flume整合Kafka
需求1:利用flume监控某目录中新生成的文件,将监控到的变更数据发送给kafka,kafka将收到的数据打印到控制台:
1.查看topic
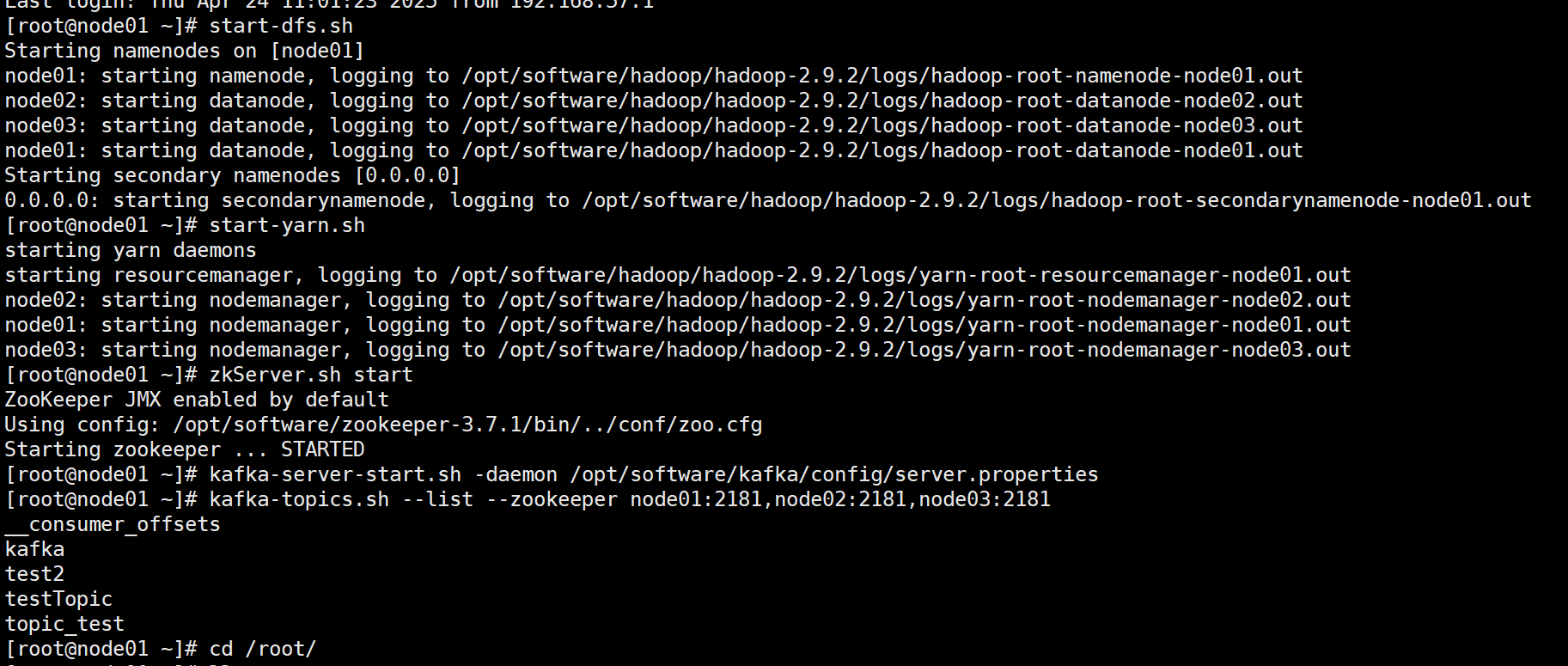
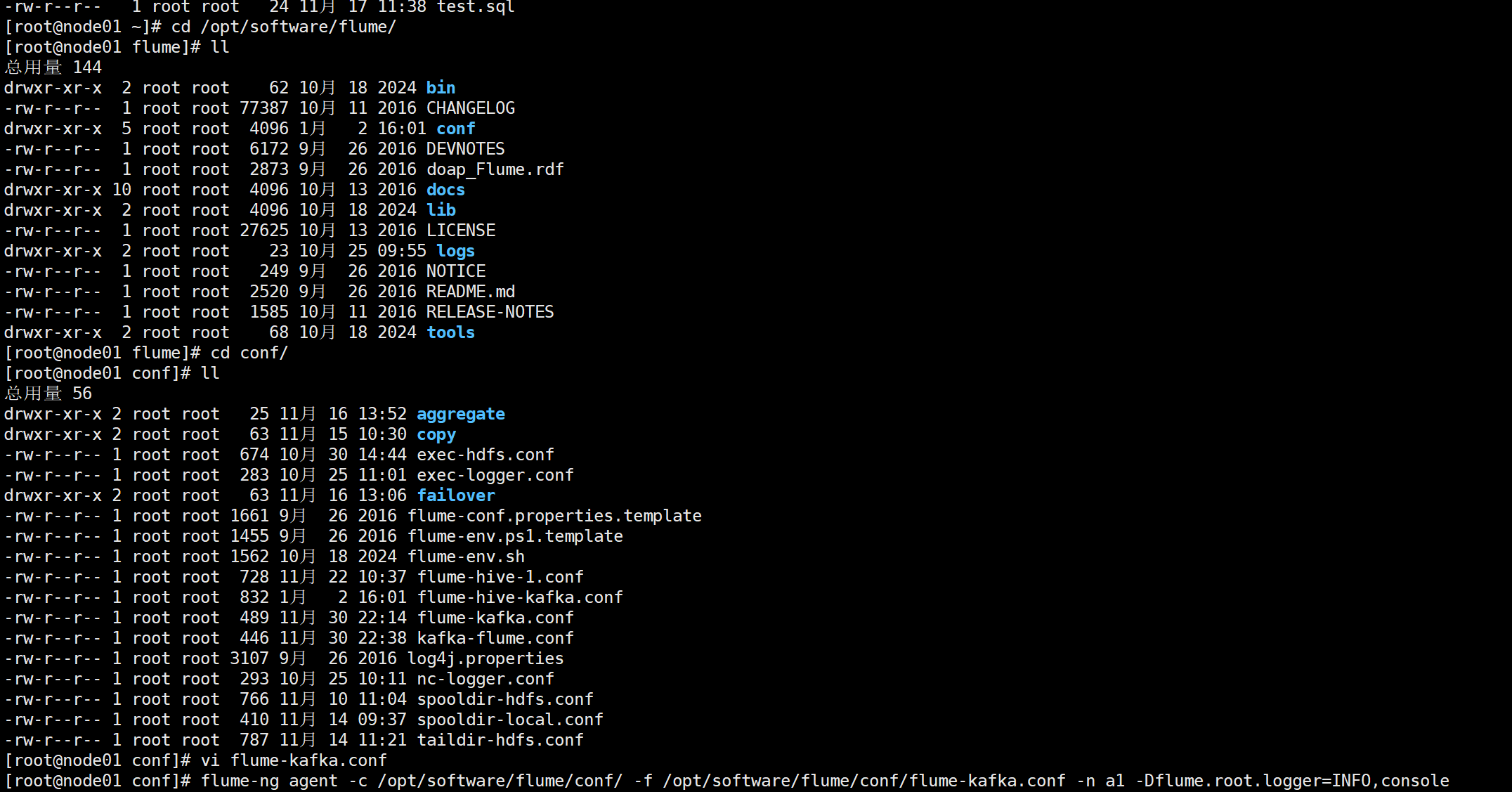
2.编辑flume-Kafka.conf,并启动flume
3.启动Kafka消费者

4.新增测试数据

5.查看Kafka消费者控制台

需求2:Kafka生产者生成的数据利用Flume进行采集,将采集到的数据打印到Flume的控制台上。
1编辑kafka-flume.conf,并启动flume
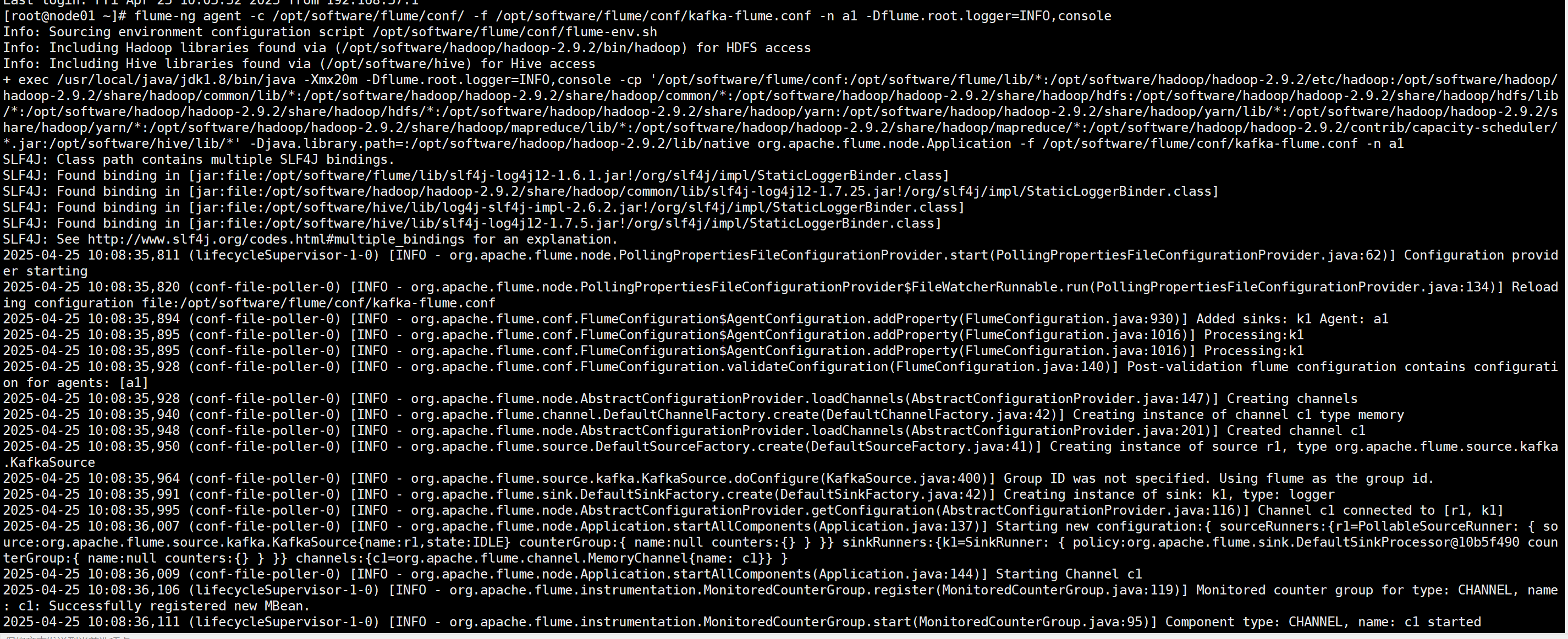
2.启动Kafka生产者,并在生产者种写入数据
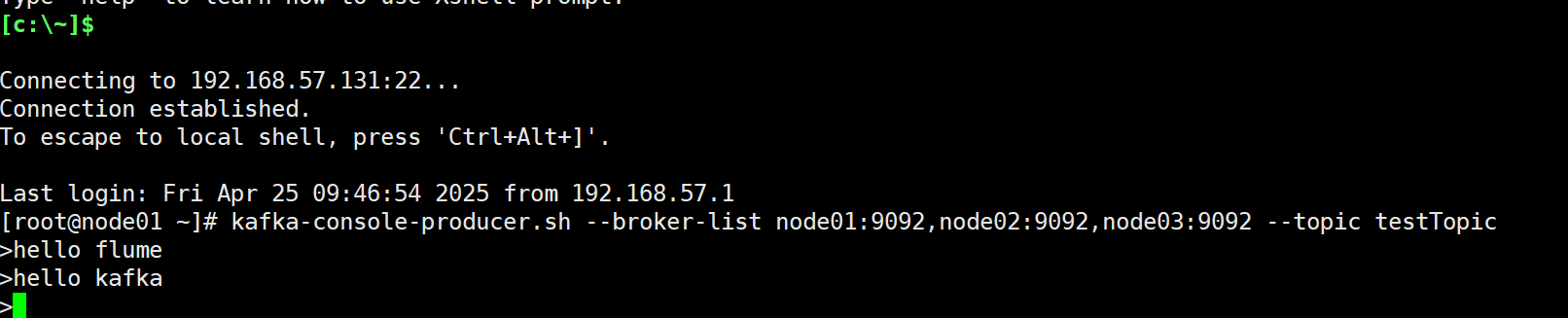
3.查看flume采集的数据

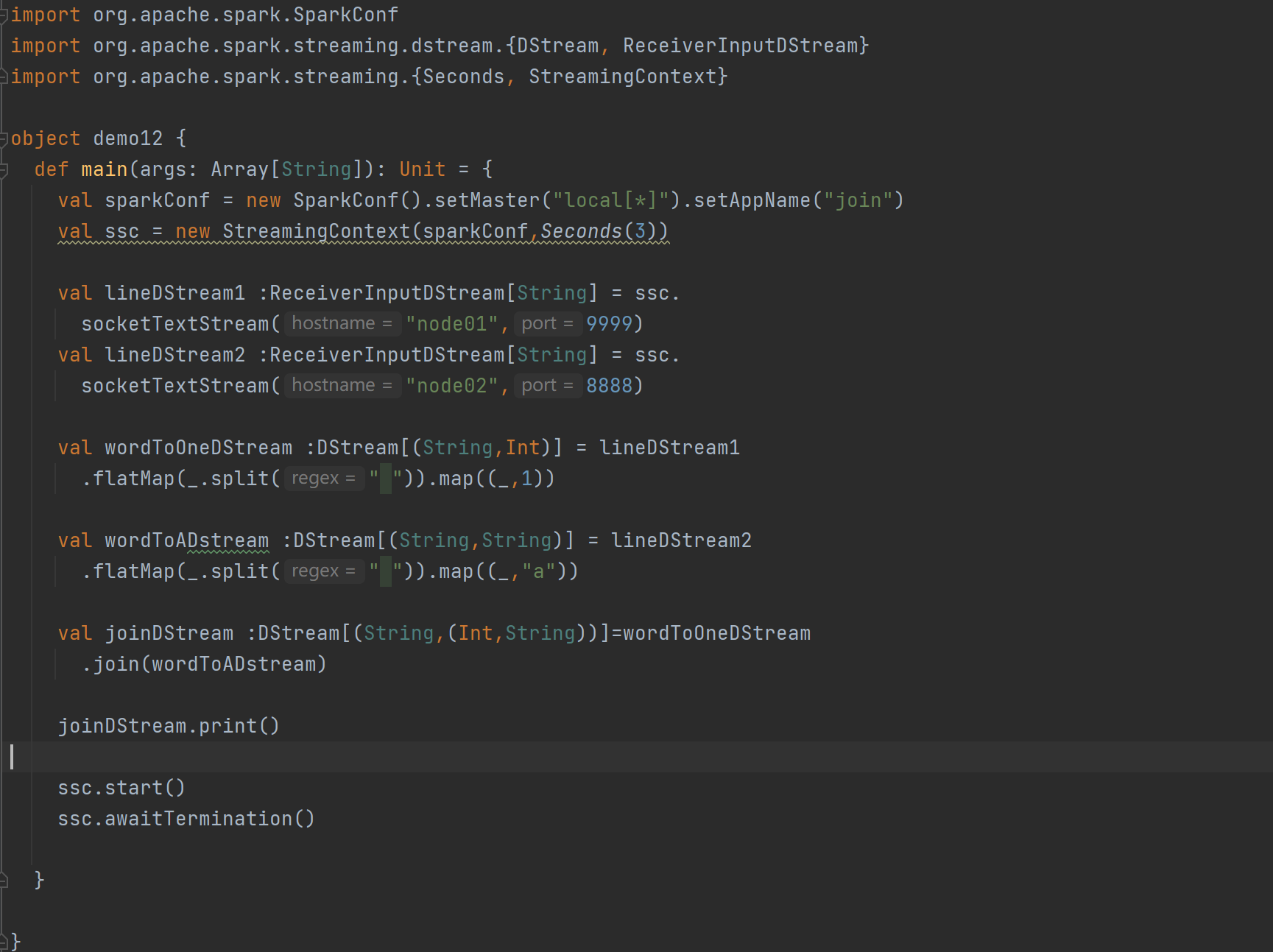
DStream转换
DStream 上的操作与 RDD 的类似,分为 Transformations(转换)和 Output Operations(输出)两种,此外转换操作中还有一些比较特殊的原语,如:updateStateByKey()、transform()以及各种 Window 相关的原语。
Transform
Transform 允许 DStream 上执行任意的 RDD-to-RDD 函数。即使这些函数并没有在 DStream的 API 中暴露出来,通过该函数可以方便的扩展 Spark API。该函数每一批次调度一次。其实也就是对 DStream 中的 RDD 应用转换。
代码案例
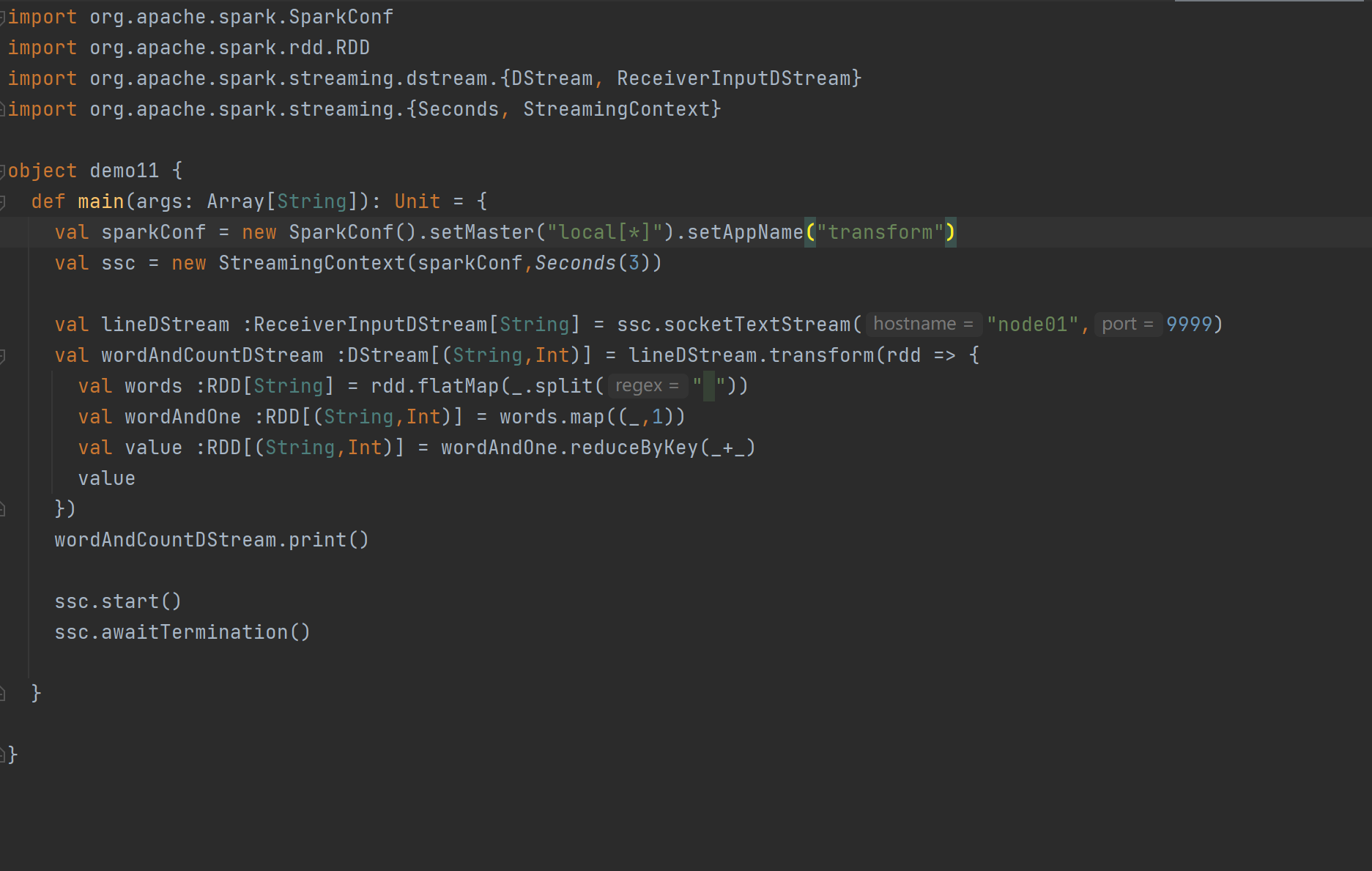

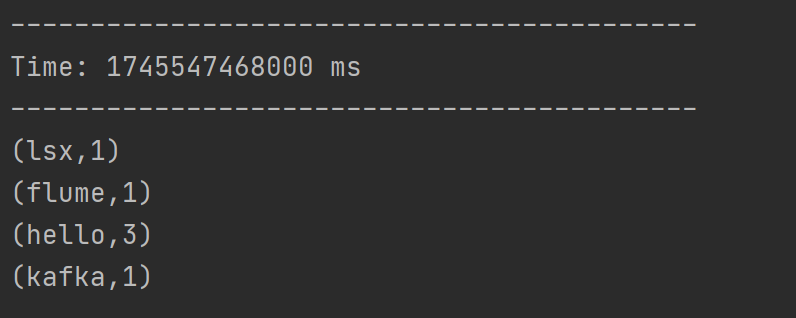
join
两个流之间的 join 需要两个流的批次大小一致,这样才能做到同时触发计算。计算过程就是对当前批次的两个流中各自的 RDD 进行 join,与两个 RDD 的 join 效果相同
代码案例