目录
- 前言
- [1. Lambda架构概述](#1. Lambda架构概述)
-
- [1.1 什么是Lambda架构?](#1.1 什么是Lambda架构?)
- [1.2 Lambda架构的背景与起源](#1.2 Lambda架构的背景与起源)
- [2. Lambda架构的核心特点](#2. Lambda架构的核心特点)
-
- [2.1 容错性与高可用性](#2.1 容错性与高可用性)
- [2.2 实时性与批处理的平衡](#2.2 实时性与批处理的平衡)
- [2.3 高度可扩展性](#2.3 高度可扩展性)
- [2.4 系统复杂性](#2.4 系统复杂性)
- [3. Lambda架构的组成部分](#3. Lambda架构的组成部分)
-
- [3.1 批处理层(Batch Layer)](#3.1 批处理层(Batch Layer))
- [3.2 实时处理层(Speed Layer)](#3.2 实时处理层(Speed Layer))
- [3.3 查询服务层(Serving Layer)](#3.3 查询服务层(Serving Layer))
- [4. Lambda架构的应用场景](#4. Lambda架构的应用场景)
-
- [4.1 大数据分析](#4.1 大数据分析)
- [4.2 需要高可用性与容错的系统](#4.2 需要高可用性与容错的系统)
- [4.3 实时数据处理与批量分析相结合的应用](#4.3 实时数据处理与批量分析相结合的应用)
- [5. Lambda架构的挑战与不足](#5. Lambda架构的挑战与不足)
-
- [5.1 开发与运维的复杂性](#5.1 开发与运维的复杂性)
- [5.2 数据一致性问题](#5.2 数据一致性问题)
- [5.3 性能瓶颈](#5.3 性能瓶颈)
- [6. 结语](#6. 结语)
前言
在大数据处理领域,如何高效地处理海量数据同时又能快速响应实时需求,是一个重要的技术挑战。随着数据量的不断增长和实时需求的提升,传统的数据架构已难以满足现代企业的需求。Lambda架构应运而生,它结合了批处理和实时流处理的优点,提供了一种平衡性能和数据精确度的解决方案。
Lambda架构能够同时处理大规模数据的历史分析和实时流数据的即时处理,是应对大数据挑战的一种有效架构。本文将对Lambda架构进行详细解读,包括其基本概念、特点、构成部分及应用场景,最后还将探讨该架构的优缺点和挑战。
1. Lambda架构概述
1.1 什么是Lambda架构?
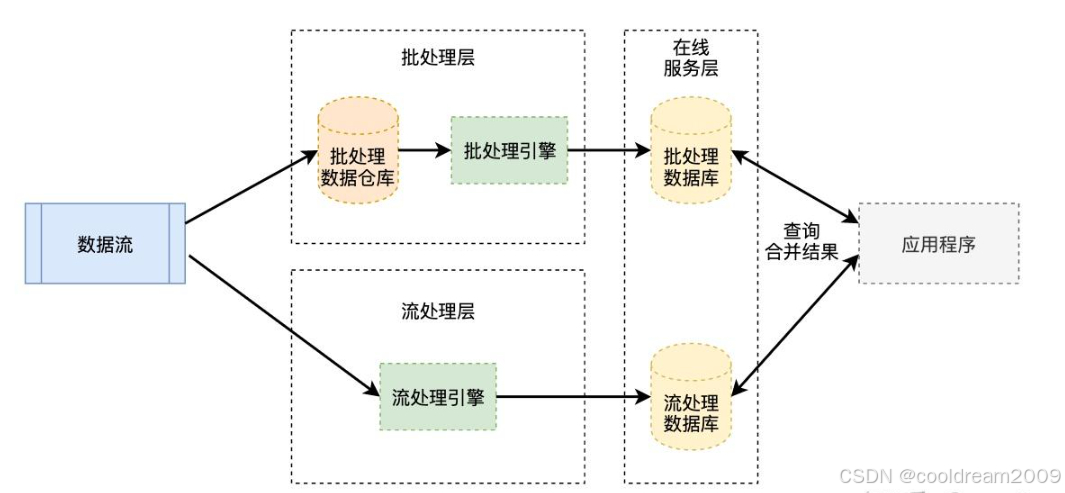
Lambda架构是一种用于处理大数据的分布式架构模式,它通过将数据处理分为批处理层、实时处理层和查询服务层,以满足大规模数据的存储、处理和查询需求。Lambda架构的核心思想是通过分层设计,实现数据的高效处理,同时兼顾实时性和准确性。
该架构的设计目标是解决两大问题:一方面是数据量的急剧增加,另一方面是需要快速响应的数据处理需求。Lambda架构通过批处理层处理大量历史数据,利用实时层快速处理新到的数据,并通过服务层将批量处理结果和实时处理结果整合,为用户提供实时且准确的数据查询。
1.2 Lambda架构的背景与起源
Lambda架构最早由Nathan Marz提出,他在处理大数据时发现传统的数据处理架构无法同时兼顾实时性和精确性,特别是在需要处理不断增长的海量数据时。Lambda架构便是为了解决这一问题而诞生的,主要是希望通过三层架构模式,分别承担不同的功能需求。
Lambda架构不仅仅是一种理论上的架构设计,它已经在许多大数据处理系统中得到了实际应用,如Apache Hadoop、Apache Spark等都可以实现Lambda架构的设计思路。
2. Lambda架构的核心特点
2.1 容错性与高可用性
Lambda架构的设计高度关注系统的容错性。由于数据处理被分为多个独立的层次,即便其中一层出现故障,其他层也能够继续工作。特别是在批处理层出现问题时,实时处理层可以接管数据的处理工作,保证系统的稳定运行。通过这种方式,Lambda架构能够有效避免单点故障,提升系统的可用性和可靠性。
2.2 实时性与批处理的平衡
Lambda架构的一个核心特点是能够同时满足实时处理和批量处理的需求。批处理层能够处理历史数据,并生成精确的结果,而实时处理层则能够快速响应数据的变化,提供近乎实时的数据反馈。这种设计使得Lambda架构在面对大数据时能够在保证数据精度的同时,也能做到低延迟的响应。
2.3 高度可扩展性
Lambda架构天然具备良好的可扩展性。每个处理层都可以独立扩展,以应对不断增长的数据量和计算需求。例如,当数据量增大时,可以通过增加更多的计算节点来扩展批处理层的处理能力;同样,实时处理层也可以通过增加处理流的数据源节点来提高系统的吞吐量。通过水平扩展,Lambda架构能够应对大规模数据的挑战。
2.4 系统复杂性
尽管Lambda架构具有明显的优势,但也伴随着较高的系统复杂性。开发者需要同时处理批处理和实时处理两条数据流,分别使用不同的技术栈进行开发和维护。此外,数据的合并与一致性问题也使得Lambda架构的实现和维护工作较为繁琐。特别是在数据量和复杂度较高的情况下,Lambda架构的运维成本和技术要求将大幅增加。
3. Lambda架构的组成部分
3.1 批处理层(Batch Layer)
批处理层是Lambda架构的核心组成部分,它负责处理大规模历史数据的计算。通常情况下,批处理层会定期读取海量的数据集,进行复杂的计算,并生成批量数据视图,这些数据视图将用于后续的查询和分析。
批处理层的计算通常具有较高的延迟,但能够保证计算结果的准确性。与实时层不同,批处理层并不关注数据流的速度,它专注于对历史数据的深度分析。例如,常见的技术栈有Apache Hadoop、Apache Spark等,它们能够高效地处理分布式大数据集,提供强大的计算能力和容错性。
3.2 实时处理层(Speed Layer)
实时处理层负责对新到的数据进行实时处理,它能够快速响应数据的变化,及时计算出数据的近似结果。由于其处理的是流数据,实时处理层通常对数据的精确度有一定的容忍度,重点是保证低延迟和高吞吐量。
实时处理层一般使用如Apache Kafka、Apache Storm、Apache Flink等流处理框架,这些框架专门用于处理大规模的实时数据流,并能够高效地计算和更新数据。实时层的结果通常是近似值,这一点与批处理层的精确结果形成对比。
3.3 查询服务层(Serving Layer)
查询服务层是Lambda架构的最后一层,负责将批处理层和实时处理层的结果进行整合,并为用户提供查询接口。服务层能够将实时处理和批处理的结果合并,提供给用户一个统一的查询接口。在这一层,用户可以对数据进行快速查询,并获得最新的计算结果。
查询服务层的设计通常注重低延迟的查询响应,它需要高效地处理和展示批处理和实时数据的合并结果。常见的技术实现包括HBase、Cassandra等分布式数据库,它们能够提供高性能的存储和查询能力,支持大规模的数据读取和写入。
4. Lambda架构的应用场景
4.1 大数据分析
Lambda架构在大数据分析中得到了广泛应用。随着数据量的不断增大,传统的数据处理架构往往难以满足实时与精度的双重需求。Lambda架构通过批处理层处理历史数据,提供准确的数据分析结果;同时通过实时处理层对实时数据流进行快速响应,确保系统在数据变化时能够立即做出反应。这使得Lambda架构特别适用于数据量庞大且需要快速响应的场景,如实时推荐系统、实时日志分析等。
4.2 需要高可用性与容错的系统
在很多大数据应用中,系统的高可用性和容错性至关重要。例如,金融、医疗等领域的数据处理系统要求具备高度的稳定性与可靠性。Lambda架构通过将数据处理分为多个层次,每一层都可以独立容错,从而有效避免系统的单点故障。即使某一层出现故障,其他层也能够继续提供服务,保证了系统的持续运行。
4.3 实时数据处理与批量分析相结合的应用
Lambda架构特别适用于那些同时需要实时数据处理与批量数据分析的应用场景。例如,在电商平台,既需要实时处理用户行为数据,以便即时推送推荐商品,又需要定期分析用户的购买习惯,以优化长期的市场营销策略。Lambda架构能够将这两种需求有效结合,为业务提供灵活的数据处理能力。
5. Lambda架构的挑战与不足
5.1 开发与运维的复杂性
Lambda架构虽然在理论上具备较强的优势,但在实践中却面临较高的开发与运维复杂度。开发者需要同时处理两条独立的数据流:批处理流和实时处理流。这要求开发人员掌握两种完全不同的技术栈(如批处理使用Hadoop、实时流处理使用Kafka或Storm),增加了开发和维护的工作量。
5.2 数据一致性问题
由于批处理层与实时处理层分别独立计算,实时层的结果通常是近似值,可能与批处理层的最终结果有所不同。在合并这两部分结果时,如何保证数据的一致性和准确性,成为了Lambda架构中的一个重要挑战。特别是在某些高精度要求的应用中,如何平衡实时处理的近似性与批处理的精确性,是开发者需要解决的难题。
5.3 性能瓶颈
Lambda架构的批处理层与实时处理层各自独立运行,这可能会导致在数据量极大时,系统的性能出现瓶颈。例如,在某些高并发的场景下,实时处理层可能无法快速地计算出结果,而在合并实时结果和批处理结果时,可能会遭遇
延迟问题。因此,在构建Lambda架构时,如何优化性能,避免性能瓶颈,也是一个需要考虑的重要问题。
6. 结语
Lambda架构通过将数据处理分为批处理、实时处理和查询服务三部分,成功地解决了大数据系统中对实时性与精确度的双重需求。尽管其在开发、维护和性能优化上存在一定挑战,但对于大数据处理尤其是需要同时满足高吞吐量和低延迟的应用场景,Lambda架构仍然是一种值得采用的有效设计模式。
随着大数据技术的不断发展,Lambda架构也在不断演进,许多新的框架和工具使得其实现更加高效和灵活。未来,随着技术的成熟,Lambda架构可能会在更多领域得到应用,为各行各业提供强大的数据处理能力。