前言
上一篇介绍了 因子的评价和分析方法,让我知道如何判断该因子的作用,以及对最终结果的影响,其最大的问题,他只能评价和分析单因子,而对多个因子,不能直接加以评价。我们自然会想到,如果是多因子,他是如何影响结果,每个因子起的作用是怎么样的,这些因子哪几个比较重要,他们的次序是怎么样的,如果给定这些因子的权重,能否合成一个新的因子,这个新的因子,加以评价分析。
以上这两个问题,就是本篇和以后文章需要解决的问题。首先就因子的重要性来分析,取决于用什么模型来架构,如果是线性模型,那自然是因子的权重系数,即为该因子的系数(或斜率);如果是非线性模型,如树型模型,就可以直接取重要性排序系统来确定,如果是神经网络模型,就很难获取,解释性自然很差了。
本篇从线性回归模型来分析因子,其中线性回归的模型很多,一般线性回归、岭回归,Lasso回归、Rubust回归,最常用的就是一般线性回归。基本的思路:现以上证50为标的,以财务总资产、总负债 、净利润、年度收入增长、研发费用等因素作为因子,以市值为作目标,建立模型线性,最后以预测值与真实值的差值,进行排序,找到市值被低估最多股票作为选股的标的,进行回测。
获取数据
为了与之前的文章统一,本文仍使用聚宽平台的数据,
python
#导入jqdata的全部函数
from jqdata import *
#这回咱们就把选择上证50成分股做股票池
stocks = get_index_stocks('000016.XSHG')
#用query函数获取股票的代码
q = query(valuation.code,
#还有市值
valuation.market_cap,
#净资产,用总资产减去总负债
balance.total_assets - balance.total_liability,
#再来一个资产负债率的倒数
balance.total_assets/balance.total_liability,
#把净利润也考虑进来
income.net_profit,
#还有年度收入增长
indicator.inc_revenue_year_on_year,
#研发费用
balance.development_expenditure
).filter(valuation.code.in_(stocks))
#将这些数据存入一个数据表中
df = get_fundamentals(q)
#给数据表指定每列的列名称
df.columns = ['code',
'mcap',
'na',
'1/DA ratio',
'net income',
'growth',
'RD']
#检查一下是否成功
df.head()| - | code | mcap | na | 1/DA ratio | net income | growth | RD |
|---|---|---|---|---|---|---|---|
| 0 | 600028.XSHG | 6888.7924 | 9.762930e+11 | 1.880751 | 6.749000e+09 | -4.61 | NaN |
| 1 | 600030.XSHG | 3734.7778 | 2.987667e+11 | 1.211600 | 5.138545e+09 | 23.74 | NaN |
| 2 | 600031.XSHG | 1617.8733 | 7.300160e+10 | 1.922396 | 1.113674e+09 | 12.33 | 242669000.0 |
| 3 | 600036.XSHG | 10612.5110 | 1.233475e+12 | 1.112970 | 3.552000e+10 | 7.53 | NaN |
| 4 | 600048.XSHG | 1048.6108 | 3.450036e+11 | 1.335300 | 1.544011e+09 | -21.62 | NaN |
建模
把市值作为目标值,其他财务因子作为特征,用 0 来填充缺失值。
python
#把股票代码做成数据表的index
df.index = df['code'].values
#然后把原来代码这一列丢弃掉,防止它参与计算
df = df.drop('code', axis = 1)
#把除去市值之外的数据作为特征,赋值给X
X = df.drop('mcap', axis = 1)
#市值这一列作为目标值,赋值给y
y = df['mcap']
#用0来填补数据中的空值
X = X.fillna(0)
y = y.fillna(0)训练并预测
python
#使用线性回归来拟合数据
reg = LinearRegression().fit(X,y)
#将模型预测值存入数据表
predict = pd.DataFrame(reg.predict(X),
#保持和y相同的index,也就是股票的代码
index = y.index,
#设置一个列名,这个根据你个人爱好就好
columns = ['predict_mcap'])
#检查是否成功
predict.head()| - | predict_mcap |
|---|---|
| 600028.XSHG | 4833.806993 |
| 600030.XSHG | 3125.629608 |
| 600031.XSHG | 2175.318676 |
| 600036.XSHG | 11034.704820 |
| 600048.XSHG | 2496.955008 |
查看模型参数
python
# (1) 各特征系数(对应 X.columns 的顺序)
print("特征系数:", reg.coef_)
# (2) 偏置项(截距)
print("偏置值:", reg.intercept_) # 特征系数: [1.6610656144885165e-09 359.032360682994 2.103156475641299e-07
-0.13441721290214032 5.958907500769328e-08]
偏置值: 1116.8298565517507
python
for feature, coef in zip(X.columns, reg.coef_):
print(f"{feature}: {coef:.4f}")na: 0.0000
1/DA ratio: 359.0324
net income: 0.0000
growth: -0.1344
RD: 0.0000
从上述数据来看,真正起作用的主要是
1/DA ratio和growth这两个因子
计算差值并排序
python
#使用真实的市值,减去模型预测的市值
diff = df['mcap'] - predict['predict_mcap']
#将两者的差存入一个数据表,index还是用股票的代码
diff = pd.DataFrame(diff, index = y.index, columns = ['diff'])
#将该数据表中的值,按生序进行排列
diff = diff.sort_values(by = 'diff', ascending = True)
#找到市值被低估最多的10只股票
diff.head(10)| - | diff |
|---|---|
| 600276.XSHG | -3535.849409 |
| 601988.XSHG | -3470.535336 |
| 601328.XSHG | -3014.714514 |
| 601668.XSHG | -2815.339172 |
| 601390.XSHG | -2792.367126 |
| 601398.XSHG | -2723.120877 |
| 601919.XSHG | -2678.387472 |
| 600050.XSHG | -2321.983808 |
| 601225.XSHG | -2308.808637 |
| 601888.XSHG | -1822.134836 |
结果分析
从上表可以看出,模型将计算出实际市值与预测市值,将这些差值最多的股票选出,进行买入持有,等这个差值变小了再卖出,基于这个思想,制定股票交易策略。
注:以上结果是基于现在(今天2025-04-26),也许你的结果与我不一样,因为get_fundamentals()函数默认获取的是当前日期的内容。你可以修改函数,将日期给写上,df = get_fundamentals(q, '2025-04-26') ,得以重现。
回测代码
这里给出的回测代码,主要是交易部分
以下是完整的回测代码,你可以复制后,放在策略中回测
python
# 导入函数库
from sklearn.linear_model import LinearRegression, Ridge
import numpy as np
import pandas as pd
from jqdata import *
# 初始化函数,设定基准等等
def initialize(context):
# 设定沪深300作为基准
set_benchmark('000001.XSHG')
# 开启动态复权模式(真实价格)
set_option('use_real_price', True)
# 输出内容到日志 log.info()
log.info('初始函数开始运行且全局只运行一次')
# 过滤掉order系列API产生的比error级别低的log
log.set_level('order', 'error')
### 股票相关设定 ###
# 股票类每笔交易时的手续费是:买入时佣金万分之三,卖出时佣金万分之三加千分之一印花税, 每笔交易佣金最低扣5块钱
# set_order_cost(OrderCost(close_tax=0.001, open_commission=0.0003, close_commission=0.0003, min_commission=5), type='stock')
#定义初始日期为0
g.days =0
#每5天调仓一次
g.refresh_rate = 5
#最大持股的个数为10个
g.stocknum = 10
## 运行函数(reference_security为运行时间的参考标的;传入的标的只做种类区分,因此传入'000300.XSHG'或'510300.XSHG'是一样的)
# 开盘前运行
run_daily(before_market_open, time='before_open', reference_security='000300.XSHG')
# 开盘时运行
run_daily(market_open, time='open', reference_security='000300.XSHG')
# 收盘后运行
run_daily(after_market_close, time='after_close', reference_security='000300.XSHG')
## 开盘前运行函数
def before_market_open(context):
# 输出运行时间
log.info('函数运行时间(before_market_open):'+str(context.current_dt.time()))
# 给微信发送消息(添加模拟交易,并绑定微信生效)
# send_message('美好的一天~')
# 要操作的股票:平安银行(g.为全局变量)
# g.security = '000001.XSHE'
## 开盘时运行函数
def market_open(context):
log.info('函数运行时间(market_open):'+str(context.current_dt.time()))
#如果天数能够被5整除,
#就运行我们在研究环境中写好的代码
if g.days % 5 == 0:
#下面的代码是从研究环境中移植过来的
#去掉了画图和查看表头的部分
#此处就不逐行注释了
stocks = get_index_stocks('000016.XSHG', date = None)
q = query(valuation.code,
#还有市值
valuation.market_cap,
#净资产,用总资产减去总负债
balance.total_assets - balance.total_liability,
#再来一个资产负债率的倒数
balance.total_assets/balance.total_liability,
#把净利润也考虑进来
income.net_profit,
#还有年度收入增长
indicator.inc_revenue_year_on_year,
balance.development_expenditure
).filter(valuation.code.in_(stocks))
df = get_fundamentals(q, date=None)
df.columns = ['code', 'mcap', 'na', '1/DA ratio','net income', 'growth','RD']
df.index = df.code.values
df = df.drop('code',axis = 1)
df = df.fillna(0)
X = df.drop('mcap', axis = 1)
y = df['mcap']
X = X.fillna(0)
y = y.fillna(0)
#下面是机器学习的部分
reg = LinearRegression ()
model = reg.fit(X,y)
predict =pd.DataFrame(reg.predict(X),
index = y.index,
columns = ['predict_mcap'])
diff = df['mcap'] - predict['predict_mcap']
diff =pd.DataFrame(diff,index =y.index, columns = ['diff'])
diff = diff.sort_values(by = 'diff', ascending = True)
#下面是执行订单的部分
#首先将把市值被低估最多的10只股票存入持仓列表
stockset = list(diff.index[:10])
#同时已经持有的股票,存入卖出的列表中
sell_list = list(context.portfolio.positions.keys())
#如果某只股票在卖出列表中
for stock in sell_list:
#同时又不在持仓列表中
if stock not in stockset[:g.stocknum]:
#就把这只股票卖出
stock_sell = stock
#卖出后该股票的持仓量为0,也就是直接清仓
order_target_value(stock_sell, 0)
#如果持仓的数量小于我们设置的最大持仓数
if len(context.portfolio.positions) < g.stocknum:
#我们就把剩余的现金,平均买入股票#例如持仓8只股票,剩余3万块现金
#就买入2只列表中的股票,每只买入的金额上限为1.5万元
num = g.stocknum - len(context.portfolio.positions)
cash = context.portfolio.cash/num
else:
cash =0
num =0
for stock in stockset[:g.stocknum]:
if stock in sell_list:
pass
else:
stock_buy = stock
order_target_value(stock_buy, cash)
num = num - 1
if num == 0:
break
#同时天数加1
g.days += 1
#如果天数不能被5整除
else:
#不执行交易,直接天数加1
g.days = g.days +1
## 收盘后运行函数
def after_market_close(context):
log.info(str('函数运行时间(after_market_close):'+str(context.current_dt.time())))
#得到当天所有成交记录
trades = get_trades()
for _trade in trades.values():
log.info('成交记录:'+str(_trade))
log.info('一天结束')
log.info('##############################################################')以上回测代码,没有删除原先模板的内容,主要内容可以查看market_open函数部分,特别是机器学习(线性回归)部分。
回测结果
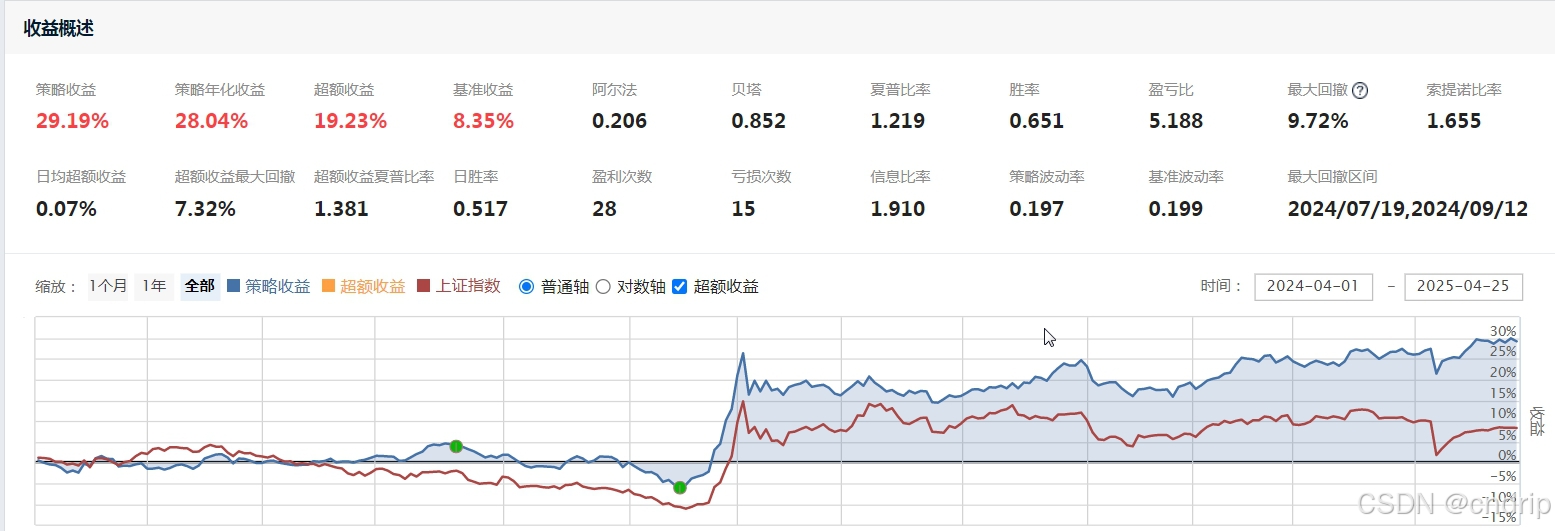
结论
- 从上图来看,回测区间从2024-01-01~至今,策略的各项指标还不对,基准选的是上证指数,标的是上证50的50支股票选出10支。
- 上述只选5个因子,但真正起作用的是只有两个因子, 你可以将其他不起作用的因子剔除,增加其他因子,以提高模型的有效性。
- 上述分析,没有将模型进行验证,在实际的过程中,是需要将数据集分为训练集和验证集,并加以验证,考虑到是线性模型,另外,反过来说,本文是预测结果与真实值的差,越大越好,这就带了两个问题,
3.1 模型预测值与真实值越大越好,则说明模型越差越好,那训练还有意义吗;
3.2 既然差值最大越好,则说该股票的市值越大越好,因此,这个模型必须是大市值,小市值根本上了排行榜;所以我在测试非50标的,效果是非常差的。 - 上述只是一个简单的思路,在实际的实践中,这个目标标签y不可能这样去实现,可能将目标的绝对值转化为相对值(比值),比如差值除以总市值成为比值,但同时在训练前,又没有差值,那样就不好弄,总之这个方法可以进一步探讨。