Linux:基础IO && 文件系统
一、系统IO
(一)系统文件操作接口
我们在C++中用到的各种函数底层都是封装了系统调用接口,通过系统指令实现了用户层到操作系统的交互。
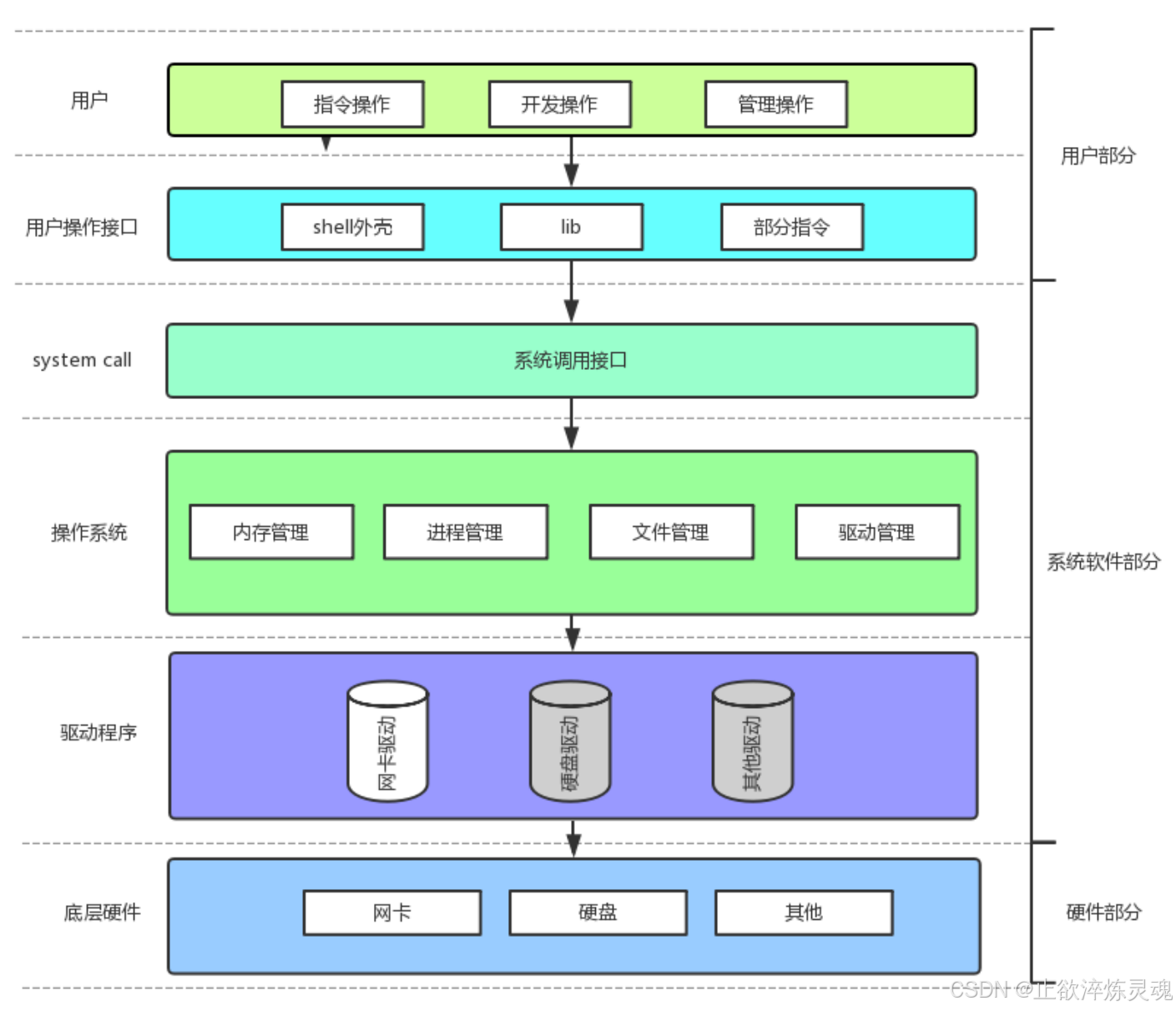
打开文件,对文件进行操作,本质是进程对文件进行操作。
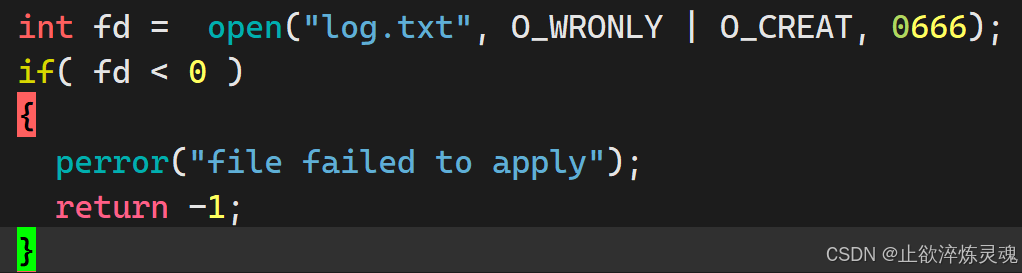
1、open
其中选项有很多最通常使用的有O_RDONLY, O_WRONLY, or O_RDWR,同时控制追加和清空的一组O_TRUNC, O_APPEND.
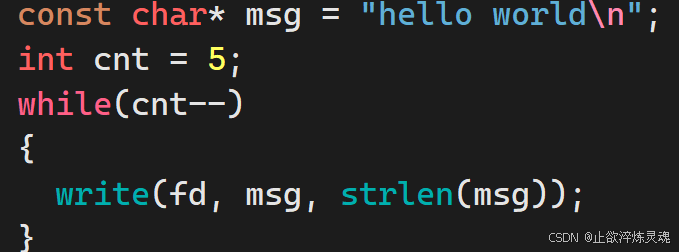
2、write
此处不用写入末尾的\n,不然导致乱码,此外,这里的msg是按照字节写入,因此上层不管是文本写入或者二进制写入都是调用write.
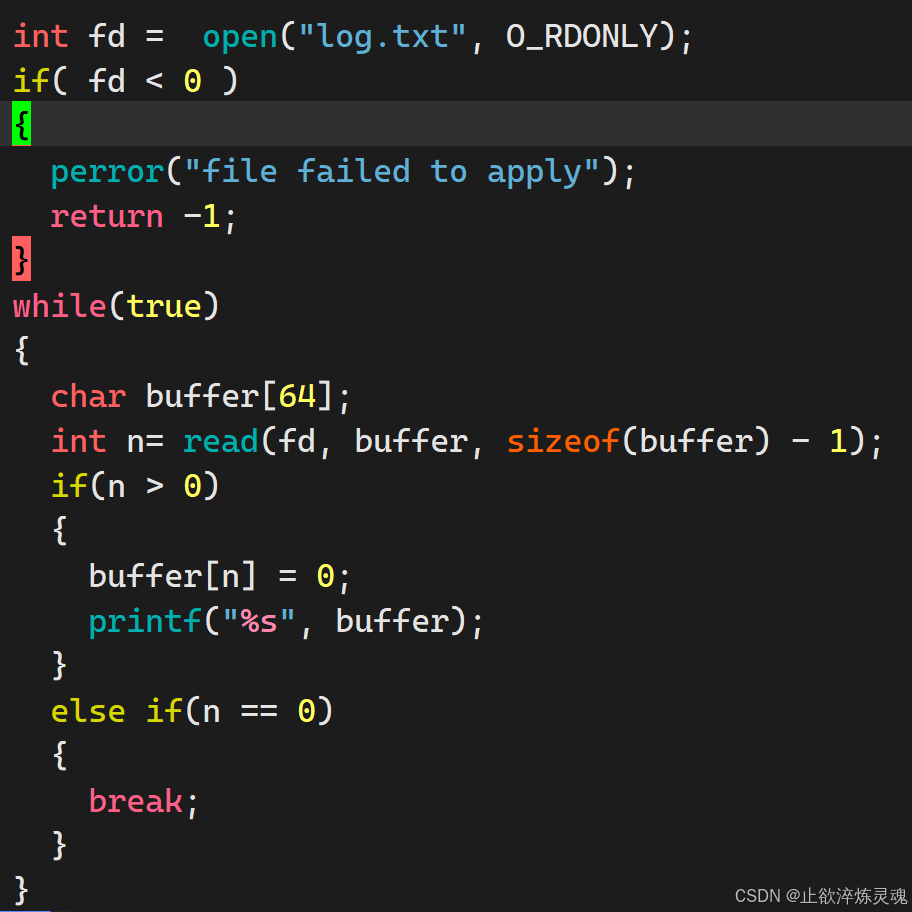
3、read
读取函数的返回值:如果成功且没有完成sizeof个字节,返回读取到的数量,读取完成返回0;
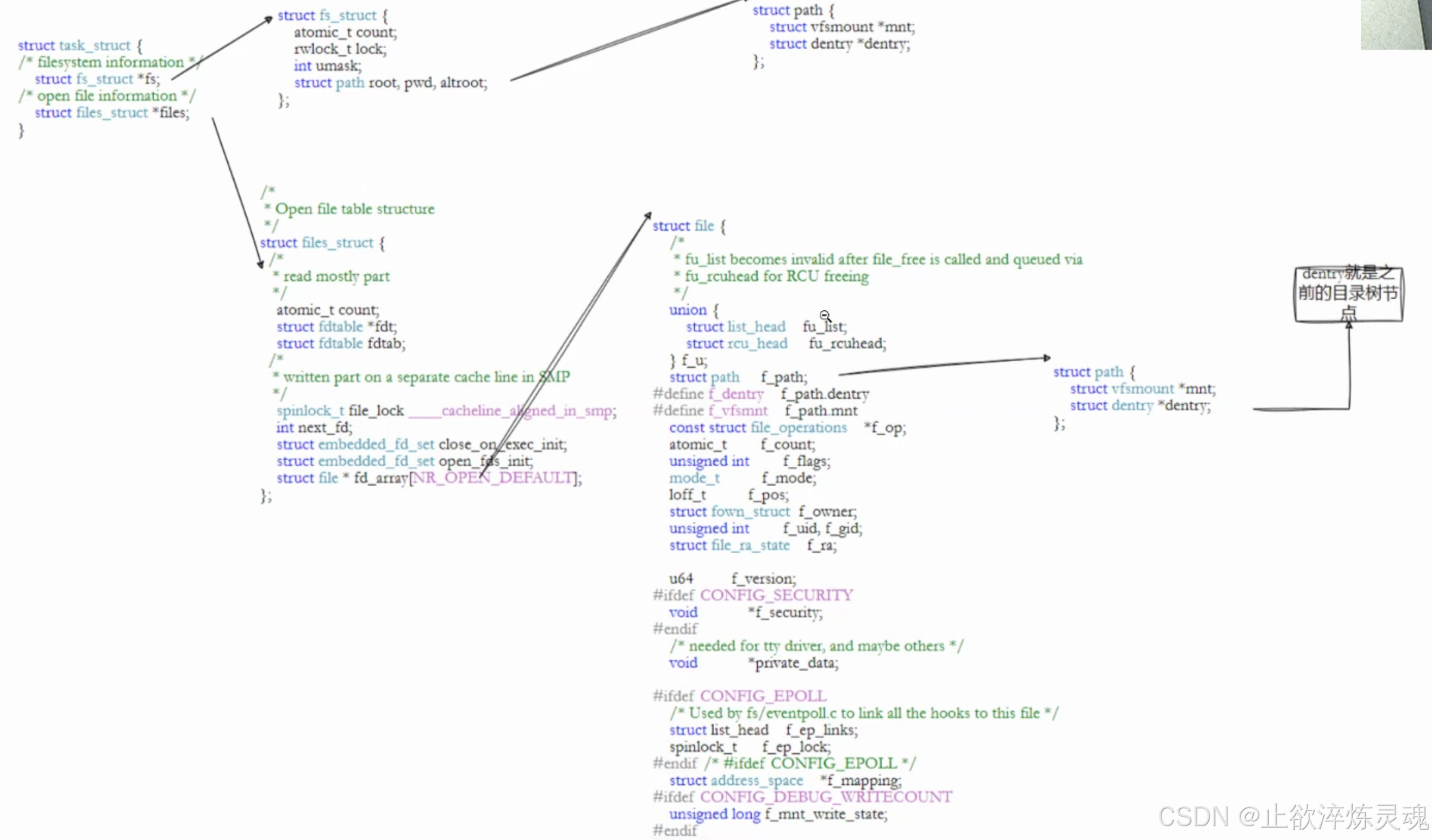
(二)文件描述符
1、概念
通过前面的学习,我们知道所谓的文件描述符就是一个正数,实际上他是进程结构体中files指针指向的files_struct(文件描述符表)这个指针数组的下标。通过指针,我们就能访问到内核中该文件。
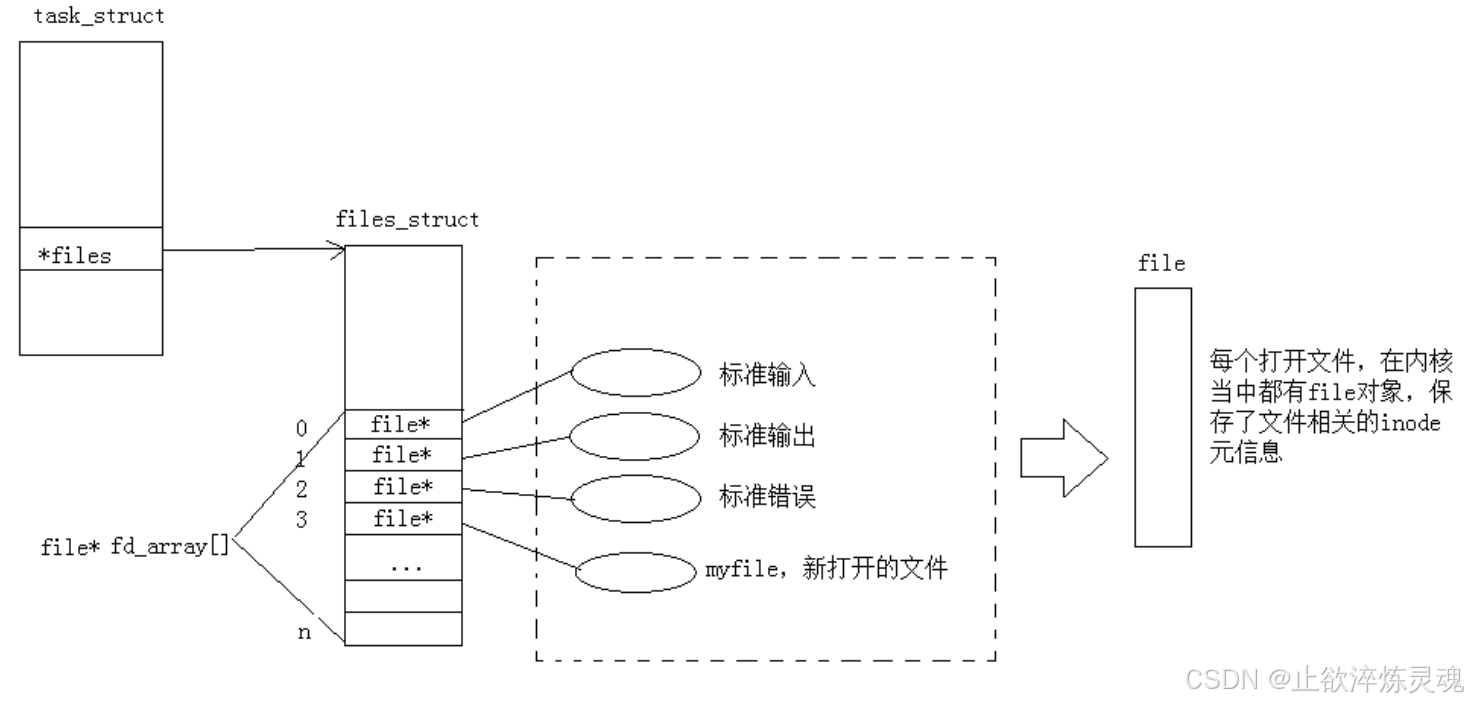
实现文件描述符是为了不同平台的可移植性,不同平台的系统调用方式可能有所差距,我们使用条件编译给予不同平台上层不同的 C++/JAVA...代码可以提高语言的跨平台性。
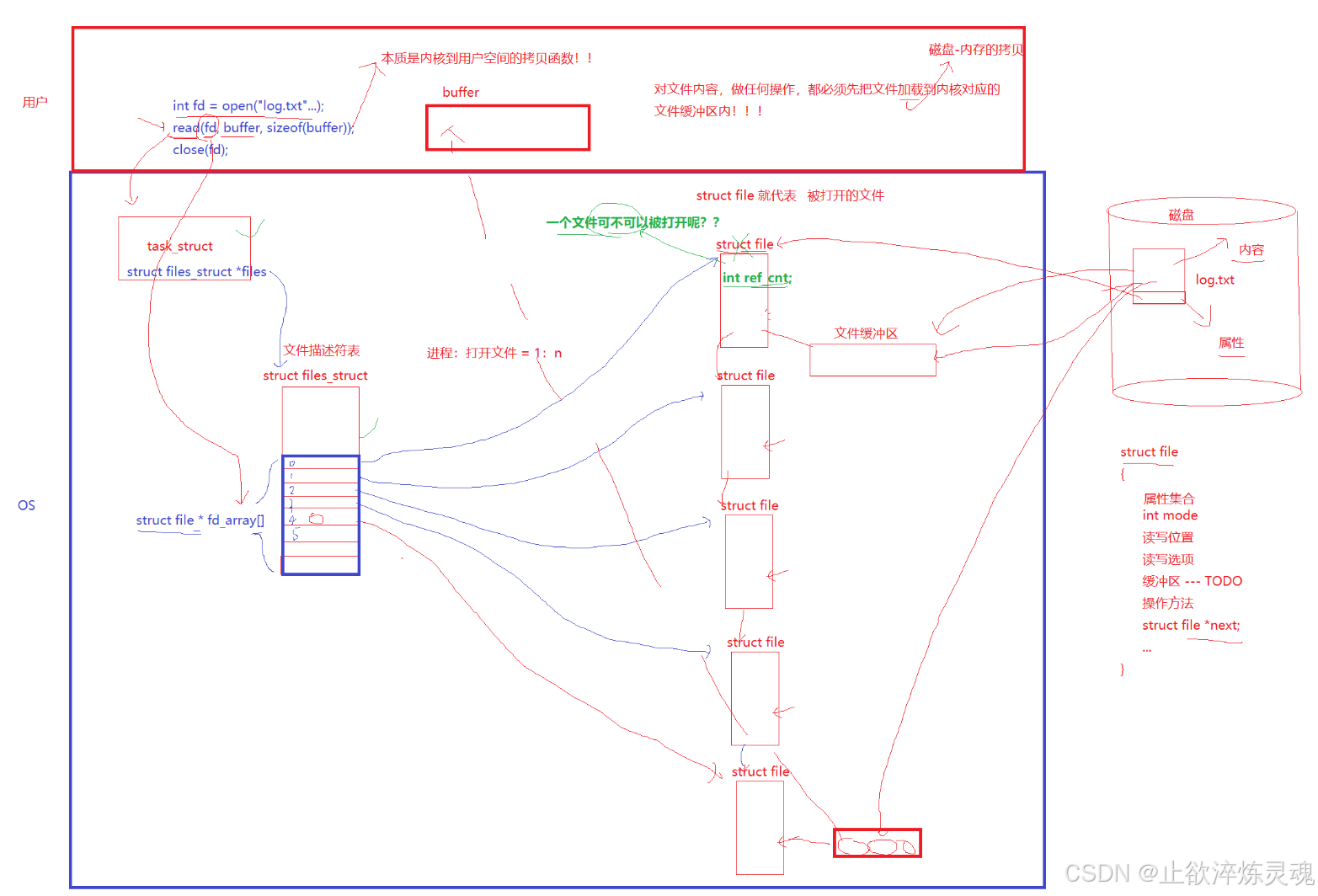
注:此图非原创
2、标准输入、标准输出、标准错误
stdin,stdout.stderr这FILE*的指针内部封装了文件描述符0. 1. 2。

(三)dup系统调用(重定向原理)
我们将自己写的文件将它替换文件描述符表的指针指向,进而实现重定向。其中dup函数正是实现的关键。
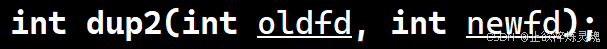
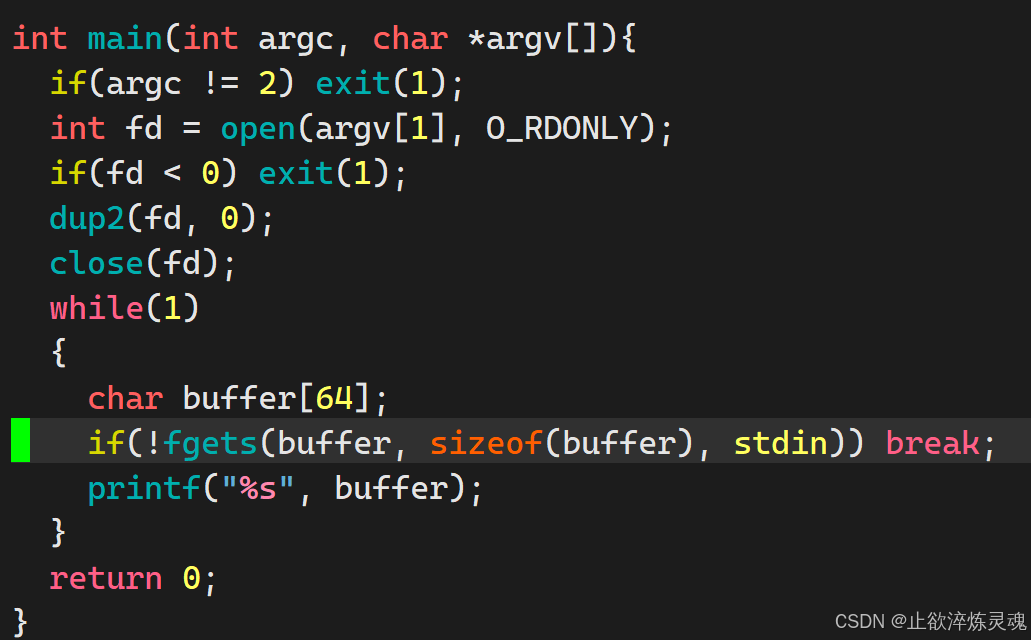
二、文件缓冲区
文件缓冲区有两个一个是用户级缓冲区,另一个则是系统内核级缓冲区。
(一)文件缓冲区两个层次
系统内核级缓冲区:
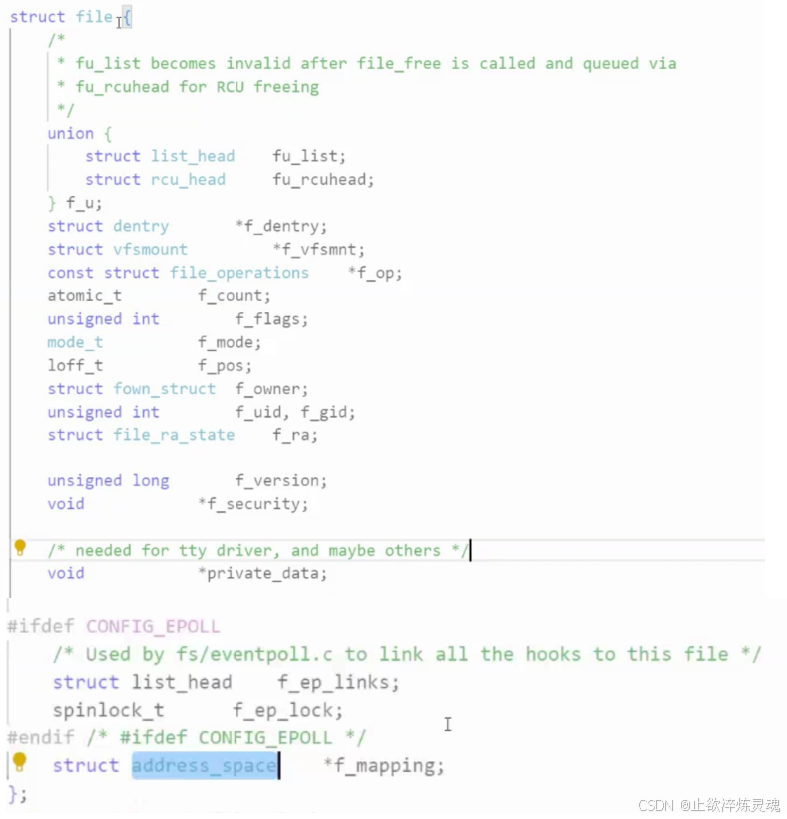
用户级缓冲区:
在系统中定义了typedef _IO_FILE FILE,通过这个指针底层封装了用户级缓冲区以及文件描述符。
(二)模拟实现文件缓冲区
cpp
#include "mystdio.h"
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <string.h>
#include <stdlib.h>
#include <unistd.h>
static MyFile *BuyFile(int fd, int flag)
{
MyFile *f = (MyFile*)malloc(sizeof(MyFile));
if(f == NULL) return NULL;
f->bufferlen = 0;
f->fileno = fd;
f->flag = flag;
f->flush_method = LINE_FLUSH;
memset(f->outbuffer, 0, sizeof(f->outbuffer));
return f;
}
MyFile *MyFopen(const char *path, const char *mode)
{
int fd = -1;
int flag = 0;
if(strcmp(mode, "w") == 0)
{
flag = O_CREAT | O_WRONLY | O_TRUNC;
fd = open(path, flag, 0666);
}
else if(strcmp(mode, "a") == 0)
{
flag = O_CREAT | O_WRONLY | O_APPEND;
fd = open(path, flag, 0666);
}
else if(strcmp(mode, "r") == 0)
{
flag = O_RDWR;
fd = open(path, flag);
}
else
{
//TODO
}
if(fd < 0) return NULL;
return BuyFile(fd, flag);
}
void MyFclose(MyFile *file)
{
if(file->fileno < 0) return;
MyFFlush(file);
close(file->fileno);
free(file);
}
int MyFwrite(MyFile *file, void *str, int len)
{
// 1. 拷贝
memcpy(file->outbuffer+file->bufferlen, str, len);
file->bufferlen += len;
// 2. 尝试判断是否满足刷新条件!
if((file->flush_method & LINE_FLUSH) && file->outbuffer[file->bufferlen-1] == '\n')
{
MyFFlush(file);
}
return 0;
}
void MyFFlush(MyFile *file)
{
if(file->bufferlen <= 0) return;
// 把数据从用户拷贝到内核文件缓冲区中
int n = write(file->fileno, file->outbuffer, file->bufferlen);
(void)n;
fsync(file->fileno);
file->bufferlen = 0;
}三、理解文件系统
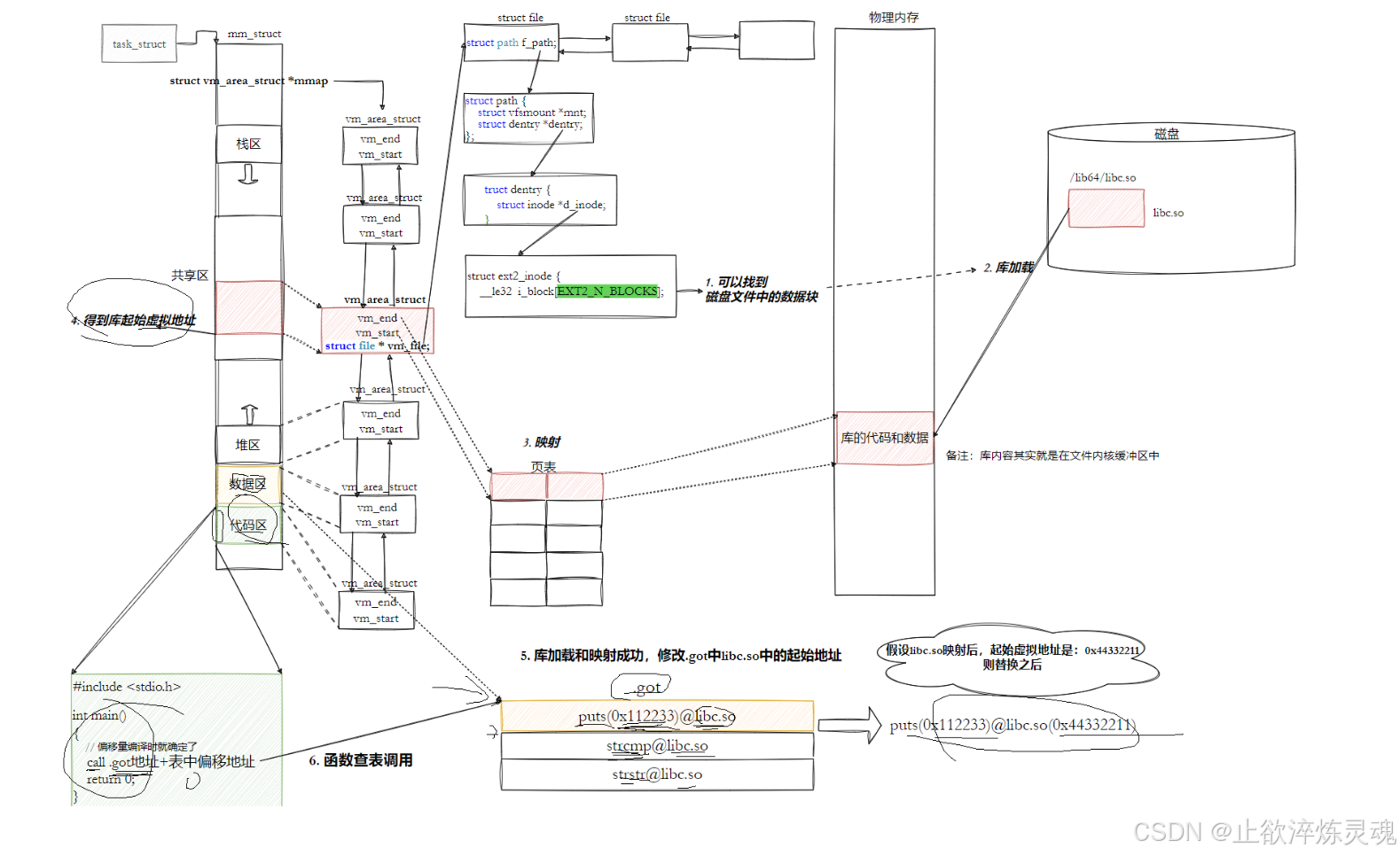
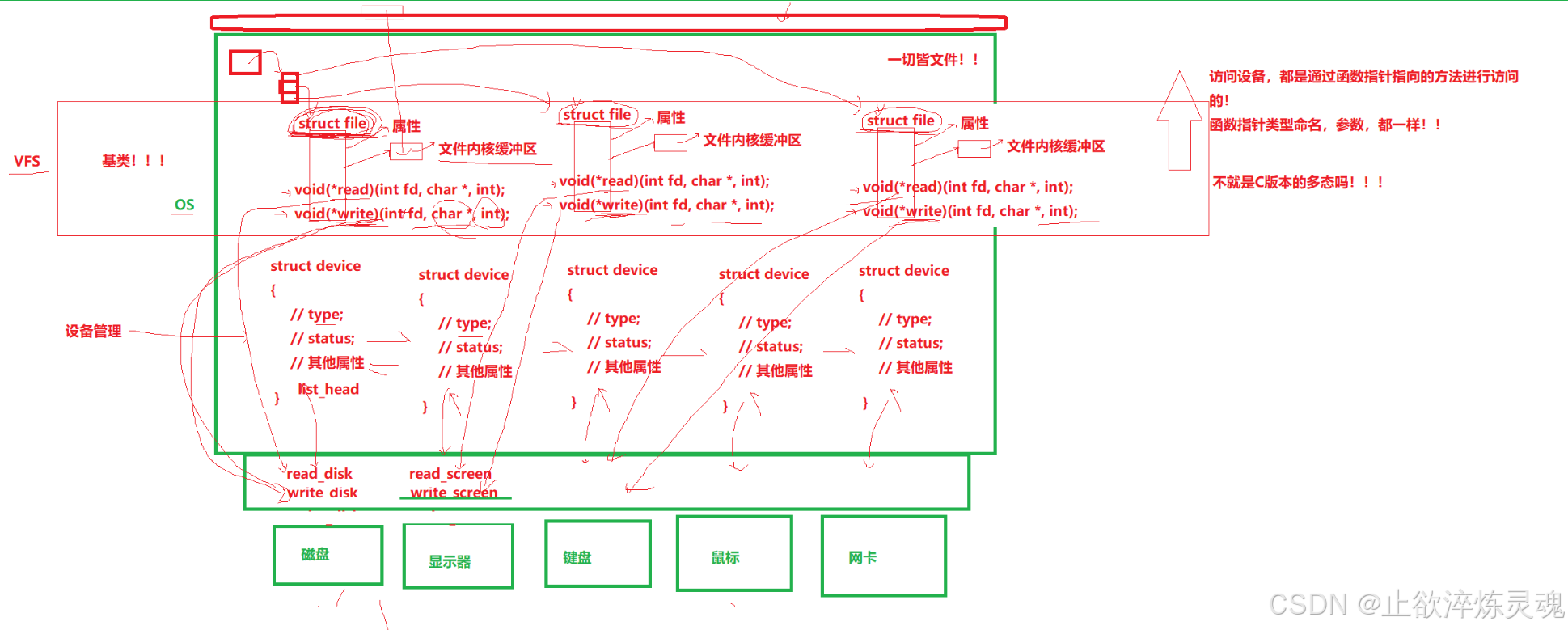
(一)虚拟文件系统(一切皆文件)
其中,struct file文件中的两个指针调用底层硬件的IO实现了一种类似多态一样的功能。
(二)文件系统
1、磁盘物理构造
物理结构中,扇区的存储类似一个三维数组,此时我们管这种存储方式叫做CHS寻址。
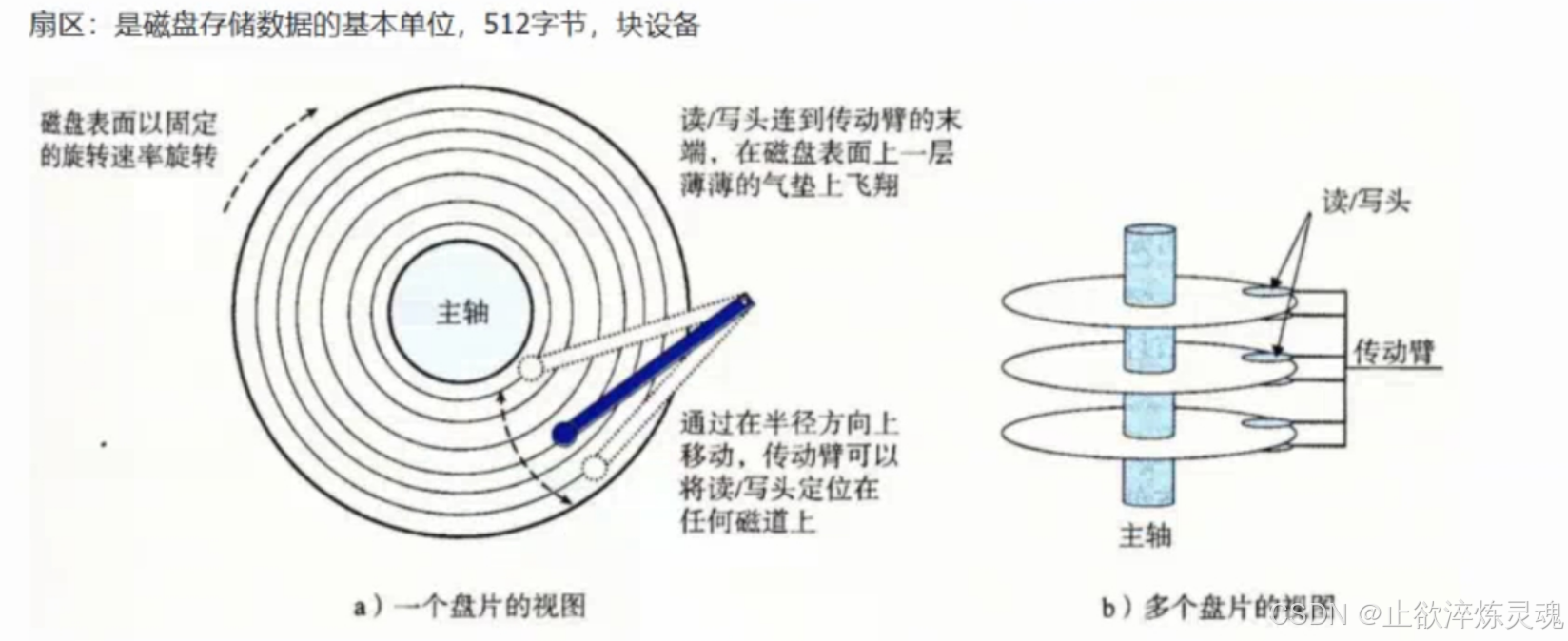

2、磁盘的逻辑结构
磁盘的储存和磁带类似,我们可以把磁盘存储理解成一个逻辑连续的线性结构,整片存储空间看成一个一维数组,其中每一个扇区的地址叫做LBA地址。

我们内存中读取一块内存也是以块(4KB)为单位。其中LBA和CHS地址是可以互相转化的,其中转化方式不在叙述。
3、文件系统结构
文件系统的载体是分区,每一个对磁盘单独划分的区域都是一个单独的文件系统。
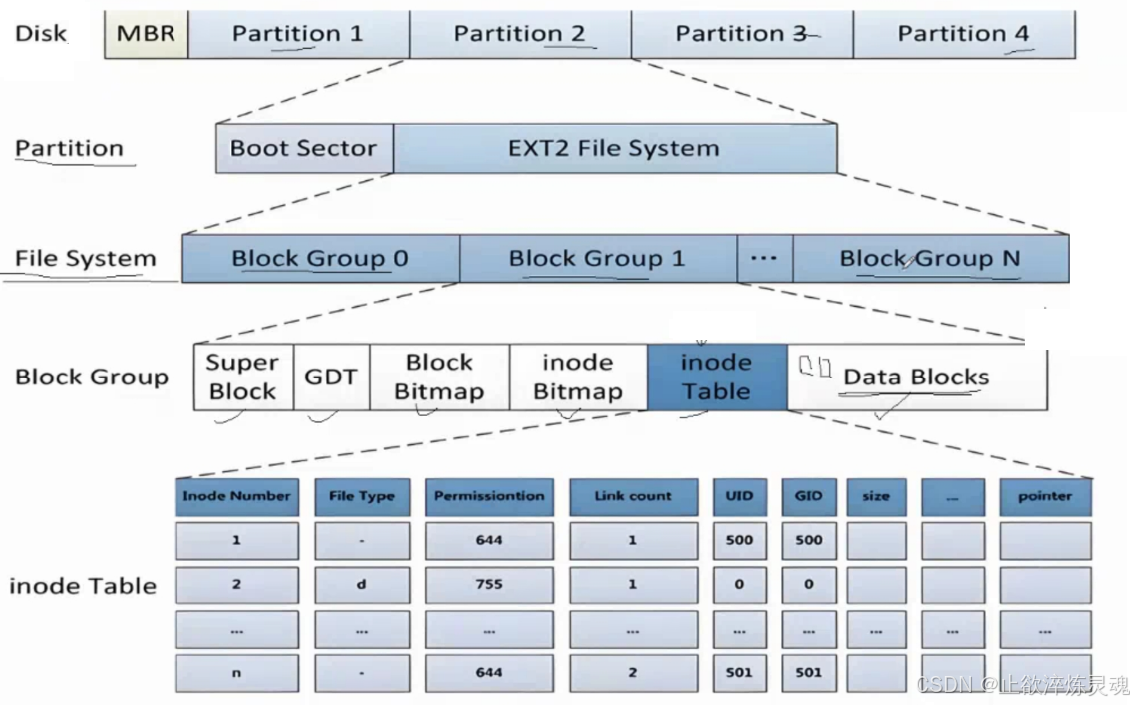
- Block Group :一块
Block Group的内存大小是4KB,一个inode的大小是128字节,因此一个块可以存储32个inode. - inode Table:跨组不跨分区,
inode里面有inode number,使用ls -li可以查看,此外还有一个整形数组用来进行到data Blocks的映射。

- GDT : 快组描述符,整个分区有多少个块组就有多少个块组描述符,用来描述快组的整体使用情况,记录每个区域的起始位置。
- Super Block :超级块,记录文件系统占用的总空间,文件系统中空闲和已使用的磁盘块数量。描述文件系统中块和inode的大小,记录根目录的
inode。
文件系统中对待文件和目录是一视同仁的,没有区分,其中目录里面的
data block存储内容是文件名,我们平时使用文件名查找信息时,先打开当前路径(路径由进程提供),读取目录里面的内容,得到文件名和inode间的映射关系,接着拿着这个inode去查找对应的信息。
硬链接/软连接
软连接: 相当于快捷方式,通过文件名字引用另外一个文件,实际上,新的文件和被引用的文件的inode不同。
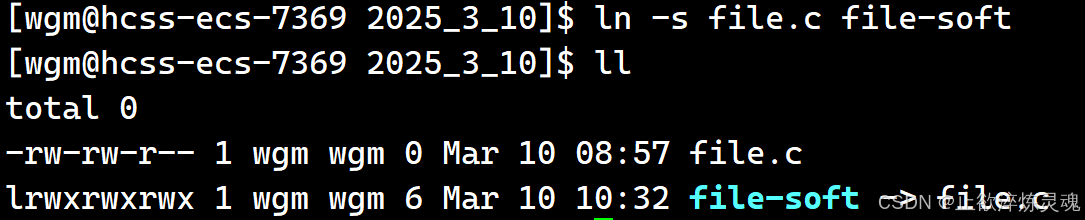

使用unlink取消快捷方式。
将来我们写程序时,如果程序的路径藏得比较深,那么我们可以建立一个软连接,这样我们可以通过软连接直接运行程序。
硬链接: 真正磁盘上找文件并不是找文件名,而是inode,其实可以让多个文件名对应同一个inode

硬链接的作用是对目标文件进行备份。
四、动态库和静态库
库是现有的成熟的可重复使用的代码,本质上是一种可执行的二进制形式(即
.o,可被操作系统载入内存运行。
(一)静态库
aLinux,libwindows
静态库实质是对.o文件进行打包,生成.a的归档文件,使用时直接用gcc, g++链接即可。
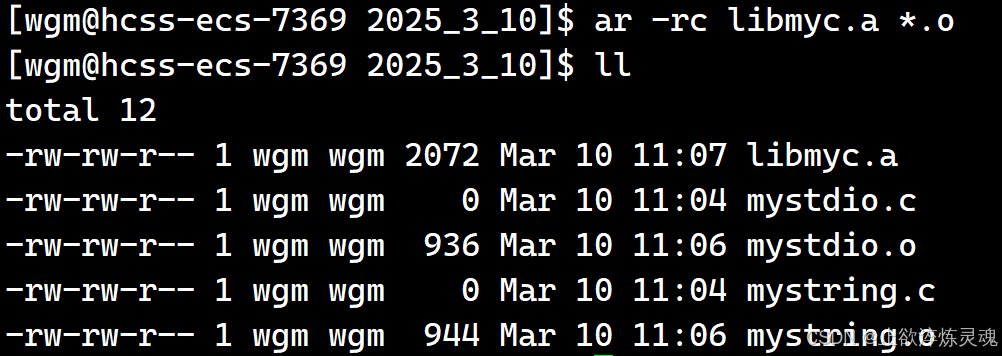
1、静态库制作
ar将文件进行归档,rc即replace and create。
2、静态库链接
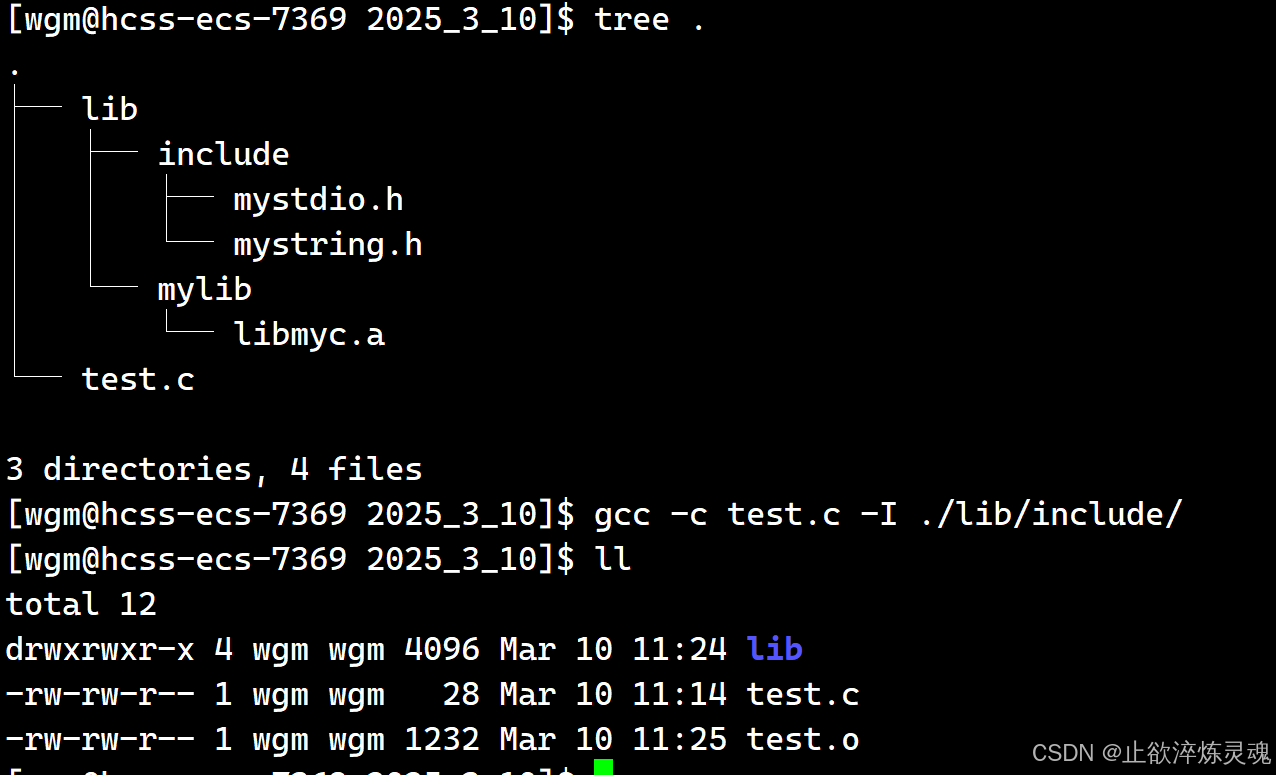
汇编阶段
我们在程序中包含的头文件如果不在同一个路径下,系统是找不到的,因此需要使用-I来指定路径
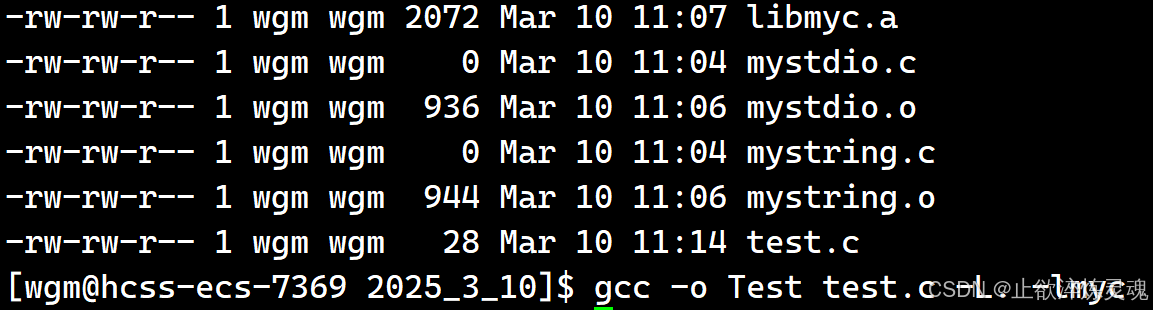
链接阶段
默认情况下,g++不会到当前路径去找库,需要添加选项-L,同时如果是自己写的库,也要注明编译器才会去查找。
或者说我们也可以直接将两个阶段合并成一个。

(二)动态库
soLinuxdllwindows
1、动态库制作
- 首先在编译时加入无关码选项。

- 生成的动态库也要添加选项,和静态库添加
ar有所差异。

2、动态库链接
我们直接再像之前静态库一样不能正常运行,此时我们有四种方法可以解决这个问题
- 1、将动态库拷贝到
/lib64/下。 - 2、制作软链接,指向
lib64/。 - 3、通过系统的环境变量来指明路径,通常情况下这个环境变量为空,我们需要手动创建。


- 4、在
/etc/ld.so.conf.d/路径下创建任何一个以.conf为后缀的文件,文件中的内容存放动态库的路径。
(三)链接原理
1、静态链接
静态链接是程序构建过程中的一个重要环节,它通过将目标文件和库文件合并成一个独立的可执行文件,下面以两份代码来模拟这个过程,以code.c代表静态库。
code.c:
cpp
#include<stdio.h>
void run()
{
printf("runing...\n");
}hello.c:
cpp
#include<stdio.h>
void run();
int main()
{
printf("hello, world!\n");
run();
return 0;
}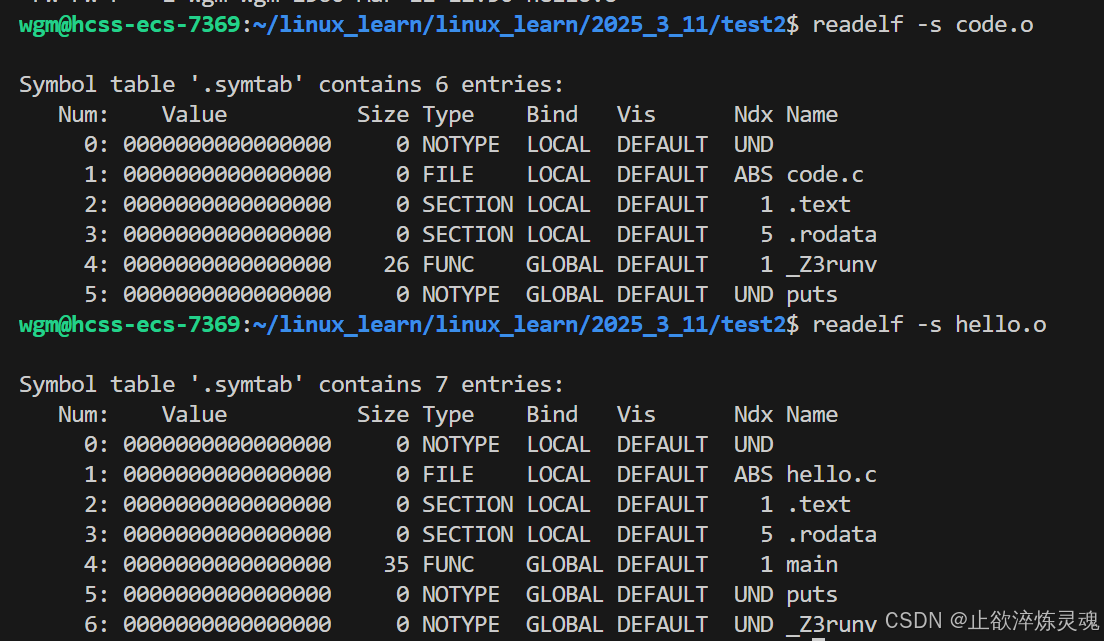
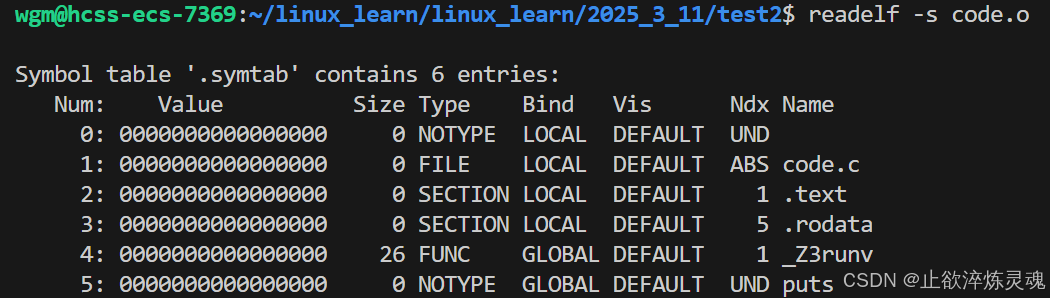
而我们链接将这两个.o文件合并成一个新的.o文件后,符号表就会互相填充,不再是UND未定义。
五、ELF格式
动静态库,可执行程序,可重定位.o文件都属于ELF格式的文件。
(一)ELF组成
- ELF header: 描述文件的特征,定位文件其它部分。
- Program header table(程序表头): 表里记录了每个段的开始位置和位移,长度。
- Section header table(节头表): 包含对节的描述。
- Section(节): ELF文件的基本组成单位,包含特定类型数据。如代码节存储可执行代码,数据节存储全局变量和静态变量。
程序头表和节头表作用:
链接视图(Linking view)-对应节头表Section header table文件结构的粒度更细,将文件按功能模块的差异进行划分, 为了空间布局上的效率,将来在链接目标文件时,链接器会把很多节(section)合并,规整成可执行的段(seqment)、可读写的段、只读段等。合并了后,空间利用率就高了。
执行视图(execution view)-对应程序头表program header table告诉操作系统,如何加载可执行文件,完成进程内存的初始化。一个可执行程序的格式中,一定有
program header table.
重要的节
- Text 段:存储程序的代码,只读且共享。
cpp
当你编写一个简单的函数
int add(int a, int b) { return a + b; },
编译后,这个函数的指令会被存储在 Text 节中。- Data 段:存储初始化的全局变量和静态变量,可读写。
cpp
int global_var = 10; // 这个变量会存储在 Data 段中
static int static_var = 20; // 同样存储在 Data 段- BSS 段:存储未初始化的全局变量和静态变量,运行时自动初始化为零,节省空间。
cpp
int uninitialized_global; // 未初始化的全局变量,存储在 BSS 段
static int uninitialized_static; // 未初始化的静态变量,也存储在 BSS 段(二)ELF形成可执行
一个ELF会有多种不同的
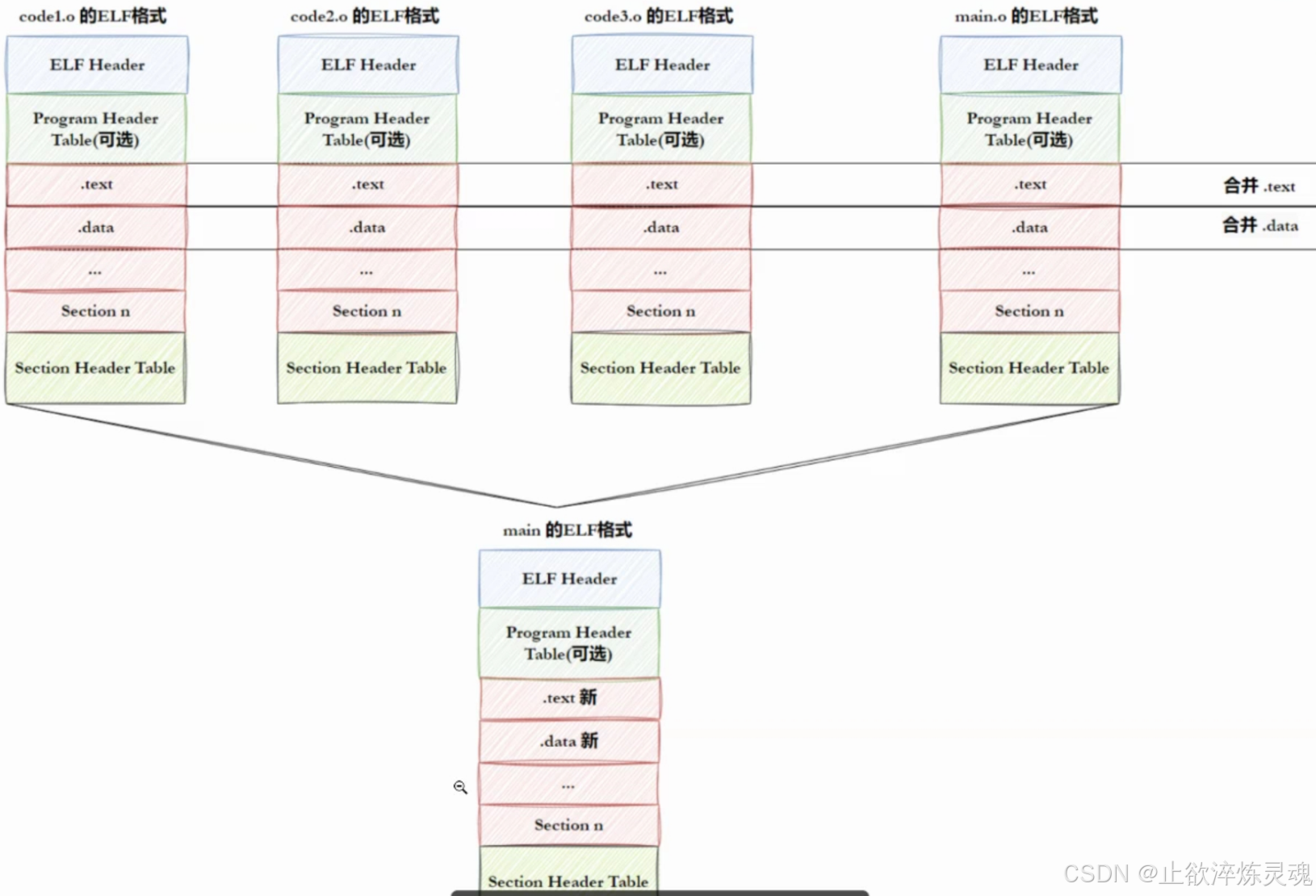
Section,在加载到内存的时候,也会进行Section合并,形segment合并原则:相同属性,比如:可读,可写,可执行,需要加载时申请空间等。这样,即便是不同的Section,在加载到内存中,可能会以segment的形式,加载到一起,这个合并工作也已经在形成ELF的时候,合并方式已经确定了,具体合并原则被记录在了ELF的 程序头表(Program header table)中
- 1、将多份
c++代码编译形成.o文件 + 动静态库(ELF) - 2、将多份
.o文件section进行合并
1、Section合并的主要=是为了减少页面碎片,提高内存使用效率。如果不进行合并,假设页面大小为4096字节(内存块基本大小,加载,管理的基本单位),如果.text部分为4097字节,.init部分为512字节,那么它们将占用3个页面,而合并后,它们只需2个页面。
2、操作系统在加载程序时,会将具有相同属性的
section合并成一个大的segment,这样就可以实现不同的访问权限,从而优化内存管理和权限访问控制。
(三)ELF常用指令
使用size查看ELF格式文件的组成。

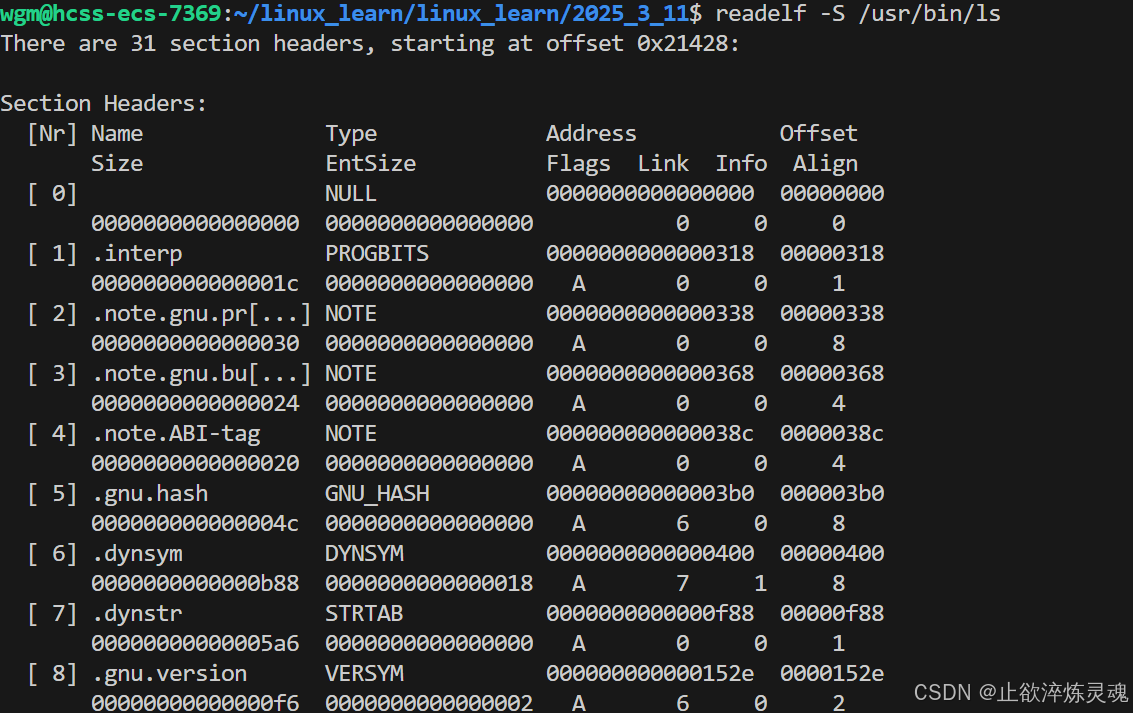
使用readelf -S可以用来查看文件的节头表,当前一共 30 个结点,里面标识了起始地址和偏移量。
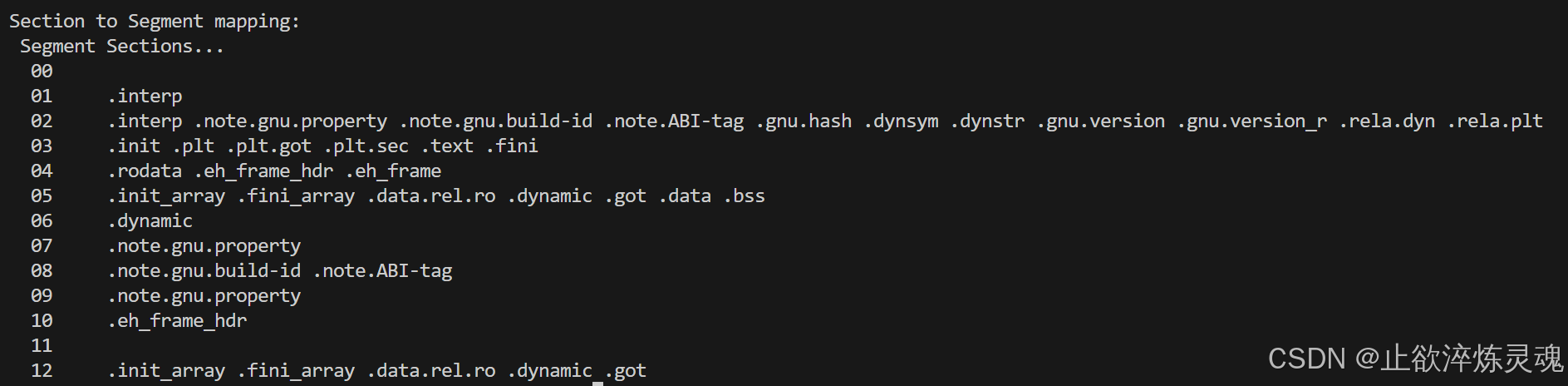
使用readelf -l可以用来查看文件的程序头表,将 30 个节打包成指定数量的段segment
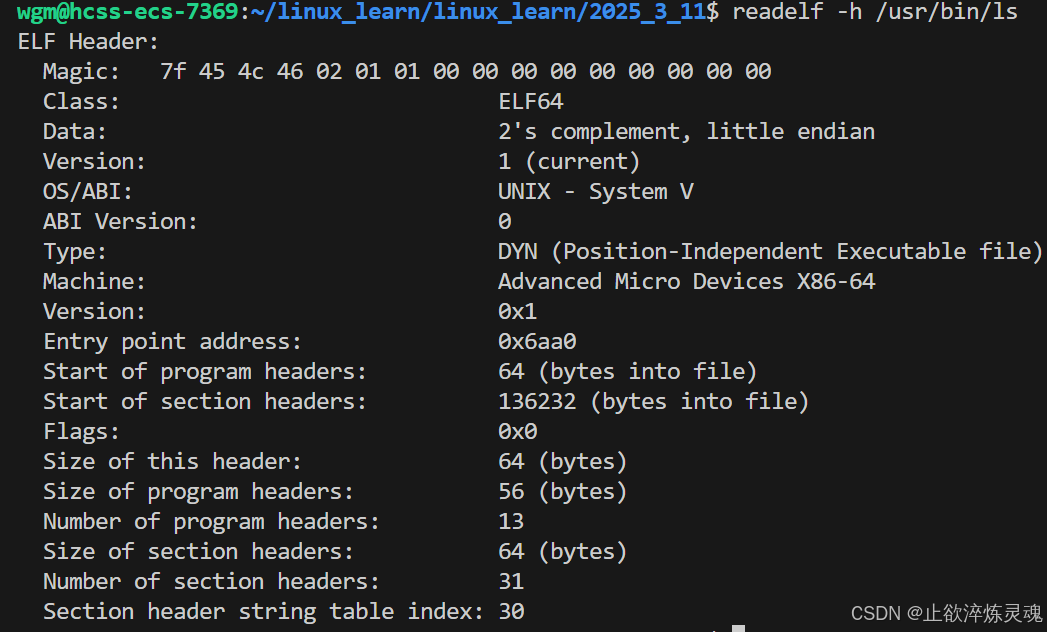
使用readelf -h可以用来查看文件的程序头表
其中Magic用来判断该ELF是一个可执行程序,Entry point address是指程序的入口地址。
使用readelf -s查看ELF文件的符号表
(四)ELF转化成可执行程序
1、逻辑地址,物理地址,虚拟地址
程序在开始时,我们都选择从 0 开始,这种编制方式也叫平坦模式。其实函数在编译好之后使用的地址已经是虚拟地址了,对应虚拟地址空间。
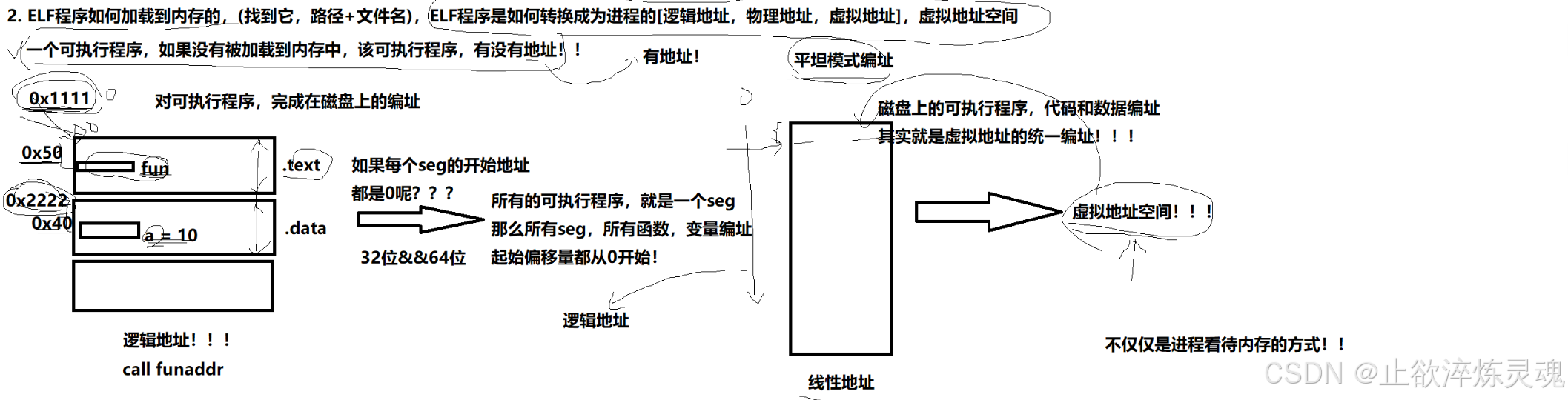
在存储时,每一个虚拟地址都对应了磁盘中的一个物理地址。
操作系统读取磁盘时,将磁盘上的物理地址和虚拟地址同时读入内存。
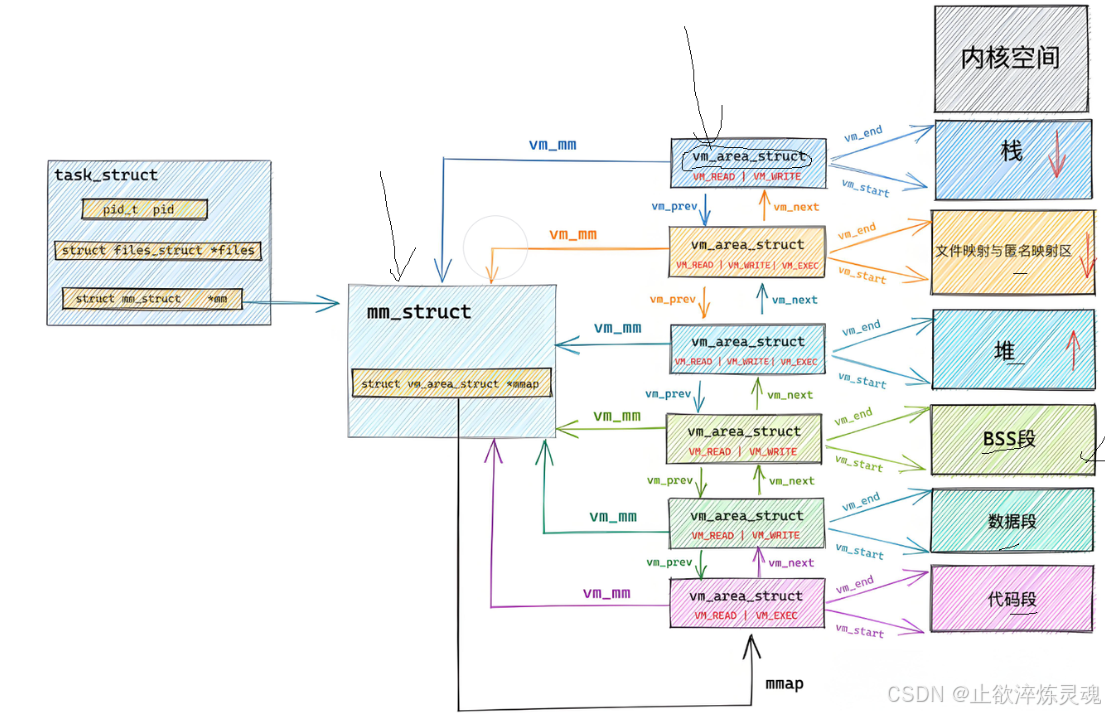
2、磁盘加载程序
cpu将可执行程序第一条语句的地址到寄存器EIP中,开始执行程序。

3、动态库如何与可执行程序关联
动态链接实际上将链接的过程推迟到了程序加载的时候。
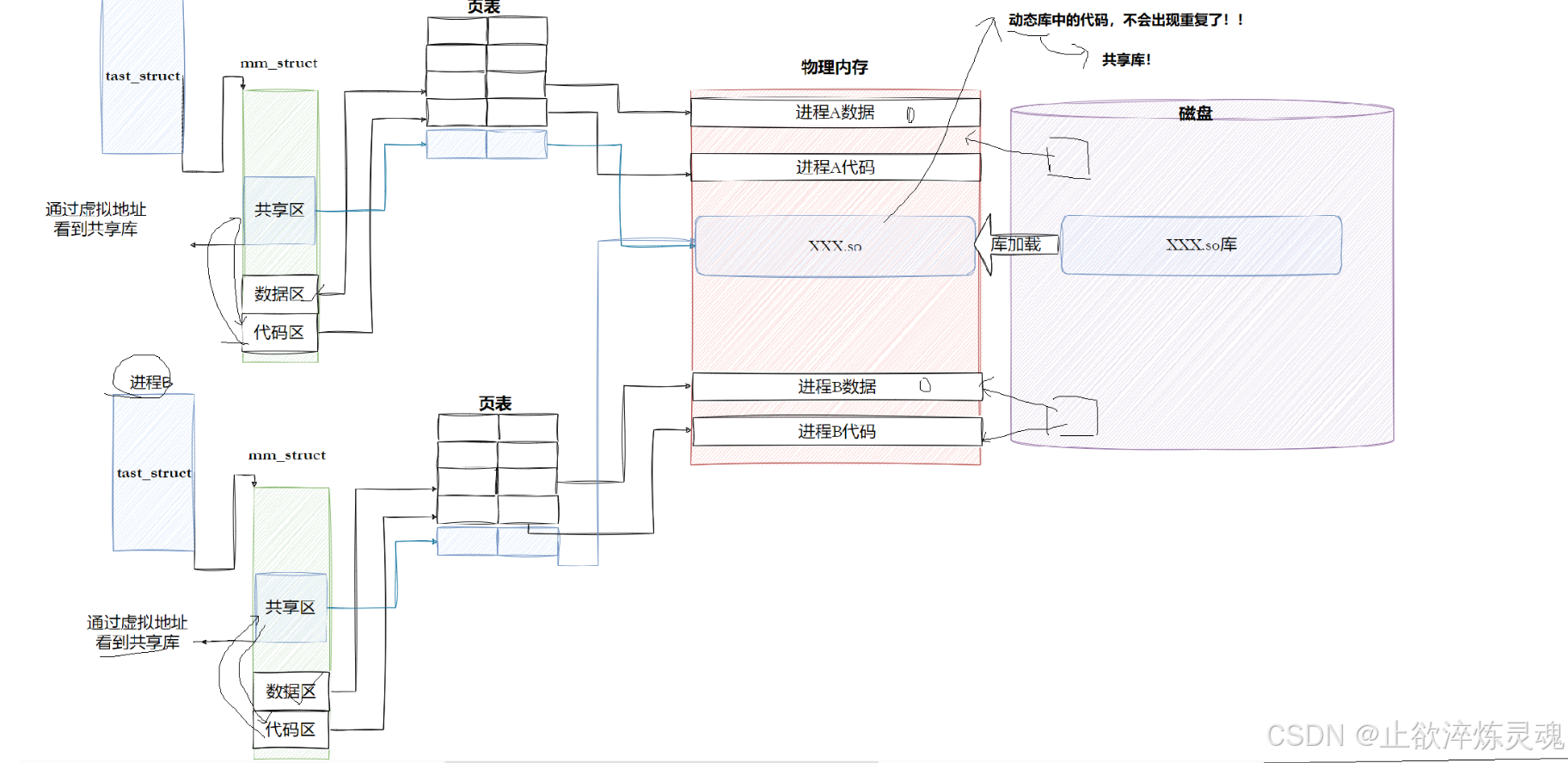
在C/C++程序中,当程序开始执行时,它首先并不会直接跳转到 main 函数。实际上,程序的入口点是_start这是一个由C运行时库(通常是glibc)或链接器(如Id)提供的特殊函数。
在start函数中,会执行一系列初始化操作,这些操作包括:
- 1.设置堆栈:为程序创建一个初始的堆栈环境。
- 2.初始化数据段:将程序的数据段(如全局变量和静态变量)从初始化数据段复制到相应的内存位置,并清零未初始化的数据段。
- 3.动态链接:这是关键的一步,_start 函数会调用动态链接器的代码来解析和加载程序所依赖的动态库(shared libraries)。动态链接器会处理所有的符号解析和重定位,确保程序中的函数调用和变量访问能够正确地映射到动态库中的实际地址。
- 4.调用 -1ibc_start_main:一旦动态链接完成,_start 函数会调用1ibc_start_main(这是glibc提供的一个函数)。1ibc_start_main 函数负责执行一些额外的初始化工作,比如设置信号处理函数、初始化线程库(如果使用了线程)等。
- 5.调用 main 函数:最后,libc_start_main 函数会调用程序的 main 函数,此时程序的执行控制权才正式交给用户编写的代码。
- 6.处理 main 函数的返回值:当 main 函数返回时,1ibc_start_main 会负责处理这个返回值,并最终调用_exit 函数来终止程序。