时间序列预测策略
(1)单步预测与多步预测
-
单步预测:每次预测时,输入窗口仅预测未来一个值。
-
多步预测:每次预测时,输入窗口预测未来n个值(也叫n步)。
单步预测和多步预测都是时间序列预测中常见的算法,根据其原理演化出了很多种优秀的算法,本节我们介绍四种非常实用的算法。
在做时间序列预测的时候,我们往往会预测未来多个时间步。但是,我们又没有未来的数据做训练,这时候就会引入一个概念:
- N阶滞后特征:训练和预测数据用到了N天之前的数据特征
举个例子:假设我们有10天的数据,现在要预测未来3天的数据。我们可以通过构造N阶滞后特征来实现这个目标。
已知序列:1,2,3,4,5,6,7,8,9,10,目标序列:11,12,13
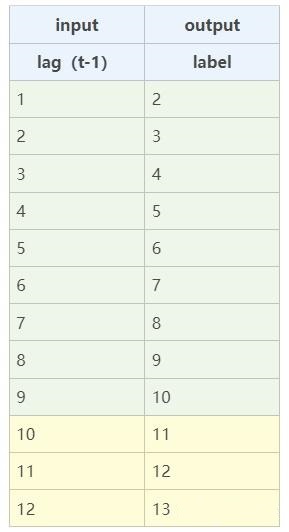
单步预测:构造1阶滞后特征lag(t-1)作为训练数据,当前已知序列作为训练目标。下表中,绿色区域为训练过程,黄色区域为预测过程。当模型训练完成后,用第10天的数据可以预测第11天的数据,第11天预测第12天,第12天预测第13天。
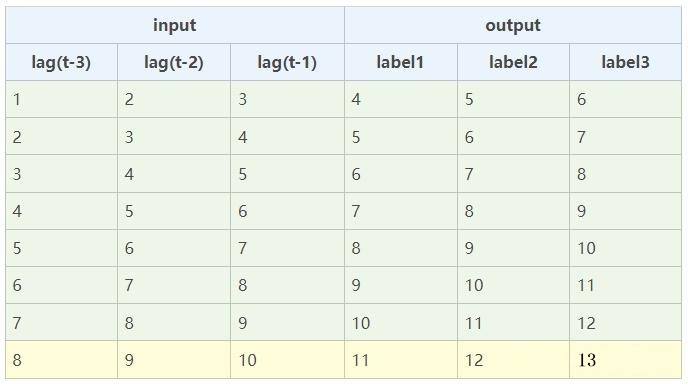
多步预测:构造多输出模型,一次预测3个未来值。下图示例中input长度选取为3,实际应用中input长度通常远大于output长度。
(2)直接多步预测
定义:直接多步预测(Direct Multi-Step Forecasting),构建n个模型预测未来n个值,每个模型预测1个值。这种方法本质是一种单步预测法。
我们继续用之前的示例模型:已知序列:1,2,3,4,5,6,7,8,9,10,目标序列:11,12,13。
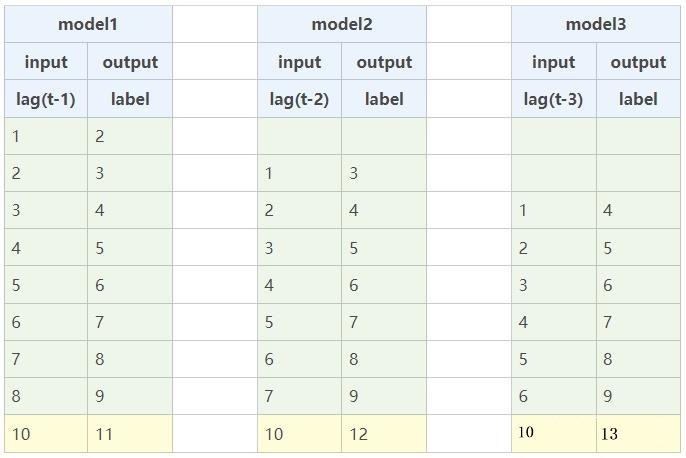
为了预测3个时间点的数值,我们需要构建3个模型,分别预测3个数值。
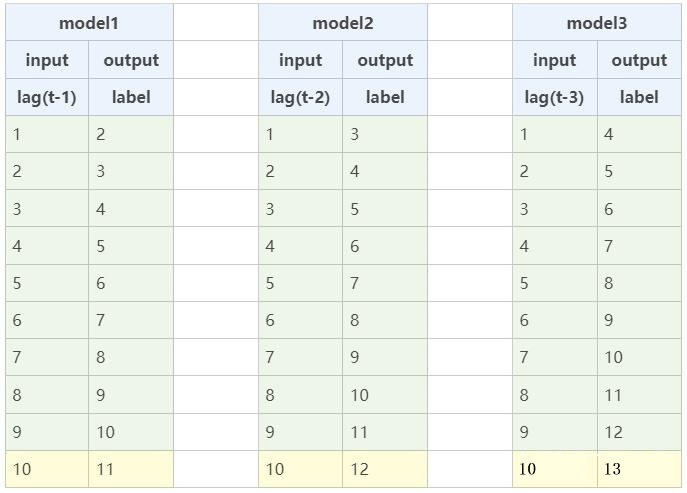
model1:1,2,3,4,5,6,7,8,9,10,11,构建1阶滞后序列训练模型
model2:1,2,3,4,5,6,7,8,9,10,12,构建2阶滞后序列训练模型
model3:1,2,3,4,5,6,7,8,9,10,13,构建3阶滞后序列训练模型
3个模型的训练过程如下所示:
算法优点:
- 直接多步预测能够直接预测未来的多个步骤,无需依赖单步预测的结果。这意味着它可以快速给出多步的预测值,无需进行多次迭代或叠加训练。
- 直接多步预测不依赖单步预测的结果,因此可以避免由于单步预测误差累积而导致的长期预测精度下降的问题。
算法缺点:
- 直接多步预测法需要为每个预测步长训练一个模型,这意味着如果预测步长很长,那么需要训练的模型数量会非常多,这增加了计算成本和模型管理的复杂性。
参考文档:时间序列多步预测的五种策略
(3)递归多步预测
定义:递归多步预测(Recursive Multi-Step Forecasting),用单个模型进行训练,通过使用模型已预测出的时间步的值作为输入,来预测下一个时间步的值,这个过程是递归进行的。
我们继续用之前的示例模型:已知序列:1,2,3,4,5,6,7,8,9,10,目标序列:11,12,13。
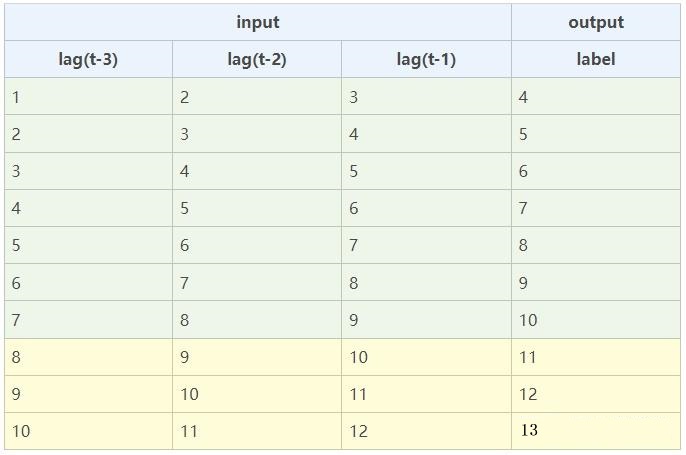
预测3个时间点的数值,我们只需构建1个模型,来递归预测3个未来数值。
当序列数据8,9,10预测出第11个数据值时,我们需要将这个预测值当做特征9,10,11去预测第12个数据。以此类推,递归迭代,直到预测过程全部完成。
模型的训练过程如下所示:
算法优点:
- 递归多步预测只需要建立单步预测模型,不需要考虑复杂的多步预测关系式。这种方法使得预测的实现过程相对简单。
- 递归多步预测通过利用时间序列数据之间的相关性,使用前一个时间步的预测结果来对下一个时间步进行预测,这有助于捕捉时间序列数据中的动态变化。
算法缺点:
- 递归多步预测的主要缺点是误差累积。由于它是基于之前步骤的预测结果来进行下一步的预测,因此任何一步的预测误差都会被带入到后续的预测中,导致误差的累积。随着预测步数的增加,误差累积效应会变得更加严重,从而影响预测结果的准确性。
(4)直接+递归的混合预测
定义:直接+递归的混合预测(Direct-Recursive Hybrid Forecasting),结合直接策略和递归策略,构建n个模型预测未来n个值,但是每个模型都可以使用上一个模型预测出的结果继续预测。n个模型可以是同构的(相同的lag),也可以是异构的(不同的lag)。
我们继续用之前的示例模型:已知序列:1,2,3,4,5,6,7,8,9,10,目标序列:11,12,13。
我们构建了3个模型(异构模型)。
model1(用1阶滞后特征训练),预测出的第11个点数值,作为model2(用2阶滞后特征训练)的训练数据,预测出的第12个点数值,作为model3(用3阶滞后特征训练)的训练数据,继续预测第13个点的数值。
算法优点:
- 直接多步预测方法虽然避免了递归方法中因使用预测值作为输入而导致的误差累积问题,但递归方法能够利用时间序列的相关性。混合预测方法通过结合两者的特性,可以在一定程度上减少误差累积,特别是在需要预测多个时间步长时。
- 递归方法通过利用前一个时间步的预测结果来预测下一个时间步,从而能够充分利用时间序列的相关性。混合预测方法保留了这一特性,使得预测结果更加准确。
算法缺点:
- 混合预测方法需要同时训练直接预测模型和递归预测模型,这增加了模型的复杂度。在实际应用中,可能需要更多的计算资源和时间来训练和优化模型。
(5)多输入多输出预测
定义:多输入多输出预测MIMO(Multiple Input Multiple Output),在一个模型里输出多个预测值,其本质是一种多输出模型。
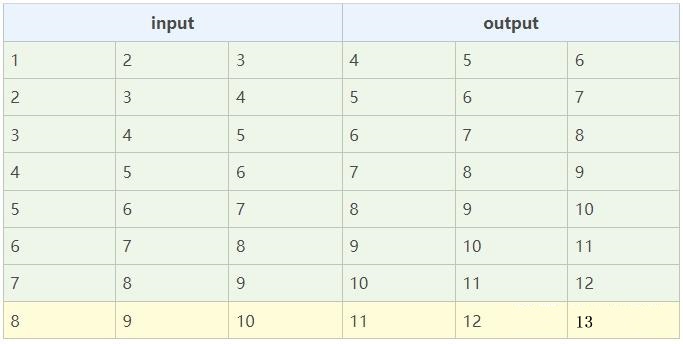
我们继续用之前的示例模型:已知序列:1,2,3,4,5,6,7,8,9,10,目标序列:11,12,13。
我们构建了1个模型,3个输入特征,3个输出预测值。
算法优点:
- 由于模型能够同时预测多个未来的数值,因此可以显著提高预测的效率。这对于需要快速响应或处理大量数据的场景非常有用。
- 在多步预测中,传统的递归预测方法可能会因为每一步的预测误差累积而导致预测结果逐渐偏离真实值。而多输出序列预测算法可以一次性预测多个时间点的值,从而减少了误差累积的可能性。
算法缺点:
- 与单步预测相比,多输出序列预测算法需要同时处理多个时间点的预测任务,因此计算复杂度通常较高。这可能导致预测速度变慢,尤其是在处理大规模数据集时。
- 为了训练一个准确的多输出序列预测模型,通常需要大量的历史数据来捕捉时间序列的复杂性和动态性。如果数据量不足或质量不高,可能会导致预测结果不准确。