支持向量机-python实现
由于本菜鸟目前还没有学习到软间隔和核函数的处理,so,先分享的硬间隔不带核函数,也就是不涉及非线性可分转化成线性可分的逻辑,后续如果学的懂,就在本篇文章的代码中继续拓展核函数等。
先来看看支持向量机的概念和解决的问题
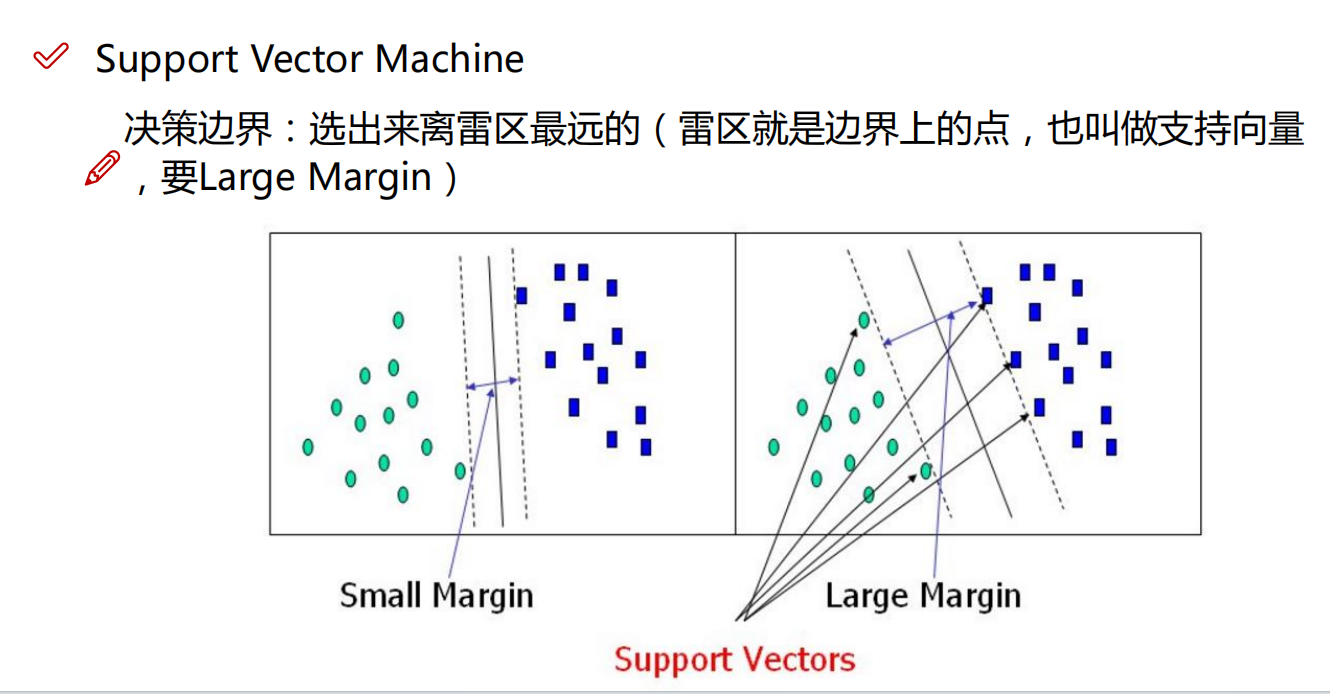






咱们来举个例子
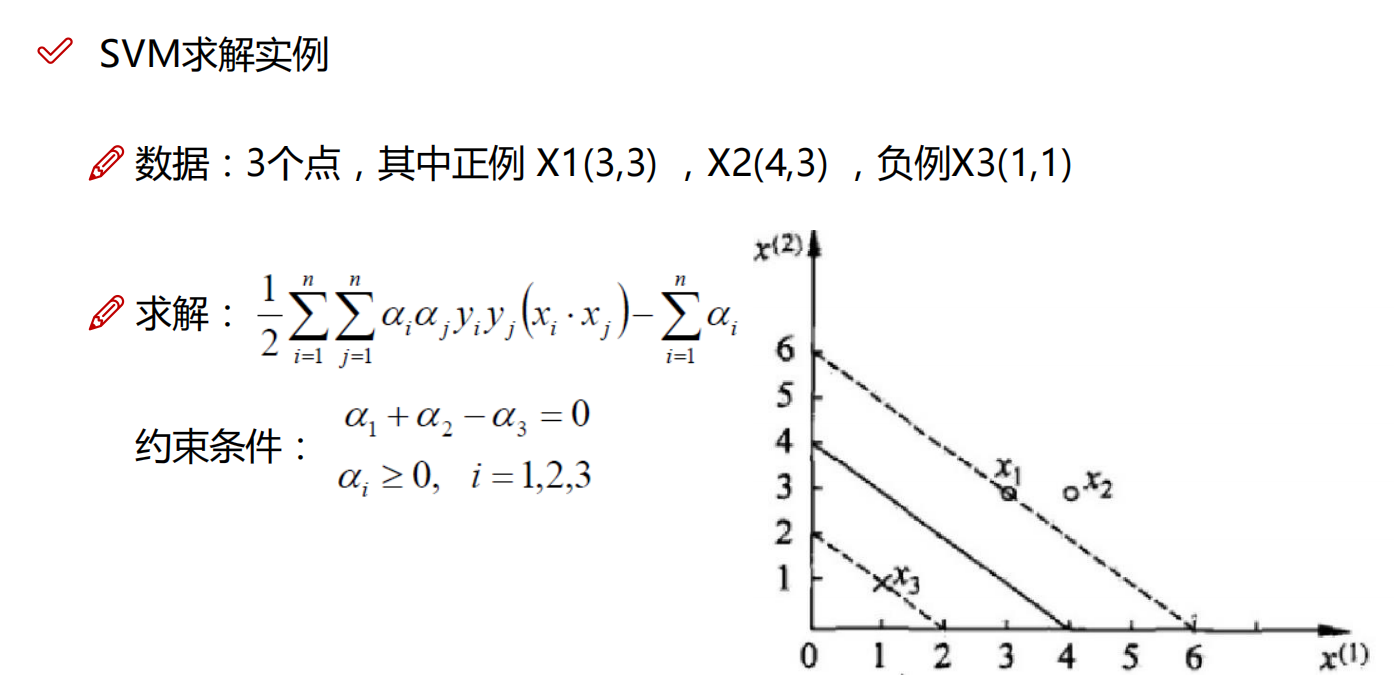
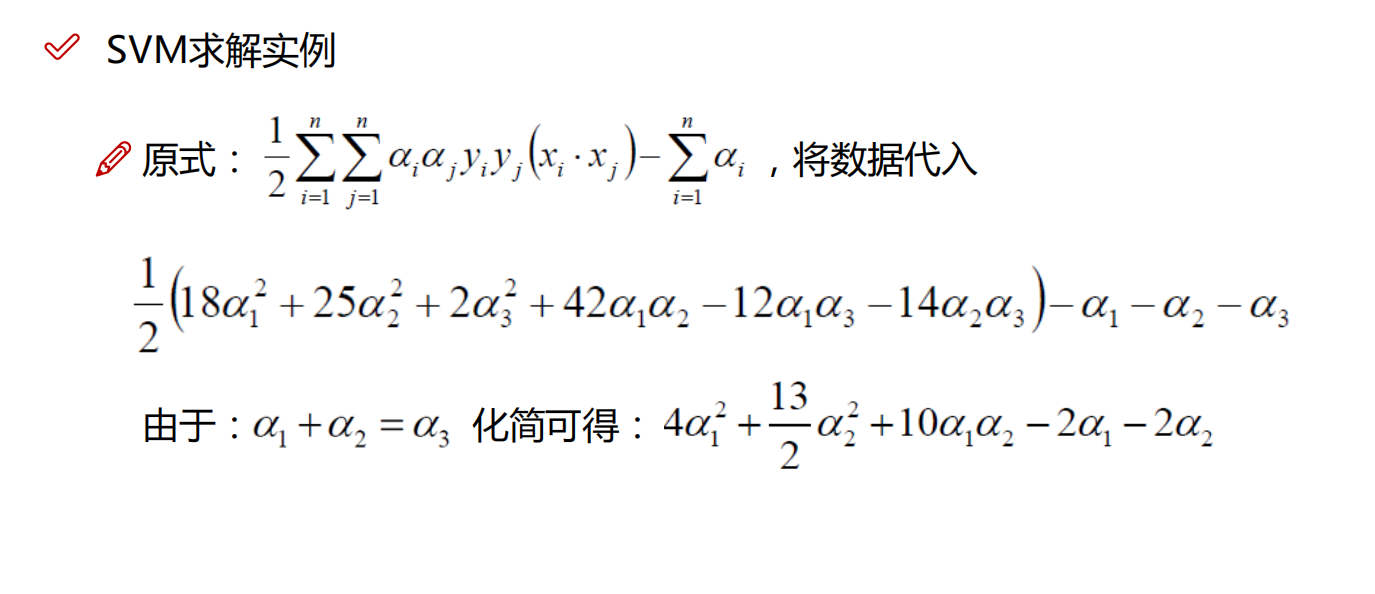

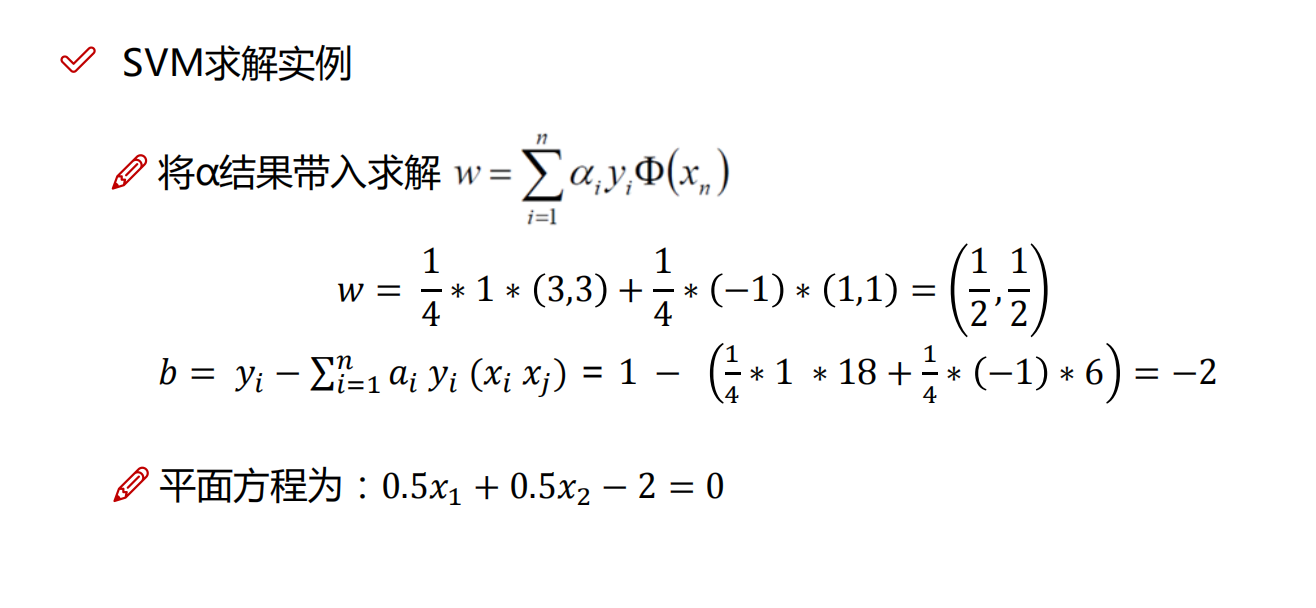
上代码了
python
# 用于函数求导的
import sympy as sp
import numpy as np
# 硬间隔不带核函数支持向量机
class SVM:
# learn_rate:学习率
# lambda_rate: 转移率
# descend_times: 梯度下降次数
# w:超平面所有纬度的斜率(是个向量)
# b:常数
# train_x: 测试输入数据
# train_y:测试输出数据
# labels: 属性类别
def __init__(self, learn_rate=0.01, lambda_rate=0.01, descend_times=1000):
self.learn_rate = learn_rate
self.lambda_rate = lambda_rate
self.descend_times = descend_times
self.w = None
self.b = None
self.train_x = []
self.train_y = []
self.labels = []
# 类别映射
def type_mapping(self, Y):
return np.array([(1 if item == Y[0] or item == 1 else -1) for item in Y])
# 对于最后一个an变量,可用a0-an-1化简
def getParamsA(self, symbols, Y, size, i):
if i < size - 1:
return symbols[i]
else:
res = 0.0
for index in range(size - 1):
res += (symbols[index] * Y[index])
return -1.0 * Y[i] * res
# 拉格朗日乘数法求解
def lagrange_mutiply(self, X, Y):
Y, size = self.type_mapping(Y), len(X)
params_symbol = np.array([None] * size)
for i in range(size):
params_symbol[i] = sp.symbols('a' + str(i))
L = 0.0
for i in range(size):
for j in range(size):
L += (self.getParamsA(params_symbol, Y, size, i)
* self.getParamsA(params_symbol, Y, size, j)
* Y[i] * Y[j]
* np.dot(X[i], X[j]))
L = sp.simplify(0.5 * L - sum(params_symbol[:size - 1]) - self.getParamsA(params_symbol, Y, size, size - 1))
res_symbol, res_var = [], []
for i in range(size - 1):
res_symbol.append(sp.diff(L, params_symbol[i]))
res_var.append(params_symbol[i])
diff_solve = sp.solve(res_symbol, res_var)
res_last_value = 0.0
for i in range(size - 1):
res_last_value += (diff_solve[params_symbol[i]] * Y[i])
diff_solve[params_symbol[size - 1]] = -1 * Y[size - 1] * res_last_value
# 向量中不包含负数
w, b = np.zeros(len(X[0])), 0
if len([item for item in list(diff_solve.values()) if item < 0]) == 0:
for k_i, key in enumerate(params_symbol):
w += (diff_solve[key] * Y[k_i] * X[k_i])
b = np.dot(w, X[0]) - Y[0]
else: # 向量中包含负数,采取随机梯度下降算法求解w和b
for t in range(self.descend_times):
for idx, x_i in enumerate(X):
condition = Y[idx] * (np.dot(x_i, w) - b) >= 1
if condition:
w -= self.learn_rate * (2 * self.lambda_rate * w)
else:
w -= self.learn_rate * (2 * self.lambda_rate * w - np.dot(x_i, Y[idx]))
b -= self.learn_rate * Y[idx]
return w, b
# 数据处理
def fit(self, X, Y, Labels):
X, Y = np.array(X), np.array(Y)
self.train_x, self.train_y, self.labels = X, Y, Labels
self.w, self.b = self.lagrange_mutiply(X, Y)
# 分类判断
def predict(self, X):
t = 1 if np.dot(self.w, np.array(X)) - self.b > 0 else -1
y_ = list(self.type_mapping(self.train_y)).index(t)
return self.train_y[y_]
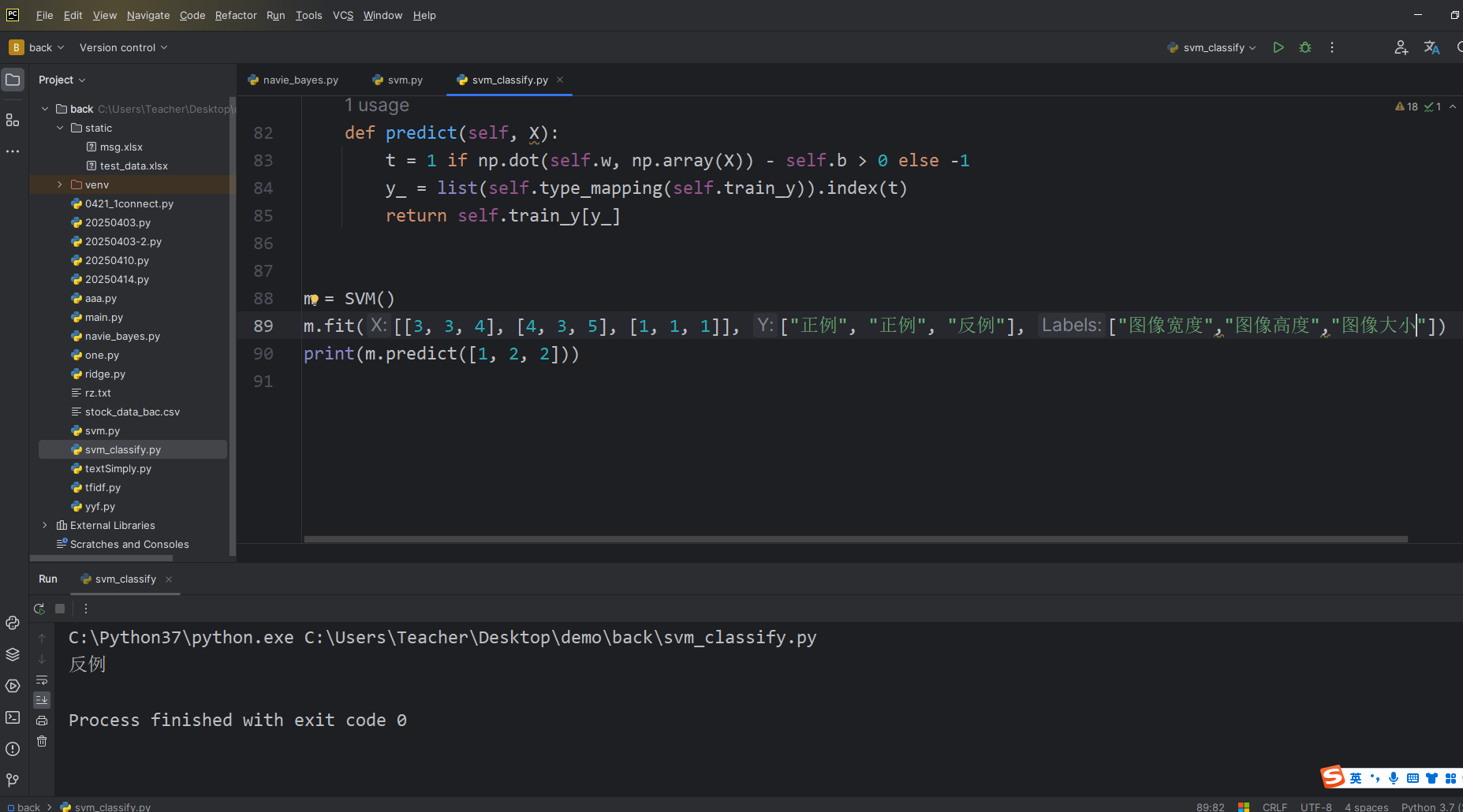
m = SVM()
m.fit([[3, 3, 4], [4, 3, 5], [1, 1, 1]], ["正例", "正例", "反例"], ["图像宽度","图像高度","图像大小"])
print(m.predict([1, 2, 2]))分类结果打印
我们来看看效果