java使用CMU sphinx语音识别
-
- 一、pom依赖
- 二、下载中文资源包
-
- 1、下载中文资源包(需要其他语言的选择对应的文件夹即可),中文选择Mandarin
- 2、将下载后的文件放到项目中
- 3、代码-识别wav语音文件
- 4、代码-识别实时输入(本地pc未成功)
-
- [4.1 测试端需要有语音输入设备](#4.1 测试端需要有语音输入设备)
一、pom依赖
1、依赖dependency
xml
<!-- CMUSphinx Core Library -->
<dependency>
<groupId>edu.cmu.sphinx</groupId>
<artifactId>sphinx4-core</artifactId>
<version>5prealpha-SNAPSHOT</version>
</dependency>
<!-- CMUSphinx Data Library -->
<dependency>
<groupId>edu.cmu.sphinx</groupId>
<artifactId>sphinx4-data</artifactId>
<version>5prealpha-SNAPSHOT</version>
</dependency>2、配置仓库repository
xml
<repository>
<id>snapshots-repo</id>
<url>https://oss.sonatype.org/content/repositories/snapshots</url>
<releases><enabled>false</enabled></releases>
<snapshots><enabled>true</enabled></snapshots>
</repository>二、下载中文资源包
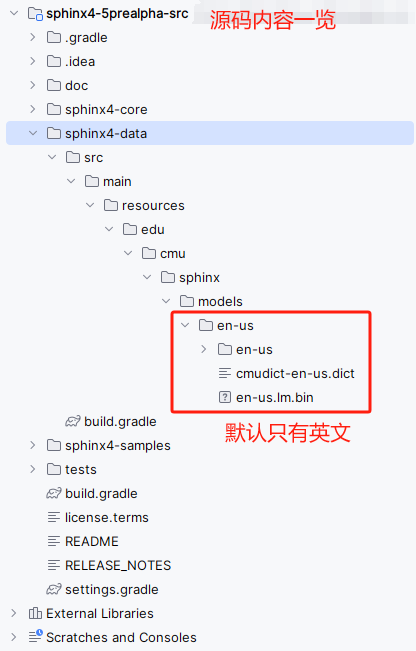
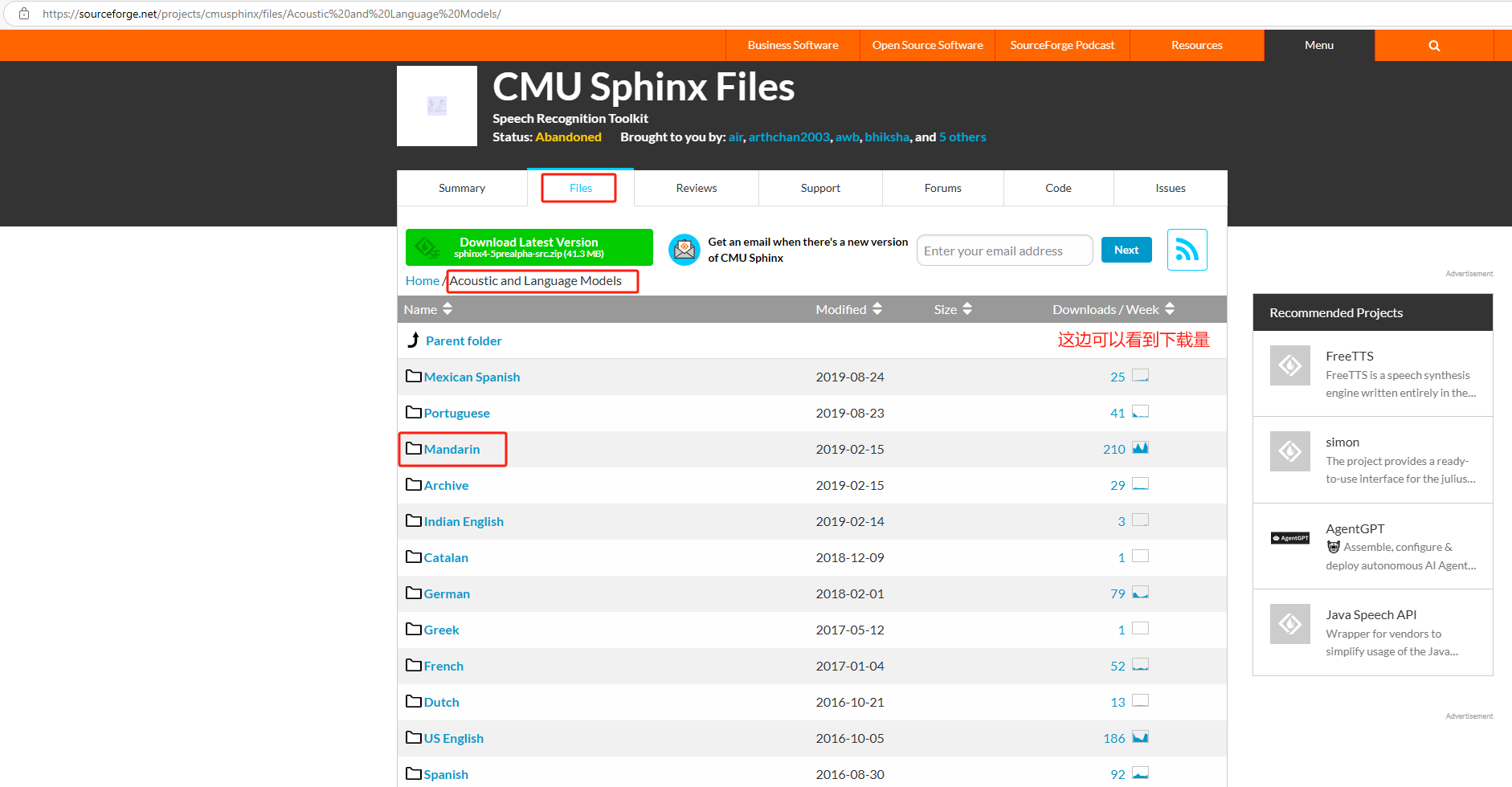
点击菜单Files ,其中Acoustic and Language Models 是语言资源包文件夹,下面还有sphinx不同版本的源码,源码中默认只包含英文资源包。
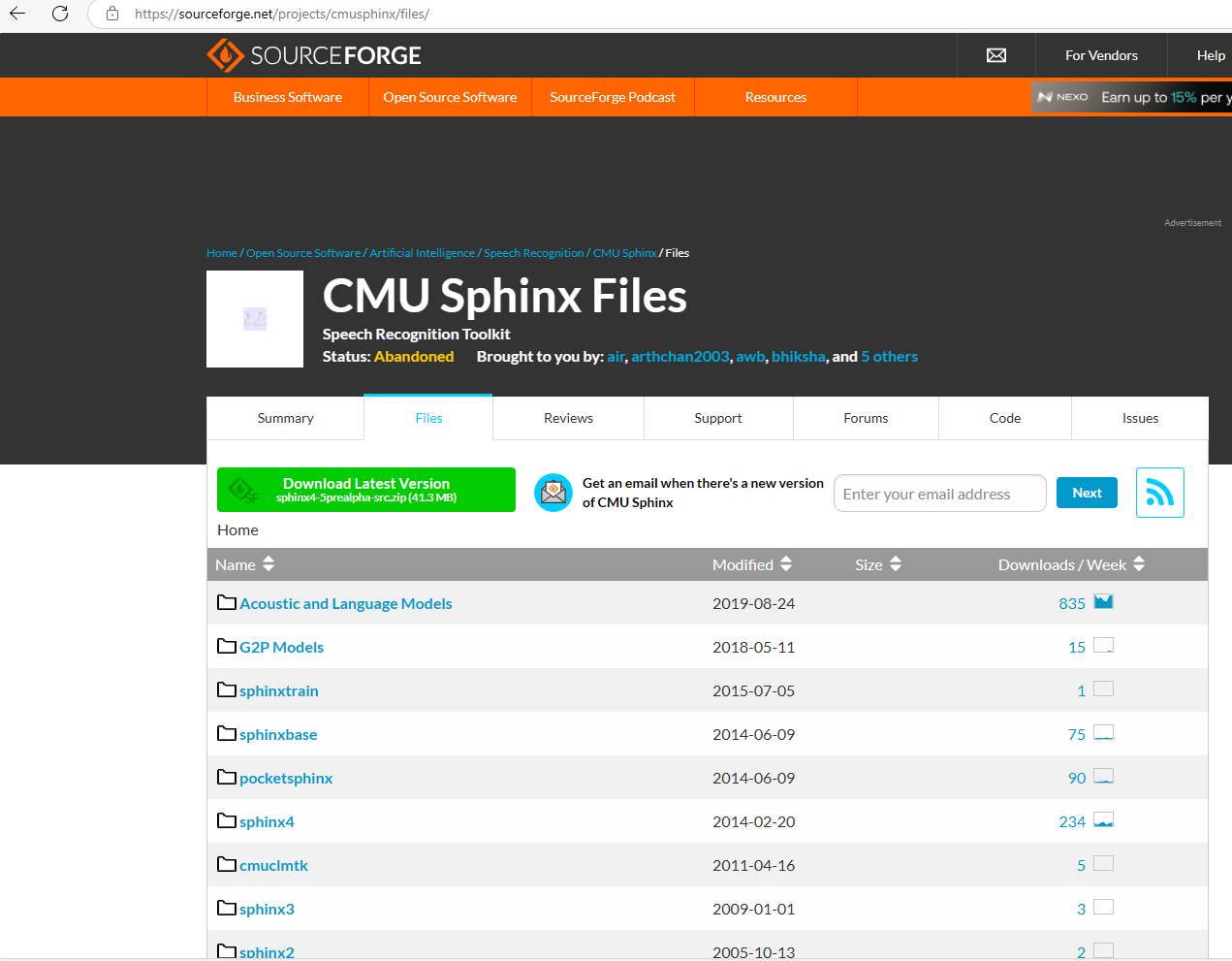
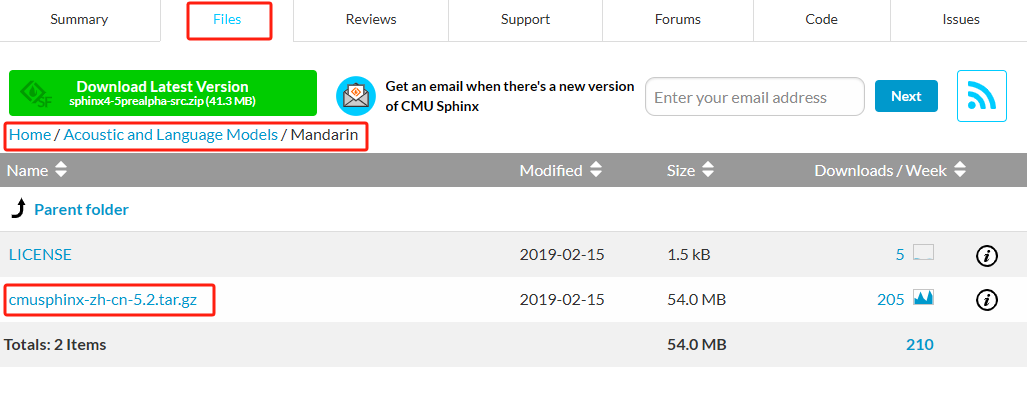
1、下载中文资源包(需要其他语言的选择对应的文件夹即可),中文选择Mandarin
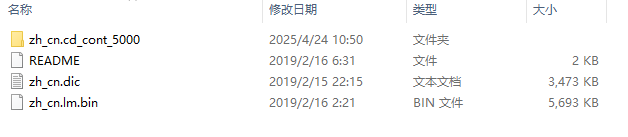
2、将下载后的文件放到项目中
解压后的文件
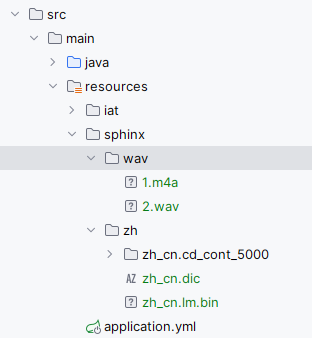
3、代码-识别wav语音文件
好像只能识别wav格式的文件,m4a试了不行,可以自行尝试看下结果
java
public static void speechToTxt2() throws Exception {
// 1、配置
Configuration conf = new Configuration();
conf.setAcousticModelPath("resource:/sphinx/zh/zh_cn.cd_cont_5000");
conf.setDictionaryPath("resource:/sphinx/zh/zh_cn.dic");
conf.setLanguageModelPath("resource:/sphinx/zh/zh_cn.lm.bin");
System.out.println("Loading models...");
// conf.setAcousticModelPath("resource:/edu/cmu/sphinx/models/en-us/en-us");
// conf.setDictionaryPath("resource:/edu/cmu/sphinx/models/en-us/cmudict-en-us.dict");
Context context = new Context(conf);
context.setLocalProperty("decoder->searchManager", "allphoneSearchManager");
Recognizer recognizer = context.getInstance(Recognizer.class);
InputStream stream = ParseUtil.class.getResourceAsStream("/sphinx/wav/2.wav");
stream.skip(44);
// Simple recognition with generic model
recognizer.allocate();
context.setSpeechSource(stream, TimeFrame.INFINITE);
Result result;
while ((result = recognizer.recognize()) != null) {
SpeechResult speechResult = new SpeechResult(result);
System.out.format("Hypothesis: %s\n", speechResult.getHypothesis());
System.out.println("List of recognized words and their times:");
for (WordResult r : speechResult.getWords()) {
System.out.println(r);
}
// System.out.println("Lattice contains "
// + speechResult.getLattice().getNodes().size() + " nodes");
}
recognizer.deallocate();
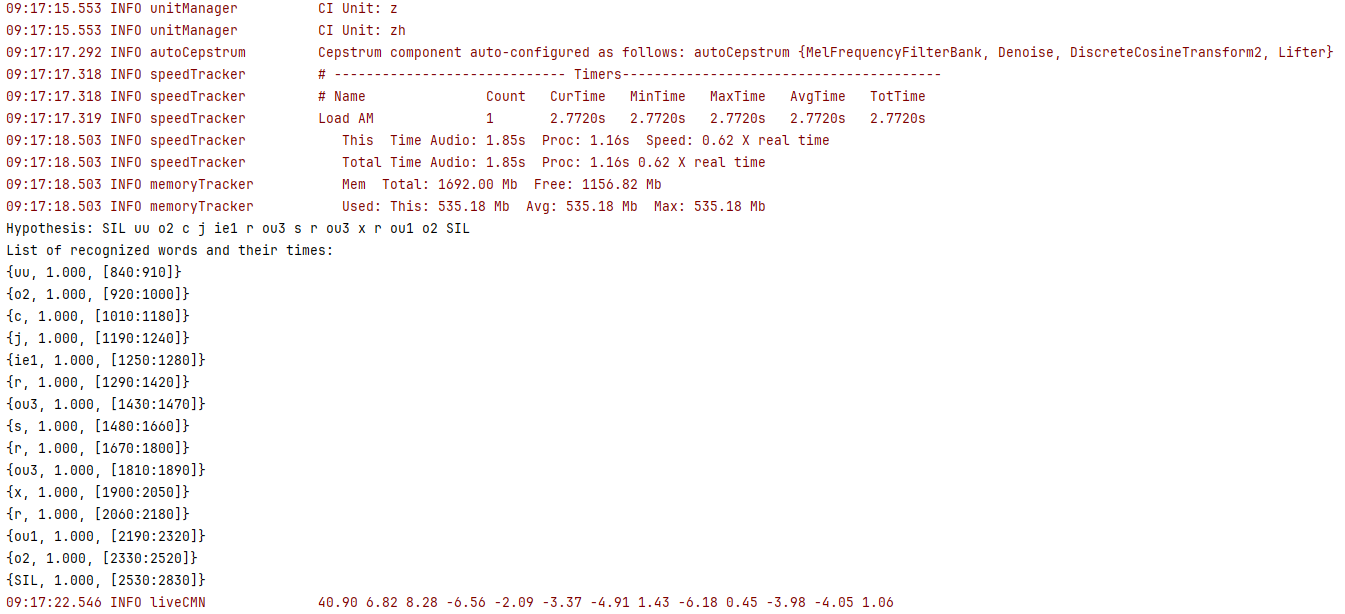
}输出结果如图
其中 Hypothesis: SIL uu o2 c j ie1 r ou3 s r ou3 x r ou1 o2 SIL 就是需要训练的内容。
我们下载的资源文件zh_cn.dic 中有已经简单训练的结果
4、代码-识别实时输入(本地pc未成功)
调用时,系统能检测到在使用麦克风。但在recognizer.getResult()这行总是会报溢出错误,也有可能是输入的设备不支持,各位可以自行尝试。有结果可以评论学习一下,感谢。
java
public static void speechToTxt() throws Exception {
// 1、配置
Configuration conf = new Configuration();
conf.setAcousticModelPath("resource:/sphinx/zh/zh_cn.cd_cont_5000");
conf.setDictionaryPath("resource:/sphinx/zh/zh_cn.dic");
conf.setLanguageModelPath("resource:/sphinx/zh/zh_cn.lm.bin");
// 2、语音识别器
LiveSpeechRecognizer recognizer = new LiveSpeechRecognizer(conf);
// 2.1 开始识别
recognizer.startRecognition(true);
// 2.2 识别结果
SpeechResult result;
while ((result = recognizer.getResult()) != null) {
System.out.println(result.getHypothesis());
}
// 2.3 停止识别
recognizer.stopRecognition();
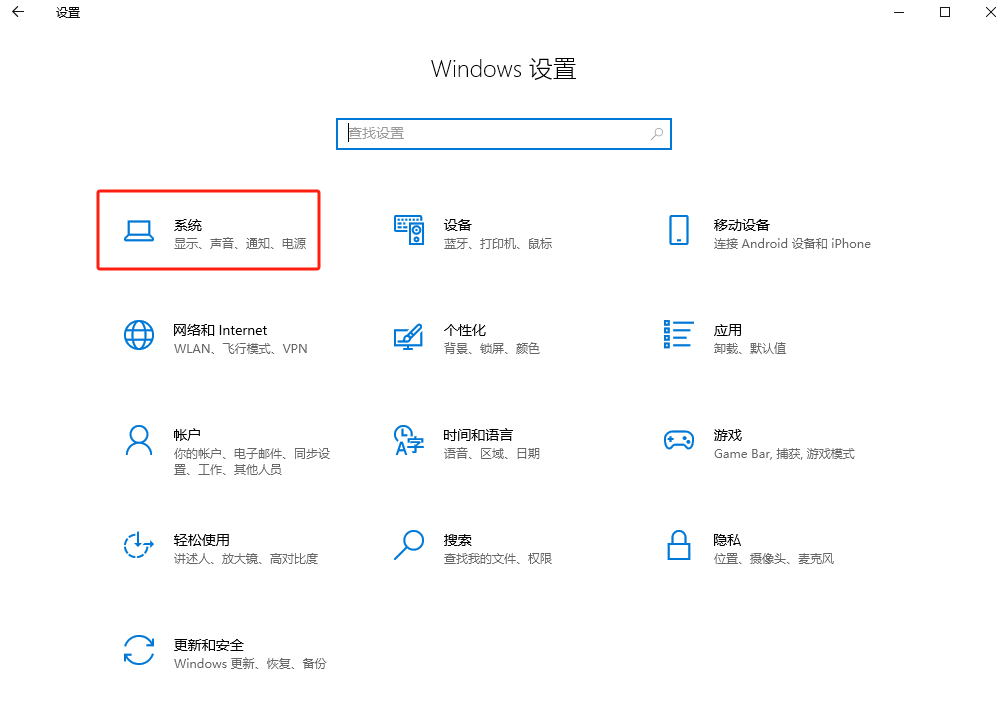
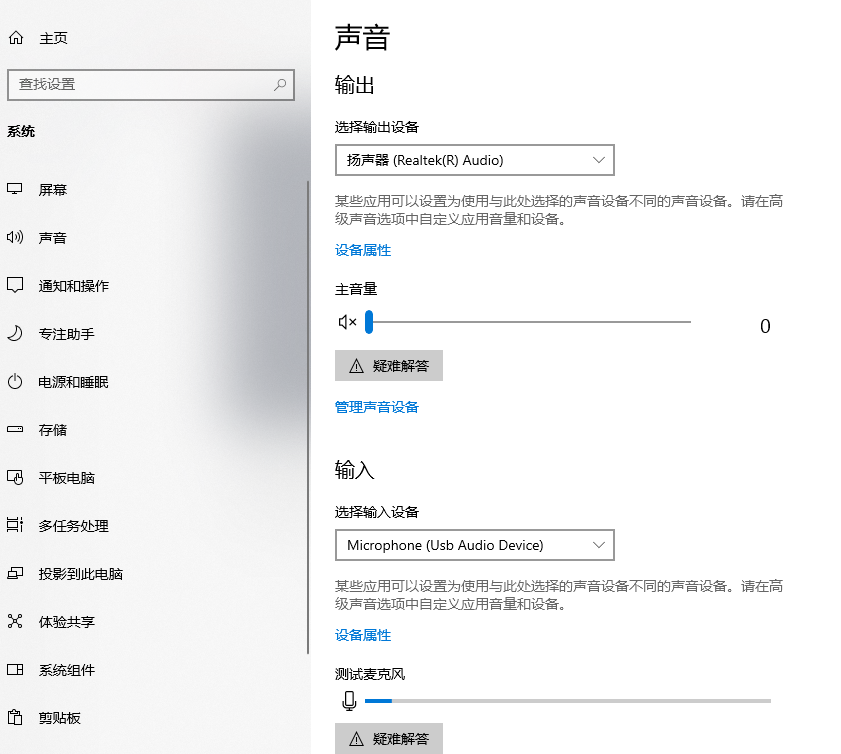
}4.1 测试端需要有语音输入设备
设置-系统-声音-输入 ,输入 配置中需要有输入设备,测试麦克风 可以查看此设备是否可用