Qwen3 已于4月29日早上发布,如何在 ZStack AIOS 上立刻体验最新的 Qwen3 模型?

由于 Qwen3 模型的支持需要较新的推理框架(vllm、sglang、llama.cpp 等底层框架),本篇文章将先向大家介绍如何一步步升级推理模板,平台的管理员或者 AI 开发者在完成推理模板升级后可以共享给平台所有用户,所有用户即可无需配置立即体验最新的 Qwen3 模型。
通过 ZStack AIOS 平台,企业可以像本文所示,迅速部署和体验像 Qwen3 这样的最新 AI 模型 ,并将其无缝赋能给各个业务部门。这种便捷的模型部署与管理机制充分体现了 ZStack AIOS 的灵活性和产品成熟度,使得从 AI 研发到业务应用的路径显著缩短。平台的统一化管理特性确保了 IT 管理人员可以高效地控制资源分配,同时让业务部门能够根据实际需求自主访问和使用 AI 能力,进而加速企业数字化转型,助力业务创新与 AI 应用场景的高效探索和落地实践。无论是产品研发、客户服务还是内部流程优化,ZStack AIOS 都能为企业提供强有力的技术支撑。
准备环节
创建推理模板
首先进入到 ZStack AIOS 模型平台,克隆一个系统自带 SGlang 的推理模板
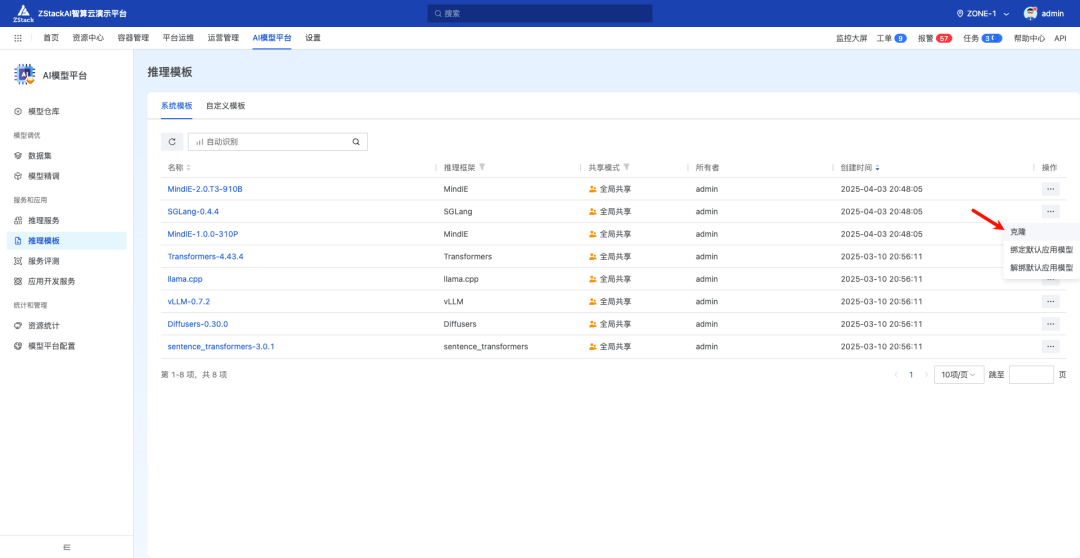
由于最新的 SGLang 版本为0.4.6.post1,因此我们将推理模板名称设置为 SGLang-0.4.6.post1,实例配置选择 "云主机"
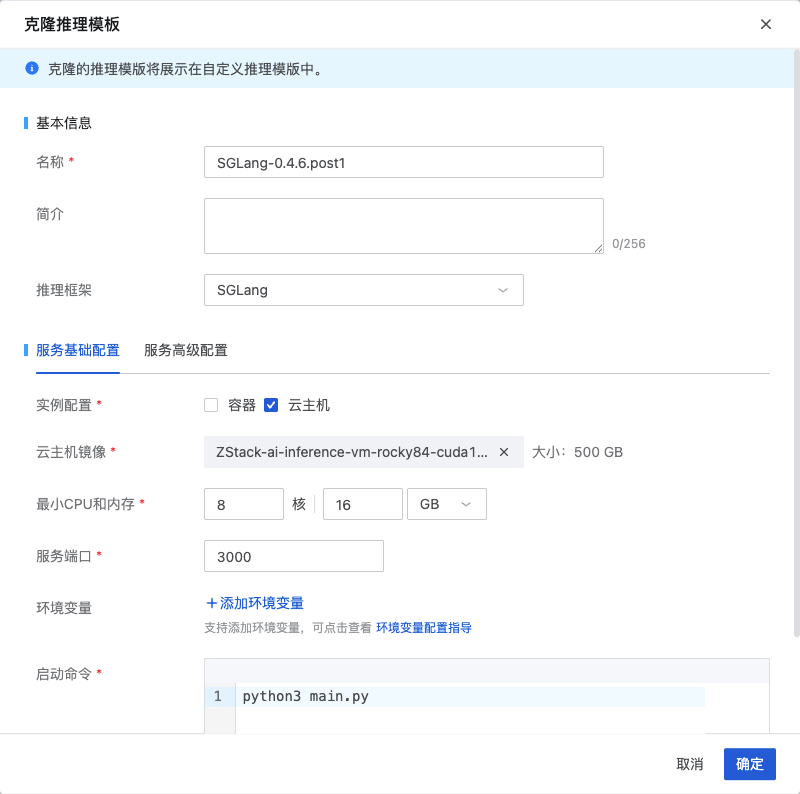
配置推理镜像
下面使用一个 Qwen2.5 模型来配置这个推理模板,例如 Qwen2-0.5B 或平台内置的 Qwen2-7B 均可,主要是验证新版本 SGLang 的可用性。创建推理服务的时候推理模板选择 SGLang-0.4.6.post1:
启动后进入 jupyter notebook,选择 terminal,执行以下命令升级 sglang 和配套依赖:
pip install sglang[all]==0.4.6.post1 -U
wget https://bj20013.api.aliyunfile.com/v2/redirect\?id\=9b8b2fa73e484893a5f567e6be22c1921745913012094149418 -O flashinfer_python-0.2.3+cu124torch2.6-cp38-abi3-linux_x86_64.whl
pip install flashinfer_python-0.2.3+cu124torch2.6-cp38-abi3-linux_x86_64.whl
dnf -y install gcc-toolset-9-gcc gcc-toolset-9-gcc-c++
echo -e "\nsource /opt/rh/gcc-toolset-9/enable" >> /etc/profile; systemctl restart zstack_ai.service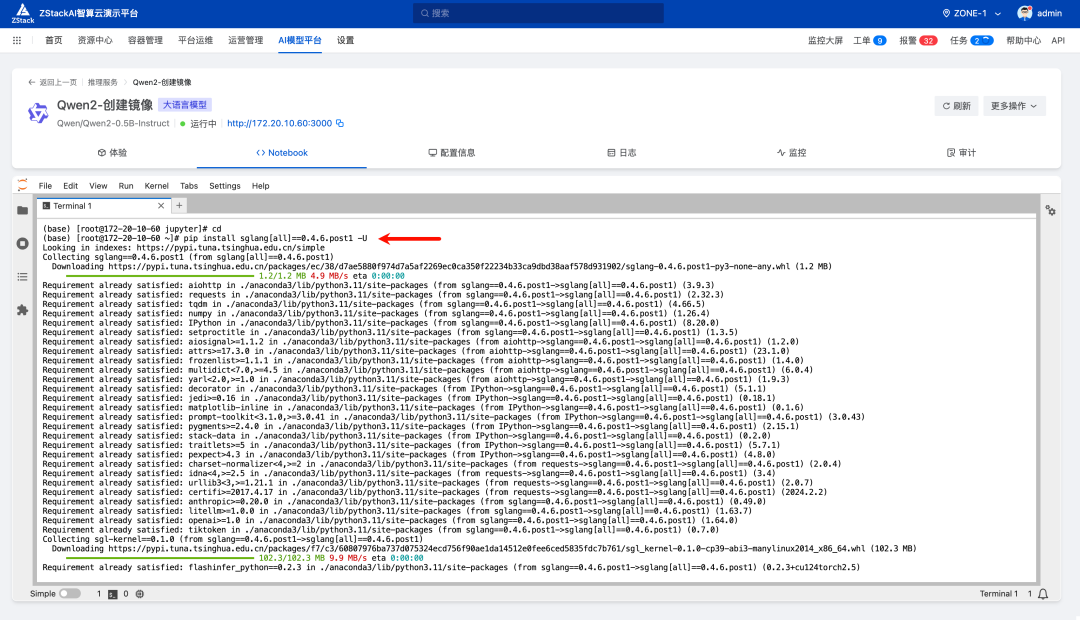
执行完systemctl restart zstack_ai.service之后模型服务会显示启动中,是正常的
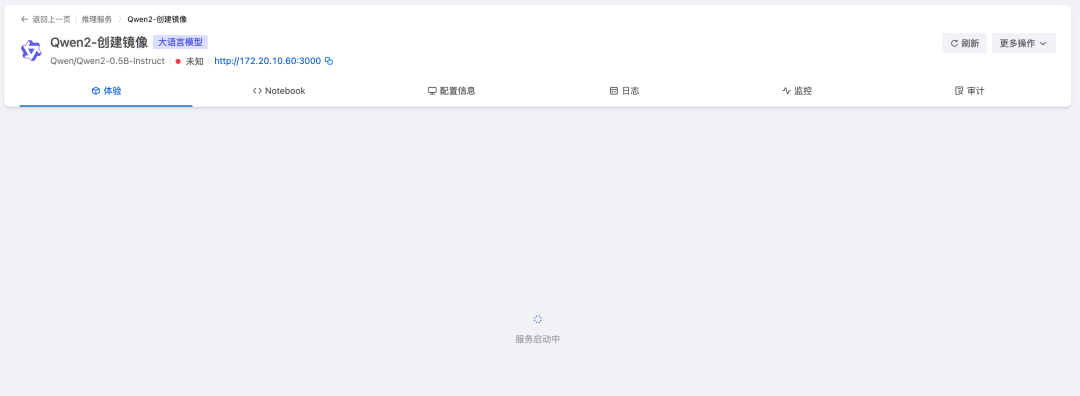
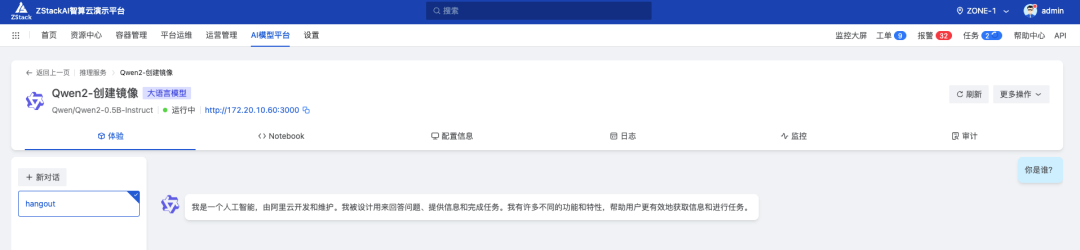
稍等片刻后即可检查模型输出是否正常:
下面我们进入模型服务的"配置信息"页面,找到这个实例,创建一个实例镜像:
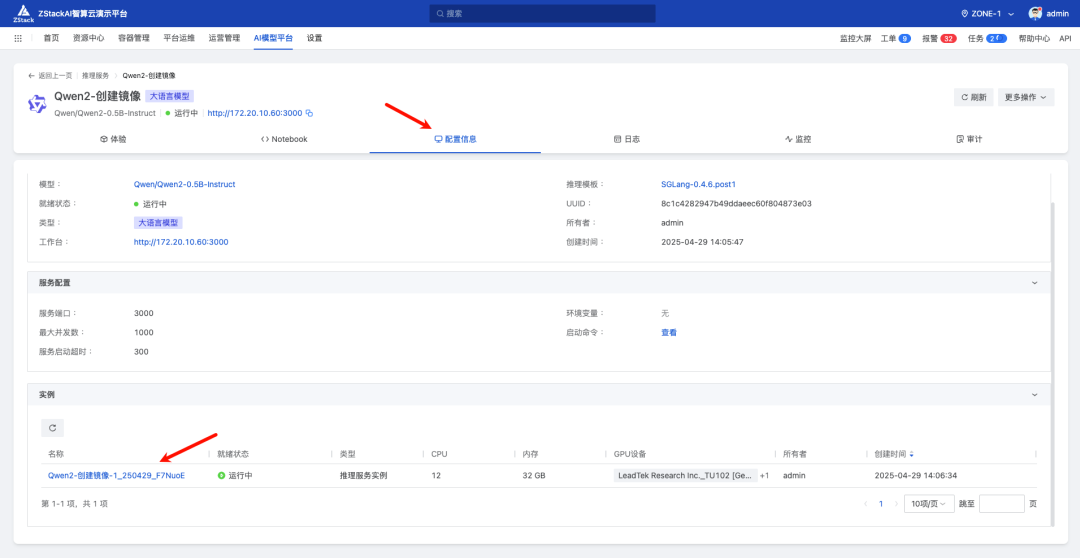
将云主机停止,点击创建镜像,命名为 SGLang-0.4.6.post1-image
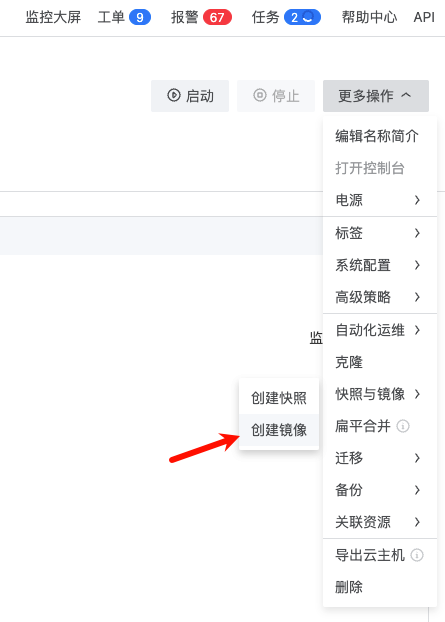
然后编辑前面创建的推理模板,将推理模板所关联的云主机镜像改为刚刚封装的这个 SGLang-0.4.6.post1-image
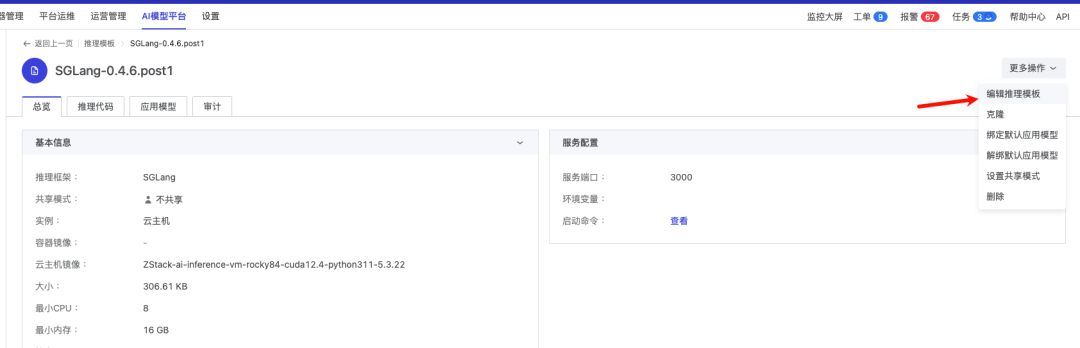
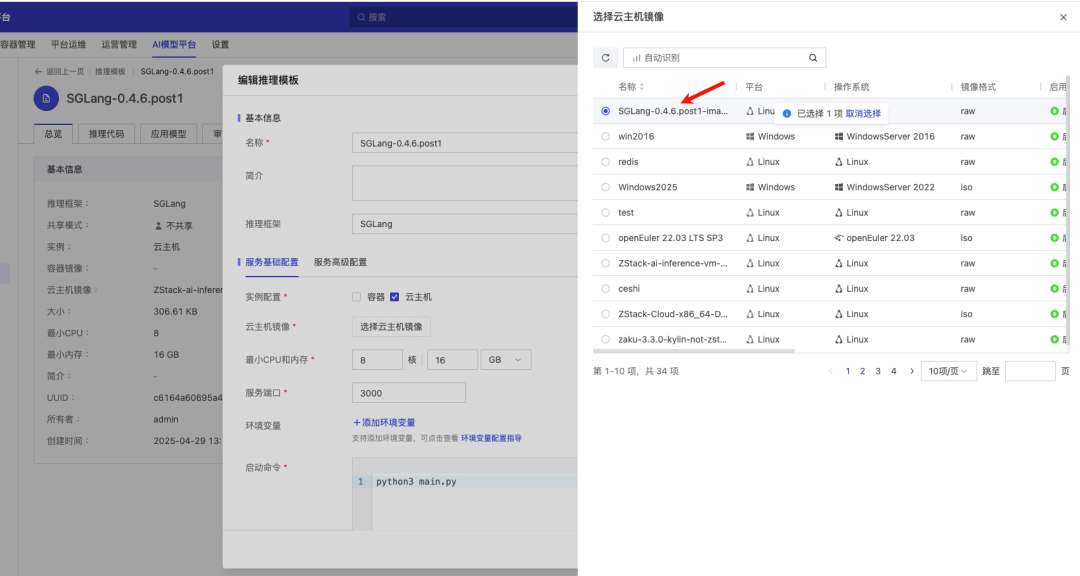
启动 Qwen3 模型
下载模型
此时进入模型仓库,添加模型,假设我们从 ModelScope 下载,在来源选择 ModelScope,Model ID 填入我们计划使用的模型,例如 Qwen/Qwen3-14B、Qwen/Qwen3-235B-A22B 等,在推理模板选择我们刚刚新建的推理模板 SGLang-0.4.6.post1
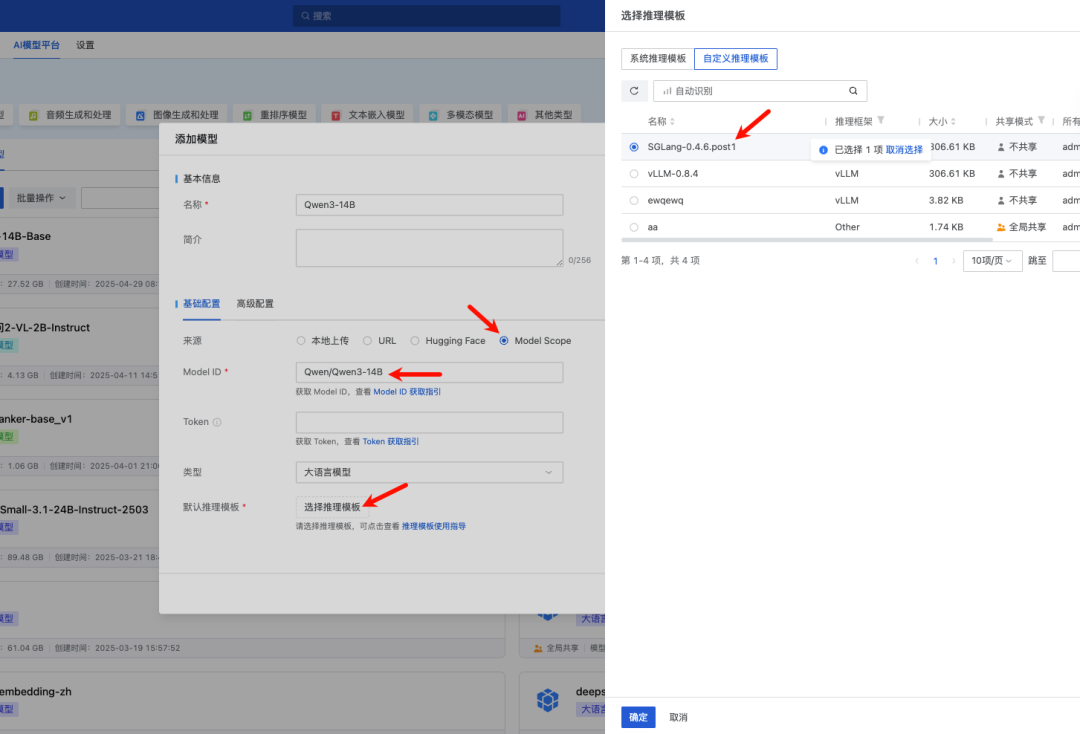
运行模型
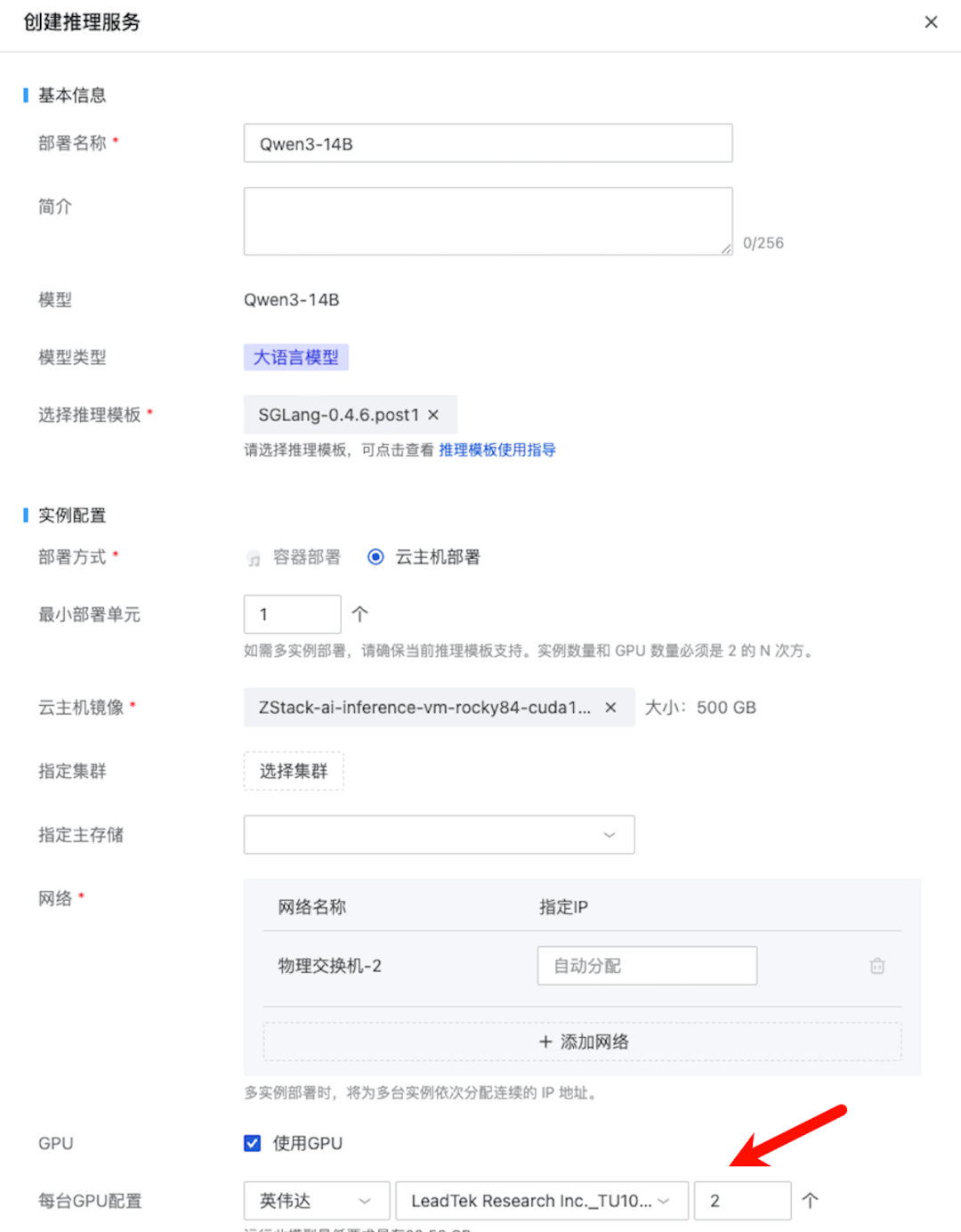
由于 14B 模型有 28GB 的权重,因此我们使用两张 22GB GPU 进行部署:
接下来等待启动即可,可以通过界面对话或者通过其他客户端如 chatwise 等接入测试:
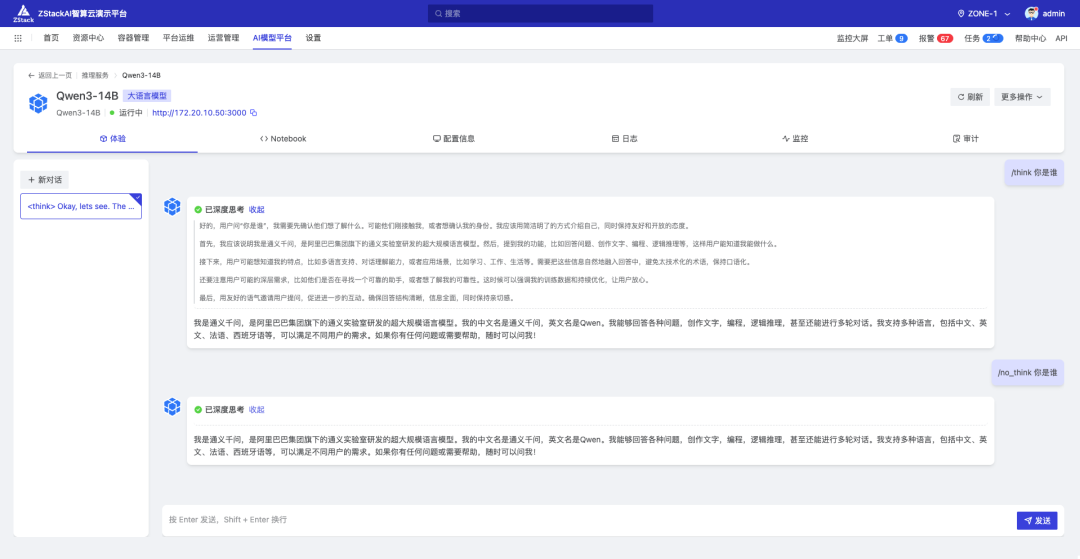
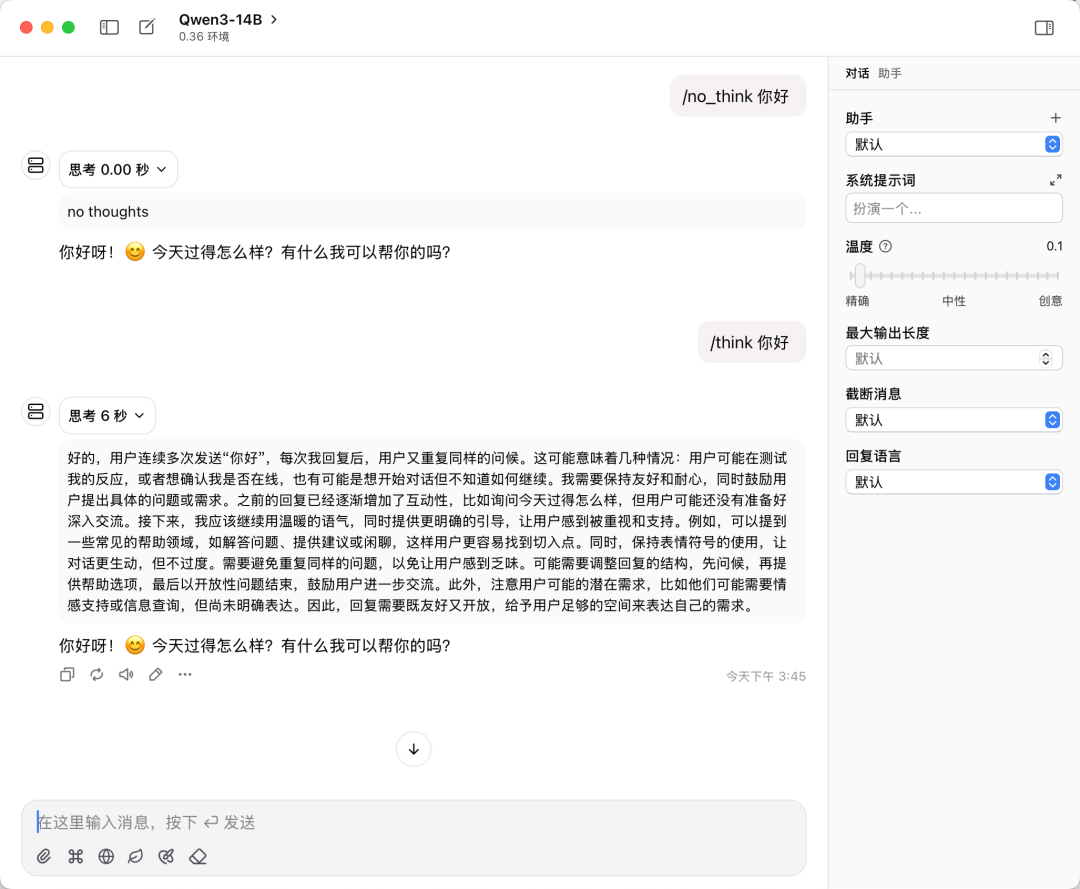
可以看到,在 Qwen3 模型中 /think、/no_think 可以作为特殊 token 来控制是否打开思考,这极大地方便了我们在需要逻辑推理和不需要逻辑推理的时候快速进行切换。
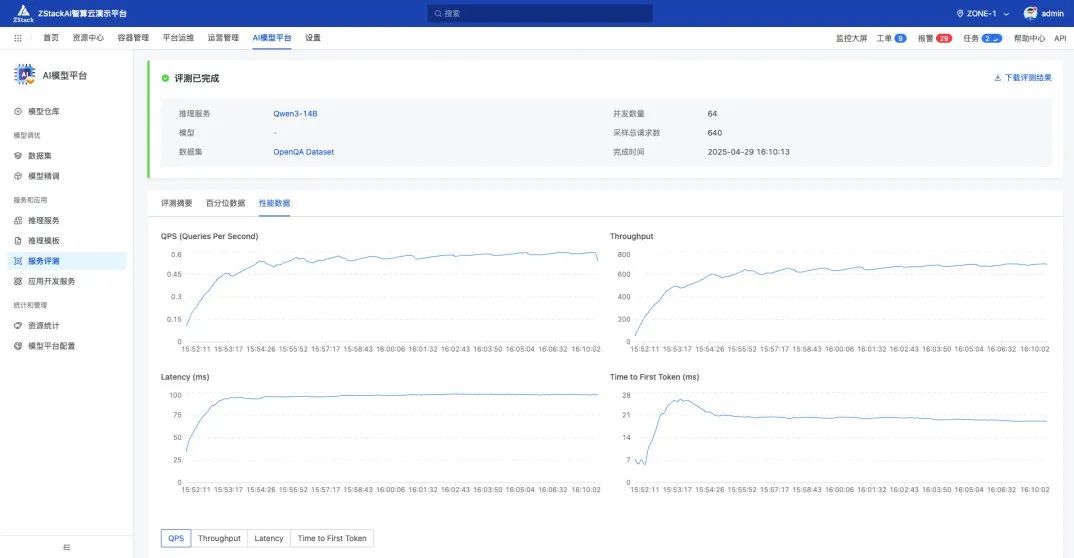
此外,我们也可以通过服务评测对推理服务进行测试,得益于高性能的 flashinfer 后端,两张 22GB 的消费级 GPU 即可实现接近 700 的 TPS。