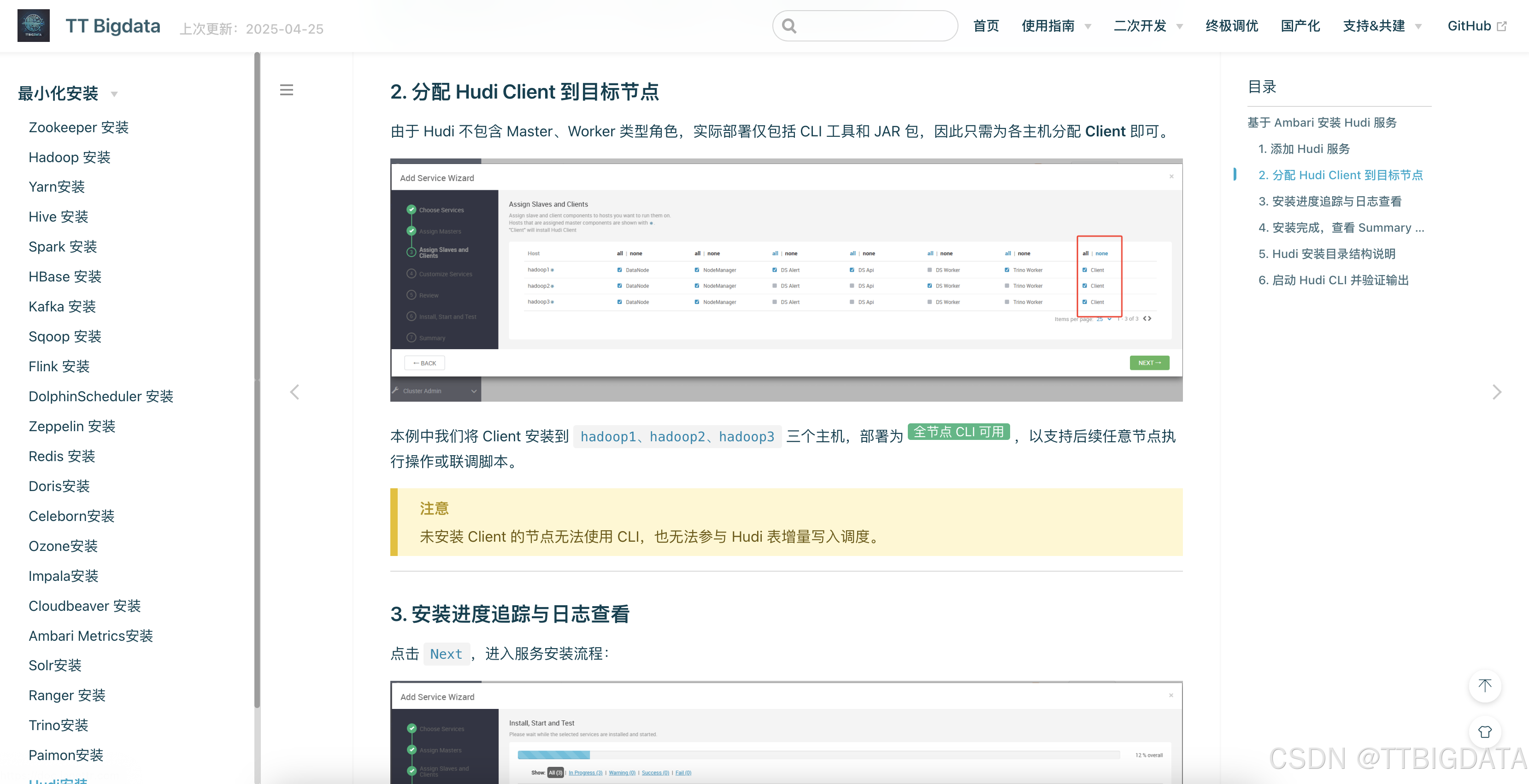
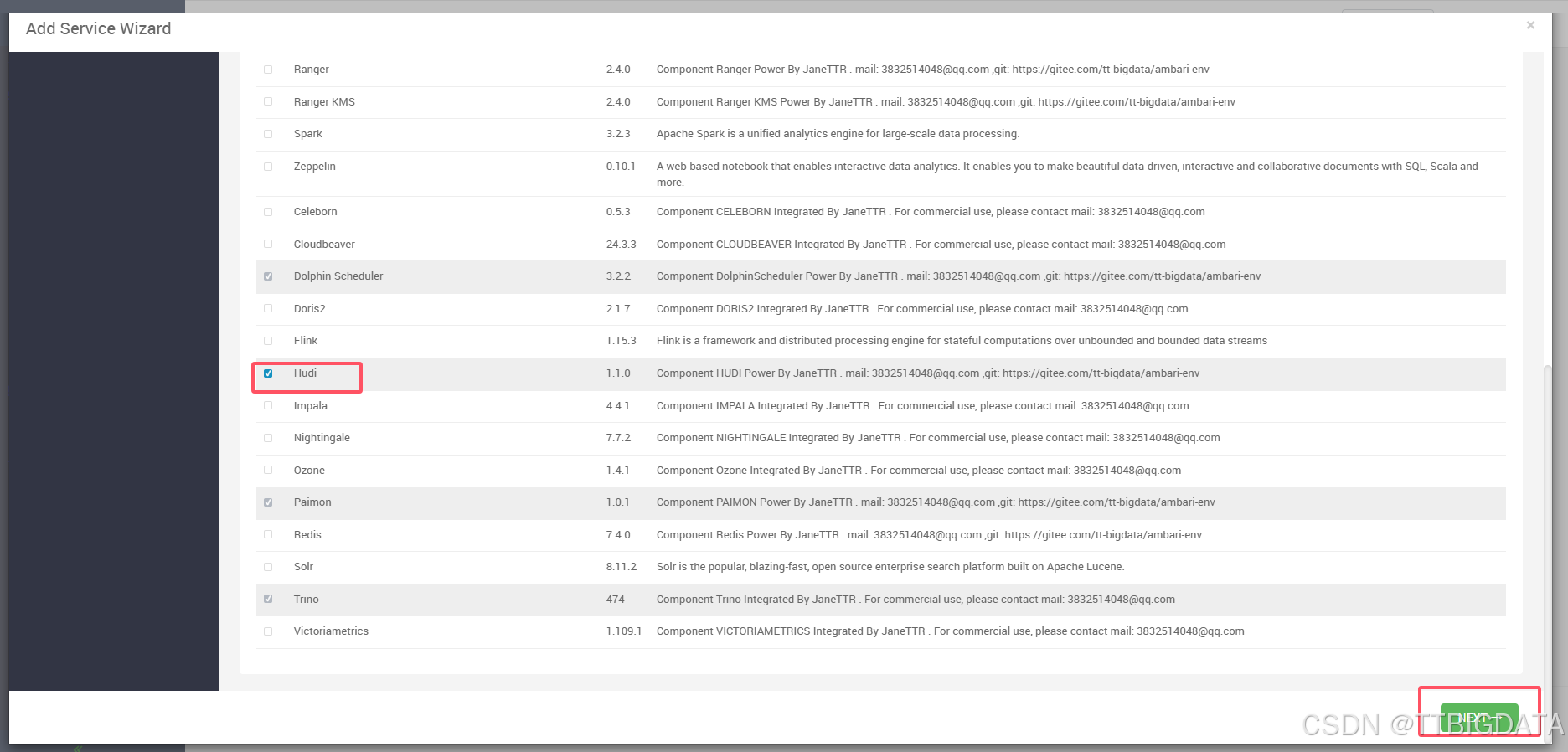
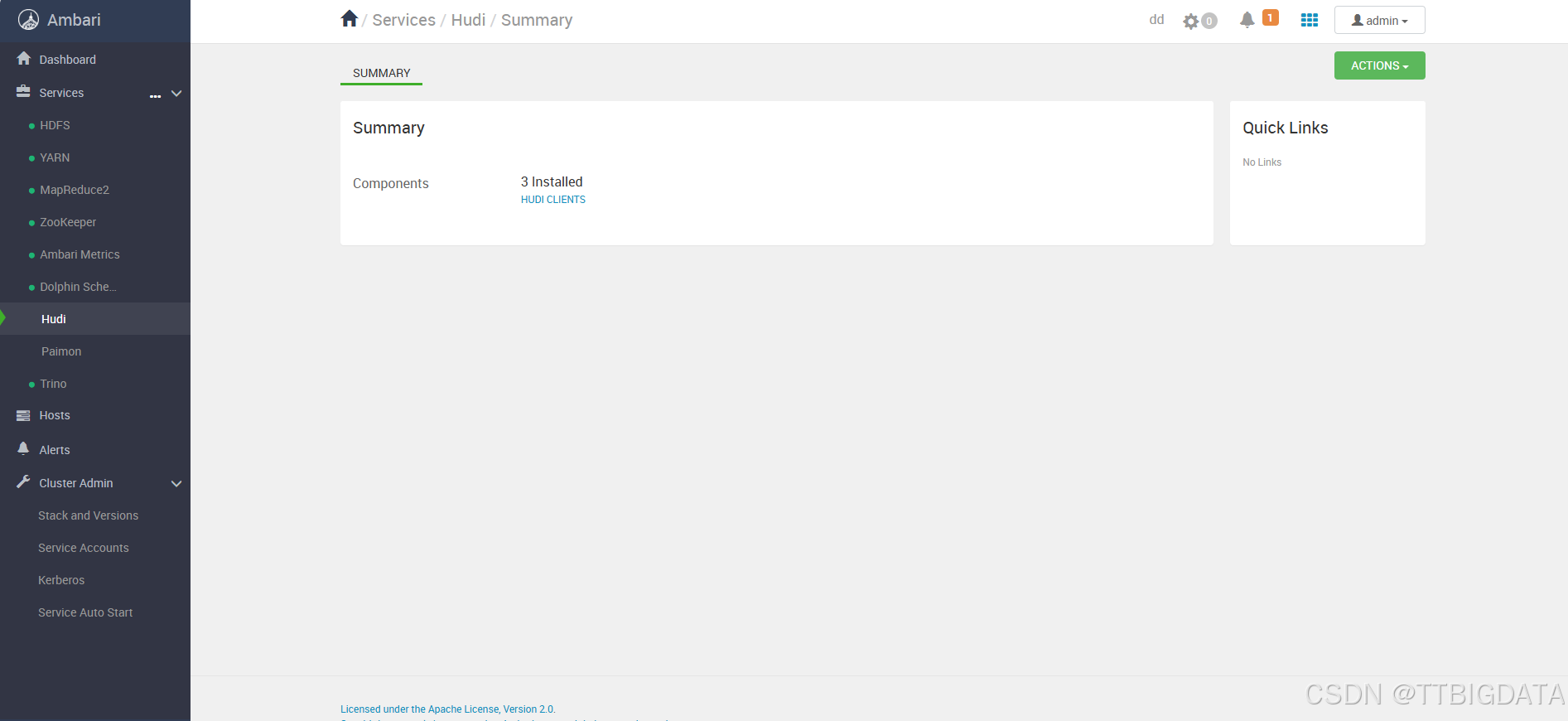
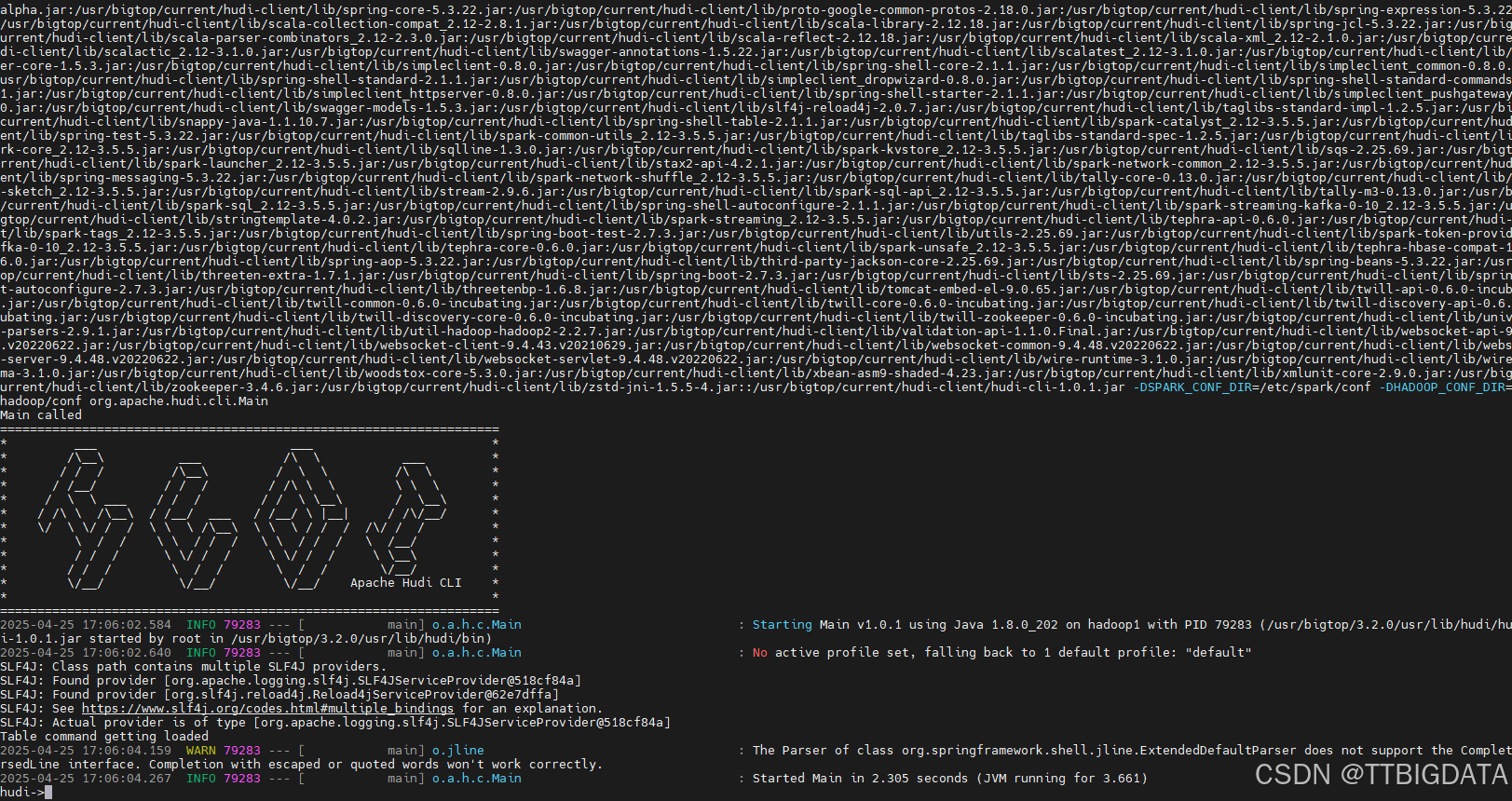
如下是部署过程截图示意👇:
- 服务选择:
- 安装完成:

- CLI 启动成功:
✅ 支持的核心能力
当前版本内已支持以下能力:
- Hudi CLI 工具全功能(表操作、timeline 查看、metadata 检查)
- Spark 支持(含 Spark 任务写入、读取)
- HDFS/Hive 兼容目录结构
- Trino Catalog 读取支持(需额外配置)
支持版本:
| 组件 | 版本 |
|---|---|
| Hudi | 1.1.0 |
| Spark | 3.2+ |
| Hive Catalog | 可选 |
| Trino | 474+ |
📚 如何安装
如果你也在做基于 Ambari 的组件扩展、数据湖架构实践,欢迎一起探讨。
bash
如何安装可参考:https://doc.janettr.com/