📢博客主页:https://blog.csdn.net/2301_779549673
📢博客仓库:https://gitee.com/JohnKingW/linux_test/tree/master/lesson
📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
📢本文由 JohnKi 原创,首发于 CSDN🙉
📢未来很长,值得我们全力奔赴更美好的生活✨


文章目录
- [🏳️🌈一、HttpRequest 类](#🏳️🌈一、HttpRequest 类)
-
- [1.1 基本结构](#1.1 基本结构)
- [1.2 构造函数、析构函数](#1.2 构造函数、析构函数)
- [1.3 反序列化函数 Descrialize](#1.3 反序列化函数 Descrialize)
- [1.4 获取一行字符串 GetLine()](#1.4 获取一行字符串 GetLine())
- [1.5 打印方法 Print](#1.5 打印方法 Print)
- [1.6 解析请求行 PraseReqLine](#1.6 解析请求行 PraseReqLine)
- [1.7 解析请求头 void PraseHeader();](#1.7 解析请求头 void PraseHeader();)
- [1.8 增加路径字段](#1.8 增加路径字段)
- [1.9 测试](#1.9 测试)
- [🏳️🌈二 、整体代码](#🏳️🌈二 、整体代码)
- 👥总结
🏳️🌈一、HttpRequest 类
1.1 基本结构
我们结合这张图,构建出 http请求 的基本结构,并定义一些基本方法
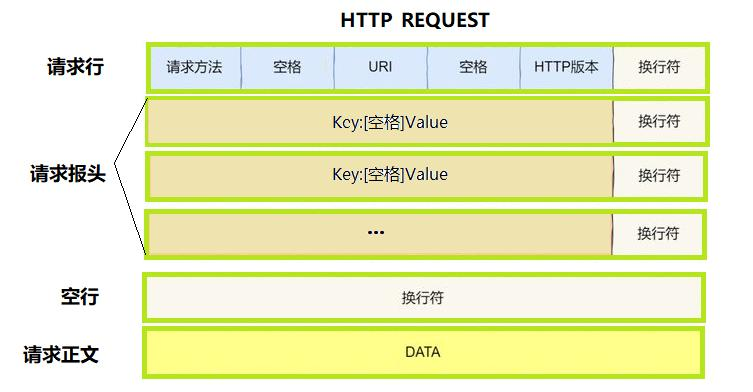
const static std::string _base_sep = "\r\n"; // static 关键字使变量具有内部链接,仅当前翻译单元(源文件)可见。
class HttpRequest {
private:
std::string GetLine(std::string& reqstr); // 获取一行信息
void PraseReqLine(); // 解析请求行
void PraseHeader(); // 解析请求头
public:
HttpRequest();
void Descrialize(std::string& reqstr);
void Print();
~HttpRequest();
private:
std::string _req_line; // 请求行
std::vector<std::string> _req_headers; // 请求报头
std::string _blank_line; // 空行
std::string _req_body; // 请求体
};1.2 构造函数、析构函数
构造函数 初始化空行即可,因为空行是固定的,析构函数无需处理!
HttpRequest() : _blank_line(_base_sep) {}
~HttpRequest() {}1.3 反序列化函数 Descrialize
我们这里是需要解析获取到的请求,所以用的方法自然是 反序列化
void Descrialize(std::string& reqstr) {
// 基本的反序列化
_req_line = GetLine(reqstr); // 读取第一行请求行
// 请求报头
std::string header;
do {
header = GetLine(reqstr);
// 如果既不是空,也不是空行,就是请求报头,加入到请求报头列表中
if (header.empty())
break;
else if (header == _base_sep)
break;
_req_headers.push_back(header);
} while (true);
// 正文
if (!reqstr.empty())
_req_body = reqstr;
}1.4 获取一行字符串 GetLine()
// 获取一行信息
std::string GetLine(std::string& reqstr) {
auto pos = reqstr.find(_base_sep);
if (pos == std::string::npos)
return "";
std::string line = reqstr.substr(0, pos); // 截取一行有效信息
reqstr.erase(0, pos + _base_sep.length()); // 删除有效信息和分隔符
return line.empty() ? _base_sep
: line; // 有效信息为空则返回分隔符,否则返回有效信息
}1.5 打印方法 Print
void Print() {
std::cout << "----------------------------------------" << std::endl;
std::cout << "请求行: " << _req_line << std::endl;
std::cout << "请求报头: " << std::endl;
for (auto& header : _req_headers) {
std::cout << header << std::endl;
}
std::cout << "空行: " << _blank_line << std::endl;
std::cout << "请求体: " << _req_body << std::endl;
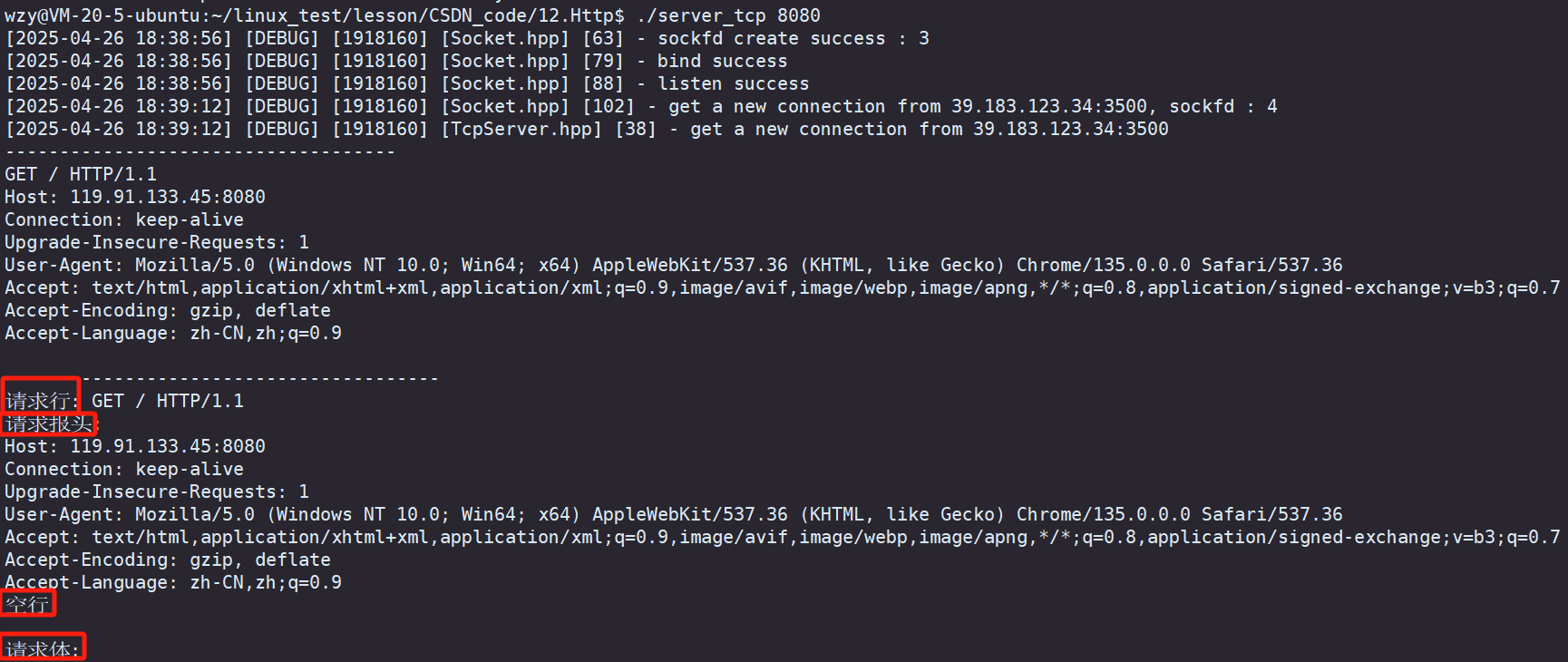
}当我们使用浏览器访问我们的服务器,就能够成功地将我们需要地所有信息给序列化出来,这里没有请求,所以请求体为空
1.6 解析请求行 PraseReqLine
我们已经知道请求行的组成如下,所以我们可以进一步细分 HttpRequest 类,增加响应的请求行的成员变量

std::string _method; // 请求方法
std::string _url; // 请求url
std::string _version; // 请求版本将 _req_line(请求行)封装为字符串流,按空格分隔读取方法、路径、协议版本
// 解析请求行
void PraseReqLine() {
// 以空格为分隔符,不断读取
std::stringstream ss(_req_line);
ss >> _method >> _url >> _version;
}1.7 解析请求头 void PraseHeader();

我们可以知道请求报头中存在类似哈希表的 KV 结构 ,因此我们可以是使用一个 unordered_map,存储每一个键值对

根据我们之前获取到的请求报头,可以知道分隔符是 ": ",可以根据这个进行解析请求报头
// 解析请求头
void PraseHeader() {
for (auto& header : _req_headers) {
auto pos = header.find(':');
if (pos == std::string::npos)
continue;
std::string k = header.substr(0, pos);
std::string v = header.substr(pos + _line_sep.size());
if (k.empty() || v.empty())
continue;
_headers_kv[k] = v;
}
}1.8 增加路径字段
**我们向服务器请求的时候,需要知道资源的路径,因此我们可以增加路径字段
**
-
我们提供一个路径的前缀
wwwroot -
并且当这个用户访问的路径为
/时,提供默认路径default.htmlconst static std::string _prefix_path = "wwwroot"; // 默认前缀路劲
const static std::string _default_path = "default.html"; // 默认路径
我们可以在构造函数时,给路劲添加上默认前缀路径
HttpRequest() : _blank_line(_base_sep), _path(_prefix_path) {}我们在解析 请求行 时对 url 进行分析,判断是否为空,并且给 path 赋值
void PraseReqLine(){
// 以空格为分隔符,不断读取
std::stringstream ss(_req_line);
ss >> _method >> _url >> _version;
_path += _url;
// 处理url,如果是根目录,则返回默认路径
if(_url == "/")
_path += _default_path;
}提供两个新方法用来获取当前的 url 和 路径
std::string Url() {
LOG(LogLevel::INFO) << "client want url : " << _url;
return _url;
}
std::string Path() {
LOG(LogLevel::INFO) << "client want url : " << _path;
return _path;
}1.9 测试
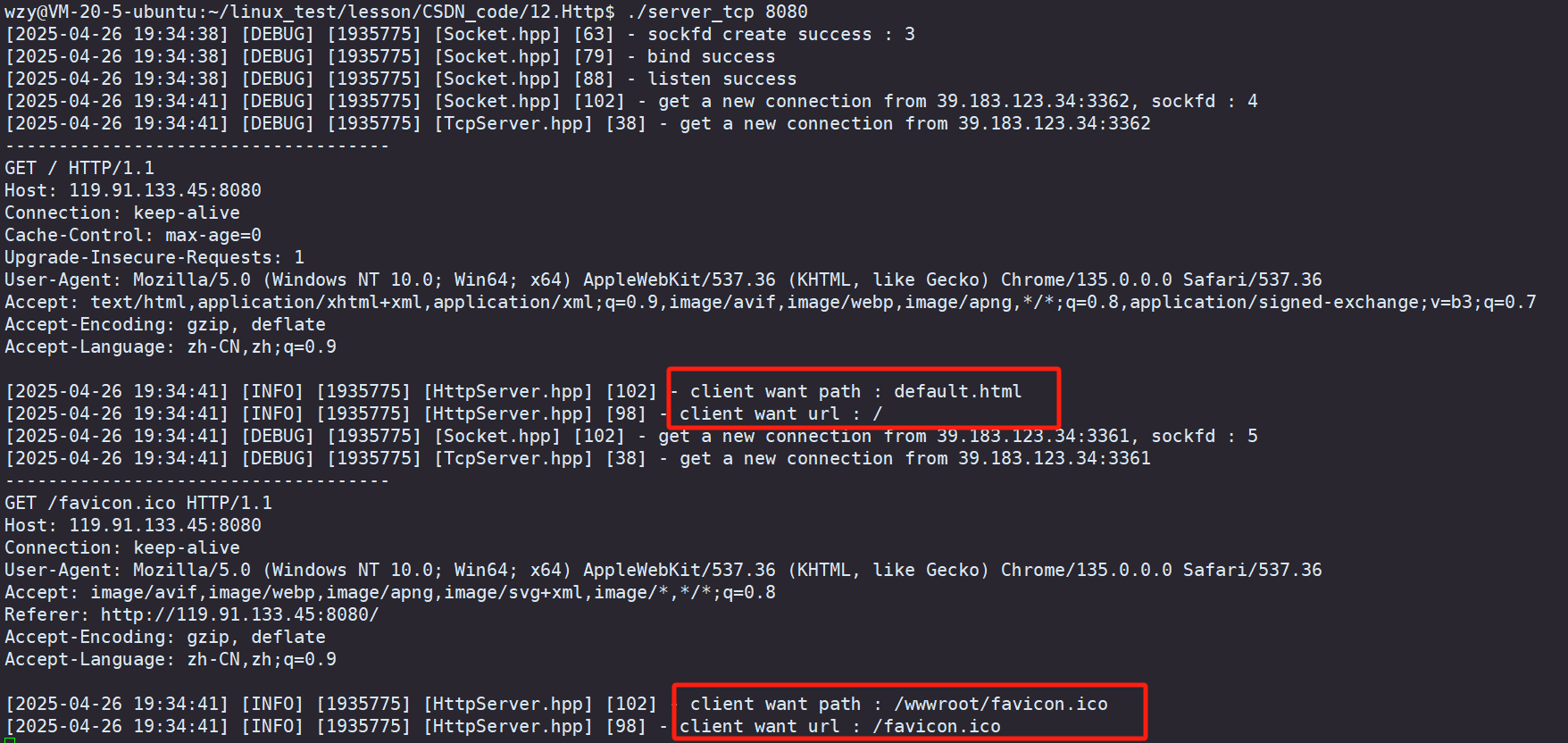
我们运行服务端后,再用浏览器访问我们的服务器,成功捕捉到了两次请求,
- 第一次请求(端口 3362):
浏览器主动请求你输入的 URL(如 http://119.91.133.45:8080/),服务端返回页面/default.html - 第二次请求(端口 3361):
浏览器 自动请求网站图标 /favicon.ico,用于在标签页、书签栏显示小图标。若服务端未显式处理该请求,浏览器仍会尝试获取。
🏳️🌈二 、整体代码
#pragma once
#include <iostream>
#include <string>
#include <vector>
#include <sstream>
#include <unordered_map>
#include "Log.hpp"
using namespace LogModule;
const static std::string _base_sep = "\r\n"; // static 关键字使变量具有内部链接,仅当前翻译单元(源文件)可见。
// const static std::string _base_sep = "\r\n"; // 默认具有外部链接,其他文件可通过 extern 引用。
const static std::string _line_sep = ": ";
const static std::string _prefix_path = "/wwwroot"; // 默认前缀路劲
const static std::string _default_path = "default.html"; // 默认路径
namespace HttpServer{
class HttpRequest{
private:
// 获取一行信息
std::string GetLine(std::string& reqstr){
auto pos = reqstr.find(_base_sep);
if(pos == std::string::npos) return "";
std::string line = reqstr.substr(0, pos); // 截取一行有效信息
reqstr.erase(0, pos + _base_sep.length()); // 删除有效信息和分隔符
return line.empty() ? _base_sep : line; // 有效信息为空则返回分隔符,否则返回有效信息
}
// 解析请求行
void PraseReqLine(){
// 以空格为分隔符,不断读取
std::stringstream ss(_req_line);
ss >> _method >> _url >> _version;
_path += _url;
// 处理url,如果是根目录,则返回默认路径
if(_url == "/")
_path = _default_path;
}
// 解析请求头
void PraseHeader(){
for(auto& header : _req_headers){
auto pos = header.find(':');
if(pos == std::string::npos)
continue;
std::string k = header.substr(0, pos);
std::string v = header.substr(pos + _line_sep.size());
if(k.empty() || v.empty()) continue;
_headers_kv[k] = v;
}
}
public:
HttpRequest() : _blank_line(_base_sep), _path(_prefix_path) {}
void Descrialize(std::string& reqstr){
// 基本的反序列化
_req_line = GetLine(reqstr); // 读取第一行请求行
// 请求报头
std::string header;
do{
header = GetLine(reqstr);
// 如果既不是空,也不是空行,就是请求报头,加入到请求报头列表中
if(header.empty()) break;
else if(header == _base_sep) break;
_req_headers.push_back(header);
}while(true);
// 正文
if(!reqstr.empty())
_req_body = reqstr;
// 进一步反序列化请求行
PraseReqLine();
// 分割请求报头,获取键值对
PraseHeader();
}
void Print(){
std::cout << "----------------------------------------" <<std::endl;
std::cout << "请求行: ###" << _req_line << std::endl;
std::cout << "请求报头: " << std::endl;
for(auto& header : _req_headers){
std::cout << "@@@" << header << std::endl;
}
std::cout << "空行: " << _blank_line << std::endl;
std::cout << "请求体: " << _req_body << std::endl;
std::cout << "Method: " << _method << std::endl;
std::cout << "Url: " << _url << std::endl;
std::cout << "Version: " << _version << std::endl;
}
std::string Url(){
LOG(LogLevel::INFO) << "client want url : " << _url;
return _url;
}
std::string Path(){
LOG(LogLevel::INFO) << "client want path : " << _path;
return _path;
}
~HttpRequest() {}
private:
std::string _req_line; // 请求行
std::vector<std::string> _req_headers; // 请求报头
std::string _blank_line; // 空行
std::string _req_body; // 请求体
std::string _method; // 请求方法
std::string _path; // 资源路径
std::string _url; // 请求url
std::string _version; // 请求版本
std::unordered_map<std::string, std::string> _headers_kv; // 存储每行报文的哈希表
};
class HttpHandler{
public:
HttpHandler(){}
std::string handle(std::string req){
std::cout << "------------------------------------" << std::endl;
std::cout << req;
HttpRequest req_obj;
req_obj.Descrialize(req);
// req_obj.Print();
std::string path = req_obj.Path();
std::string url = req_obj.Url();
std::string responsestr = "HTTP/1.1 200 OK\r\n";
responsestr += "Content-Type: text/html\r\n";
responsestr += "\r\n";
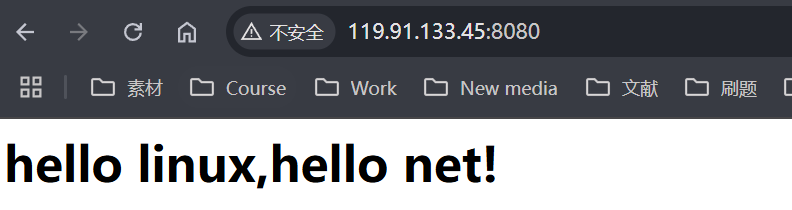
responsestr += "<html><h1>hello linux,hello net!<h2></html>";
return responsestr;
}
~HttpHandler(){}
};
}👥总结
本篇博文对 【Linux网络】构建与优化HTTP请求处理 - 从HttpRequest到HttpServer 做了一个较为详细的介绍,不知道对你有没有帮助呢
觉得博主写得还不错的三连支持下吧!会继续努力的~