一、Kafka
- Topic相关
生产数据的命令涉及脚本、broker list、主机号和端口号、topic名称等要素;消费数据命令中的参数名与生产数据有所不同,并且如果要从头开始消费需要添加特定参数,同时分区间的数据无序但分区中的数据有序,还需指定消费者组。
- Kafka作为Spark数据源创建DataFrame的方式
采用的是direct API,由计算的executor主动消费数据,避免了因接收速度大于计算速度而产生的内存溢出。
二、基于Spark Streaming读取Kafka数据的小案例
- 代码实现步骤
首先是导入依赖到POM文件中。
在代码方面,配置Spark相关对象,设定Kafka的相关参数(包括Kafka运行的主机号和端口号、消费者所在组、字符串序列方式等四个参数)。
创建Spark Streaming对象(SSC),涉及多个参数(原封不动写上的连接对象、分区分配策略、消费者消费策略等),然后通过读取Kafka数据创建DataFrame。
对读取的数据进行操作,如通过map映射只取数据中的值部分,后续进行词频计算相关的操作(包括split、flatMap、map、reduceByKey等操作),最后处理开始、停止相关逻辑(一般手动停止或者遇到异常停止)。
- 运行流程
开启Kafka集群,确保在node01、node02、node03等节点都能找到Kafka。
创建名为Kafka的topic
打开集群
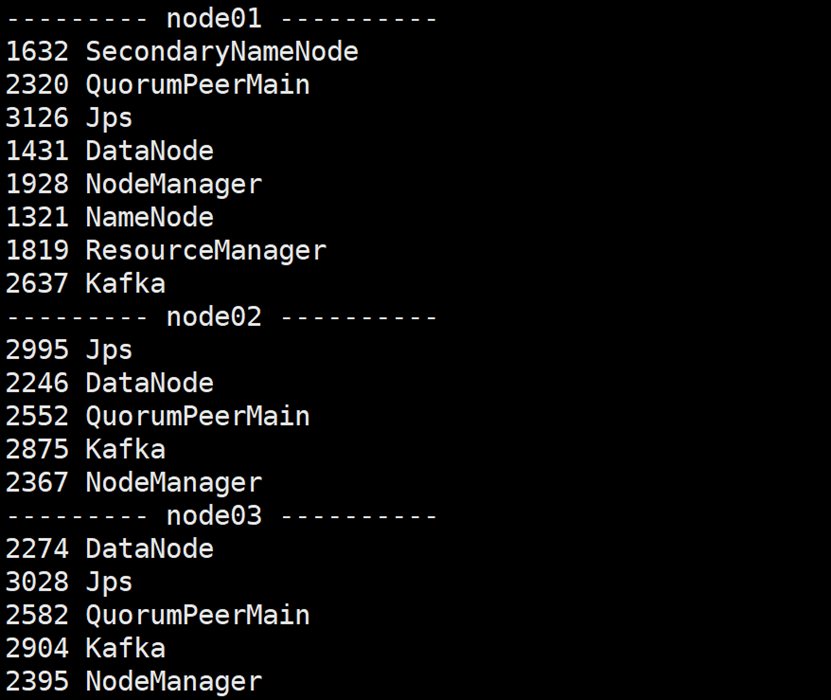
开启Kafka生产者,产生数据
kafka-console-producer.sh --broker-list node01:9092,node02:9092,node03:9092 --topic kafka