学习笔记:Qlib 量化投资平台框架 --- OTHER COMPONENTS/FEATURES/TOPICS
Qlib 是微软亚洲研究院开源的一个面向人工智能的量化投资平台,旨在实现人工智能技术在量化投资中的潜力,赋能研究,并创造价值,从探索想法到实施生产。Qlib 支持多种机器学习建模范式,包括监督学习、市场动态建模和强化学习。借助 Qlib,用户可以轻松尝试他们的想法,以创建更优秀的量化投资策略。
文中内容仅限技术学习与代码实践参考,市场存在不确定性,技术分析需谨慎验证,不构成任何投资建议。

公式化Alpha因子构建
一、核心概念
1.1 公式化Alpha因子定义
- 通过数学公式表达的预测性因子
- 用于解释和预测资产未来收益
- 示例:MACD(指数平滑异同移动平均线)
1.2 MACD技术指标解析
M A C D = 2 × ( D I F − D E A ) MACD = 2 \times (DIF - DEA) MACD=2×(DIF−DEA)
分量公式
- DIF(差离值) :
D I F = E M A ( C L O S E , 12 ) − E M A ( C L O S E , 26 ) C L O S E DIF = \frac{EMA(CLOSE, 12) - EMA(CLOSE, 26)}{CLOSE} DIF=CLOSEEMA(CLOSE,12)−EMA(CLOSE,26) - DEA(信号线) :
D E A = E M A ( D I F , 9 ) C L O S E DEA = \frac{EMA(DIF, 9)}{CLOSE} DEA=CLOSEEMA(DIF,9)
二、QLib实现步骤
2.1 数据加载器配置
python
from qlib.data.dataset.loader import QlibDataLoader
# MACD公式表达式
MACD_EXP = '(EMA($close, 12) - EMA($close, 26))/$close - EMA((EMA($close, 12) - EMA($close, 26))/$close, 9)/$close'
# 特征与标签配置
fields = [MACD_EXP] # 特征字段
names = ['MACD'] # 特征名称
labels = ['Ref($close, -2)/Ref($close, -1) - 1'] # 标签计算公式
label_names = ['LABEL'] # 标签名称
data_loader_config = {
"feature": (fields, names),
"label": (labels, label_names)
}2.2 数据加载与执行
python
# 初始化数据加载器
data_loader = QlibDataLoader(config=data_loader_config)
# 加载CSI300数据
df = data_loader.load(
instruments='csi300',
start_time='2010-01-01',
end_time='2017-12-31'
)
# 输出数据结构示例
print(df)
"""
feature label
MACD LABEL
datetime instrument
2010-01-04 SH600000 -0.011547 -0.019672
SH600004 0.002745 -0.014721
... ... ...
"""三、关键技术要素
3.1 特征工程组件
- EMA计算函数:
EMA($close, N) - 价格引用函数:
Ref($close, -N) - 算术运算符支持:+、-、*、/
3.2 数据维度说明
- feature列:包含计算得到的MACD值
- label列 :反映未来收益率
L A B E L = C l o s e t + 2 C l o s e t + 1 − 1 LABEL = \frac{Close_{t+2}}{Close_{t+1}} - 1 LABEL=Closet+1Closet+2−1
四、注意事项
- 前置初始化 :必须执行
qlib.init()初始化环境 - 数据格式规范 :
- 时间索引格式:YYYY-MM-DD
- 证券代码格式:交易所代码+股票代码(如SH600000)
- 计算周期说明 :
- 短期EMA周期:12日
- 长期EMA周期:26日
- 信号线周期:9日
五、扩展学习
- 数据加载器文档:Data Loader
- 数据API文档:Data API
在线模式与离线模式
1. 模式概述
支持模式:QLib 提供两种数据访问模式
- Online Mode(在线模式)
- Offline Mode(离线模式)*
2. 在线模式核心优势
设计目标:
- 集中化数据管理 - 用户无需处理多版本数据管理问题
- 减少缓存生成量 - 优化存储空间利用率
- 远程数据访问 - 支持分布式环境下的数据调用
3. Qlib-Server架构解析
3.1 系统定位
-
专用配套服务系统
-
基础架构:
textQlib基础计算引擎 + 扩展服务系统 + 智能缓存机制
3.2 核心价值
- 实现数据的集中化管理
- 支持在线模式运行环境搭建
- 提供远程服务调用能力
4. 进阶学习指引
- 项目文档:Qlib-Server Project
- 技术规范:Qlib-Server Document
序列化机制
一、核心功能概述
-
支持序列化对象类型:
- DataHandler
- DataSet
- Processor
- Model
- 其他继承自Serializable基类的对象
-
序列化格式:
- 使用pickle格式进行持久化存储
- 支持选择pickle后端(默认pickle/dill)
二、序列化基类实现
python
qlib.utils.serial.Serializable关键特性
-
属性保存规则:
-
自动保存不以
_开头的实例属性 -
可通过以下方式修改默认行为:
pythonself.config(dump_all=False) # 配置方法 default_dump_all = False # 类属性覆盖
-
-
Pickle后端选择:
pythonpickle_backend = "pickle" # 默认选项(标准序列化) pickle_backend = "dill" # 支持函数序列化等高级特性
三、序列化实践示例
1. 序列化数据集示例
python
# ============= 序列化数据集 =============
dataset.to_pickle(path="dataset.pkl") # dataset是DatasetH实例
# ============= 反序列化数据集 =============
with open("dataset.pkl", "rb") as file_dataset:
dataset = pickle.load(file_dataset)2. 关键注意事项
-
序列化内容限制:
- 仅保存状态信息(如数据标准化的均值/方差)
- 不保存实际数据(数据不属于状态)
-
反序列化后操作:
python# 必须重新初始化以下参数: instruments # 投资标的 start_time # 起始时间 end_time # 结束时间 segments # 数据分段
完整示例参考:this link(this link)
四、重要设计原则
-
状态与数据分离:
- 状态:需要持久化的配置参数
- 数据:动态生成不进行存储
-
可扩展性设计:
- 通过继承Serializable基类实现自定义序列化
- 支持不同pickle协议扩展
五、API参考
详细接口说明请参见:Serializable API
任务管理模块
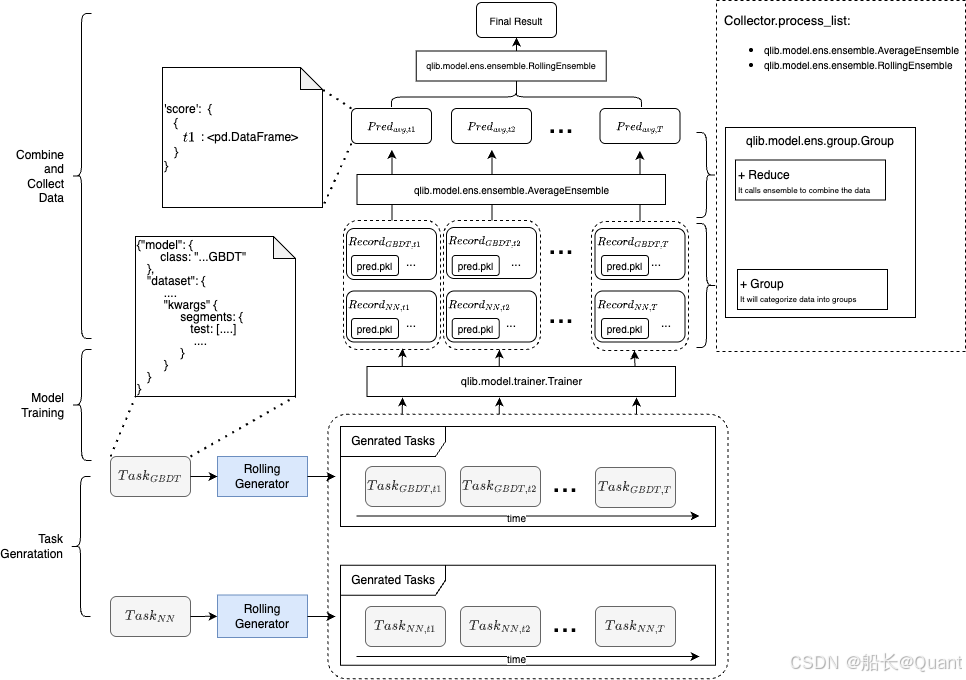
一、核心功能概述
QLib任务管理系统提供完整的工作流自动化解决方案,包含四大核心组件:
- 任务生成(Task Generating)
- 任务存储(Task Storing)
- 任务训练(Task Training)
- 结果收集(Task Collecting)
支持不同时间段/损失函数/模型的自动任务生成与管理,适用于在线服务场景
二、任务生成(Task Generating)
2.1 核心类
python
class qlib.workflow.task.gen.TaskGen # 任务生成基类
class qlib.workflow.task.gen.RollingGen # 时间窗口滚动生成器2.2 核心方法
python
@abstract
def generate(task: dict) -> List[dict]:
"""基于任务模板生成衍生任务
Parameters:
task - 基础任务模板(字典格式)
Returns:
生成的任务列表
"""2.3 典型应用场景
- 时间窗口滚动:输入基础模板+滚动步数 → 输出不同时间段的衍生任务
- 损失函数测试:输入基础模板+损失函数列表 → 输出不同损失函数的任务集
三、任务存储(Task Storing)
3.1 MongoDB配置
python
from qlib.config import C
C["mongo"] = {
"task_url": "mongodb://localhost:27017/", # MongoDB连接地址
"task_db_name": "rolling_db" # 数据库名称
}3.2 任务管理器(TaskManager)
python
class qlib.workflow.task.manage.TaskManager(task_pool: str)3.2.1 核心方法
python
create_task(task_def_l, dry_run=False) # 批量创建任务
fetch_task(query={}, status='waiting') # 查询获取任务
commit_task_res(task, res, status='done') # 提交任务结果
task_stat(query={}) # 统计任务状态分布
reset_waiting(query={}) # 重置运行中任务为等待状态3.2.2 任务状态机
text
STATUS_WAITING → STATUS_RUNNING → STATUS_PART_DONE → STATUS_DONE3.3 命令行工具
bash
python -m qlib.workflow.task.manage -t <pool_name> wait # 等待任务完成
python -m qlib.workflow.task.manage -t <pool_name> task_stat # 查看任务统计四、任务训练(Task Training)
4.1 核心执行函数
python
qlib.workflow.task.manage.run_task(
task_func: Callable,
task_pool: str,
query: dict = {},
force_release: bool = False,
before_status: str = 'waiting',
after_status: str = 'done',
**kwargs
)4.2 训练器(Trainer)
python
class qlib.model.trainer.Trainer # 即时训练器
class qlib.model.trainer.DelayTrainer # 延迟训练器
# 主要方法
train(tasks: list) → list # 开始训练
end_train(models: list) → list # 结束训练
is_delay() → bool # 判断训练器类型4.3 训练器类型对比
| 特性 | TrainerR | TrainerRM |
|---|---|---|
| 任务管理 | 基础方式 | 基于TaskManager |
| 适用场景 | 简单任务列表 | 需要生命周期管理 |
五、结果收集(Task Collecting)
5.1 收集流程
text
Collector → Group → Ensemble5.2 核心组件
- Collector:收集处理结果(合并/分组等)
- Group:按规则分组结果
- Ensemble:集成处理分组结果
5.3 常用集成方法
python
AverageEnsemble # 跨模型结果平均
RollingEnsemble # 时间窗口滚动集成六、配置注意事项
- MongoDB连接必须在初始化时配置
- 需要预先设置mlruns路径用于结果收集
- 任务状态转换需遵循严格的状态机规则
- 使用safe_fetch_task保证线程安全
七、典型工作流
WAITING RUNNING 任务生成 存储到MongoDB 状态检查 任务训练 结果提交 结果收集 等待/重试
Point-in-Time (PIT) 数据库
概述
核心概念
- 点时间数据(Point-in-Time Data):解决历史回测中数据时效性问题,确保在任意历史时间戳获取正确的数据版本,避免因使用最新数据导致的数据泄漏(data leakage)。
- 应用场景:金融历史分析(如财务报告回溯)、交易策略回测(假设每日收盘交易)。
核心价值
- 保证一致性:确保在线交易与历史回测试验的性能一致。
数据准备
工具与流程
- 数据采集
QLib提供爬虫工具(crawler)下载金融数据。 - 格式转换
使用转换工具(converter)将数据转为QLib格式。 - 操作指引
参考脚本路径:scripts/data_collector/pit/README.md,内含下载、转换及额外使用示例。
文件结构设计
数据文件(XXX_a.data或XXX_q.data)
文件结构
- 列定义 (每行对应一条记录,占20字节):
date:数据发布日期(格式:YYYYMMDD)。period:数据所属报告期编码规则:- 年度数据 :整数年份(如
2007)。 - 季度数据 :
<年份><季度序号>(如200704表示2007年第4季度)。
- 年度数据 :整数年份(如
value:特征值。_next:下一个相同报告期数据的字节索引。4294967295表示无后续记录。
示例数据
python
# 数据格式示例(来自XXXX.data文件)
array([(20070428, 200701, 0.090219 , 4294967295),
(20070817, 200702, 0.13933 , 4294967295),
... # 省略部分数据
(20190718, 201902, 0.175322 , 4294967295),
(20191016, 201903, 0.25581899, 4294967295)],
dtype=[('date', '<u4'), ('period', '<u4'), ('value', '<f8'), ('_next', '<u4')])索引文件(XXX_a.index)
文件结构
- 起始索引
首行为起始年份(如2007)。 - 字节索引数组
记录每个报告期首次更新的字节位置(按升序排列)。
示例索引
python
# 索引文件结构示例(来自XXXX.index文件)
array([ 0, 20, 40, ..., 4294967295], dtype=uint32)关键特性与约束
数据排列规则
- 按日期升序 :数据文件中的记录按
date字段升序排列。
文件名约定
- 年度数据 :
XXX_a.data(如财务年度报告)。 - 季度数据 :
XXX_q.data(如季度财务数据)。
已知限制
- 适用范围
当前设计主要支持年度/季度周期性数据(如财务报表),适用于多数市场基础因子。 - 性能瓶颈
PIT计算逻辑尚未优化,存在显著性能提升空间。 - 编码约束
依赖文件名标识数据类型(_a或_q后缀),需严格遵循命名规范。
设计原理补充
数据查询优化
- 索引文件作用:通过预记录首次更新的字节位置,加速按报告期查询数据的效率。
- _next字段逻辑 :
若同一报告期存在多次更新(如修正数据),_next指向下一条记录的字节位置,形成链式结构。
特殊值说明
- _next = 4294967295:表示当前记录是该报告期的最终版本,无后续更新。