etcd 数据库由 CoreOS 公司创建。
https://github.com/etcd-io/etcd
api信息https://etcd.io/docs/v3.5/dev-guide/api_reference_v3/
etcdctl --help
etcd 最初由 CoreOS 公司开发,作为其核心项目之一。
CoreOS 成立于 2013 年,专注于容器化技术(如 Linux 容器、rkt 容器运行时)和分布式系统基础设施。
2018 年,CoreOS 被 Red Hat 收购(后 Red Hat 又并入 IBM)
轻量级、高可用的键值存储,用于存储分布式系统的关键元数据(如服务发现、配置管理)。
具有强一致性、高可靠性和易用性。
ETCD 是一个高可用的分布式键值key-value数据库,可用于服务发现。
etcd 存储了 K8s 集群的所有状态(如 Pod 定义、Service 配置、节点信息),是控制平面的"大脑"。
基于 Raft 共识算法,提供强一致性、高可用性,支持 watch 机制实现实时数据同步。
K8S API 服务器接收到请求后,会验证请求格式和内容。通过验证的请求会被存储到 etcd(Kubernetes 的分布式数据库)中。
对象创建:一旦存储在 etcd 中,Pod 就被正式创建,标记为 Pending 状态。
Raft 算法
https://www.youtube.com/watch?v=YbZ3zDzDnrw\&feature=youtu.be
角色
Leader选举(Leader election)
日志复制(Log replication)
安全性(Safety)
日志压缩(Log compaction)
Raft将系统中的角色分为领导者(Leader)、跟从者(Follower)和候选者(Candidate)
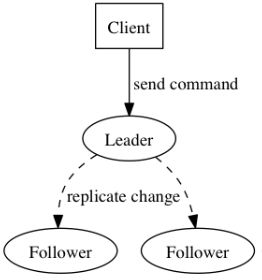
Leader:接受客户端请求,并向Follower同步请求日志,当日志同步到大多数节点上后告诉Follower提交日志。
Follower:接受并持久化Leader同步的日志,在Leader告之日志可以提交之后,提交日志。
Candidate:Leader选举过程中的临时角色。
Raft 任意时刻最多只有一个Leader,正常工作期间只有Leader和Followers。
Raft算法将时间分为一个个的周期(term)
选举Leader之后,Leader会在整个周期内管理整个集群
如果Leader选举失败,该term就会因为没有Leader而结束。
没有服务器赢得多数的选票,Leader选举失败,等待选举时间超时后发起下一次选举。
leader会定期发送心跳,根据唯一Term标识进行通信
选举超时随机化:节点在超时时间内未收到leader心跳会发起选举,但超时时间随机化(如150ms-300ms),确保大多数情况下只有一个节点率先发起选举。
Follower将其当前term加一然后转换为Candidate。它首先给自己投票并且给集群中的其他服务器发送 RequestVote RPC。
当旧leader恢复时,它会发现当前Term已超过自己的Term,立即切换为Follower状态,并接受新leader的日志。如果旧leader在失联期间提交了部分日志,新leader会通过日志复制机制(AppendEntries RPC)强制旧leader回退冲突日志,确保全局一致性。
日志冲突处理:如果旧leader在失联期间提交了部分日志,新leader会通过日志复制机制(AppendEntries RPC)强制旧leader回退冲突日志,确保全局一致性。
Raft要求leader必须获得超过半数的节点确认(quorum)才能提交日志。即使网络分区导致部分节点隔离,只有拥有多数节点的分区能选举新leader,另一分区无法形成有效选举。
Raft保证新leader一定包含所有已提交的日志(通过RequestVote阶段的日志完整性检查),避免日志分叉。
如果leader突然崩溃导致缺少了一条followers的条目,则Leader为了使Followers的日志同自己的一致,Leader需要找到Followers同它的日志一致的地方,然后覆盖Followers在该位置之后的条目。当 leader 和 follower 日志冲突的时候,leader 将校验 follower 最后一条日志是否和 leader 匹配,如果不匹配,将递减查询,直到匹配,匹配后,删除冲突的日志。这样就实现了主从日志的一致性。
Leader会通过RPC向follower发出日志复制,等待所有的follower复制完成,这个过程是阻塞的。
老的leader里面没提交的数据会回滚,然后同步新leader的数据。
持久化
etcd 通过 WAL + Snapshot 的组合
日志会定期压缩,带有快照功能
Leader 节点会保留所有未提交的日志条目,但已提交的日志会在以下条件触发压缩
已接收10000条日志条目,或者超过5分钟
日志保留策略:快照生成后,所有早于该快照的日志会被标记为可删除。
每个节点上的kubelet定期向API Server上报节点状态(如CPU、内存、磁盘使用情况),API Server将这些信息写入etcd。
当创建Pod时,API Server将Pod的元数据(如名称、标签、容器镜像等)写入etcd。
调度器从etcd读取节点状态和Pod元数据,基于算法(如资源匹配、亲和性规则)选择最佳节点,并将调度结果写回etcd。
etcd使用Raft算法保证强一致性,确保所有节点看到的数据视图一致。这对调度器的决策至关重要,避免"裂脑"问题。
etcd通过多版本控制系统(MVCC)保存键值的所有历史变更
默认保留最近1000个版本,旧版本会被合并到历史文件。
MVCC版本号递增:每次修改操作(如 PUT、DELETE)均触发全局版本号加1,支持数据追溯和并发控制。
启动参数作用:
建议通过 etcdctl endpoint status 或监控工具(如 Prometheus)观察版本号和存储使用情况,结合业务需求调整参数配置。
空间问题
--auto-compaction-retention
作用:设置自动压缩(Auto-Compaction)的保留策略,控制旧版本数据的保留时间。
原理:ETCD会定期清理低于指定保留时间的旧版本数据,释放存储空间。
配置示例:
--auto-compaction-retention=1h:保留最近1小时内的数据,自动压缩更早的版本。
若未配置此参数,默认禁用自动压缩(需手动执行 compact 命令)。
--auto-compaction-mode:定义压缩模式,可选 periodic(基于时间)或 revision(基于版本号)。
示例:--auto-compaction-mode=periodic --auto-compaction-retention=5m 表示每5分钟压缩一次旧数据。
--quota-backend-bytes作用:设置后端存储(Backend Storage)的配额,限制数据库的最大大小。
原理:当数据库大小超过配额时,ETCD会触发警报或自动压缩操作。
配置示例:
--quota-backend-bytes=8589934592:限制数据库大小为8GB(默认值通常为2GB)。
若未配置此参数,使用默认配额(可能因版本不同而有所差异)。
RPC
Raft 算法中服务器节点之间通信使用远程过程调用(RPC)
RequestVote RPC:候选人在选举期间发起。
AppendEntries RPC:领导人发起的一种心跳机制,复制日志也在该命令中完成。
InstallSnapshot RPC: 领导者使用该RPC来发送快照给太落后的追随者。
外部etcd关联
在 kubeadm 配置中指定外部 etcd
kubeadm init --config kubeadm-config.yaml
bash
# kubeadm-config.yaml
apiVersion: kubeadm.k8s.io/v1beta3
kind: InitConfiguration
etcd:
external:
endpoints:
- https://etcd-node1:2379
- https://etcd-node2:2379
- https://etcd-node3:2379
caFile: /etc/ssl/etcd/ca.crt
certFile: /etc/ssl/etcd/client.crt
keyFile: /etc/ssl/etcd/client.key静态pod
bash
# etcd-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: etcd
namespace: kube-system
spec:
containers:
- name: etcd
image: quay.io/coreos/etcd:v3.5.9
command:
- etcd
- --advertise-client-urls=http://0.0.0.0:2379
- --listen-client-urls=http://0.0.0.0:2379
hostNetwork: true
volumes:
- name: etcd-data
hostPath:
path: /var/lib/etcd
bash
kubectl apply -f etcd-pod.yaml网络相关
Calico Source Code