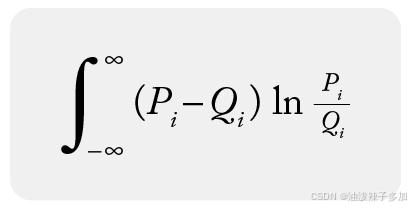
一、PSI(Population Stability Index)的定义与原理
-
概念
- PSI 用于衡量"预期分布"(通常取训练集或基准样本)与"实际分布"(验证集、线上新数据等)在各分箱(score bin)上的偏移程度。
- 数值越小表示两者分布越接近,模型或特征越稳定;数值越大则提示分布发生了显著漂移。
-
计算公式
P S I = ∑ i = 1 K ( p i − q i ) ln ( p i q i ) \mathrm{PSI} = \sum_{i=1}^K \bigl(p_i - q_i\bigr)\,\ln\Bigl(\tfrac{p_i}{q_i}\Bigr) PSI=i=1∑K(pi−qi)ln(qipi)其中:
- p i p_i pi:第 i i i个分箱中"实际分布"占比
- q i q_i qi:第 i i i个分箱中"预期分布"占比
- K K K:分箱总数(常见10~20个)
-
分箱策略
- 等频分箱:每箱样本数相同,能保证每箱都有统计意义,适合数据量稳定的场景。
- 等距分箱:每箱取值区间相同,能直观反映分数分布形态。
- 自定义分箱:结合业务经验对重要阈值(如决策边界)进行细化分箱。
- 注意 :极端值或零占比会导致 ln ( p i / q i ) \ln(p_i/q_i) ln(pi/qi)趋于无穷,可在计算前对 p i p_i pi, q i q_i qi 做小量平滑(如加 ϵ = 1 0 − 6 \epsilon=10^{-6} ϵ=10−6)。
-
常用阈值
- PSI < 0.10:分布基本无漂移,模型/变量稳定
- 0.10 ≤ PSI < 0.25:存在中等漂移,需要关注
- PSI ≥ 0.25:分布显著漂移,建议排查并重新建模
二、PSI计算流程
确定比较对象
- 明确两个需要比较的样本分布:
- 期望分布(expected):通常是模型训练集样本;
- 实际分布(actual) :通常是验证集、线上样本或跨时间段样本。
分箱处理(以训练集为基准)
- 将变量的取值区间划分为多个"箱"(bins):
- 连续变量推荐使用等频或等距分箱;
- 离散变量可以按照原始类别,必要时合并低频类别;
- 分箱数量建议设为 10 或 20,避免过粗或过细。
统计每个分箱的占比
- 在每个分箱中,分别统计 expected 和 actual 样本的数量;
- 转化为百分比(即每个分箱中样本数除以总样本数)形成两个分布。
计算每个分箱的差异值 - 对于每个分箱,计算 expected 和 actual 之间的占比差异;
- 利用差异程度与比值变化评估每个分箱的"变化强度"。
求和得到总体 PSI 值 - 将所有分箱的差异值汇总,得到最终 PSI 指标。
判读 PSI 结果 - 小于 0.1:分布基本一致,变量稳定;
- 0.1 ~ 0.25:轻度偏移,可关注;
- 大于 0.25:显著偏移,建议替换或重新评估。
三、KL 散度(Kullback--Leibler Divergence)的定义与原理
- Shannon 熵
对离散分布 P P P: H ( P ) = − ∑ x P ( x ) ln P ( x ) H(P) = -\sum_x P(x)\,\ln P(x) H(P)=−x∑P(x)lnP(x) - KL 散度 D K L ( P ∥ Q ) = ∑ x P ( x ) ln P ( x ) Q ( x ) D_{\mathrm{KL}}(P \,\|\, Q) = \sum_x P(x)\,\ln\frac{P(x)}{Q(x)} DKL(P∥Q)=x∑P(x)lnQ(x)P(x)
- 物理含义 :用分布 Q Q Q来近似真实分布 P P P,需要额外的信息量(Nats)。
- 性质 :
- 非负性: D K L ( P ∥ Q ) ≥ 0 D_{\mathrm{KL}}(P\|Q)\ge0 DKL(P∥Q)≥0,当且仅当P=QP=Q时为0;
- 非对称性: D K L ( P ∥ Q ) ≠ D K L ( Q ∥ P ) D_{\mathrm{KL}}(P\|Q) \neq D_{\mathrm{KL}}(Q\|P) DKL(P∥Q)=DKL(Q∥P)。
四、KL 散度与 PSI 之间的关系
将 PSI 公式展开,可分解为两部分:
P S I = ∑ i ( p i − q i ) ln p i q i = ∑ i p i ln p i q i − ∑ i q i ln p i q i = D K L ( P ∥ Q ) + D K L ( Q ∥ P ) \begin{aligned} \mathrm{PSI} &= \sum_i (p_i - q_i)\ln\frac{p_i}{q_i} \\ &= \sum_i p_i\ln\frac{p_i}{q_i} \;-\; \sum_i q_i\ln\frac{p_i}{q_i} \\ &= D_{\mathrm{KL}}(P\|Q) \;+\; D_{\mathrm{KL}}(Q\|P) \end{aligned} PSI=i∑(pi−qi)lnqipi=i∑pilnqipi−i∑qilnqipi=DKL(P∥Q)+DKL(Q∥P)
- 解读:PSI=双向 KL 散度之和,是一种对称化的分布差异度量。
- 优势 :相比单向的 KL 散度,PSI 同时考虑了 P → Q P\to Q P→Q和 Q → P Q\to P Q→P两个方向的信息损失,更为全面。
五、PSI 在实际风控业务中的应用
-
特征筛选
- 以训练期(INS)样本分布为基准,按月/周计算新样本(OOT/OOS)上各特征的 PSI。
- 剔除 PSI 较高(>0.25)的特征,确保入模变量的长期稳定。
-
模型监控
- 模型上线后,持续按时间窗口计算整体分数 PSI 曲线。
- 当 PSI 突然跳升时,需立刻排查:
- 是否样本群体发生变化?
- 是否数据源采集出异常?
- 是否外部政策或市场波动影响?
-
多层次评估
- 时间粒度:可分月、周、日。
- 层次粒度:贷款层面、申请层面、核心人群分层。
- 联合分析:结合 EDD(探索性数据分析)中的分位数对比,判断分布偏移的方向。
-
最佳实践
- 平滑处理:对零值、极小占比做加 ϵ \epsilon ϵ避免数值问题。
- 动态阈值:可结合业务接受度灵活调整 PSI 报警线。
- 可视化:制作 PSI 报表(折线图 + 报警带)便于一目了然。
六、PSI 的 Python 计算示例
python
import numpy as np
import pandas as pd
def calculate_psi(expected, actual, bins=10, eps=1e-6):
"""
计算 Population Stability Index(PSI)。
参数:
expected: array-like, 基准样本的一维数值 array
actual: array-like, 验证样本的一维数值 array
bins: int or sequence, 分箱数或分箱边界
eps: float, 用于平滑避免除零/对数问题
返回:
psi_value: float, PSI 总值
psi_table: DataFrame, 各箱的 q, p, psi_i
"""
# 1. 生成分箱:使用训练样本的分位数
if isinstance(bins, int):
quantiles = np.linspace(0, 1, bins + 1)
bin_edges = np.unique(np.quantile(expected, quantiles))
else:
bin_edges = np.array(bins)
# 2. 计算各箱占比
e_counts, _ = np.histogram(expected, bins=bin_edges)
a_counts, _ = np.histogram(actual, bins=bin_edges)
q = e_counts / e_counts.sum()
p = a_counts / a_counts.sum()
# 3. 平滑
q = np.where(q == 0, eps, q)
p = np.where(p == 0, eps, p)
# 4. 计算每箱 psi,以及总 psi
psi_i = (p - q) * np.log(p / q)
psi_value = np.sum(psi_i)
# 5. 构造结果表格
psi_table = pd.DataFrame({
'bin_left' : bin_edges[:-1],
'bin_right': bin_edges[1:],
'exp_pct' : q,
'act_pct' : p,
'psi_i' : psi_i
})
return psi_value, psi_table
# 示例用法
if __name__ == '__main__':
# 假设 exp_scores, act_scores 为两个一维 numpy 数组
exp_scores = np.random.normal(loc=0.5, scale=0.1, size=10000)
act_scores = np.random.normal(loc=0.52, scale=0.12, size=10000)
psi_val, psi_df = calculate_psi(exp_scores, act_scores, bins=10)
print(f"总体 PSI = {psi_val:.4f}")
print(psi_df)七、疑问
为什么KL 散度可以描述分布稳定性?
KL 散度(Kullback--Leibler divergence)之所以能够用来描述分布的"稳定性",主要基于以下几点:
非负性与零点条件 D K L ( P ∥ Q ) = ∑ x P ( x ) ln P ( x ) Q ( x ) D_{\mathrm{KL}}(P\|Q) = \sum_x P(x)\,\ln\frac{P(x)}{Q(x)} DKL(P∥Q)=x∑P(x)lnQ(x)P(x)
对任意两离散分布 P , Q P,Q P,Q,有
- D K L ( P ∥ Q ) ≥ 0 D_{\mathrm{KL}}(P\|Q)\ge0 DKL(P∥Q)≥0,
- 当且仅当 P = Q P=Q P=Q时, D K L ( P ∥ Q ) = 0 D_{\mathrm{KL}}(P\|Q)=0 DKL(P∥Q)=0。
这就保证了:两分布完全一致时,KL 散度为零;分布越不一致,KL 散度越大
信息增益的度量
从信息论角度,KL散度可以理解为"如果真实分布是 P P P,却用 Q Q Q去描述,需要额外多少信息量 N a t s Nats Nats才能不丢失信息"。
- 当用基准(训练)分布 Q Q Q去预测或编码新数据,其实新数据的真实分布是 P P P;
- KL 散度正是衡量这种"模型失配"导致的平均额外信息量或意外程度。
如果分布没有漂移(即在线数据与训练数据分布相同),这种"失配信息"就为零;如果漂移严重,则额外信息量大,KL 散度也大。
PSI描述稳定性的直观说明?
- PSI 会把"新数据占比 -- 训练数据占比"算出来,再乘以一个"惩罚系数"(就是 ln ( 新占比 旧占比 ) \ln(\tfrac{\text{新占比}}{\text{旧占比}}) ln(旧占比新占比))。
- 这个惩罚系数越大,表示"在这个区间里人头变化的相对程度"越大,我们就更要"给分布漂移一个高分"------也就是 PSI 的那一部分越大。
- 最后把所有区间的"差异分"加起来,就得到一个总分:PSI。
- 分数越低,说明新旧两批样本在所有拼图块里分布得越来越一样,越稳定;分数越高,就代表某些区间出现了明显偏移,模型或特征可能不再适用了。