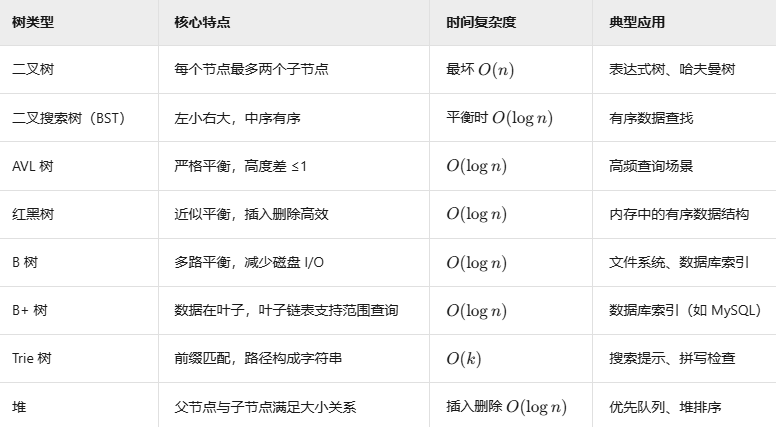
树的基本定义
树的定义
树(Tree) 是一种 非线性数据结构,由 节点(Node) 和 边(Edge) 组成,满足以下条件:
有且仅有一个根节点(Root):根节点没有父节点,是树的起点。
除根节点外,每个节点有且仅有一个父节点。
节点之间通过边连接,形成层次关系。
没有环路(Cycle):从根到任意节点的路径唯一。
树的逻辑结构
树形结构:
从根节点向下展开,形成多级分支,类似自然界中的树(倒置结构)。
节点间的连接具有 方向性(父→子)和 层次性。
递归定义:
一棵树由根节点和若干子树构成,每棵子树本身也是树。
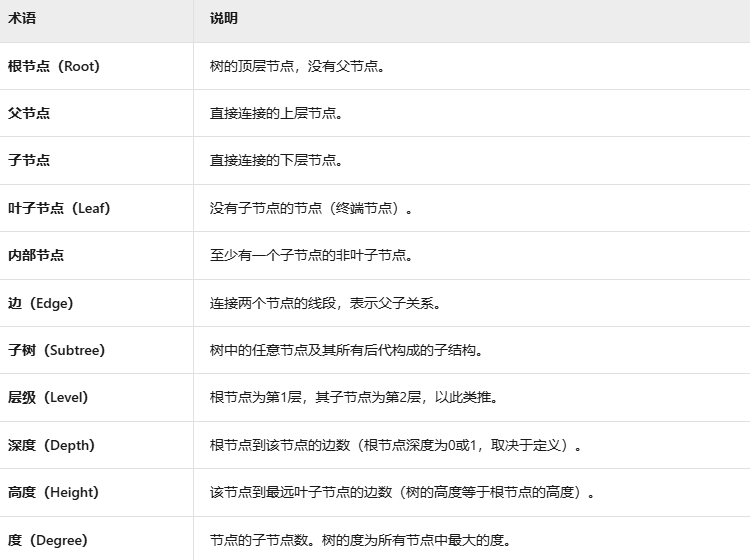
核心术语
树的分类
根据节点子节点的限制,树可分为多种类型:
1.普通树:
每个节点可以有任意多个子节点。
2.二叉树(Binary Tree):
每个节点最多有两个子节点(左子节点和右子节点)。
3.多叉树(N-ary Tree):
每个节点最多有 N 个子节点(如 B 树、Trie 树)。
树的性质
1.节点数:
一棵树有 n 个节点,则它有 n−1 条边(每条边对应一个父子关系)。
2.高度与节点数的关系:
对于高度为 h 的树,最少有 h+1 个节点(线性链状结构),最多有 2 h 2^h 2h−1 个节点(满二叉树)。
树的应用场景
1.文件系统:
目录结构是树形层级(根目录→子目录→文件)。
2.数据库索引:
B+ 树用于加速数据查询。
3.组织架构:
公司部门层级关系(CEO→部门→团队→员工)。
4.算法与数据结构:
二叉搜索树、堆、哈夫曼树等用于高效操作。
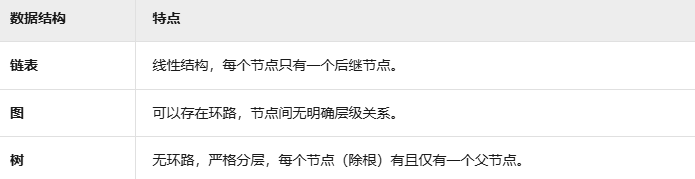
树与其他数据结构的区别
常见树结构
二叉树
定义:每个节点最多有两个子节点(左子节点和右子节点)。
特点:
结构简单,基础树形结构。
可用于构建其他复杂树结构(如二叉搜索树、堆)。
根节点(Root):树的顶层节点,没有父节点。
叶子节点(Leaf):没有子节点的节点。
内部节点(Internal Node):至少有一个子节点的非叶子节点。
普通二叉树
定义:每个节点最多有两个子节点,无其他约束。
示例:
bash
A
/ \
B C
/ \ \
D E F满二叉树(Full Binary Tree)
定义:所有非叶子节点都有两个子节点,且所有叶子节点在同一层。
特点:
深度为 h 的满二叉树有 2 h 2^h 2h−1 个节点。
示例:
bash
A
/ \
B C
/ \ / \
D E F G二叉搜索树(BST, Binary Search Tree)
定义:
左子树所有节点的值 < 根节点的值。
右子树所有节点的值 > 根节点的值。
特点:
中序遍历结果为有序序列。
如果平衡,查询效率高(O(logn))。
缺点:
可能退化为链表(插入顺序不佳时),查询效率降至 O(n)。
应用场景:
需要快速查找的有序数据集。
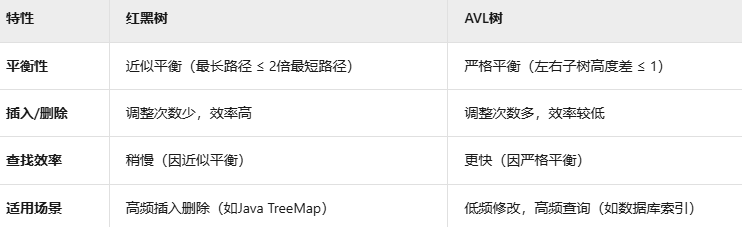
平衡二叉树(AVL 树、红黑树)
定义:
二叉搜索树的变种,通过旋转操作保持平衡。
任意节点的左右子树高度差不超过 1。
特点:
严格平衡,查询效率稳定(O(logn))。
缺点:
插入和删除时需要频繁旋转,维护成本高。
应用场景:
适合读多写少的场景(如字典)。
完全二叉树
定义:
除最后一层外,其他层节点数达到最大值。
最后一层的节点必须从左到右连续填充,中间不能有空缺。
示例:
bash
A
/ \
B C
/ \ /
D E F二叉树的遍历
bash
A
/ \
B C
/ \ \
D E F深度优先遍历(DFS)
前序遍历(Preorder):根 → 左 → 右
bash
①A
/ \
②B ⑤C
/ \ \
③D ④E ⑥F
结果:A → B → D → E → C → F中序遍历(Inorder):左 → 根 → 右
bash
④A
/ \
②B ⑥C
/ \ \
①D ③E ⑤F
结果:D → B → E → A → C → F后序遍历(Postorder):左 → 右 → 根
bash
⑥A
/ \
③B ⑤C
/ \ \
①D ②E ④F
结果:D → E → B → F → C → A广度优先遍历(BFS / 层次遍历)
按层遍历:从根节点开始,逐层从左到右访问。
bash
①A
/ \
②B ③C
/ \ \
④D ⑤E ⑥F
结果:A → B → C → D → E → F二叉树的应用
1.二叉搜索树(BST):快速查找、插入、删除有序数据。
2.堆(完全二叉树):优先队列、堆排序。
3.哈夫曼树(Huffman Tree):数据压缩(如 ZIP 文件)。
4.表达式树:解析数学表达式(如 (a + b) * c)。
5.决策树:机器学习分类模型。
红黑树(Red-Black Tree)
红黑树概述
红黑树(Red-Black Tree) 是一种 自平衡二叉搜索树,通过颜色标记和旋转操作维持树的平衡,确保最坏情况下的查找、插入和删除操作时间复杂度为 O(logn)。其核心设计目标是在插入和删除时减少平衡调整的次数,适合高频修改的数据场景。
红黑树的五大性质
节点颜色:每个节点是红色或黑色。
根节点:根节点必须是黑色。
叶子节点:所有叶子节点(NIL节点,空节点)为黑色。
红色节点限制:红色节点的子节点必须为黑色(即不存在连续红色节点)。
黑高一致:从任一节点到其所有后代叶子节点的路径上,黑色节点的数量相同(称为 黑高)。
红黑树的操作
插入操作:
按BST规则插入新节点,并将其标记为红色。
修复红黑树性质:
Case 1:父节点为黑色 → 无需调整。
Case 2:父节点为红色,叔叔节点为红色 → 父节点和叔叔变黑,祖父变红,再递归处理祖父节点。
Case 3:父节点为红色,叔叔节点为黑色 → 通过旋转和重新着色调整(分左旋和右旋情况)。
示例(插入节点后修复):
bash
插入前:
B (祖父)
/ \
R (父) B (叔叔)
/
R (新节点)
修复后(Case 2):
R (祖父)
/ \
B B
/
R删除操作:
步骤:
按BST规则删除节点。
若删除节点为红色:直接删除,无需调整。
若删除节点为黑色:需通过旋转和颜色调整恢复黑高。
Case 1:兄弟节点为红色 → 旋转父节点,使兄弟变黑。
Case 2:兄弟节点为黑色,且兄弟的子节点均为黑 → 兄弟变红,递归处理父节点。
Case 3:兄弟节点为黑色,且兄弟的远侄子为红 → 旋转父节点并重新着色。
示例(删除黑色节点后的调整):
bash
删除前:
B (父)
/ \
B (被删节点) R (兄弟)
\
B (远侄子)
修复后(Case 3):
B (父)
/ \
B B
\
R旋转操作:
左旋(Left Rotate):将右子节点提升为父节点,原父节点变为左子节点。
bash
P R
\ /
R → P
/ \
L L右旋(Right Rotate):将左子节点提升为父节点,原父节点变为右子节点。
bash
P L
/ \
L → P
\ /
R R红黑树的应用
Java集合框架:TreeMap、TreeSet 基于红黑树实现。
C++ STL:map、multimap、set、multiset。
Linux内核:进程调度、内存管理等模块使用红黑树管理数据。
数据库系统:部分数据库的索引结构采用红黑树。
红黑树的性能分析
时间复杂度:插入、删除、查找均为 O(logn)。
空间复杂度:O(n),每个节点存储颜色标记(1 bit)。
实际优化:通过减少旋转次数,红黑树在动态数据场景中表现优异。
B 树(B-Tree)
B树(B-Tree)是一种多路平衡搜索树,广泛用于处理大规模数据存储(如数据库、文件系统)的场景。其核心设计目标是减少磁盘I/O次数,通过保持树的高度平衡,优化数据的存储与访问效率。
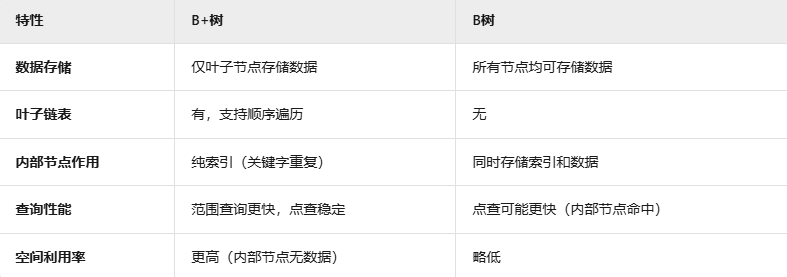
B树通过多路平衡的设计,在高并发、大规模数据存储场景中表现优异。理解其核心操作(分裂、合并)及平衡逻辑,是掌握数据库索引和文件系统优化的关键基础。对于需要频繁范围查询的场景,B+树通常是更好的选择。
B树定义
阶数(Order):B树的阶数由正整数 M 表示,决定了每个节点的最大子节点数和关键字数量。
节点特性:
每个节点最多有 M 个子节点。
每个非根节点至少有 ⌈M/2⌉ 个子节点(根节点至少有2个子树,除非它是叶子节点)。
每个非根非叶子节点至少有 ⌈M/2⌉−1 个关键字,最多有 M−1 个关键字。
所有叶子节点位于同一层,保证树的高度平衡。
B树的核心性质
1.平衡性:所有叶子节点在同一层,保证查找效率稳定。
2.多路分支:每个节点有多个子节点,减少树高。
3.自调整机制:插入操作可能触发节点分裂,删除操作可能触发节点合并或从兄弟节点借位,始终保持平衡。
B树的操作
查找
类似二叉搜索树,但在每个节点内部通过二分法确定分支路径:
从根节点开始,按关键字有序遍历。
若找到匹配值,返回结果;否则进入对应区间子节点。
直到叶子节点结束。
插入
定位插入位置:找到对应的叶子节点。
插入关键字:
若叶子节点未满(关键字数 < M−1),直接插入。
若节点已满,进行分裂:
将中间关键字(中位数)提升到父节点。
分裂原节点为两个新节点,各包含一半关键字。
若父节点满,继续向上递归分裂。
分裂可能一直向上传播到根节点,导致树高增加。
示例:3阶B树插入关键字(每个节点最多2个关键字):
插入到满节点 10,20 → 分裂为 10 和 20,中间提升 10 到父节点。
删除
分两种情况处理:
删除叶子节点关键字:
直接删除,若关键字数不足下限,需从兄弟节点借位或合并节点。
删除内部节点关键字:
用前驱(左子树最大值)或后继(右子树最小值)替代被删节点,转为叶子节点删除。
合并操作:若节点关键字过少且兄弟节点无法借位,与父节点的分隔键合并。
B树的应用场景
数据库索引:B树支持高效的点查和范围查询,降低磁盘I/O。
文件系统:存储文件的元数据(如NTFS、Ext4)。
键值存储:如LevelDB的SSTable索引。
B树时间复杂度
查找、插入、删除的时间复杂度均为 O( log m n \log_{m}n logmn),其中 M 为阶数,N 为数据总量。
由于 M 通常较大,树高远低于二叉树(如 log 100 n \log_{100}n log100n vs log 2 n \log_{2}n log2n),显著减少磁盘访问次数。
B+ 树(B+ Tree)
B+树(B-Plus Tree)是B树的变种,专为大规模数据存储和高效范围查询设计。它在数据库索引、文件系统等领域应用广泛,核心特点是数据仅存储在叶子节点,并通过叶子节点的链表连接优化顺序访问。
B+树的定义
阶数(Order):由正整数 M 表示,决定每个节点的最大子节点数和关键字数量。
节点特性:
内部节点(非叶子节点):
存储关键字作为索引(分隔键),不存储实际数据。
最多有 M 个子节点,至少有 ⌈M/2⌉ 个子节点(根节点例外)。
叶子节点:
存储所有关键字和对应的数据指针(或数据本身)。
叶子节点通过双向链表连接,支持高效顺序遍历。
每个叶子节点至少有 ⌈M/2⌉ 个关键字,最多有 M−1 个关键字。
所有叶子节点位于同一层,保证树高平衡。
B+树的核心性质
数据分离:内部节点仅存索引,数据全在叶子节点。
顺序访问优化:叶子节点通过链表连接,支持高效范围查询。
更高的分支因子:因内部节点不存数据,可容纳更多关键字,进一步降低树高。
B+树的操作
查找
点查:
从根节点开始,按关键字比较向下遍历。
最终到达叶子节点,若存在匹配关键字,返回数据;否则返回空。
范围查询:
找到起始关键字所在的叶子节点。
沿链表顺序遍历,直到终止关键字。
插入
定位插入位置:找到对应的叶子节点。
插入关键字:
若叶子节点未满(关键字数 < M−1),直接插入。
若叶子节点已满,进行分裂:
将中间关键字(中位数)复制到父节点作为索引。
分裂原节点为两个新节点,各包含一半关键字。
若父节点已满,递归向上分裂。
分裂规则:与B树不同,中间关键字在父节点中被复制而非移动。
示例:3阶B+树插入关键字(每个节点最多2个关键字):
插入到满叶子节点 10,20 → 分裂为 10 和 20,中间关键字 20 被复制到父节点作为索引。
删除
定位删除位置:找到目标关键字所在的叶子节点。
删除关键字:
若叶子节点关键字数仍满足下限(≥ ⌈M/2⌉),直接删除。
若关键字数不足,尝试从兄弟节点借位:
若兄弟节点有富余关键字,调整父节点索引。
若无法借位,与兄弟节点合并,并删除父节点中的冗余索引。
合并传播:合并可能导致父节点关键字不足,递归向上调整。
B+树的应用场景
数据库索引(如MySQL InnoDB):
范围查询(BETWEEN、ORDER BY)高效。
全表扫描只需遍历叶子链表。
文件系统(如ReiserFS、XFS):
快速定位文件块。
键值存储引擎(如RocksDB、MongoDB默认存储引擎WiredTiger)。
B+树的时间复杂度
查找、插入、删除的时间复杂度均为 O( log m n \log_{m}n logmn)
由于内部节点不存储数据,分支因子 M 更大,树高更低,I/O次数更少。
B+树 vs B树
Trie 树(字典树)
Trie 树(字典树或前缀树)是一种专门用于字符串检索和前缀匹配的树形数据结构。其核心思想是通过字符串的公共前缀来共享存储空间,优化查询效率,广泛应用于搜索引擎、输入法提示、路由表等场景。
Trie 树的定义
节点结构:每个节点代表一个字符,从根节点到某一节点的路径构成一个字符串。
根节点:不存储字符,表示空字符串。
子节点:每个节点的子节点对应不同字符(如26个小写字母、ASCII字符等)。
结束标记:节点可附加标记(如 is_end)表示是否为一个完整字符串的结尾。
示例:插入字符串 "apple", "app", "banana" 的 Trie 树结构:
root
/
a b
/
p a
/
p (is_end) n
/
p a
/ \
l (is_end) n
\
e (is_end) a (is_end)
Trie 树的核心性质
前缀共享:具有相同前缀的字符串共享路径,减少冗余存储。
快速检索:查找时间复杂度与字符串长度相关,与数据量无关。
自动排序:按字典序插入时,Trie 树天然支持有序遍历。
Trie 树的操作
插入字符串
从根节点开始,逐字符遍历字符串。
若字符对应的子节点不存在,则创建新节点。
到达字符串末尾时,标记当前节点为结束节点(is_end = true)。
示例:插入 "apple":
root → a → p → p → l → e(标记 e 节点为结束)。
查找字符串
从根节点开始,逐字符向下匹配。
若路径中途子节点不存在,返回 false。
若到达字符串末尾且当前节点标记为结束,返回 true。
示例:查找 "app":
root → a → p → p(该节点标记为结束,存在)。
查找前缀
与查找字符串类似,但无需检查结束标记,只需确认前缀存在。
删除字符串
先查找字符串是否存在。
若存在,从叶子节点向上回溯删除节点,直到遇到有其他子节点或标记为结束的节点。
注意:需处理共享前缀的情况,避免误删其他字符串。
Trie 树的应用场景
搜索引擎自动补全:根据输入前缀快速推荐候选词。
拼写检查:快速判断单词是否存在。
路由表匹配:IP地址前缀匹配(需结合压缩优化)。
词频统计:在节点中存储计数信息。
敏感词过滤:结合AC自动机(Aho-Corasick)实现多模式匹配。
Trie 树时间复杂度
插入:O(L),其中 L 为字符串长度。
查找:O(L)。
前缀匹配:O(L)。
堆(Heap)
堆(Heap)是一种基于完全二叉树的抽象数据结构,具有独特的堆序性,常用于高效获取数据集中的最大值或最小值。堆分为最大堆和最小堆,分别用于快速访问极值,是优先队列(Priority Queue)的底层实现核心。
堆的定义
完全二叉树:除最后一层外,其他层节点全满,最后一层节点从左到右填充。
堆序性:
最大堆:父节点的值 ≥ 子节点的值(根节点为最大值)。
最小堆:父节点的值 ≤ 子节点的值(根节点为最小值)。
存储结构:通常用数组实现,利用完全二叉树的性质简化索引计算。
堆的核心性质
1.结构特性:
完全二叉树,高度为 O(logn)。
数组表示中,节点索引关系:
父节点索引:parent(i)=⌊(i−1)/2⌋
左子节点索引:left(i)=2i+1
右子节点索引:right(i)=2i+2
2.堆序性:仅保证父节点与子节点的大小关系,不保证兄弟节点有序。
堆的操作
插入元素(Insert)
添加到末尾:将新元素插入数组末尾。
上浮(Percolate Up):从新元素开始,与父节点比较并交换,直到满足堆序性。
示例:在最大堆 70, 60, 50, 20, 10 中插入 65:
插入后数组 → 70, 60, 50, 20, 10, 65
上浮过程:65 > 20 → 交换 → 65 > 60 → 交换 → 最终堆 → 70, 65, 50, 60, 10, 20
删除堆顶元素(Extract-Max/Min)
交换堆顶与末尾:将堆顶元素与最后一个元素交换,删除末尾。
下沉(Percolate Down):从堆顶开始,与较大(或较小)的子节点交换,直到恢复堆序性。
示例:从最大堆 70, 65, 50, 60, 10, 20 删除堆顶:
删除后数组 → 20, 65, 50, 60, 10
下沉过程:20 < 65 和 50 → 与 65 交换 → 20 < 60 → 交换 → 最终堆 → 65, 60, 50, 20, 10
构建堆(Heapify)
Floyd算法:从最后一个非叶子节点开始,逐个节点执行下沉操作。
时间复杂度:O(n),数学证明基于树高和节点数量关系。
堆的应用场景
堆排序:通过构建堆,依次取出堆顶元素实现排序(时间复杂度 O(nlogn))。
优先队列:任务调度、事件驱动模拟(如Dijkstra算法)。
Top K 问题:快速找到数据流中最大的K个元素。
合并有序序列:K路归并时,用堆高效选择最小元素。
堆时间复杂度
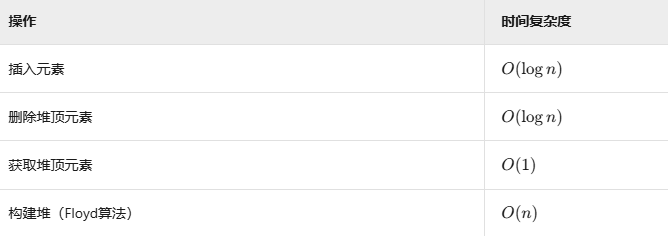
各种树对比