文章目录
- 逻辑回归简介
-
- sigmoid函数绘制
- [Sigmoid 作用](#Sigmoid 作用)
- 逻辑回归使用sigmoid函数的原因
- 关键推导步骤
- 伯努利分布关联
- 广义线性模型和指数族分布
- 逻辑回归损失函数的推导
逻辑回归简介
- 逻辑回归算法是基于多元线性回归的算法,逻辑回归是一个分类的算法,逻辑回归算法是基于多元线性回归的算法。
- 逻辑回归是线性的分类器。
- 拓展:基于决策树的一系列算法,基于神经网络的算法等那些是非线性的算法。SVM支持向量机的本质是线性的,但是也可以通过内部的核函数升维来变成非线性的算法。
sigmoid函数绘制
python
import math
import matplotlib.pyplot as plt
import numpy
def sigmoid(x):
a=[]
for item in x:
a.append(1.0/(1.0+math.exp(-item)))
return a
x=numpy.arange(-10,10,0.1)
y=sigmoid(x)
plt.title("sigmoid function achieve")
plt.plot(x,y)
plt.xlabel("x")
plt.ylabel("y")
plt.show()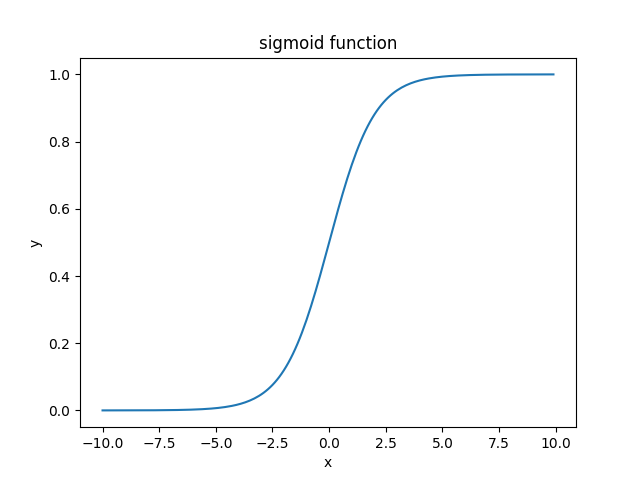
Sigmoid 作用
- 逻辑回归就是在多元线性回归基础上把结果缩放到0到1之间。 h θ ( x ) h_\theta(x) hθ(x)越接近+1越是正例, h θ ( x ) h_\theta(x) hθ(x)越接近0越是负例,根据中间0.5分为二类。
h θ ( x ) = g ( θ T x ) = 1 1 + e − θ T x h_\theta(x)=g(\theta^Tx)=\frac{1}{1+e^{-\theta^Tx}} hθ(x)=g(θTx)=1+e−θTx1 - 分类器的本质就是要找到分界,当把0.5作为分界时,即 z = θ T x = 0 z=\theta^Tx=0 z=θTx=0的解
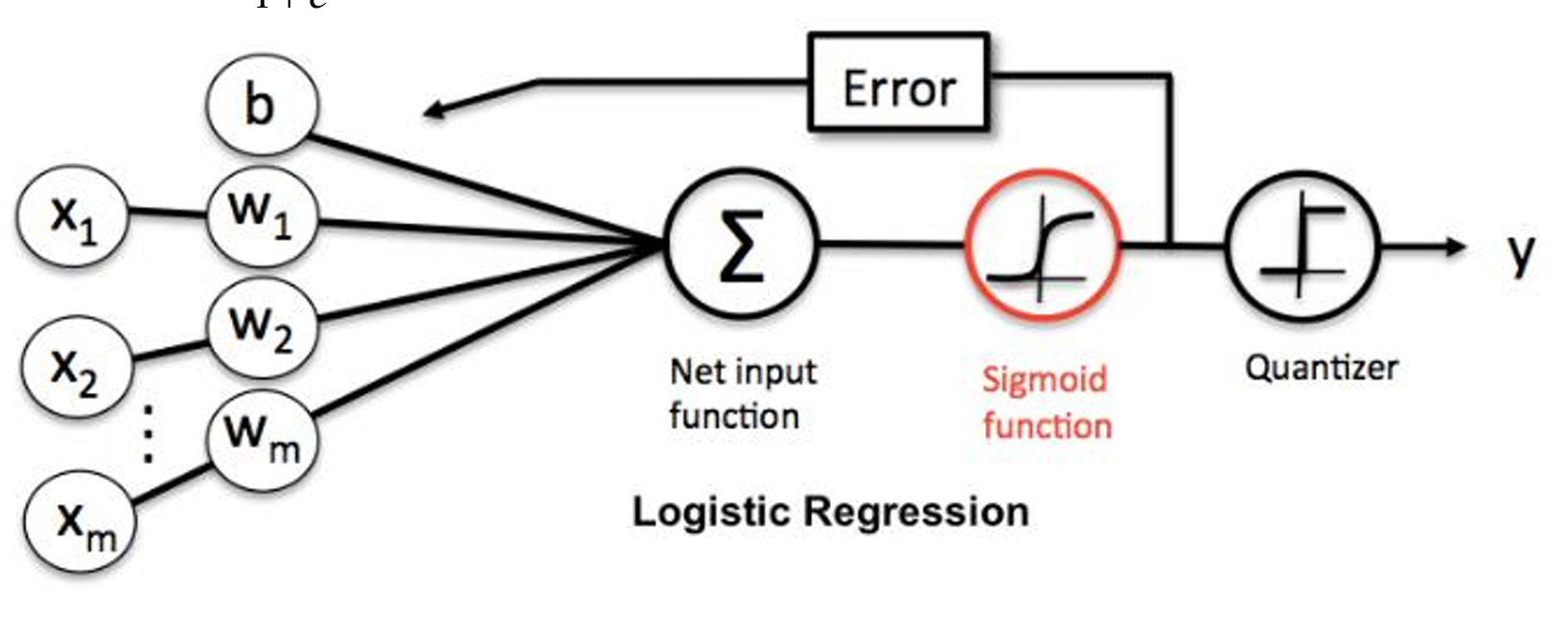
逻辑回归使用sigmoid函数的原因
Sigmoid函数天然满足:
- 概率映射(输出∈(0,1))
- 对数几率线性化
- 与伯努利分布完美结合
因此成为逻辑回归的理想选择。
- 核心原因:
Sigmoid函数能将线性模型的输出(任意实数)压缩到(0,1)区间,直接对应"属于正类的概率",同时满足二分类中"正负类概率之和为1"的要求。
关键推导步骤
-
建模概率比值 :
假设正类概率为 P ( y = 1 ) = p P(y=1) = p P(y=1)=p,负类概率 P ( y = 0 ) = 1 − p P(y=0) = 1-p P(y=0)=1−p。定义**几率比(Odds Ratio)**为:
Odds = p 1 − p \text{Odds} = \frac{p}{1-p} Odds=1−pp取对数后,用线性模型拟合:
log ( p 1 − p ) = w T x + b \log\left(\frac{p}{1-p}\right) = w^T x + b log(1−pp)=wTx+b -
解出概率 p p p
通过指数运算反解:
p 1 − p = e w T x + b ⟹ p = e w T x + b 1 + e w T x + b = 1 1 + e − ( w T x + b ) \frac{p}{1-p} = e^{w^T x + b} \implies p = \frac{e^{w^T x + b}}{1 + e^{w^T x + b}} = \frac{1}{1 + e^{-(w^T x + b)}} 1−pp=ewTx+b⟹p=1+ewTx+bewTx+b=1+e−(wTx+b)1最终形式正是Sigmoid函数:
P ( y = 1 ) = σ ( w T x + b ) = 1 1 + e − ( w T x + b ) P(y=1) = \sigma(w^T x + b) = \frac{1}{1 + e^{-(w^T x + b)}} P(y=1)=σ(wTx+b)=1+e−(wTx+b)1
伯努利分布关联
逻辑回归的标签 ( y ) 服从伯努利分布( y ∈ { 0 , 1 } y \in \{0,1\} y∈{0,1}),其概率质量函数可统一写成:
P ( y ) = p y ( 1 − p ) 1 − y , 其中 p = σ ( w T x + b ) P(y) = p^y (1-p)^{1-y}, \quad \text{其中} \ p = \sigma(w^T x + b) P(y)=py(1−p)1−y,其中 p=σ(wTx+b)
最大化该分布的似然函数,即得到逻辑回归的优化目标。
广义线性模型和指数族分布
逻辑回归损失函数的推导
- 根据若干已知的X,y(训练集)找到一组W使得X作为已知条件下y发生的概率最大。逻辑回归中既然 g ( w , x ) g(w,x) g(w,x)的输出含义为 P ( y = 1 ∣ w , x ) P(y=1|w,x) P(y=1∣w,x),那么 P ( y = 0 ∣ w , x ) = 1 − g ( w , x ) P(y=0|w,x)=1-g(w,x) P(y=0∣w,x)=1−g(w,x)。
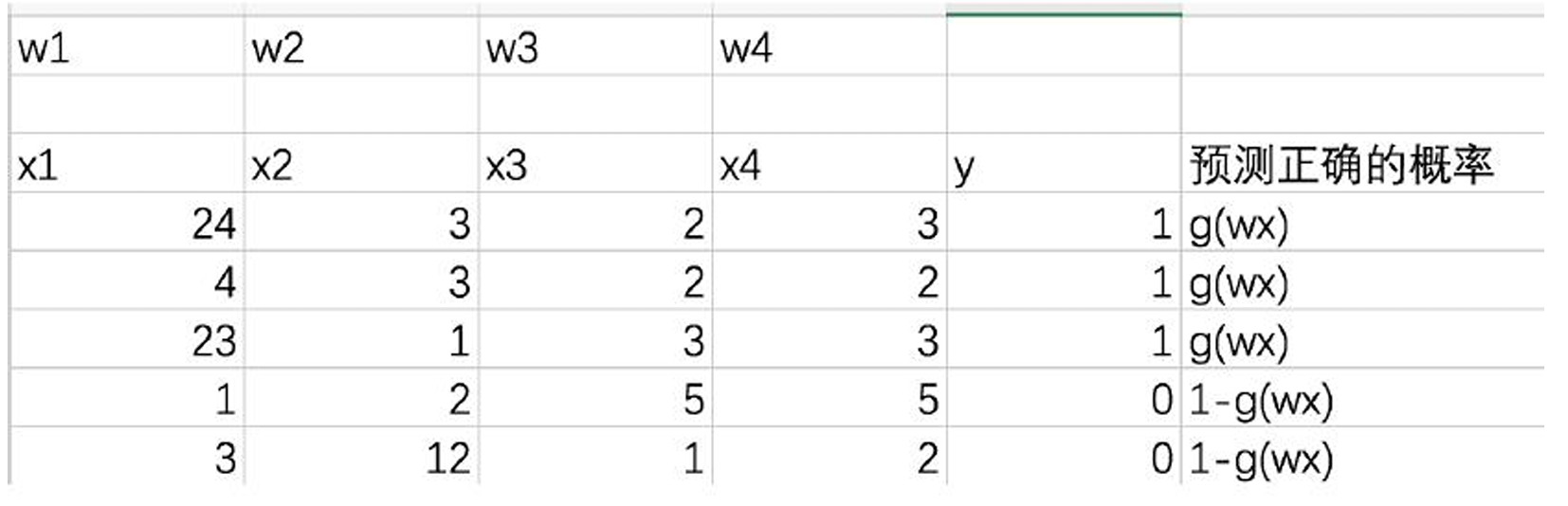
p ( y ∣ x : θ ) = ( h θ ( x ) ) y ( 1 − h θ ( x ) ) 1 − y p(y|x:\theta)=(h_\theta(x))^y(1-h_\theta(x))^{1-y} p(y∣x:θ)=(hθ(x))y(1−hθ(x))1−y
L ( θ ) = p ( y ⃗ ∣ X ; θ ) = ∏ i = 1 m p ( y ( i ) ∣ x ( i ) ; θ ) = ∏ i = 1 m ( h θ ( x ( i ) ) ) y ( i ) ( 1 − h θ ( x ( i ) ) ) 1 − y ( i ) \begin{aligned} L(\theta) &= p(\vec{y}|X;\theta) \\ &= \prod_{i=1}^{m} p(y^{(i)}|x^{(i)};\theta) \\ &= \prod_{i=1}^{m} \left(h_\theta(x^{(i)})\right)^{y^{(i)}} \left(1-h_\theta(x^{(i)})\right)^{1-y^{(i)}} \end{aligned} L(θ)=p(y ∣X;θ)=i=1∏mp(y(i)∣x(i);θ)=i=1∏m(hθ(x(i)))y(i)(1−hθ(x(i)))1−y(i)
-
符号对齐:
- h θ ( x ( i ) ) h_\theta(x^{(i)}) hθ(x(i)) 表示样本 x ( i ) x^{(i)} x(i) 的预测概率 σ ( θ T x ) \sigma(\theta^T x) σ(θTx)
- 指数部分 y ( i ) y^{(i)} y(i) 和 1 − y ( i ) 1-y^{(i)} 1−y(i) 构成伯努利分布的紧凑表达式
-
推导逻辑 :
当 y ( i ) = 1 : h θ ( x ( i ) ) 1 ⋅ ( 1 − h θ ( x ( i ) ) ) 0 = h θ ( x ( i ) ) 当 y ( i ) = 0 : h θ ( x ( i ) ) 0 ⋅ ( 1 − h θ ( x ( i ) ) ) 1 = 1 − h θ ( x ( i ) ) \begin{aligned} \text{当 } y^{(i)}=1 &: \quad h_\theta(x^{(i)})^1 \cdot (1-h_\theta(x^{(i)}))^0 = h_\theta(x^{(i)}) \\ \text{当 } y^{(i)}=0 &: \quad h_\theta(x^{(i)})^0 \cdot (1-h_\theta(x^{(i)}))^1 = 1-h_\theta(x^{(i)}) \end{aligned} 当 y(i)=1当 y(i)=0:hθ(x(i))1⋅(1−hθ(x(i)))0=hθ(x(i)):hθ(x(i))0⋅(1−hθ(x(i)))1=1−hθ(x(i)) -
对数似然转换 :
ℓ ( θ ) = log L ( θ ) = ∑ i = 1 m y ( i ) log h θ ( x ( i ) ) + ( 1 − y ( i ) ) log ( 1 − h θ ( x ( i ) ) ) \begin{aligned} \ell(\theta) &= \log L(\theta) \\ &= \sum_{i=1}^m \left y\^{(i)}\\log h_\\theta(x\^{(i)}) + (1-y\^{(i)})\\log(1-h_\\theta(x\^{(i)})) \\right \end{aligned} ℓ(θ)=logL(θ)=i=1∑my(i)loghθ(x(i))+(1−y(i))log(1−hθ(x(i))) -
最终形式:损失函数,往往是求最小,可以用梯度下降来求解。最终损失函数就是上面公式加负号的形式:
ℓ ( θ ) = − ∑ i = 1 m y ( i ) log h θ ( x ( i ) ) + ( 1 − y ( i ) ) log ( 1 − h θ ( x ( i ) ) ) \begin{aligned} \ell(\theta) &=- \sum_{i=1}^m \left y\^{(i)}\\log h_\\theta(x\^{(i)}) + (1-y\^{(i)})\\log(1-h_\\theta(x\^{(i)})) \\right \end{aligned} ℓ(θ)=−i=1∑my(i)loghθ(x(i))+(1−y(i))log(1−hθ(x(i)))
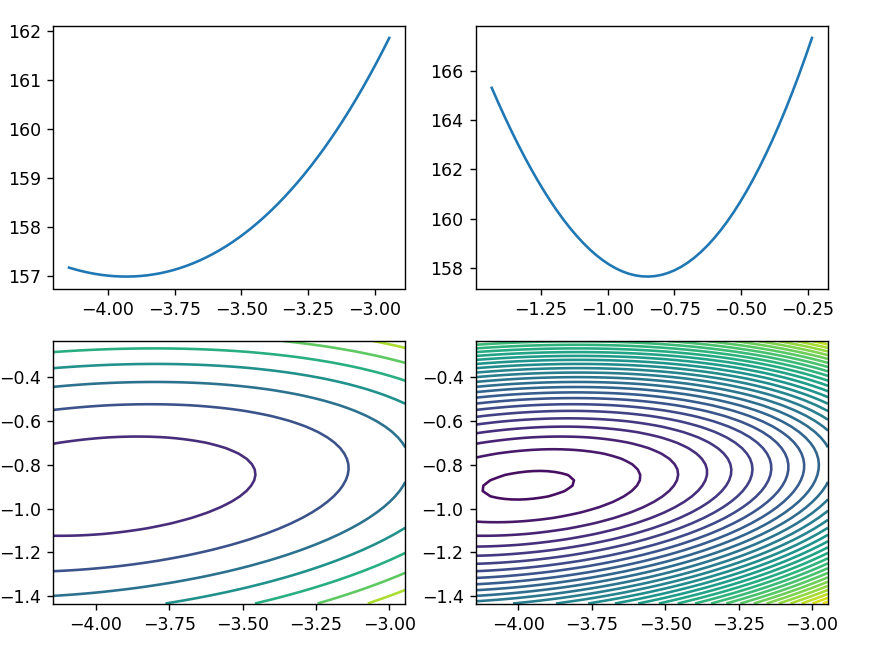
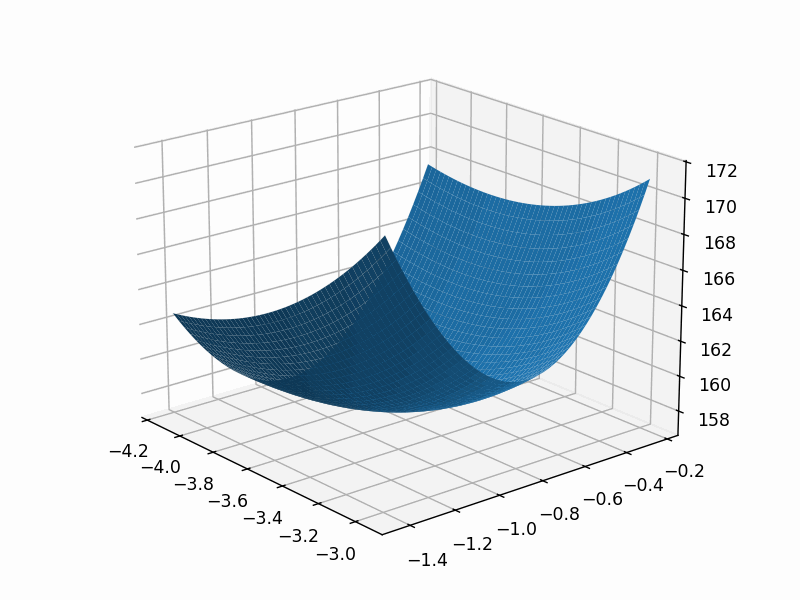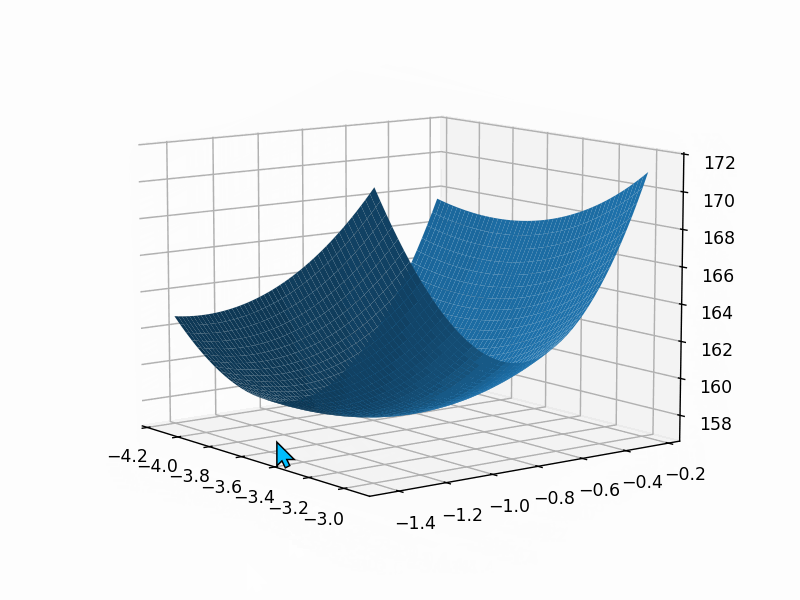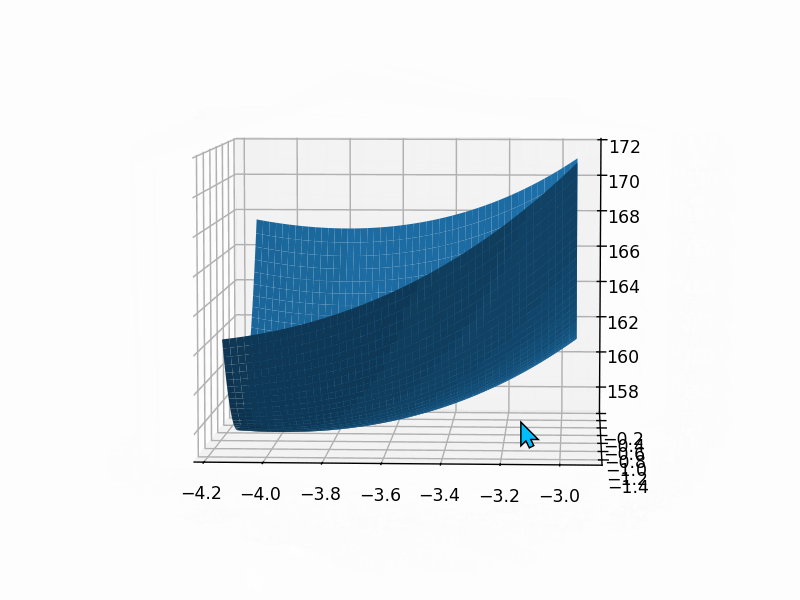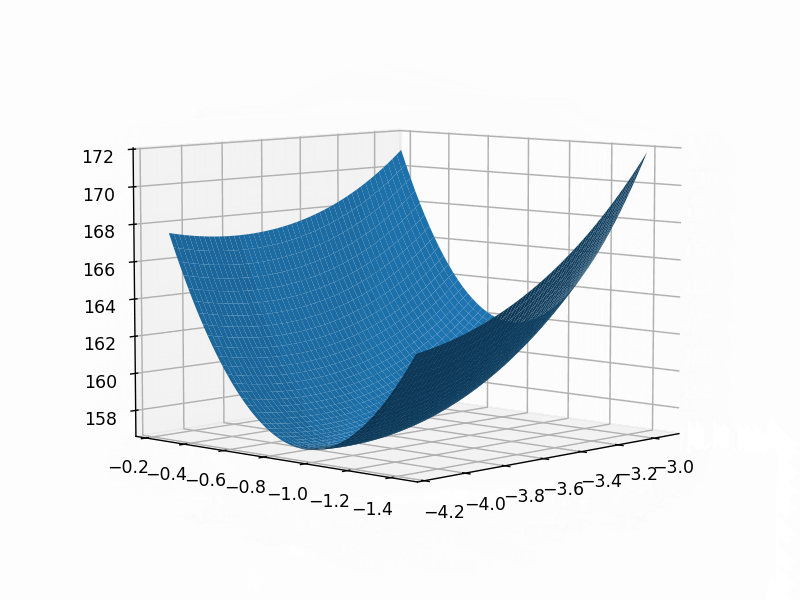
绘制损失函数
python
from sklearn.datasets import load_breast_cancer
from sklearn.linear_model import LogisticRegression
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
from sklearn.preprocessing import scale
# 加载数据集并进行归一化处理
data = load_breast_cancer()
# 提取数据集中前两个特征作为x,并将目标值作为y
x, y = scale(data['data'][:, :2]), data['target']
# 使用逻辑回归算法求解两个特征对应的最优参数
# 设置fit_intercept=False,因为逻辑回归模型本身已经包含了截距项,无需额外计算
lr = LogisticRegression(fit_intercept=False)
lr.fit(x, y)
# 提取逻辑回归模型中两个特征对应的权重参数W1和W2
theta1 = lr.coef_[0, 0]
theta2 = lr.coef_[0, 1]
# 打印提取的权重参数W1和W2
print(theta1, theta2)
# 定义函数p_theta_function,用于计算给定特征和权重时的预测概率
def p_theta_function(features, w1, w2):
# 计算线性组合z = w1 * x1 + w2 * x2
z = w1 * features[0] + w2 * features[1]
# 使用sigmoid函数将z转换为概率值
return 1 / (1 + np.exp(-z))
# 定义函数loss_function,用于计算给定权重W1和W2时的数据集损失
def loss_function(samples_features, samples_labels, w1, w2):
result = 0
# 遍历数据集中的每个样本,计算总体损失
for features, label in zip(samples_features, samples_labels):
# 调用p_theta_function计算当前样本的预测概率
p_result = p_theta_function(features, w1, w2)
# 根据交叉熵损失公式计算当前样本的损失
loss_result = -1 * label * np.log(p_result) - (1 - label) * np.log(1 - p_result)
result += loss_result
# 返回结果(此处代码存在逻辑问题,应在遍历结束后统一返回)
return result
# 创建运维数组,平均取值50个点
theta1_space = np.linspace(theta1 - 0.6, theta1 + 0.6, 50)
theta2_space = np.linspace(theta2 - 0.6, theta2 + 0.6, 50)
# 计算在不同theta1和theta2下的损失函数值
result1_ = np.array([loss_function(x, y, i, theta2) for i in theta1_space])
result2_ = np.array([loss_function(x, y, theta1, i) for i in theta2_space])
# 创建一个新的图形对象
fig1 = plt.figure(figsize=(8, 6))
# 添加第一个子图,展示theta1变化时的损失函数值
plt.subplot(2, 2, 1)
plt.plot(theta1_space, result1_)
# 添加第二个子图,展示theta2变化时的损失函数值
plt.subplot(2, 2, 2)
plt.plot(theta2_space, result2_)
# 添加第三个子图,使用等高线图展示theta1和theta2的损失函数值
plt.subplot(2, 2, 3)
theta1_grid, theta2_grid = np.meshgrid(theta1_space, theta2_space)
loss_grid = loss_function(x, y, theta1_grid, theta2_grid)
plt.contour(theta1_grid, theta2_grid, loss_grid)
# 添加第四个子图,使用更多等高线展示损失函数值的分布
plt.subplot(2, 2, 4)
plt.contour(theta1_grid, theta2_grid, loss_grid, 30)
# 创建第二个图形对象,用于展示损失函数值的三维表面图
fig2 = plt.figure()
# ax = Axes3D(fig2)
ax=fig2.add_axes(Axes3D(fig2))
ax.plot_surface(theta1_grid, theta2_grid, loss_grid)
plt.show()