在大数据和机器学习蓬勃发展的时代,信用卡欺诈检测成为了保障金融安全的重要环节。逻辑回归作为一种经典的机器学习算法,在这一领域发挥着关键作用。本文将通过一段完整的Python代码,详细解析逻辑回归在信用卡欺诈检测中的具体应用过程,带大家深入理解其原理与实践。
数据读取与预处理
首先,我们使用pandas库读取信用卡交易数据。代码data = pd.read_csv(r"./creditcard.csv")将存储在本地的creditcard.csv文件读取到data变量中,随后通过print(data.head())查看数据的前5行,初步了解数据的结构和内容。
python
import pandas as pd
data = pd.read_csv(r"./creditcard.csv")
print(data.head())#前5的数据数据预处理环节至关重要。对于Amount列数据,我们采用StandardScaler进行Z标准化处理,目的是使数据具有零均值和单位方差,消除不同特征之间的量纲差异,提升模型的训练效果。代码如下:
python
from sklearn.preprocessing import StandardScaler#z标准化的函数
scaler = StandardScaler()#初始化
a = data[['Amount']]
b = data['Amount']
data['Amount'] = scaler.fit_transform(data[['Amount']])
print(data.head())#打印这个表格的前5行同时,考虑到Time列在本次分析中可能对模型帮助不大,使用data = data.drop(['Time'],axis=1)将其删除,简化数据结构。
数据可视化分析
为了直观了解正负样本的分布情况,我们使用matplotlib和pylab库进行数据可视化。通过pd.value_counts(data['Class'])统计Class列中每类的个数,再绘制柱状图展示正负例样本数。这一步有助于我们对数据的不均衡性有更清晰的认识,为后续模型构建提供参考。
python
import matplotlib.pyplot as plt
from pylab import mpl
#matplotlib不能显示中文,借助于pylab实现中文显示
mpl.rcParams['font.sans-serif'] = ['Microsoft YaHei']#显示中文
mpl.rcParams['axes.unicode_minus'] = False
labels_count = pd.value_counts(data['Class'])#统计data['Class']中每类的个数
print(labels_count)
plt.title("正负例样本数")
plt.xlabel("类别")
plt.ylabel("频数")
labels_count.plot(kind='bar')
plt.show()模型构建与训练
接下来进入核心环节------逻辑回归模型的构建与训练。我们使用train_test_split函数将原始数据集划分为训练集和测试集,其中测试集占比30%,并通过设置random_state确保每次划分的数据集相同,便于模型的评估和比较。
python
from sklearn.model_selection import train_test_split#专门用来对数据集进行切分的函数
#对原始数据集进行切分
X_whole = data.drop('Class',axis=1)#删除class列,其余数据作为特征集
y_whole = data.Class #class列作为标签(label标注)
x_train_w, x_test_w, y_train_w, y_test_w = \
train_test_split(X_whole,y_whole,test_size = 0.3, random_state = 1000)
#随机种子可以保证每次抽的数据都是一样能的然后实例化LogisticRegression类,并设置超参数C=0.01,创建逻辑回归模型对象lr。通过lr.fit(x_train_w,y_train_w)将训练数据传入模型进行训练,此时训练好的模型参数将自动保存到lr变量中。
python
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression(C=0.01)#先调用这个类创建一个逻辑回归对象lr
lr.fit(x_train_w,y_train_w)#传入训练数据,之后的模型就会自动保存到变量lr模型评估
模型训练完成后,我们使用测试集对其进行评估。通过lr.predict(x_test_w)对测试集数据进行预测,得到预测结果test_predicted;再利用lr.score(x_test_w,y_test_w)计算模型在测试集上的准确率,衡量模型的整体性能。
python
test_predicted = lr.predict(x_test_w)#测试集
result = lr.score(x_test_w,y_test_w)#准确率为了更全面地评估模型的分类效果,我们引入classification_report函数,它能提供精确率、召回率、F1值等详细的分类指标,帮助我们深入分析模型在正负样本分类上的表现。
python
from sklearn import metrics
print(metrics.classification_report(y_test_w, test_predicted))运行结果
- List item
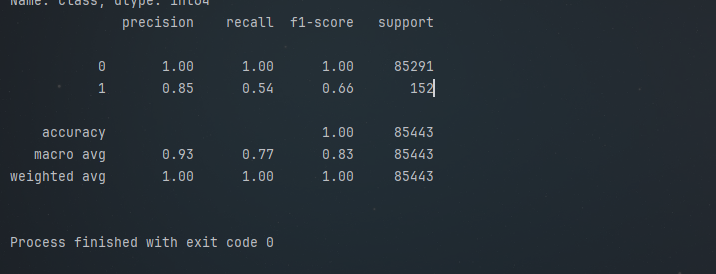
总结与展望
通过以上步骤,我们成功地将逻辑回归算法应用于信用卡欺诈检测任务中,从数据读取、预处理,到模型构建、训练与评估,完整地展示了一个机器学习项目的开发流程。逻辑回归凭借其简单易懂、可解释性强的特点,在金融风控领域有着广泛的应用。
然而,实际应用中可能存在数据不均衡、特征优化等问题,后续可以尝试采用过采样、欠采样等技术解决数据不均衡问题,或者运用特征工程方法挖掘更有效的特征,进一步提升模型的性能。希望本文能为大家在逻辑回归的学习和实践中提供帮助,也欢迎大家在评论区交流探讨更多优化思路和应用场景。
上述博客从代码出发,讲解了逻辑回归的应用全流程。若你觉得内容需要增减,或是想对某些部分深入探讨,欢迎和我说说。
这篇博客围绕代码全流程解析了逻辑回归的应用。若你想对模型优化、代码细节等方面展开更多探讨,欢迎随时分享你的想法。