一、Elasticsearch 是什么?
一句话定义:
开源分布式搜索引擎 ,擅长处理海量数据的实时存储 、搜索 与分析,是ELK技术栈(Elasticsearch+Kibana+Beats+Logstash)的核心组件。
核心能力:
- 近实时搜索:数据写入后1秒内可查
- 水平扩展:单机→集群,支持PB级数据处理
- 多场景适配:日志分析、商品搜索、舆情监控
二、为什么需要 Elasticsearch?
传统数据库的困境:
| 场景 | 传统数据库表现 | Elasticsearch解决方案 |
|---|---|---|
| 模糊搜索「周杰伦」 | 只能精确匹配「周杰伦」 | 支持谐音/错别字纠错 |
| 分析1亿条日志 | 导致数据库卡顿甚至崩溃 | 分布式并行处理,流畅响应 |
| 多字段混合查询 | 需多次关联查询 | 单次查询实现多维度关联分析 |
典型应用场景:
- 非结构化数据处理:日志、邮件、社交媒体文本等数据
- 复杂搜索需求:电商商品搜索、新闻资讯聚合
- 实时数据分析:业务指标监控、安全事件预警
三、Elasticsearch vs Solr:如何选择?
决策流程图:
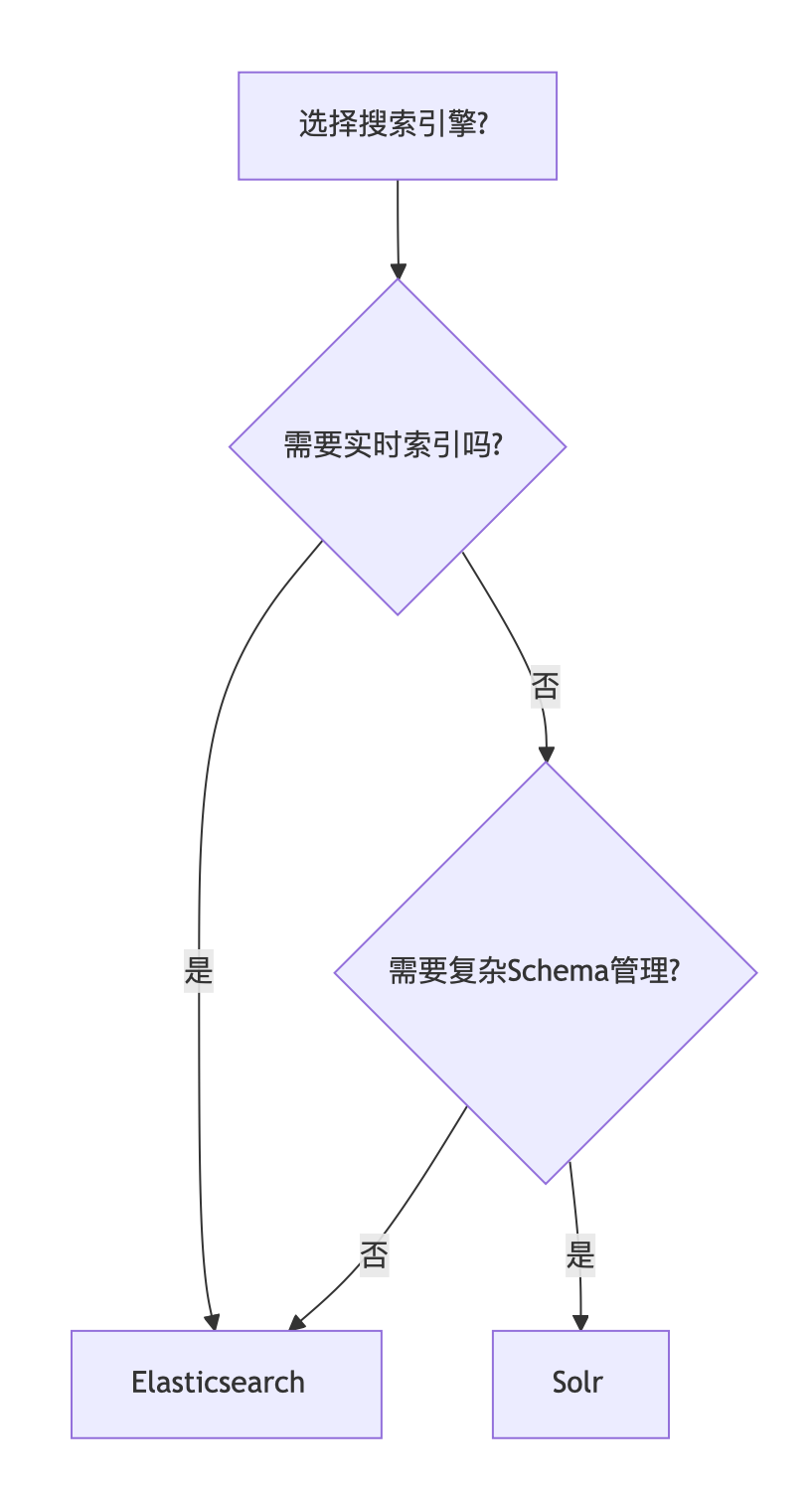
关键差异对比:
| 特性 | Elasticsearch | Solr |
|---|---|---|
| 部署复杂度 | 5分钟快速启动(JSON配置) | 需XML配置,学习成本较高 |
| 实时索引性能 | 写入无阻塞,查询响应快 | 批量写入快,实时索引有延迟 |
| 数据格式支持 | 仅JSON | JSON/XML/CSV |
| 适用场景 | 日志分析、实时搜索 | 企业级复杂搜索 |
| 社区生态 | 活跃但文档较技术化 | 成熟文档丰富 |
四、Elasticsearch 核心概念解析
索引(Index)------数据仓库分区
-
类比:图书馆的「科幻书架区」、人文书架区
-
规则:
-
- 名称必须全小写(
user_logs合法,UserLogs报错) - 一个索引存一类数据(订单索引、用户索引)
- 名称必须全小写(
4.2 文档(Document)------数据基本单元
- 形式:JSON格式(相等于关系型数据库表的行数据)
json
{
"title": "Elasticsearch入门",
"content": "全文搜索引擎的最佳实践",
"author": "技术小王",
"date": "2023-08-20"
}4.3 分片(Shard)------数据分块存储
-
作用:水平扩容+并行计算
-
类比:将1TB书籍拆成10层书架存放
-
特性:
-
- 主分片(处理写入)
- 副本分片(容灾+读请求分流)
4.4 副本(Replica)------数据双保险
-
意义:
-
- 防止节点宕机导致数据丢失
- 提升查询吞吐量(主分片+副本并行响应)
五、Elasticsearch 应用图谱
典型行业案例:
| 公司 | 应用场景 | 数据规模 |
|---|---|---|
| GitHub | 代码/日志检索 | 20TB数据/1300亿行 |
| 百度 | 用户行为分析 | 单集群日处理30TB+ |
| 阿里云 | 日志服务LaaS | 100节点集群 |