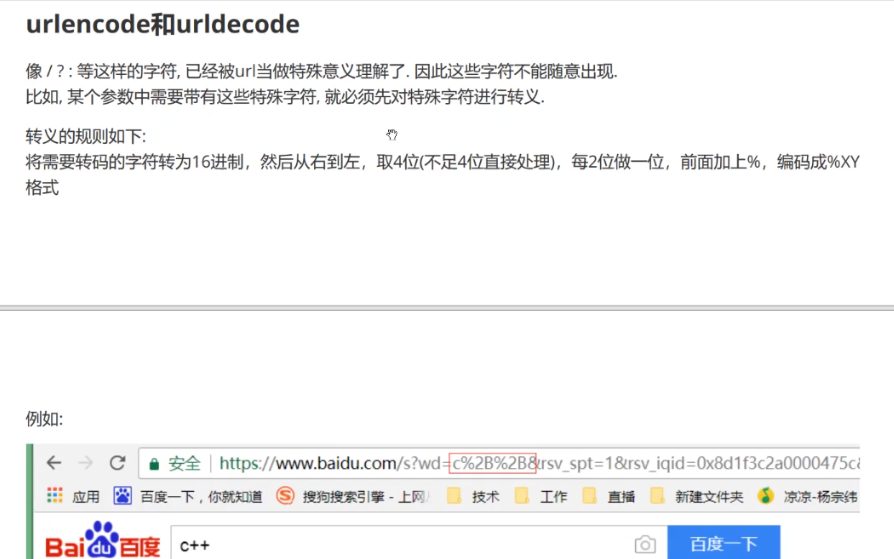
URL:

HTTP 是客户端和服务器间传输数据的应用层协议 :
- 连接建立:基于 TCP,可建立短连接(HTTP/1.0 常见,请求后断开 )或持久连接(HTTP/1.1 常见,可多次请求 )。
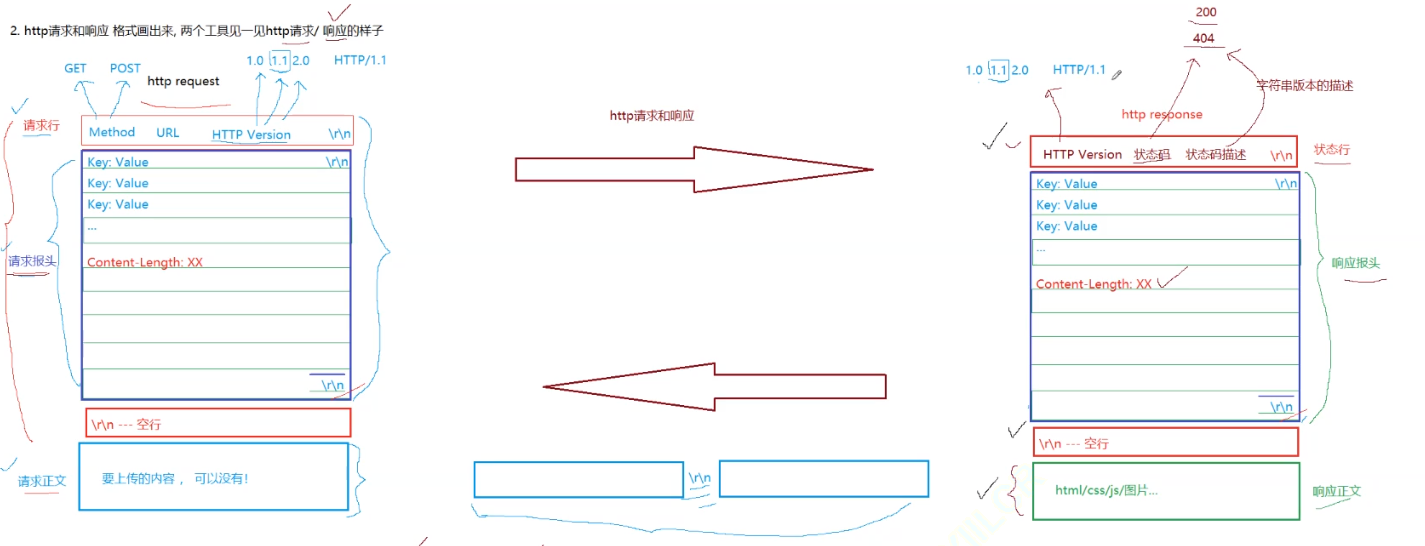
- 请求发送:客户端发请求,含请求行(方法、URL、版本 )、请求头(客户端等信息 )、请求体(部分方法有 )。
- 服务器处理:解析请求,找对应资源或程序,生成响应。
- 响应返回:服务器回送响应,有状态行(版本、状态码、消息 )、响应头(服务器等信息 )、响应体(请求数据 )。
- 连接后续:持久连接可继续请求,短连接响应后断开 。它是无状态协议,靠 Cookie 等技术维持状态 。
HTTP的方法:其中最常用的就是GET和POST,两者的区别就是GET是在URL显示提交参数,而POST是在正文里面提参。
下面是HTTP的格式:
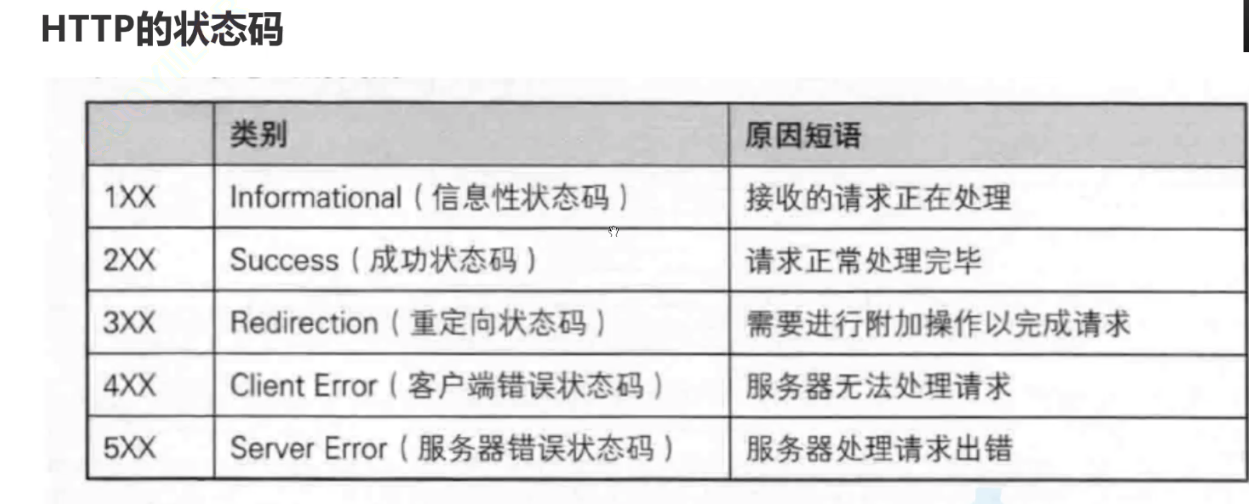
最常见的状态码,比如 200 (OK), 404 (Not Found), 403 (Forbidden), 302 (Redirect, 重定向), 504 (Bad Gateway)
HTTP常见Header
Content-type:数据类型 text、html等
Content-length:Body的长度
Host:客户端告知服务器,所请求的资源是在哪个主机的那个端口上
User-agent:声明用户的操作系统和浏览器版本信息
Refer:当前页面是从那个页面跳转过来的
Location:搭配3xx状态码使用,告诉客户端接下来要去那里访问;例如原网址搬家了,接下来要去那看信息
Cookie:用于在客户端存储少量信息。通常用于实现会话功能;
关于cookie文件看下图介绍:
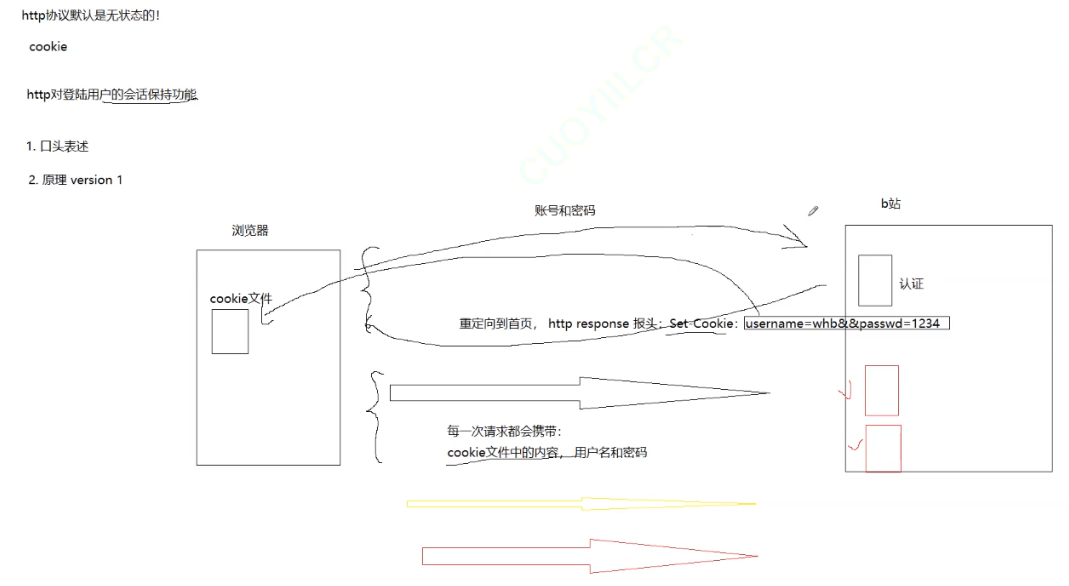
cookie存放了用户的信息包括登录密码,这一点也是http不安全的地方!从而会有黑客做假网站,诱导用户登录然后提取网站cookie,导致用户个人信息被盗取!
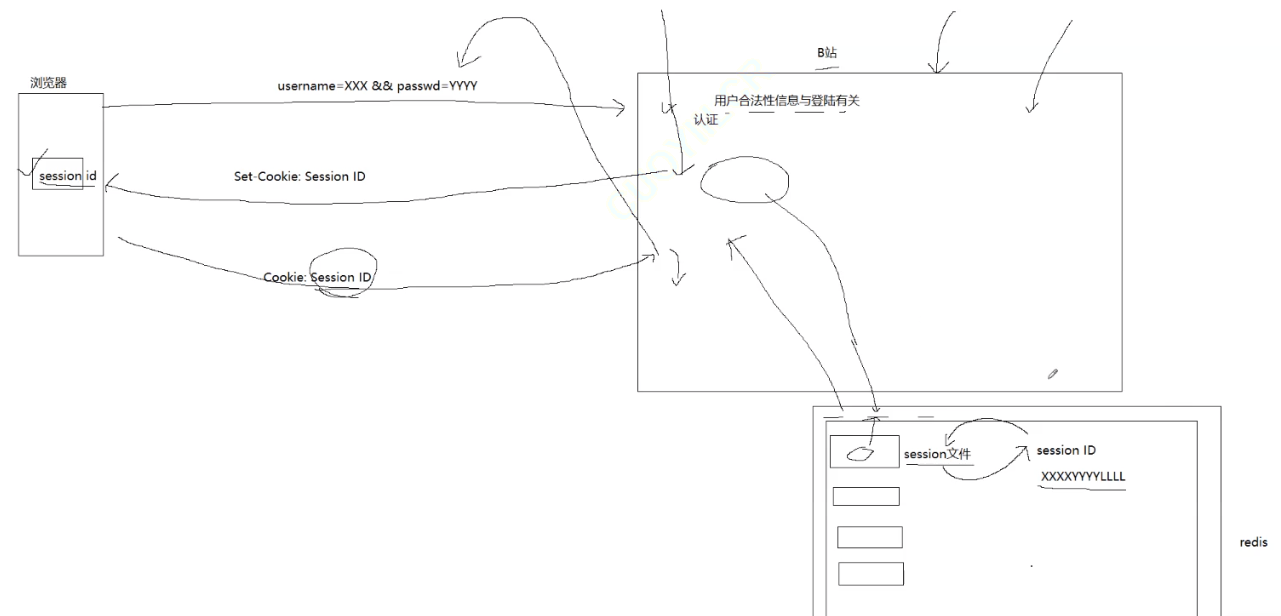
用户发起登录后,网站给会创建一个session会话,会话中会有session id网站会把id交给浏览器。从而拥有id以后登录这个网页端时候,会检查这个id如果存在就会免登录!
使用 HTTP 需注意:
- 安全:明文传数据易被窃听篡改,缺身份验证权限控制,敏感交互用 HTTPS 。
- 状态:无状态,借助 Cookie、Session 等维持状态 。
- 性能:连接效率低,可复用 TCP 连接;关注协议版本差异,新的性能优 。
- 代理:选可靠服务商,关注速度稳定、安全隐私,注意身份验证等 。
- 其他:防 HTTP 劫持,留意状态码排查问题 。
下面是模拟HTTP:httpserver.hpp:
cpp
#include "Log.hpp"
#include <iostream>
#include <unistd.h>
#include <string.h>
#include <pthread.h>
#include <sys/socket.h>
#include <sys/types.h>
#include "Socket.hpp"
#include <fstream>
#include <string>
#include <vector>
#include<sstream>
#include <unordered_map>
using namespace std;
static const uint16_t default_port = 8080;
const string wwwroot = "./wwwroot"; // web根目录
const string sep="\r\n";
const string homepage="index.html";
class HttpServer;
class ThreadData
{
public:
ThreadData(int fd /*,HttpServer* svr*/) : sockfd(fd) {}
public:
int sockfd;
// HttpServer* httpsvr;
};
class Request
{
public:
void DeSerialize(string &req)
{
while (true)
{
std::size_t pos = req.find(sep);
if (pos == std::string::npos)
break;
std::string temp = req.substr(0, pos);
if (!temp.empty())
req_header.push_back(temp);
// req.erase(0, pos + sep.size());
req.erase((size_t)0, (size_t)pos + sep.size());
}
text=req;
}
void parse()
{
stringstream ss(req_header[0]);
ss>>method>>url>>http_verison;
file_path=wwwroot;
if(url=="/"||url=="/index.html")
{
file_path+="/";
file_path+=homepage;
}else{
file_path+=url;
}
auto pos=file_path.rfind(".");
if(pos==string::npos) suffix=".html";
else suffix=file_path.substr(pos);
}
void Debug()
{
for(auto&line:req_header)
{
cout<<line<<"/n/n";
}
cout<<"method:"<<method<<endl;
cout<<"url:"<<url<<endl;
cout<<"http_verison:"<<http_verison;
cout<<text<<endl;
}
public:
vector<string> req_header;
string text;
string method;
string url;
string http_verison;
string file_path;
string suffix;
};
class HttpServer
{
public:
HttpServer(uint16_t port = default_port) : _port(port)
{
content_type.insert({".html","text/html"});
content_type.insert({".png","image/png"});
}
bool Start()
{
_listen_sockfd_.Socket();
_listen_sockfd_.Bind(_port);
_listen_sockfd_.Listen();
for (;;)
{
std::string clientIp;
uint16_t clientPort;
int sockfd = _listen_sockfd_.Accept(&clientIp, &clientPort);
if (sockfd < 0)
{
continue;
}
ThreadData *td = new ThreadData(sockfd /*,this*/);
// td->sockfd = sockfd;
pthread_t tid;
if (pthread_create(&tid, nullptr, ThreadRun, td) != 0)
{
// 处理线程创建失败的情况
std::cerr << "Failed to create thread" << std::endl;
delete td;
close(sockfd);
}
}
return true;
}
static string ReadHtmlContent(const string &htmlpath)
{
// 这里就是打开文件的正常操作
ifstream in(htmlpath,ios::binary);
if (!in.is_open())
return "404";
in.seekg(0,ios_base::end);//将文件指针移动到文件末尾(ios_base::end )
auto len=in.tellg();//用 tellg 获取文件指针位置
in.seekg(0,std::ios_base::beg);//将文件指针移回文件开头(std::ios_base::beg )
string content;
content.resize(len);
in.read((char*)content.c_str(),content.size());//把文件内容读到content里面
// string line;
// string content;
// while (getline(in, line))
// {
// content += line;
// }
in.close();
return content;
}
static string suffixToDesc(const string& suffix)
{
auto iter=content_type.find(suffix);
if(iter==content_type.end())return ".html";
else return content_type[suffix];
}
static void HnaderHttp(int fd)
{
char buffer[4096];
ssize_t n = recv(fd, buffer, sizeof(buffer) - 1, 0);
if (n > 0)
{
buffer[n] = 0;
std::cout << buffer;
Request req;
string bufferStr(buffer);//就nm你事多!
req.DeSerialize(bufferStr);
req.parse();
req.Debug();
// 目录
// url="/a/b/c";
// string path = wwwroot;
// path += url;
// 返回响应过程
string text = ReadHtmlContent(req.file_path); // 这是响应内容
string response_line = "HTTP/1.0 200 OK\r\n"; // 状态行
string response_header = "content_length:"; // 响应报头
response_header += to_string(text.size());
response_header += "\r\n"; // 每一行结束后都有换行
response_header+="content-type";
// string suffixToDesc=suffixToDesc(req.suffix);
response_header+=suffixToDesc(req.suffix);
response_header+= "\r\n"; // 这句是因为http里面响应报头和响应内容之间会有一个空白行!
response_header+="Set cookie: name:hush11&&passwd:123456";
response_header+= "\r\n";
string blank_line = "\r\n";
// 现在开始把上面哪些整合在一起
string response = response_line;
response += response_header;
response += blank_line;
response+=text;
send(fd, response.c_str(), response.size(), 0);
}
close(fd);
}
static void *ThreadRun(void *args)
{
ThreadData *td = static_cast<ThreadData *>(args);
pthread_detach(pthread_self());
HnaderHttp(td->sockfd);
// char buffer[4096];
// ssize_t n = recv(td->sockfd, buffer, sizeof(buffer) - 1, 0);
// if (n > 0) {
// buffer[n] = 0;
// std::cout << buffer;
// }
// close(td->sockfd);
// delete td; // 释放动态分配的内存
return nullptr;
}
~HttpServer() {}
private:
Sock _listen_sockfd_;
uint16_t _port;
static unordered_map<string,string> content_type;
// 使用static关键字能让代码更加灵活和高效,特别是在需要共享数据或者实现独立于对象状态的功能时。
};
cpp
#include<iostream>
#include"httpServer.hpp"
#include"Log.hpp"
#include"Socket.hpp"
#include<memory>
using namespace std;
int main(int argc,char* argv[])
{
if(argc!=2)
{
exit(0);
}
uint16_t port=stoi(argv[1]);
unique_ptr<HttpServer> sur(new HttpServer(port));
sur->Start();
return 0;
}HTTPS 协议原理
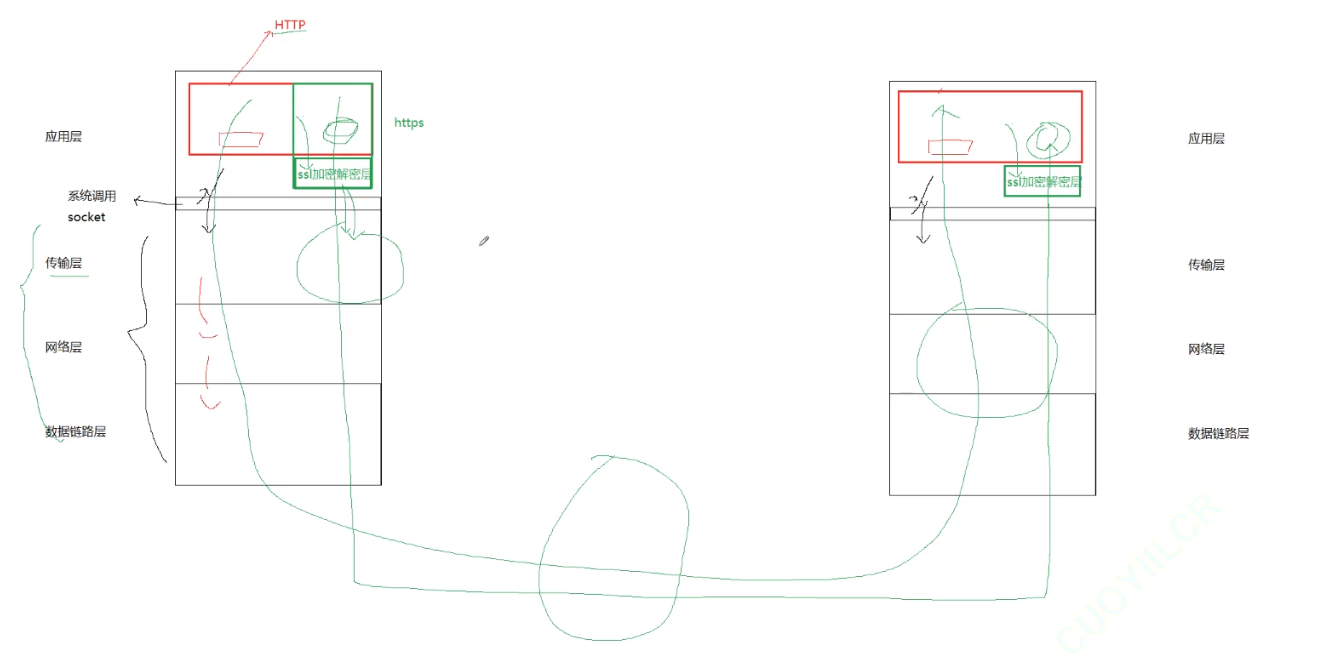
HTTPS 是什么
HTTPS 也是一个应用层协议,是在 HTTP 协议的基础上引入了一个加密层。
HTTP 协议内容都是按照文本的方式明文传输的,这就导致在传输过程中出现一些被篡改的情况。
概念准备
- 什么是 "加密"
加密就是把明文 (要传输的信息) 进行一系列变换,生成密文。
解密就是把密文再进行一系列变换,还原成明文。
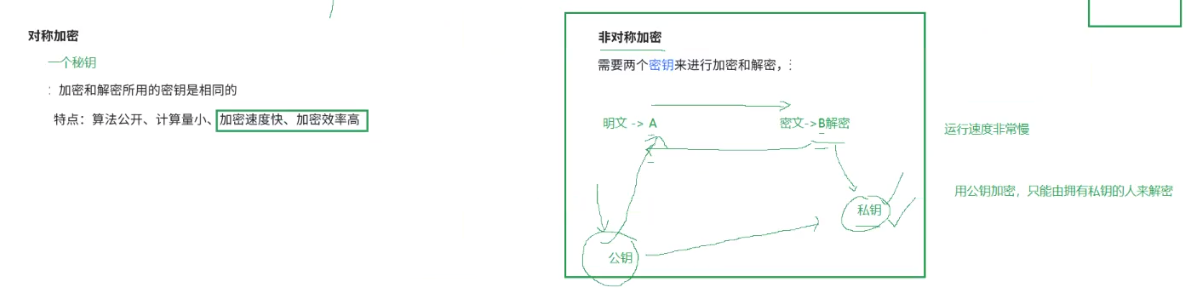
在这个加密和解密的过程中,往往需要一个或者多个中间的数据,辅助进行这个过程,这样的数据称为密钥
关于加密的方法有两种一种对称加密一种非对称加密:
只使用对称加密:
在只使用对称加密的方案中,客户端与服务器之间的通信依赖同一秘钥。客户端将明文请求通过秘钥加密成密文请求后发送给服务器,服务器收到密文请求后,再使用相同秘钥将其解密为明文请求。然而,若黑客入侵路由器,就可能截获请求内容,一旦秘钥在传输过程中被窃取,黑客便能利用该秘钥轻松解密密文请求,获取原始明文信息,导致通信内容泄露,这体现了仅使用对称加密在网络通信安全方面存在的风险与隐患。
只使用非对称加密:
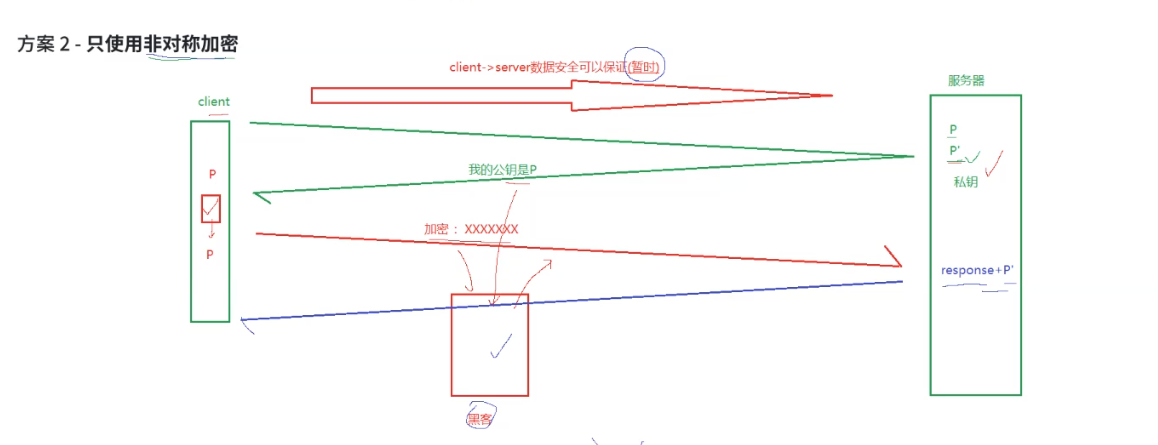
在只使用非对称加密的方案中,服务器拥有公钥 P 和私钥 P' 。服务器先将公钥 P 发送给客户端,此时客户端到服务器(client -> server)的数据安全暂时得以保证。客户端使用公钥 P 对数据进行加密(加密过程标记为 XXXXXX )后发送。但存在风险,若黑客截获通信内容,虽然无法用公钥 P 解密数据,不过若黑客设法替换服务器发送的公钥,客户端就会使用被替换的公钥加密数据,黑客便能利用对应的私钥解密获取信息,从而威胁数据安全。
方案 3 - 双方都使用非对称加密
- 服务端拥有公钥 S 与对应的私钥 S',客户端拥有公钥 C 与对应的私钥 C'
- 客户和服务端交换公钥
- 客户端给服务端发信息:先用 S 对数据加密,再发送,只能由服务器解密,因为只有服务器有私钥 S'
- 服务端给客户端发信息:先用 C 对数据加密,在发送,只能由客户端解密,因为只有客户端有私钥 C'
这样貌似也行啊,但是
- 效率太低
- 依旧有安全问题
方案四-非对称加密+对称加密

也不可行,还是存在安全问题!
方案 5 - 非对称加密 + 对称加密 + 证书认证
在客户端和服务器刚一建立连接的时候,服务器给客户端返回一个证书,证书包含了之前服务端的公钥,也包含了网站的身份信息。证书就和身份证一样!
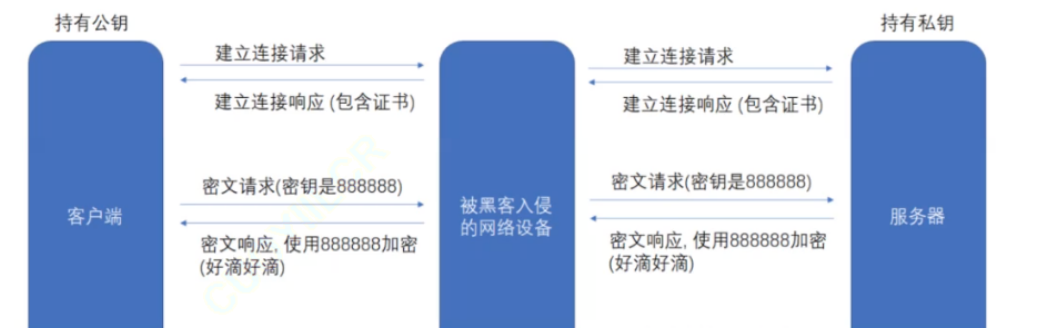
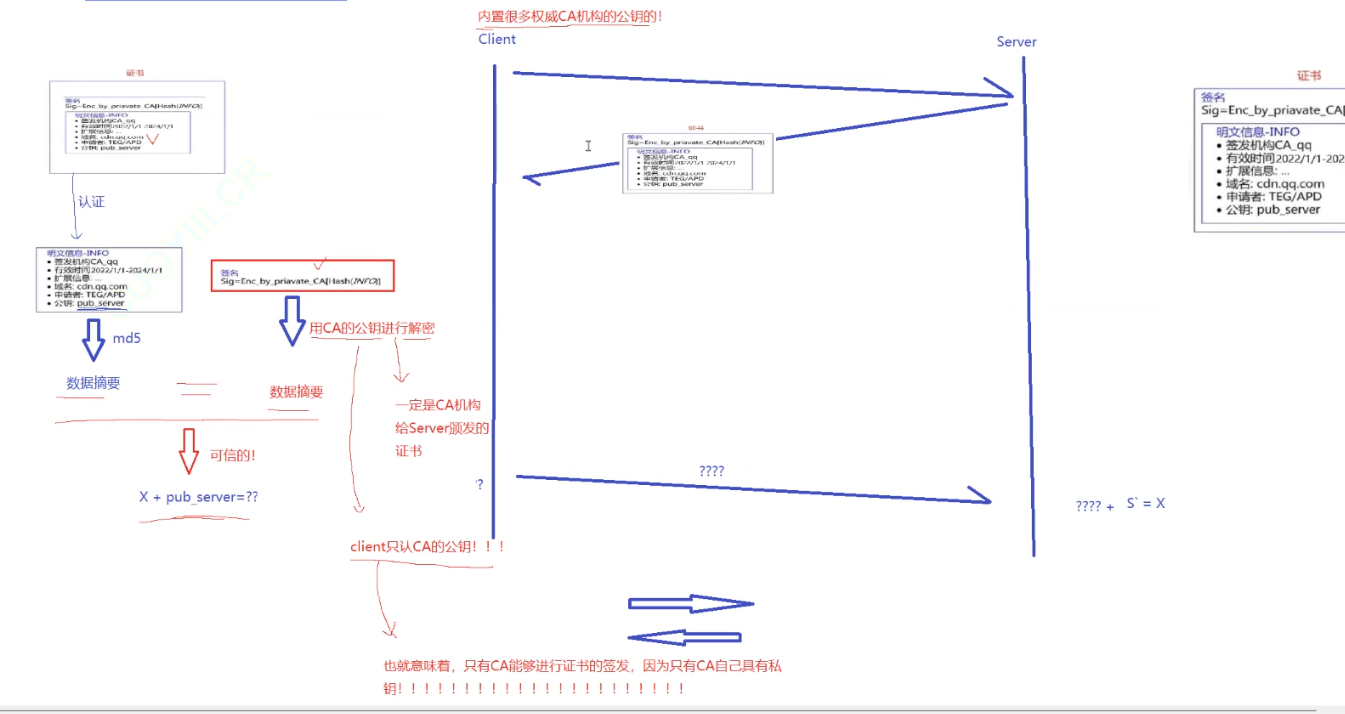
HTTPS 工作过程中涉及到的密钥有三组。
第一组 (非对称加密): 用于校验证书是否被篡改。服务器持有私钥 (私钥在形成 CSR 文件与申请证书时获得), 客户端持有公钥 (操作系统包含了可信任的 CA 认证机构有哪些,同时持有对应的公钥). 服务器在客户端请求是,返回携带签名的证书。客户端通过这个公钥进行证书验证,保证证书的合法性,进一步保证证书中携带的服务端公钥权威性。
第二组 (非对称加密): 用于协商生成对称加密的密钥。客户端用收到的 CA 证书中的公钥 (是可被信任的) 给随机生成的对称加密的密钥加密,传输给服务器,服务器通过私钥解密获取到对称加密密钥.
第三组 (对称加密): 客户端和服务器后续传输的数据都通过这个对称密钥加密解密.
数据摘要 && 数据指纹
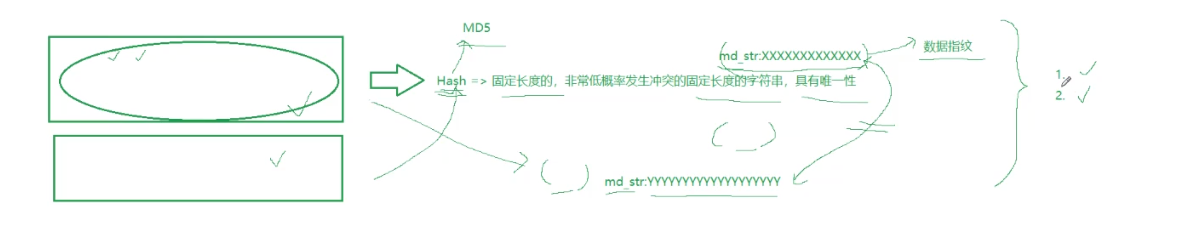
- 数字指纹 (数据摘要),其基本原理是利用单向散列函数 (Hash 函数) 对信息进行运算,生成一串固定长度的数字摘要。数字指纹并不是一种加密机制,但可以用来判断数据有没有被窜改。
- 摘要常见算法:有 MD5、SHA1、SHA256、SHA512 等,算法把无限的映射成有限,因此可能会有碰撞(两个不同的信息,算出的摘要相同,但是概率非常低)。
- 摘要特征:和加密算法的区别是,摘要严格意义不是加密,因为没有解密,只不过从摘要很难反推原信息,通常用来进行数据对比。
数字签名
- 摘要经过加密,就得到数字签名