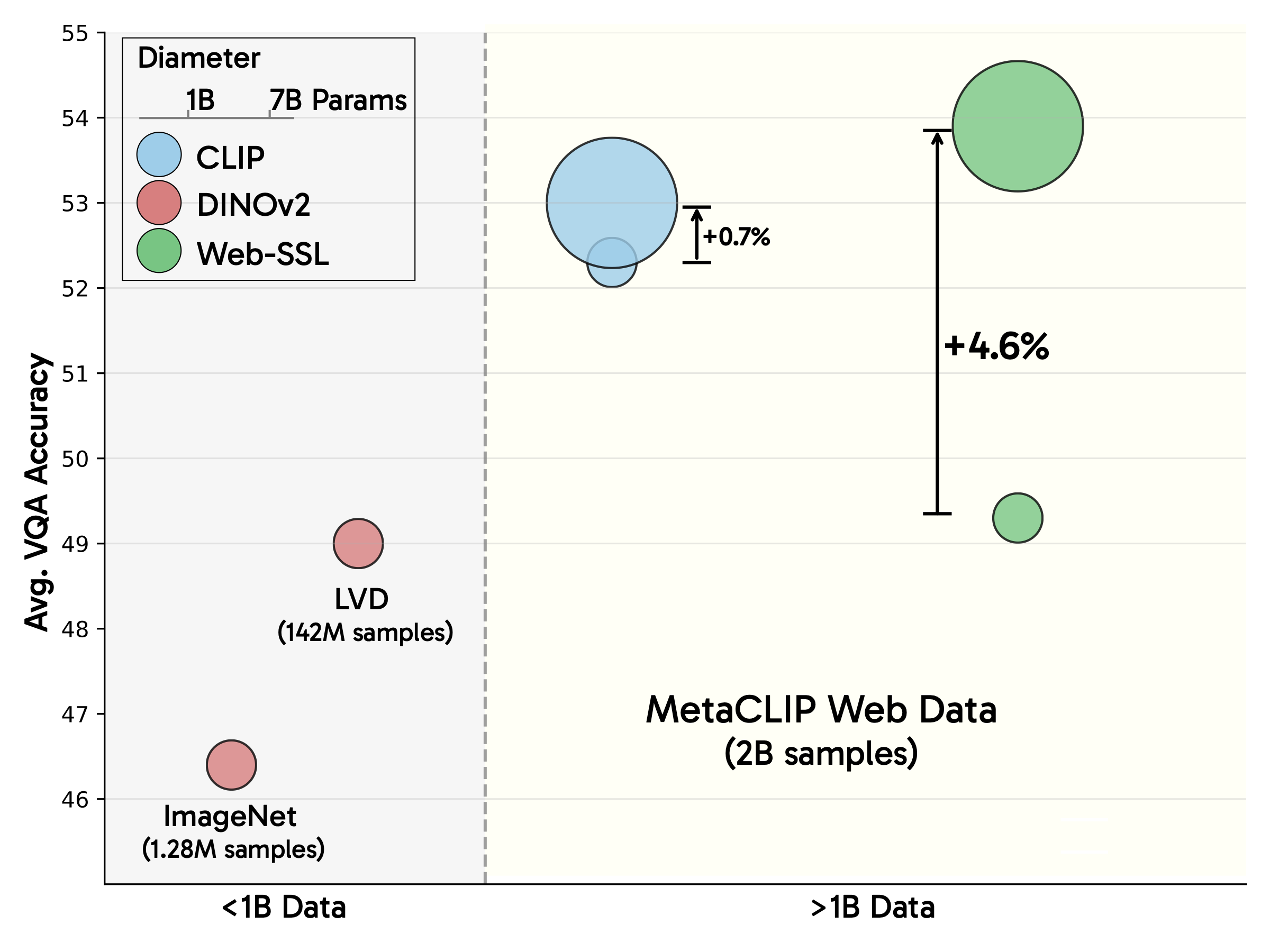
Web-SSL 探索了视觉自监督学习(SSL)在网络规模数据上的扩展潜力。通过调整模型大小和训练数据,我们证明了纯视觉模型可以与 CLIP 等语言监督方法相媲美,甚至超越它们,从而对 "语言监督是学习多模态建模所需的强大视觉表征的必要条件 "这一普遍假设提出了挑战。我们提出了 Web-SSL:一个参数从 0.3B 到 7B 不等的纯视觉模型系列,它为多模态建模和经典视觉任务提供了 CLIP 的有力替代方案。
主要发现:
- 📈 SSL 通过模型能力和数据不断改进。
- 🔍 Web-SSL 在广泛的 VQA 任务中,甚至在 OCR & 图表理解等与语言相关的任务中,都能与语言监督方法相媲美,甚至更胜一筹。
- 🖼️ 我们的模型在分类和分割等经典视觉任务中保持了极具竞争力的性能,同时在多模态任务中表现出色。
- 📊 视觉 SSL 方法对数据分布很敏感!在文本丰富的图像浓度较高的过滤数据集上进行训练,可大幅提高 OCR & 图表理解能力。
Web-DINO 型号
标准机型
Web-DINO 是 DINOv2 模型系列,参数范围从 0.3B 到 7B 不等,在更大规模的网络图像上进行训练。Web-DINO 模型在多模态任务(如 VQA)中表现尤为突出,同时又不影响经典视觉任务(如图像分类)的性能。详情请参见我们的论文。
| 模型 | 分块大小 | 分辨率 | 数据 | HuggingFace | 权重 |
|---|---|---|---|---|---|
| webssl-dino300m-full2b-224 | 14x14 | 224x224 | 2B (MC-2B) | Link | Link |
| webssl-dino1b-full2b-224 | 14x14 | 224x224 | 2B (MC-2B) | Link | Link |
| webssl-dino2b-full2b-224 | 14x14 | 224x224 | 2B (MC-2B) | Link | Link |
| webssl-dino3b-full2b-224 | 14x14 | 224x224 | 2B (MC-2B) | Link | Link |
| webssl-dino5b-full2b-224 | 14x14 | 224x224 | 2B (MC-2B) | Link | Link |
| webssl-dino7b-full8b-224 ⭐ | 14x14 | 224x224 | 8B (MC-2B) | Link | Link |
| webssl-dino7b-full8b-378 ⭐ | 14x14 | 378x378 | 8B (MC-2B) | Link | Link |
| webssl-dino7b-full8b-518 ⭐ | 14x14 | 518x518 | 8B (MC-2B) | Link | Link |
** 型号说明:**
- webssl-dino7b-full8b-224 ⭐:最佳 224x224 分辨率模型
- webssl-dino7b-full8b-378 ⭐:使用 384x384 分辨率时性能更佳
- webssl-dino7b-full8b-518 ⭐:518x518 分辨率下的最佳整体性能
过滤数据模型
这些模型是在 MC-2B 图像的过滤子集上进行训练的,这些子集包含较多文本(如标志、图表、表格、注释等)。这增强了 OCR & 图表理解能力,与在完整数据上训练的相同大小的模型相比,其他 VQA 类别的性能没有明显下降。
| 模型 | 分块大小 | 分辨率 | 数据 | HuggingFace | 权重 |
|---|---|---|---|---|---|
| webssl-dino2b-light2b-224 | 14x14 | 224x224 | 2B (MC-2B light) | Link | Link |
| webssl-dino2b-heavy2b-224 | 14x14 | 224x224 | 2B (MC-2B heavy) | Link | Link |
| webssl-dino3b-light2b-224 | 14x14 | 224x224 | 2B (MC-2B light) | Link | Link |
| webssl-dino3b-heavy2b-224 | 14x14 | 224x224 | 2B (MC-2B heavy) | Link | Link |
** 数据说明:**
- MC-2B light: MC-2B 图像中包含文本的 50.3% 子集
- MC-2B heavy: 包含图表/文档的 MC-2B 图像的 1.3% 子集。
Web-MAE 模型
Web-MAE 是一系列 MAE 模型,参数范围从 0.3B 到 3B,在更大规模的网络图像上进行训练。我们只发布了用于特征提取的编码器。
| 模型 | 分块大小 | 分辨率 | 数据 | HuggingFace | 权重 |
|---|---|---|---|---|---|
| webssl-mae300m-full2b-224 | 16x16 | 224x224 | 2B (MC-2B) | Link | Link |
| webssl-mae700m-full2b-224 | 14x14 | 224x224 | 2B (MC-2B) | Link | Link |
| webssl-mae1b-full2b-224 | 14x14 | 224x224 | 2B (MC-2B) | Link | Link |
| webssl-mae2b-full2b-224 | 14x14 | 224x224 | 2B (MC-2B) | Link | Link |
| webssl-mae3b-full2b-224 | 14x14 | 224x224 | 2B (MC-2B) | Link | Link |
Installation
It is possible that older or newer versions will work. However, we haven't tested them for this inference code.
conda create -n webssl python=3.11
conda activate webssl
pip install torch==2.5.1 torchvision==0.20.1 xformers --index-url https://download.pytorch.org/whl/cu124
pip install transformers==4.48.0 huggingface-hub==0.27.1 timm==1.0.15使用方法
我们提供了两个示例,将我们的模型与 HuggingFace 和原生 PyTorch 结合使用。请注意,您并不局限于使用预训练分辨率进行推理,但是,您可能会通过使用相同的分辨率进行推理获得最佳结果。
1.使用 HuggingFace Transformers
您可以选择使用 huggingface-cli 先在本地下载模型权重。当您没有大型缓存或网络速度较慢时,这样做很方便。
例如huggingface-cli download facebook/webssl-dino7b-full8b-518 --local-dir YOUR_PATH、然后提供 YOUR_PATH到 from_pretrained()。
python
from transformers import AutoImageProcessor, Dinov2Model
# Load a Web-DINO model
model_name = "facebook/webssl-dino1b-full2b-224"
processor = AutoImageProcessor.from_pretrained(model_name)
model = Dinov2Model.from_pretrained(model_name, attn_implementation='sdpa') # 'eager' attention also supported
model.cuda().eval()
# Process an image
from PIL import Image
image = Image.open("sample_images/bird.JPEG")
with torch.no_grad():
inputs = processor(images=image, return_tensors="pt").to('cuda')
outputs = model(**inputs)
last_hidden_states = outputs.last_hidden_state2.使用带有原始权重的 PyTorch
python
from dinov2.vision_transformer import webssl_dino1b_full2b_224
import torch
from PIL import Image
from torchvision import transforms
# Define image transformation
transform = transforms.Compose([
transforms.Resize(256, interpolation=transforms.InterpolationMode.BICUBIC),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225))
])
# Load model
model = webssl_dino1b_full2b_224()
# Load weights
checkpoint_path = "path/to/downloaded/weights.pth"
state_dict = torch.load(checkpoint_path, map_location="cpu")
msg = model.load_state_dict(state_dict, strict=False)
print(f"Loaded weights: {msg}")
model.cuda().eval()
# Process an image
image = Image.open("sample_images/bird.JPEG")
x = transform(image).unsqueeze(0).cuda()
with torch.no_grad():
features = model.forward_features(x)
patch_features = features['x_norm_patchtokens']https://github.com/facebookresearch/webssl
https://github.com/facebookresearch/webssl/blob/main/demo_webdino.py
https://github.com/facebookresearch/webssl/blob/main/demo_webmae.py