目录
-
- 引言
- [一、对抗学习的核心:生成器 vs 判别器](#一、对抗学习的核心:生成器 vs 判别器)
- 二、数学上的对抗实现
-
- [2.1 生成器(G)](#2.1 生成器(G))
- [2.2 判别器(D)](#2.2 判别器(D))
- 三、网络结构与代码实现
-
- [3.1 生成器网络(以生成图像为例)](#3.1 生成器网络(以生成图像为例))
- [3.2 判别器网络](#3.2 判别器网络)
- [3.3 数据处理与训练](#3.3 数据处理与训练)
- 四、训练与推理过程
-
- [4.1 原理](#4.1 原理)
- [4.2 训练过程](#4.2 训练过程)
- [4.3 推理过程](#4.3 推理过程)
- [4.4 噪声如何影响生成](#4.4 噪声如何影响生成)
-
- [4.4.1 随机噪声与生成过程的关系](#4.4.1 随机噪声与生成过程的关系)
- [4.4.2 对风格相关特征的影响](#4.4.2 对风格相关特征的影响)
- [4.4.3 改进模型对风格的显式控制](#4.4.3 改进模型对风格的显式控制)
- 五、典型应用
- 六、优势与挑战
-
- [6.1 优势](#6.1 优势)
- [6.2 挑战](#6.2 挑战)
- 总结
引言
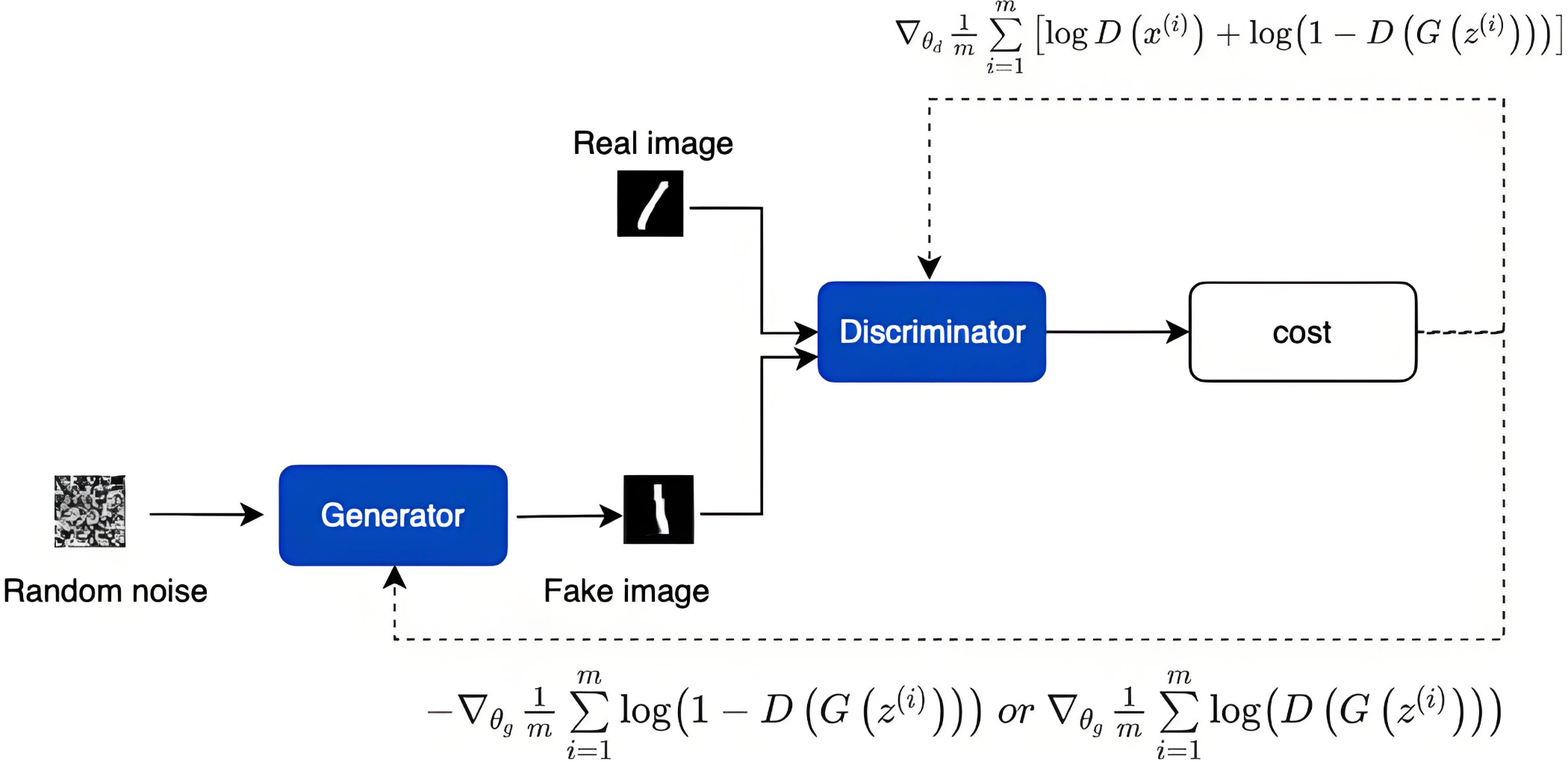
在机器学习的广阔领域中,对抗学习以其独特的"博弈"思想脱颖而出。生成对抗网络(GAN)作为其经典代表,宛如一场"猫鼠游戏"------生成器努力"造假",判别器全力"打假",二者在对抗中共同进化。
一、对抗学习的核心:生成器 vs 判别器
想象一个生活化场景:生成器(G)是"造假者",目标是伪造一幅以假乱真的名画;判别器(D)是"鉴宝专家",任务是区分真画与假画。
- 第一轮:生成器随便画一幅(质量差),判别器一眼识假,给低分。
- 第二轮:生成器调整技巧(优化参数),画得更逼真;判别器也更严格(优化参数),能识别细微破绽。
- 反复对抗:生成器不断提升造假水平,判别器增强鉴别能力,直至生成器的假画让判别器无法分辨(达到平衡)。
此过程中,生成器学会"以假乱真",判别器学会"火眼金睛",这便是对抗学习的核心逻辑。
二、数学上的对抗实现
用机器学习语言描述,生成器与判别器的优化目标如下:
2.1 生成器(G)
输入随机噪声(如随机向量 z z z),输出接近真实数据的样本 G ( z ) G(z) G(z),目标是最大化判别器误判概率:
max G E z ∼ p ( z ) log D ( G ( z ) ) \max_G \, \mathbb{E}_{z \sim p(z)} \\log D(G(z)) GmaxEz∼p(z)logD(G(z))
- max G \max_G maxG:对生成器 G G G 进行最大化操作。
- E z ∼ p ( z ) \mathbb{E}_{z \sim p(z)} Ez∼p(z):对服从分布 p ( z ) p(z) p(z) 的随机噪声 z z z 求数学期望。
- log D ( G ( z ) ) \log D(G(z)) logD(G(z)):判别器 D D D 对 G ( z ) G(z) G(z) 判断为真的概率取对数,生成器希望此值越大(即判别器误判)。
2.2 判别器(D)
输入真实数据 x x x 或生成器输出 G ( z ) G(z) G(z),输出概率值判断真假,目标是正确区分两者:
min D E x ∼ p d a t a ( x ) log D ( x ) + E z ∼ p ( z ) log ( 1 − D ( G ( z ) ) ) \min_D \, \mathbb{E}{x \sim p{data}(x)} \\log D(x) + \mathbb{E}_{z \sim p(z)} \\log (1 - D(G(z))) DminEx∼pdata(x)logD(x)+Ez∼p(z)log(1−D(G(z)))
- min D \min_D minD:对判别器 D D D 进行最小化操作。
- E x ∼ p d a t a ( x ) log D ( x ) \mathbb{E}{x \sim p{data}(x)} \\log D(x) Ex∼pdata(x)logD(x):真实数据 x x x 被判为真的概率对数期望,判别器希望此值越大。
- E z ∼ p ( z ) log ( 1 − D ( G ( z ) ) ) \mathbb{E}_{z \sim p(z)} \\log (1 - D(G(z))) Ez∼p(z)log(1−D(G(z))):生成数据 G ( z ) G(z) G(z) 被判为假的概率对数期望,判别器希望此值越大。
两者的优化是极小极大博弈(Minimax Game),平衡时生成器输出分布与真实数据分布一致,判别器无法区分(概率50%)。
三、网络结构与代码实现
3.1 生成器网络(以生成图像为例)
采用转置卷积(反卷积)构建上采样网络,代码如下:
python
import torch
import torch.nn as nn
class Generator(nn.Module):
def __init__(self, latent_dim, img_shape):
super(Generator, self).__init__()
self.img_shape = img_shape
self.model = nn.Sequential(
nn.Linear(latent_dim, 128),
nn.ReLU(True),
nn.Linear(128, 256),
nn.BatchNorm1d(256),
nn.ReLU(True),
nn.Linear(256, 512),
nn.BatchNorm1d(512),
nn.ReLU(True),
nn.Linear(512, int(torch.prod(torch.tensor(img_shape)))),
nn.Tanh()
)
def forward(self, z):
img = self.model(z)
img = img.view(img.size(0), *self.img_shape)
return img3.2 判别器网络
基于卷积神经网络(CNN)构建下采样结构:
python
class Discriminator(nn.Module):
def __init__(self, img_shape):
super(Discriminator, self).__init__()
self.img_shape = img_shape
self.model = nn.Sequential(
nn.Linear(int(torch.prod(torch.tensor(img_shape))), 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 1),
nn.Sigmoid()
)
def forward(self, img):
img_flat = img.view(img.size(0), -1)
validity = self.model(img_flat)
return validity3.3 数据处理与训练
-
数据处理 :
以MNIST数据集为例,加载并归一化:pythonfrom torchvision import datasets, transforms transform = transforms.Compose([ transforms.ToTensor(), transforms.Normalize([0.5], [0.5]) # 归一化到 [-1, 1] ]) dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform) dataloader = torch.utils.data.DataLoader(dataset, batch_size=64, shuffle=True) -
训练循环 :
python# 超参数设置 latent_dim = 100 lr = 0.0002 beta1 = 0.5 # 初始化模型 img_shape = (1, 28, 28) generator = Generator(latent_dim, img_shape) discriminator = Discriminator(img_shape) # 损失函数与优化器 criterion = nn.BCELoss() optimizer_g = torch.optim.Adam(generator.parameters(), lr=lr, betas=(beta1, 0.999)) optimizer_d = torch.optim.Adam(discriminator.parameters(), lr=lr, betas=(beta1, 0.999)) # 训练循环 for epoch in range(epochs): for i, (real_img, _) in enumerate(dataloader): # 训练判别器:真实图像 optimizer_d.zero_grad() real_label = torch.ones(real_img.size(0), 1) real_validity = discriminator(real_img) d_loss_real = criterion(real_validity, real_label) # 训练判别器:生成图像 z = torch.randn(real_img.size(0), latent_dim) fake_img = generator(z) fake_label = torch.zeros(fake_img.size(0), 1) fake_validity = discriminator(fake_img.detach()) d_loss_fake = criterion(fake_validity, fake_label) # 判别器总损失与优化 d_loss = d_loss_real + d_loss_fake d_loss.backward() optimizer_d.step() # 训练生成器 optimizer_g.zero_grad() fake_validity = discriminator(fake_img) g_loss = criterion(fake_validity, real_label) g_loss.backward() optimizer_g.step()
四、训练与推理过程
对抗神经网络(以最经典的生成对抗网络 GAN 为例)生成相似图像的原理、训练与推理过程如下:
4.1 原理
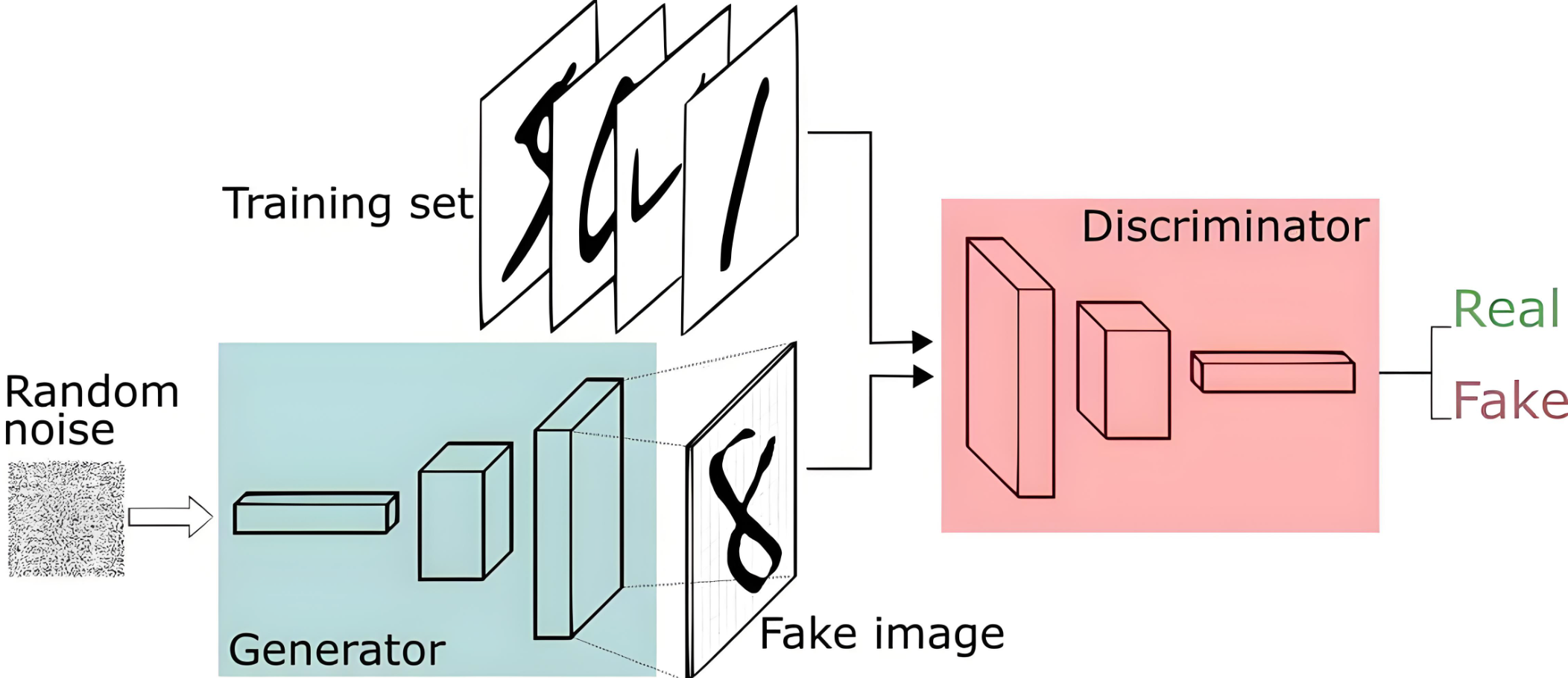
GAN 由生成器(G)和判别器(D)组成,二者通过"对抗"共同进步:
- 生成器(G):接收随机噪声(如一组随机数构成的向量),通过内部神经网络的计算(如多层转置卷积、全连接层),将噪声"变换"成图像。它的目标是让生成的图像尽可能逼真,以欺骗判别器。
- 判别器(D):接收真实图像或生成器输出的图像,输出一个概率值(0 到 1)判断图像是否为真实数据。它的目标是准确区分真实图像与生成图像。
- 对抗过程:生成器努力提升生成图像的质量(让判别器误判),判别器努力提升鉴别能力(不被生成器欺骗),在这种博弈中,生成器逐渐学会生成与训练数据相似的图像。
4.2 训练过程
- 准备数据 :
- 收集与目标相似的图像数据集(如想生成猫的图像,就准备大量猫的图片),并进行归一化处理(如将像素值从 0, 255 缩放到 -1, 1)。
- 初始化网络 :
- 随机初始化生成器 G 和判别器 D 的网络参数(如神经网络层的权重和偏置)。
- 循环训练 :
- 训练判别器(D) :
- 输入一批真实图像,标记为"真"(标签设为 1),输入判别器得到输出,计算判别器对真实图像判断为"真"的损失(如使用二元交叉熵损失)。
- 输入一批生成器 G 生成的图像(由随机噪声生成),标记为"假"(标签设为 0),输入判别器得到输出,计算判别器对生成图像判断为"假"的损失。
- 将两种损失相加,通过反向传播更新判别器 D 的参数,使其更擅长区分真假图像。
- 训练生成器(G) :
- 输入一批随机噪声,通过生成器 G 生成图像。
- 将生成的图像输入判别器 D,希望判别器误判为"真"(此时标签设为 1),计算损失(仅针对生成器生成的图像),通过反向传播更新生成器 G 的参数,使其生成的图像更接近真实图像,从而欺骗判别器。
- 重复上述过程,直到生成器 G 能稳定生成逼真图像,判别器 D 无法准确区分(即达到一种动态平衡)。
- 训练判别器(D) :
4.3 推理过程
- 训练完成后,生成器 G 已学会数据的分布特征。此时,仅使用生成器 G 进行推理 :
- 输入任意随机噪声(无需经过判别器 D),生成器 G 通过内部已训练好的网络计算,直接输出与训练数据相似的图像。例如,若训练数据是猫的图像,输入随机噪声后,生成器可能输出一张新的、逼真的猫的图像。
简单总结:训练时,生成器和判别器"斗智斗勇",生成器不断优化生成效果,判别器不断优化鉴别能力;推理时,生成器"独当一面",凭借训练学到的"技艺",将随机噪声转化为相似图像。
4.4 噪声如何影响生成
4.4.1 随机噪声与生成过程的关系
生成器将随机噪声作为输入"种子",通过内部神经网络的层层运算(如矩阵乘法、激活函数处理等)逐步转化为图像。不同的随机噪声初始值,会在生成器内部引发不同的计算路径和特征组合。以生成一张猫的图片为例:
- 若噪声的某个维度数值较大,可能在生成过程中强化图像的颜色饱和度,使生成的猫毛色更鲜艳;
- 另一个维度的数值差异,可能影响毛发的纹理细节,让猫的毛发看起来更蓬松或顺滑。
4.4.2 对风格相关特征的影响
从图像风格角度看,随机噪声的变化可能导致:
- 颜色与色调:不同噪声可能让生成器输出的猫呈现出黑猫、橘猫、灰白猫等不同颜色组合。
- 纹理与细节:有的噪声会生成短毛猫,有的则可能生成带有虎斑纹或斑点纹理的猫。
- 姿态与表情:在更复杂的模型(如结合条件输入的GAN)中,噪声的某些部分可能影响猫的姿态(如坐着、跳跃)或表情(如睁眼、闭眼)。
4.4.3 改进模型对风格的显式控制
在一些改进的生成对抗网络(如StyleGAN)中,随机噪声与风格的联系更加明确。模型会将噪声输入到不同层级的网络中,显式控制图像的"风格"属性。例如:
- 低层级的噪声输入主要影响图像的细节(如毛发的细微结构);
- 高层级的噪声输入则影响整体风格(如猫的面部轮廓、身体比例)。
因此,随机噪声作为生成器的输入变量,其取值差异会通过生成器的运算,最终反映在输出图像的风格、细节等方面,从而有可能生成不同风格的猫。
五、典型应用
- 图像生成:GAN生成人脸、风景,用于艺术创作、电影特效。
- 数据增强:生成更多样本,提升模型泛化能力。
- 风格迁移:将梵高画风迁移到普通图像。
- 安全领域:生成对抗样本测试模型鲁棒性,或用于恶意软件检测。
- 医疗:生成医学影像样本辅助疾病诊断,或设计新分子加速药物研发。
六、优势与挑战
6.1 优势
- 强大生成能力:生成逼真数据,甚至创造不存在的样本(如虚拟动物)。
- 灵活框架:适用于图像、文本、语音等多领域(如TextGAN、语音合成)。
- 无需显式建模:隐式学习数据分布,优于传统生成模型(如VAE)。
6.2 挑战
- 训练不稳定:生成器与判别器需平衡训练,否则易出现"一方碾压"。
- 模式崩溃:生成器可能只生成少数样本,而非覆盖全部数据分布(如生成人脸时重复相似脸型)。
- 评估困难:无明确指标(如准确率),需借助FID、IS等复杂指标评估生成质量。
总结
对抗学习如"猫鼠游戏",生成器与判别器在博弈中共同进化,实现单一模型难以达成的效果(如生成逼真数据)。