1.为什么需要消息队列
举个经典的例子。
你是一个网购达人,经常在网上购物。快递小哥到了你的小区后,立刻给你打电话说:"你的快递到了,请马上来取。"
但你是一个合格的牛马,在上班,不方便取快递,只能等下班才能取快递。那快递小哥总不能一直傻等着你下班吧,他还有很多其他人的快递要送。不管是你请假拿快递,还是小哥干等着你来取快递,这都会影响效率。
因此,快递柜、快递站应用而生,他的身份就是消息队列。 它充当了一个缓冲区的角色,快递小哥按照自己的时间安排送快递,我们按照自己的时间安排取快递,如此一来,就解决了快递员和你之间的时间差 和沟通效率问题。
总结一下,消息中间件出现带来的好处:
1、 解耦
快递小哥手上有很多快递需要送,他每次都需要先电话一一确认收货人是否有空、哪个时间段有空,然后再确定好送货的方案。这样完全依赖收货人了!如果快递一多,快递小哥估计的忙疯了......如果有了快递站,快递小哥只需要将同一个小区的快递放在同一个快递站,然后通知收货人来取货就可以了,这时候快递小哥和收货人就实现了解耦!
2、 异步
快递小哥打电话给我后需要一直在你楼下等着,直到我拿走你的快递他才能去送其他人的。快递小哥将快递放在快递站后,又可以干其他的活儿去了,不需要等待你到来而一直处于等待状态。提高了工作的效率。
3、 削峰
假设双十一我买了不同店里的各种商品,而恰巧这些店发货的快递都不一样,有中通、圆通、申通、各种通等......更巧的是他们都同时到货了!中通的小哥打来电话叫我去北门取快递、圆通小哥叫我去南门、申通小哥叫我去东门。我一时手忙脚乱......此时,一个菜鸟驿站就解决了这些问题。
2.什么是kafka,应用场景
kafka是基于发布/订阅的分布式消息系统。具有消息持久化速度快、高吞吐、高容错、易扩展的特点。
kafka的作用和好处是:解耦、异步、削峰。
Kafka的主要应用场景有:
- 消息队列:用作高吞吐量的消息系统,将消息从一个系统传递到另一个系统。
- 日志收集:集中收集日志数据,然后通过Kafka传递到实时监控系统或存储系统。
- 流计算:处理实时数据流,将数据传递给实时计算系统,如Apache Storm或Apache Flink。
- 事件溯源:记录事件发生的历史,以便稍后进行数据回溯或重新处理。
3.kafka的集群架构
推荐视频:详细原理_哔哩哔哩_bilibili
3.1架构图
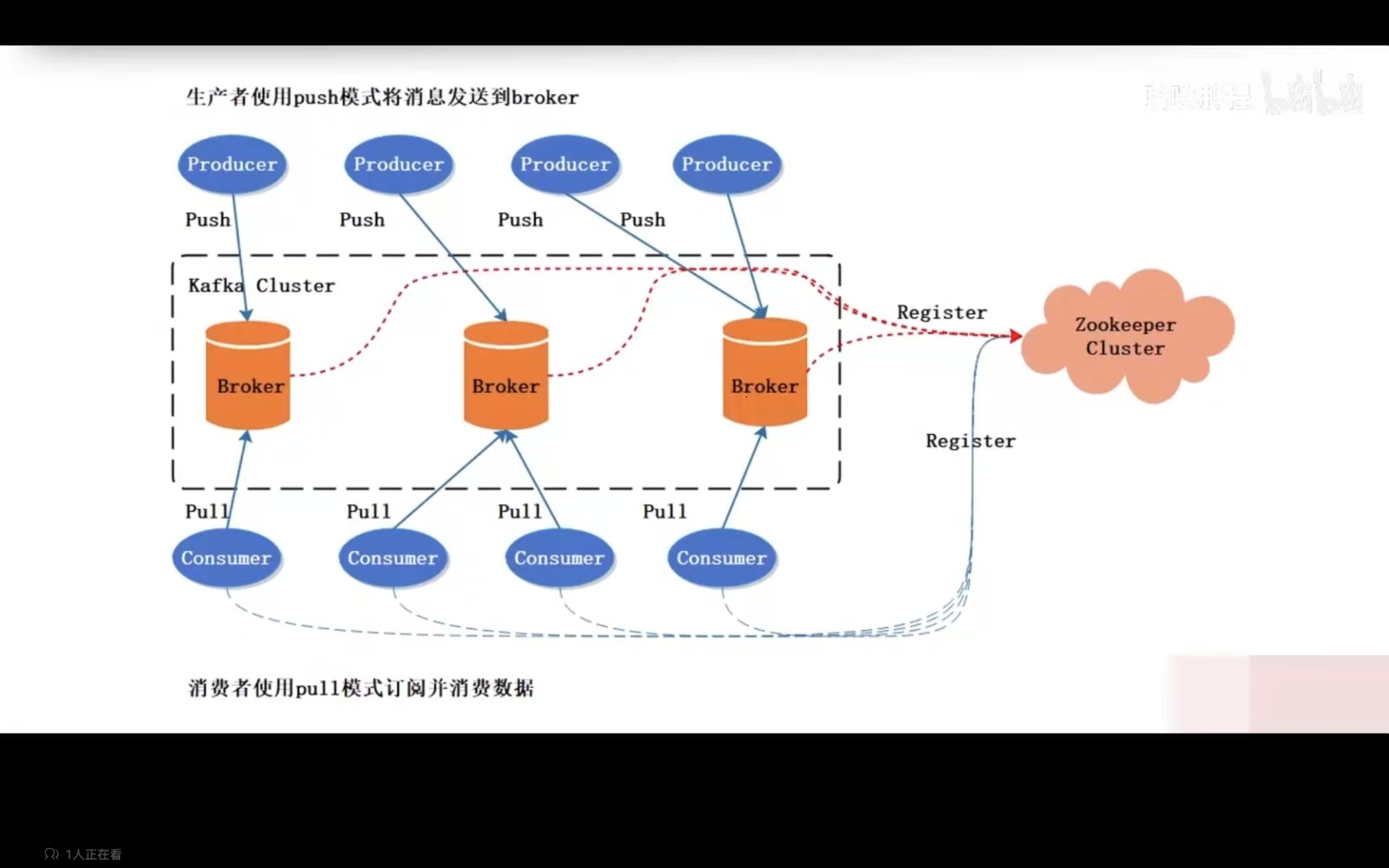
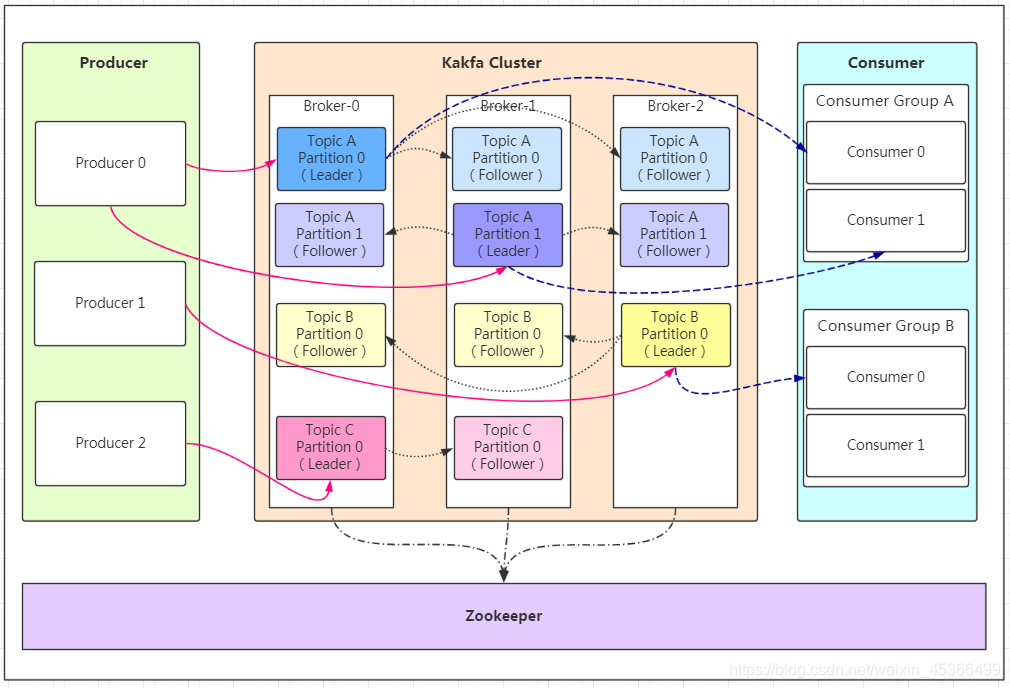
3.2.kafka基本架构包括的组件及作用
Kafka 的基本架构主要包括四个组件:Producer(生产者)、Consumer(消费者)、Broker(消息代理)和 Zookeeper(协调器)。
- Producer(生产者):负责将数据发布到 Kafka 的特定 Topic 上。它会根据要求将数据以不同的分区策略分布到各个分区里。
- Consumer(消费者):从 Kafka 的 Topic 中读取数据。消费者可以属于某个消费组(Consumer Group),这样可以让多个消费者平衡负载读取数据。
- Broker(消息代理):是 Kafka 的核心。Kafka 集群由一个或多个服务器组成,每个服务器被称为 Broker。Broker 负责接收消息、记录消息、响应消费者请求等。
- Zookeeper(协调器):用于 Kafka 的分布式协调和管理任务,比如存储 Broker 的元数据信息、管理集群成员关系、主题配置、选举 Leader。Zookeeper 确保 Kafka 集群的高可用性和一致性。
其他名词解释:
- Topic:Topic 是特定类型的消息流。Kafka 中的消息被归类为不同的主题,生产者将数据发送到特定的主题,消费者从特定的主题读取数据。
- Partition:每个 Topic 可以分成多个 Partition(分区),以便于扩展和提高并行处理能力。每个 Partition 都是一个有序的、不可变的消息序列,并且可以持续地添加消息。
- Leader and Follower:在 Partition 的副本中,有一个副本是 Leader,其他副本则是 Followers。Leader 副本负责处理所有针对该 Partition 的读写请求,Follower 副本会同步 Leader 的数据作为备份。
- **Replication:**每一个分区都有多个副本,副本的作用是做备胎。当主分区(Leader)故障的时候会选择一个备胎(Follower)上位,成为Leader。在kafka中默认副本的最大数量是10个,且副本的数量不能大于Broker的数量,follower和leader绝对是在不同的机器,同一机器对同一个分区也只可能存放一个副本(包括自己)。
- Offset:Offset 是 Partition 中每条消息的唯一标识符,它是一个单调递增的整数。消费者通过 Offset 来追踪其消费进度。
- Consumer Group:一组 Consumers 可以组成一个 Consumer Group,用于共同消费同一个 Topic 下的消息。Kafka 确保每条消息只会被同一个 Consumer Group 中的一个 Consumer 处理。