序
- 最近的工作涉及到数据引擎查询 DSL 设计,正好找到 Antlr。
- 那些繁琐的词法分析 、语法分析 工作全部由
Antlr搞定,即使你不懂编译原理,也不能阻碍你使用 Antlr 开发自己的小语言。
概述: Antlr
简介
- Antlr 是由美国旧金山大学教授 Terence Parr 于 1989 年发布,到现在已经 30 年。
- Antlr4 非常稳定,生成的代码性能也非常高。你熟悉的Hive SQL,Hibernate SQL等都是使用Antlr来进行分析的。
- Antlr 当前版本 4.7.2
ANTLRv4是一款功能强大的语法分析器生成器 ,可以用来读取、处理、执行和转换结构化文本 或二进制文件。
它被广泛应用于学术界和工业界构建各种语言、工具和框架。
- 其从称为文法 的一种形式化的语言描述 中,
ANTLR框架 生成该语言的语法分析器。
- 生成的语法分析器 可以自动构建 【语法分析树】------表示文法如何匹配输入的数据结构。
ANTLR还可以自动生成【树遍历器】,你可以用它来访问那些树的节点,以执行特定的代码。
ANTLRv4的语法分析器 使用一种新的称为Adaptive LL(*)或ALL(*)的语法分析技术 ,它可以在生成的语法分析器 【执行前】在运行时 【动态地】而不是静态地执行文法分析。
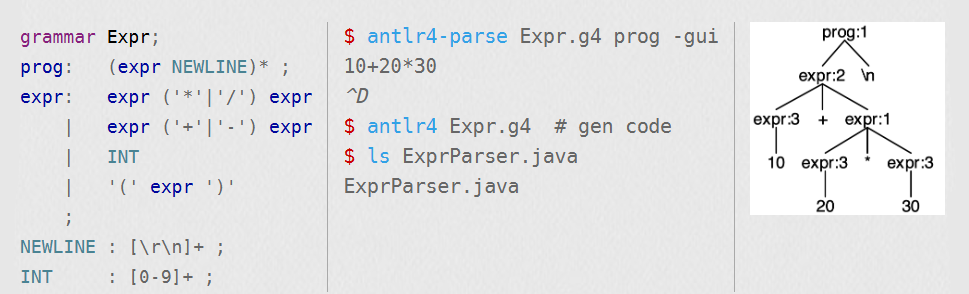
ANTLRv4极大地简化了匹配句法结构(如算术表达式)的文法规则。- 对于传统的自顶向下的语法分析器生成器来说,识别表达式的最自然的文法是无效的,ANTLR v4则不然,你可以使用像下面这样的规则来匹配表达式:
antlr
expr : expr '*' expr
| expr '+' expr
| INT
;像
expr这样的自引用规则 是递归的 且是左递归 的,因为它的可选项 中至少有一个立即引用它自身。
ANTLRv4会自动地将左递归规则 (例如expr)重写为非左递归等价物 ,唯一的约束 是左递归必须是直接的,即那些规则立即引用它们自身。
- Slogan
ANTLR (ANother Tool for Language Recognition) is a powerful parser generator for reading, processing, executing, or translating structured text or binary files.
ANTLR(ANother Tool for Language Recognition)是一个强大的解析器生成器,用于读取、处理、执行或翻译结构化文本或二进制文件。
- URL
- 开源情况
- 开源协议:BSD-3 License
- 统计数据
txt
20250427 : 17.9k star / 3.3k fork核心概念
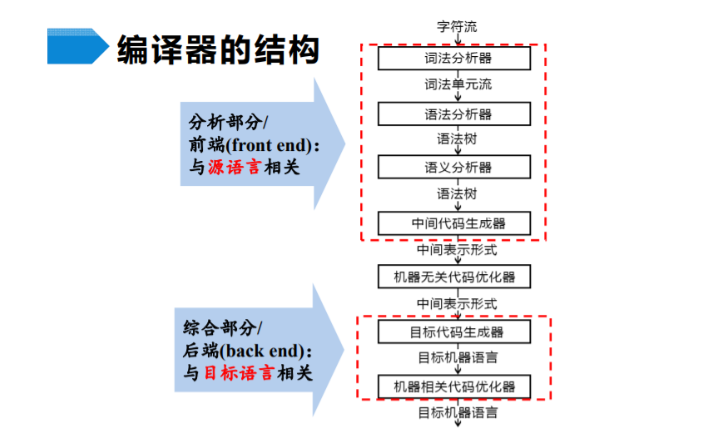
编译
- 从计算机编译原理 学科的角度来讲,编译 就是将高级语言程序 转换成汇编语言程序 /及其语言程序的过程。

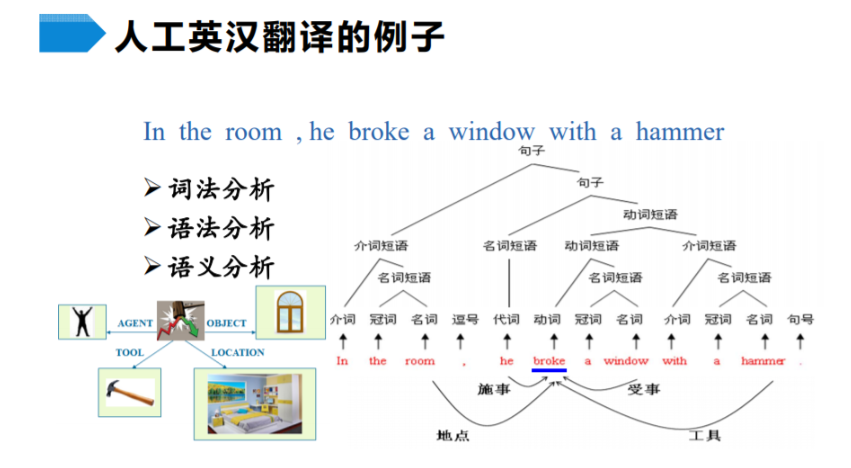
编译 ,说白了就是翻译,对比精细的人工英译汉的步骤:
- 词法分析:分析词性:每个词属于名词?形容词?动词?介词...
- 语法分析:分析各种介词短语、名词短语、动词短语...
- 语义分析 :以上两个步骤的意义就是为语义分析 做铺垫,通过将语句 展开成树的形式 (如下图),可以最终根据根节点 分析出整个句子的意思是什么。
编译的步骤也和人工翻译是一样的。
编译器的结构
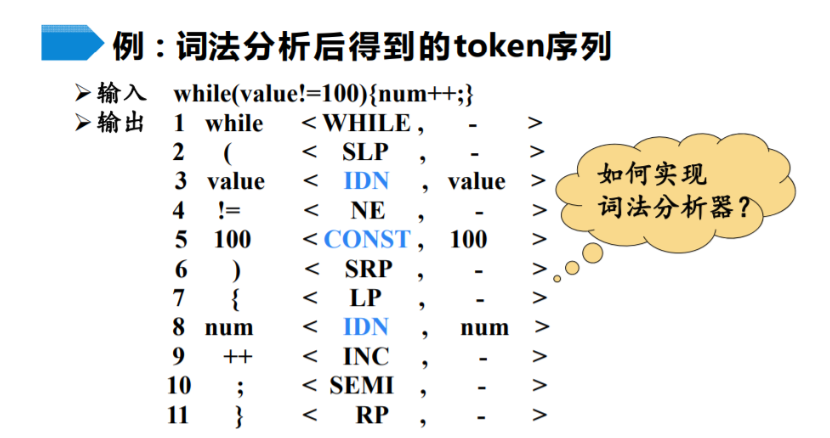
词法分析

- 词法单元形式:二元组token:
<种别码,属性值> - 对种别码的解释
- 一词一码:就是说,每个不同的词分别使用一个种别码,比如:
shell
if: <IF, >
program: <PROGRAM, >
while: <WHILE, >
- 多词一码:标识符是程序员编程时设置的。
我们为不能枚举所有标识符,因此将所有标识符归为一个种别码 。
由于多个词对应一个种别码,因此在同一种别码间需要另外设置属性值来标识不同的属性:(变量名?数组名?常量?)或者(整型?浮点型?字符型?...)
语法分析
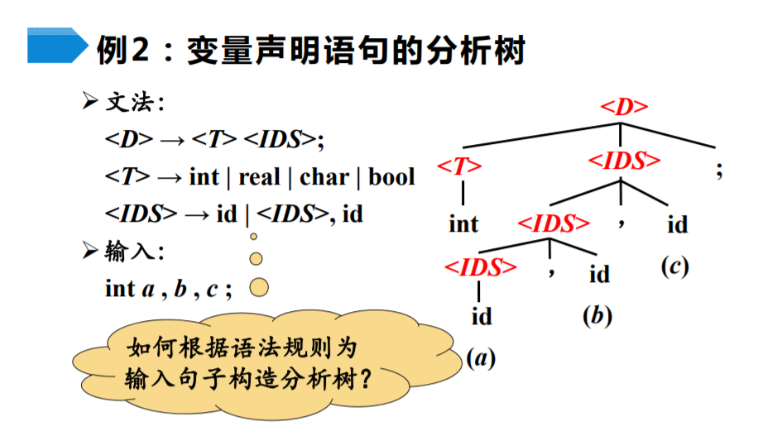
- 解释:
<D>是一条声明语句,<T>是数据类型,|表示"或"的关系,<IDS>是Identify Sequence标识序列。
对比下面的输入语句:
- 整条语句
<D>: int a, b, c; - 数据类型
<T>: int - 标识序列
<IDS>:a, b, c;
语义分析
- 主要做两件事:收集标识符的属性信息 和 对语义的检查(检查合法性)


核心功能与特性
-
词法分析;
-
语法分析;
-
按照指定的语言生成分析器代码;
-
Antlr 支持上下文无关文法
LL(*)。
- 第1个L:从左至右分析输入;
- 第2个L: 使用最左派生分析语法规则;
- 语言支持:
- Antlr 可以生成Java, C#, Python2, Python3, JavaScript, Go, C++, Swift 等语言对应的分析器代码。
- Antlr4 现在支持直接左递归 ,但不支持间接左递归。
txt
直接左递归:
S -> S | Sa
间接左递归:
S -> S | M
M -> S应用场景
定制特定领域语言(DSL)
- 类似hibernate中的HQL,用DSL来定义要执行操作的高层语法,这种语法接近人可理解的语言,由DSL到计算机语言的翻译则通过ANTLR来做,可在ANTLR的结构语言中定义DSL命令具体要执行何种操作。
文本解析
- 可利用
ANTLR解析JSON,HTML,XML,EDIFACT,或自定义的报文格式。
解析出来的信息需要做什么处理也可以在结构文件中定义。
数学计算
- 加减乘除,线性方程,几何运算,微积分等等
Antlr 使用指南
- 那些繁琐的词法分析 、语法分析 工作全部由
Antlr搞定,即使你不懂编译原理,也不能阻碍你使用 Antlr 开发自己的小语言。 - 开发一门新的领域语言(Domain Specification Language,简称
DSL),主要的工作变成了使用可扩展的巴斯科范式 (Extended Backus--Naur Form,简称EBNF)来描述语法。
基础概念
语言模式x4
-
虽然在过去的50年里人们发明了许许多多的编程语言,但是,相对而言,基本的语言模式种类并不多。之所以如此,是因为人们在设计编程语言的时候,倾向于将它们设计成与脑海中的自然语言相类似。
- 我们希望符号按照有效的顺序排列,并且符号之间拥有着特定的依赖关系。举个例子,{(}) 就是不符合语法的,因为符号的顺序不对。
-
单词之间的顺序 和依赖性约束是来自于自然语言的,基本上可以总结成四种抽象的计算机语言模式。
- 序列(sequence):一列元素,比如一行命令
- 选择(choice):在多种可选方案中做选择(备选分支),比如 if else
- 词法符号依赖(token dependency):符号总是成对出现,比如左右括号()
- 嵌套关系 (nested phrase):嵌套的词组是一种自相似的语言结构,即它的子词组也遵循相同的结构。即递归调用本身定义的语法规则,这就是递归规则(自引用规则)。递归规则 包括直接递归 (directly recursive)和间接递归(indirectly recursive)。
通配符
更多见正则表达式
常用的通配符如下所示:
- | 表示或(备选分支)
- * 表示出现0次或以上
- ? 表示出现0次或1次
-
- 表示出现1次或以上
- ~ 表示取反
- 范围运算符:.. 或者 -,比如小写字母的表示:'a'..'z' 或者 a-z
下面通过识别一些常见的词法符号来学习下通配符的用法:
-
关键字、运算符和标点符号:对于关键字、运算符和标点符号,我们无须声明词法规则,只需在语法规则中直接使用单引号将他们括起来即可,比如 'while'、'+'。
-
标识符:一个基本的标识符就是一个由大小写字母组成的字符序列。需要注意的是,下面的ID规则也能够匹配关键字(比如'while')等,上章中我们查看了Parser代码,知道ANTLR是如何处理这种歧义性的------选择所有匹配的备选分支中的第一条。因此,ID标识符应该放在关键字等定义之后。
shell
// 匹配一个或者多个大小写字母
ID : [a-zA-Z]+;- 整数:整数是包括正数和负数的不以零开头的数字。
shell
// 匹配一个整数
INTEGER : '-'?[1-9][0-9]*
| '0'
;- **浮点数:**一个浮点数以一列数字为开头,后面跟着一个小数点,然后是可选的小数部分。浮点数的另外一个格式是,以小数点开头,后面是一串数字。基于以上定义,我们可以得到以下词法规则
shell
FLOAT : DIGIT+ '.' DIGIT* // 1.39、3.14159等
| '.' DIGIT+ // .12 (表示0.12)
;
fragment DIGIT : [0-9]; // 匹配单个数字这里我们使用了一条辅助规则DIGIT,将一条规则声明为fragment可以告诉ANTLR,该规则本身不是一个词法符号,它只会被其他的词法规则使用。
这意味着在语法规则中不能引用它。这也是一条片段规则(fragment rule)。
- 字符串常量:一个字符串就是两个双引号之间的任意字符序列。
shell
// 匹配"......"之间的任意文本
STRING : '"' .*? '"';点号通配符 (
.)匹配任意的单个字符,.*表示匹配零个或多个字符组成的任意字符序列。显然,这是个贪婪匹配,它会一直匹配到文件结束,为解决这个问题,ANTLR通过标准正则表达式 的标记(?后缀)提供了对非贪婪匹配子规则(nongreedy subrule)的支持。
非贪婪匹配的基本含义是:获取一些字符,直到发现匹配后续子规则的字符为止。更准确的描述是,在保证整个父规则完成匹配的前提下,非贪婪的子规则匹配数量最少的字符。
回到我们的字符串常量定义中来,这里的定义其实并不完善,因为它不允许其中出现双引号。为了解决这个问题,很多语言都定义了以 \ 开头的转义序列,因此我们可以使用 "\来对字符串中的双引号进行转义。
shell
STRING : '"' (ESC|.)*? '"';
// 表示\" 或者 \\
fragment ESC : '\\"' | '\\\\';其中,ANTLR语法本身需要对转义字符 \ 进行转义,因此我们需要 \ 来表示单个反斜杠字符。
- 注释和空白字符 :对于注释和空白字符,大多数情况下对于语法分析器 是无用的(Python是一个例外,它的换行符表示一条命令的终止,特定数量的缩进指明嵌套的层级 ),因此我们可以使用ANTLR的
skip指令来通知词法分析器将它们丢弃。
shell
// 单行注释(以//开头,换行结束)
LINE_COMMENT : '//' .*? '\r'?'\n' -> skip;
// 多行注释(/* */包裹的所有字符)
COMMENT : '/*' .*? '*/' -> skip;词法分析器 可以接受许多 -> 操作符之后的指令,skip只是其中之一。
例如,如果我们需要在语法分析器中对注释做一定处理,我们可以使用channel指令将某些词法符号送入一个"隐藏的通道"并输送给语法分析器。
大多数编程语言将空白符 看成是词法符号间的分隔符,并将他们忽略。
shell
// 匹配一个或者多个空白字符并将他们丢弃
WS : [ \t\r\n]+ -> skip;至此,我们已经学会了通配符的用法和如何编写常见的词法规则,下面我们将学习如何编写语法规则。
语法
- 语法 (
grammar)包含了一系列描述语言结构的规则。
这些规则不仅包括描述语法结构的规则,也包括描述标识符和整数之类的词汇符号(词法符号Token)的规则,即包含词法规则和语法规则。
注意:语法分析器的规则 必须以小写字母 开头,词法分析器的规则 必须以大写字母开头。
- 语法文件声明
语法由一个为该语法命名的头部定义和一系列可以互相引用的语言规则组成。grammar关键字用于语法文件命名,需要注意的是,命名须与文件名一致。
- 语法导入
前两章的例子中,我们都是将词法规则 和语法规则 放在一个语法文件中,然而一个优雅的写法是将词法规则和语法规则进行拆分。lexer grammar关键字用于声明一个词法规则文件。如下是一个通用的词法规则文件定义。
shell
// 通用的词法规则,注意是 lexer grammar
lexer grammar CommonLexerRules;
// 匹配标识符(+表示匹配一次或者多次)
ID : [a-zA-Z]+;
// 匹配整数
INT : [0-9]+;
// 匹配换行符(?表示匹配零次或者一次)
NEWLINE : '\r'?'\n';
// 丢弃空白字符
WS : [ \t]+ -> skip;- 然后,我们只需要
import关键字,就可以轻松的将词法规则进行导入。
如下是一个计算器的语法文件。
shell
grammar LibExpr;
// 引入 CommonLexerRules.g4 中全部的词法规则
import CommonLexerRules;
prog : stat+;
stat : expr NEWLINE # printExpr
| ID '=' expr NEWLINE # assign
| NEWLINE # blank
;
expr : expr op=('*' | '/') expr # MulDiv
| expr op=('+' | '-') expr # AddSub
| INT # int
| ID # id
| '(' expr ')' # parens
| 'clear' # clear
;
// 为上诉语法中使用的算术符命名
MUL : '*';
DIV : '/';
ADD : '+';
SUB : '-';- 备选分支命名(标签)
- 如果备选分支上面没有标签,ANTLR就只会为每条规则生成一个方法(监听器和访问器中的方法,用于对不同的输入进行不同的操作)。
- 为备选分支添加一个标签,我们只需要在备选分支的右侧,以 # 开头,后面跟上任意的标识符即可,如上所示。
- 需要注意的是,为一个规则的备选分支添加标签,要么全部添加,要么全部不添加。
- 优先级
在第二章中我们讲述了ANTLR是如何处理歧义性语句(二义性文法)的:选择所有匹配的备选分支中的第一条。即ANTLR通过优先选择位置靠前的备选分支来解决歧义性问题,这也隐式地允许我们指定运算符优先级。例如,在上诉的例子中,乘除的优先级会比加减高。因此,ANTLR在解决1+2*3的歧义问题时,会优先处理乘法。
- 结合性
默认情况下,ANTLR是左结合的,即将运算符从左到右地进行结合。但是有些情况下,比如指数运算符是从右向左结合的。123应该是3(21)而不是(32)1。我们可以使用assoc来手动指定结合性。
shell
expr : expr '^' <assoc=right> expr // ^ 是右结合的
| INT
;注意,在ANTLR4.2之后,
<assoc=right>需要放在备选分支的最左侧,否则会收到警告。
shell
expr : <assoc=right> expr '^' expr // ^ 是右结合的
| INT
;- 词法分析器与语法分析器的界限
由于ANTLR的词法规则 可以使用递归 ,因此从技术角度上看,词法分析器可以和语法分析器一样强大。
这意味着我们甚至可以在词法分析器中匹配语法结构。或者,在另一个极端,我们可以把字符当作词法符号,然后使用语法分析器去分析整个字符流(这种被称为无扫描的语法分析器scannerless parser)。
因此,我们需要去界定词法分析器和语法分析器具体需要处理的界限。
- 在词法分析器中匹配并丢弃任何语法分析器无须知晓的东西。例如,需要在词法分析器中识别和扔掉像空格和注释诸如此类的东西。否则,语法分析器必须经常查看是否有空格或注释在词法符号之间。
- 在词法分析器中匹配诸如标志符、关键字、字符串和数字这样的常用记号。语法分析器比词法分析器有更多的开销,因此我们不必让语法分析器承受把数字放在一起识别成整数的负担。
- 将语法分析器不需要区分的词法结构归为同一个词法符号类型。例如,如果我们的应用把整数和浮点数当作同一事物对待,那就把它们合并成词法符号类型NUMBER。
- 将任何语法分析器可以以相同方式处理的实体归为一类。例如,如果语法分析器不在乎XML标签里的内容,词法分析器可以把尖括号中的所有东西合并成一个单独的名为TAG的词法符号类型。
- 另一方面,如果语法分析器需要把一种类型的文本拆开处理,那么词法分析器就应该将它的各个组成部分作为独立的词法符号输送给语法分析器。例如,如果语法分析器需要处理IP地址中的元素,那么词法分析器应该将IP的各个组成部分(整数和点)作为独立的词法符号送入语法分析器。
小结
本节我们学习了如何编写语法文件,但是单独的语法并没有用处,而与其相关的语法分析器仅能告诉我们输入的语句是否遵循该语言的规范。
为了构建一个语言类应用程序,这是不够的,我们还需要相应的"动作"去执行语法规则。而这就是下一章的内容------监听器和访问器。
关键原理:Antlr 的语法分析
总体流程
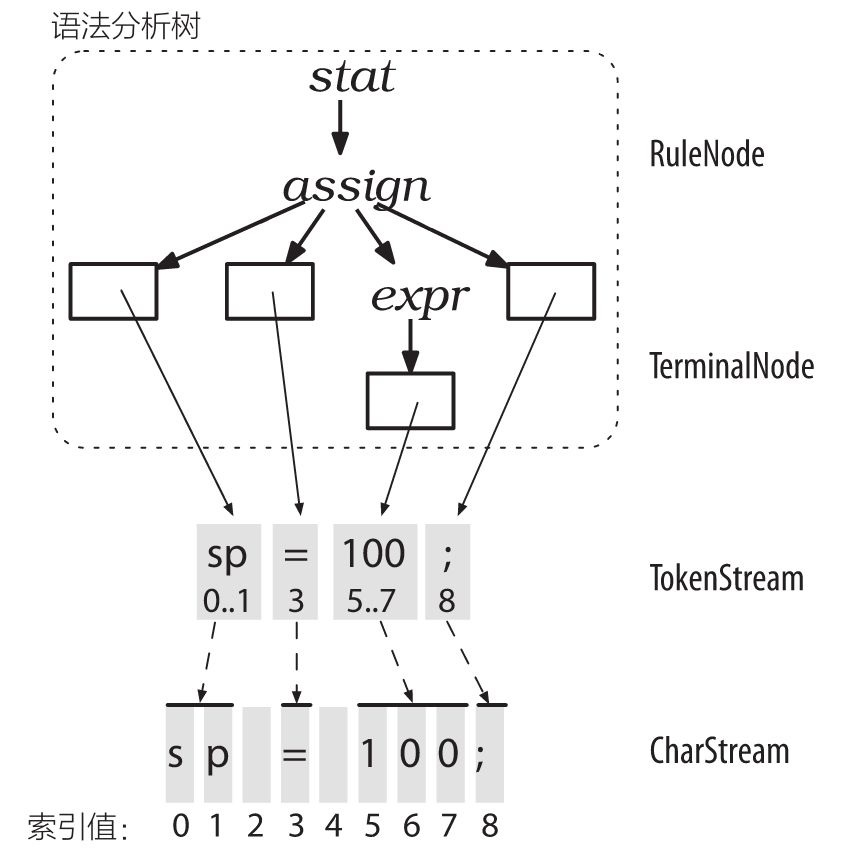
ANTLR语法分析一般分为2个阶段:
- 词法分析阶段 (lexical analysis)
对应的分析程序叫做
lexer,负责将符号 (token)分组成符号类(token class or token type)
- 解析阶段(parse)
根据词法 ,构建出一棵分析树 (parse tree)或叫语法树(syntax tree)
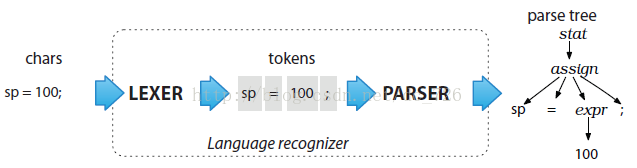
ANTLR的直观印象------------就像是在走迷宫,或者说是电路板更准确,最终只有一条最优路 可通达开始与结束,中间的各种叉路与开关,就是我们所编写的规则
下面是一博友编写的一个SQL查询的简单实现,截取一部分图示:
语法定义文件(Grammer Definition File) | 语法定义 := Antlr 元语言
因此,为了让词法分析 和语法分析 能够正常工作,在使用
Antlr 4的时候,需要定义语法 (grammar),这部分就是 Antlr 元语言。
总体结构
antlr
/** Optional javadoc style comment */
grammar Name;
options {...}
import ... ;
tokens {...}
channels {...} // lexer only
@actionName {...}
rule1 // parser and lexer rules, possibly intermingled
...
ruleNAntlr 语法定义文件 : Calculator.g4
- 首先,要了解 antlr4 本身的定义
grammar的语法。相对比较简单。我们以计算器的例子为例,简单讲解其中的概念。
antlr
// file: Calculator.g4
grammar Calculator;
line : expr EOF ;
expr : '(' expr ')' # parenExpr
| expr ('*'|'/') expr # multOrDiv
| expr ('+'|'-') expr # addOrSubstract
| FLOAT # float
;
WS : [ \t\n\r]+ -> skip;
FLOAT : DIGIT+ '.' DIGIT* EXPONET?
| '.' DIGIT+ EXPONET?
| DIGIT+ EXPONET?
;
fragment DIGIT : '0'..'9' ;
fragment EXPONET : ('e'|'E') ('+'|'-')? DIGIT+ ;
- 第1行,定义了
grammar的名字,名字需要与文件名对应- 接下来的
line和expr就是定义的语法 ,会使用到下方定义的词法注意
#后面的名字,是可以在后续访问和处理的时候使用的。一个语法有多种规则的时候可以使用 | 来进行配置。
- 在
expr这行,我们注意到四则运算 分为了两个非常相似的语句,这样做的原因是为了实现优先级,乘除是优先级高于加减的。WS定义了空白字符 ,后面的skip是一个特殊的标记,标记空白字符会被忽略。FLOAT是定义的浮点数 ,包含了整数,与编程语言中的浮点数略有不同,更类似Number的定义。- 最后的
fragment定义了两个在词法定义中使用到的符号。
在语法定义的文件 中,大部分的地方使用了正则表达式。
生成语法定义文件
- 配置 antlr4 工具,先从官网下载 Antlr4 的 jar 包,点击下载地址进行下载。
参见本文的安装章节 (
antlr-{version}-complete.jar)
shell
alias antlr4="java -jar /path/to/antlr-4.7.2-complete.jar"- 通过命令行工具可以生成 lexer、parser、visitor、listener 等文件。
visitor是默认不生成的,需要带上参数-visitor。
shell
$ antlr4 -visitor Calculator.g4生成的文件如下:
shell
Calculator.interp
CalculatorBaseListener.java
CalculatorLexer.interp
CalculatorLexer.tokens
CalculatorParser.java
Calculator.tokens
CalculatorBaseVisitor.java
CalculatorLexer.java
CalculatorListener.java
CalculatorVisitor.java使用 Visitor
Visitor的使用是最为简单方便的,继承CalculatorBaseVisitor类即可,内部的方法与 g4 文件定义相对应,对照看即可理解。
java
public class MyCalculatorVisitor extends CalculatorBaseVisitor<Object> {
@Override
public Object visitParenExpr(CalculatorParser.ParenExprContext ctx) {
return visit(ctx.expr());
}
@Override
public Object visitMultOrDiv(CalculatorParser.MultOrDivContext ctx) {
Object obj0 = ctx.expr(0).accept(this);
Object obj1 = ctx.expr(1).accept(this);
if ("*".equals(ctx.getChild(1).getText())) {
return (Float) obj0 * (Float) obj1;
} else if ("/".equals(ctx.getChild(1).getText())) {
return (Float) obj0 / (Float) obj1;
}
return 0f;
}
@Override
public Object visitAddOrSubstract(CalculatorParser.AddOrSubstractContext ctx) {
Object obj0 = ctx.expr(0).accept(this);
Object obj1 = ctx.expr(1).accept(this);
if ("+".equals(ctx.getChild(1).getText())) {
return (Float) obj0 + (Float) obj1;
} else if ("-".equals(ctx.getChild(1).getText())) {
return (Float) obj0 - (Float) obj1;
}
return 0f;
}
@Override
public Object visitFloat(CalculatorParser.FloatContext ctx) {
return Float.parseFloat(ctx.getText());
}
}CalculatorClient
实现了 visitor 之后,就可以完成一个简单的计算器了。
java
import org.antlr.v4.runtime.ANTLRInputStream;
import org.antlr.v4.runtime.CommonTokenStream;
public class CalculatorClient {
public static void main(String[] args) {
String query = "3.1 * (6.3 - 4.51) + 5 * 4";
CalculatorLexer lexer = new CalculatorLexer(new ANTLRInputStream(query));
CalculatorParser parser = new CalculatorParser(new CommonTokenStream(lexer));
CalculatorVisitor visitor = new MyCalculatorVisitor();
System.out.println(visitor.visit(parser.expr())); // 25.549
}
}安装
ANTLR是由Java写成的。
所以,在安装
ANTLR前必须保证已安装有Java 1.6或以上版本。你可以到这里下载
ANTLR的最新版本,或者也可使用命令行工具下载:
shell
$ curl -O https://www.antlr.org/download/antlr-4.7.2-complete.jar- 归档文件 包含运行
ANTLR工具 的所有必要依赖 ,以及编译和执行 由ANTLR生成的识别器所需的运行库。
简而言之,就是
ANTLR工具将文法 转换成识别程序 ,然后识别程序 利用ANTLR运行库 中的某些支持类识别由该文法描述的语言的句子。此外,该归档文件 还包含2个支持库:
TreeLayout(一个复杂的树布局库)
StringTemplate(一个用于生成代码和其它结构化文本的模板引擎)。
- 现在来测试下ANTLR工具是否工作正常:
shell
$ java -jar antlr-4.7.2-complete.jar # 启动 org.antlr.v4.Tool如果正常的话会看到以下帮助信息:
shell
ANTLR Parser Generator Version 4.7.1
-o ___ specify output directory where all output is generated
-lib ___ specify location of grammars, tokens files
-atn generate rule augmented transition network diagrams
-encoding ___ specify grammar file encoding; e.g., euc-jp
-message-format ___ specify output style for messages in antlr, gnu, vs2005
-long-messages show exception details when available for errors and warnings
-listener generate parse tree listener (default)
-no-listener don't generate parse tree listener
-visitor generate parse tree visitor
-no-visitor don't generate parse tree visitor (default)
-package ___ specify a package/namespace for the generated code
-depend generate file dependencies
-D<option>=value set/override a grammar-level option
-Werror treat warnings as errors
-XdbgST launch StringTemplate visualizer on generated code
-XdbgSTWait wait for STViz to close before continuing
-Xforce-atn use the ATN simulator for all predictions
-Xlog dump lots of logging info to antlr-timestamp.log
-Xexact-output-dir all output goes into -o dir regardless of paths/package每次运行
ANTLR工具都要输入这么长的命令是不是有些痛苦?写个脚本来解放我们的手指吧!
shell
#!/bin/sh
java -cp antlr-4.7.1-complete.jar org.antlr.v4.Tool $*把它保存为
antlr,以后就可以使用下列命令来运行ANTLR工具:
shell
$ ./antlr案例实践
Antlr4提供了大量的官方 grammar 示例,包含了各种常见语言,非常全面,提供了非常全面的学习教材
CASE Twitter搜索 + ANTLR
- Twitter搜索使用
ANTLR进行语法分析,每天处理超过20亿次查询
CASE Hadoop生态(Hive/Pig/...) + ANTLR
- Hadoop生态系统中的Hive、Pig、数据仓库和分析系统所使用的语言都用到了
ANTLR
CASE ANTLR + 法律文本分析
Lex Machina将ANTLR用于分析法律文本
CASE Oracle SQL工具 + ANTLR
- Oracle公司在SQL开发者IDE和迁移工具中使用了ANTLR
CASE NetBeans IDE + ANTLR => 解析 C++ 源码
- NetBeans公司的IDE使用ANTLR来解析C++
CASE Hibernate ORM框架 + ANTLR => 处理HQL语言
- Hibernate对象-关系映射框架(ORM)使用ANTLR来处理HQL语言
CASE 简单的计算器
计算器的语法设计
shell
grammar Calc;
start: input
input: setvariable NL input
| expression NL? EOF #calculate
;
setvariable : ID '=' expression #setvariable
;
expression : expression POW expression #pow
| expression (MUL | DIV) expression #muldiv
| expression (ADD | SUB) expression #addsub
| '(' expression ')' #expr
| ID #id
| NUMBER #num
;
POW : '^'
ADD : '+'
SUB: '-'
MUL: '*'
DIV : '/'
NL : '\r' ? '\n'
ID : [a-zA-Z_]+
NUMBER : [0-9]+- 写在前面的分支优先级高,因此指数运算优先级高于乘除运算,乘除运算优先级高于加减运算。
- 乘除写在一个分支,加减写在一个分支,表示它们具有相同的优先级。
比如: 两个表达式
shell
a * b / c
a / b * c- 由于
*和/具有优先级相同,先出现的先匹配,因此构造的语法树分别如下:
txt
a * b / c 对应的语法分析树:
expr
/ | \
expr / c
/ | \
a * b
a / b * c 对应的语法分析树:
expr
/ | \
expr * c
/ | \
a / b- 上面的计算器语法可以支持如表达式:
shell
a = 2
b = a ^ 2 + a
c = a + b * c / a
a + b * c / (a + c)计算器的实现
如果使用
Java来开发,自然首选 IDEA。
-
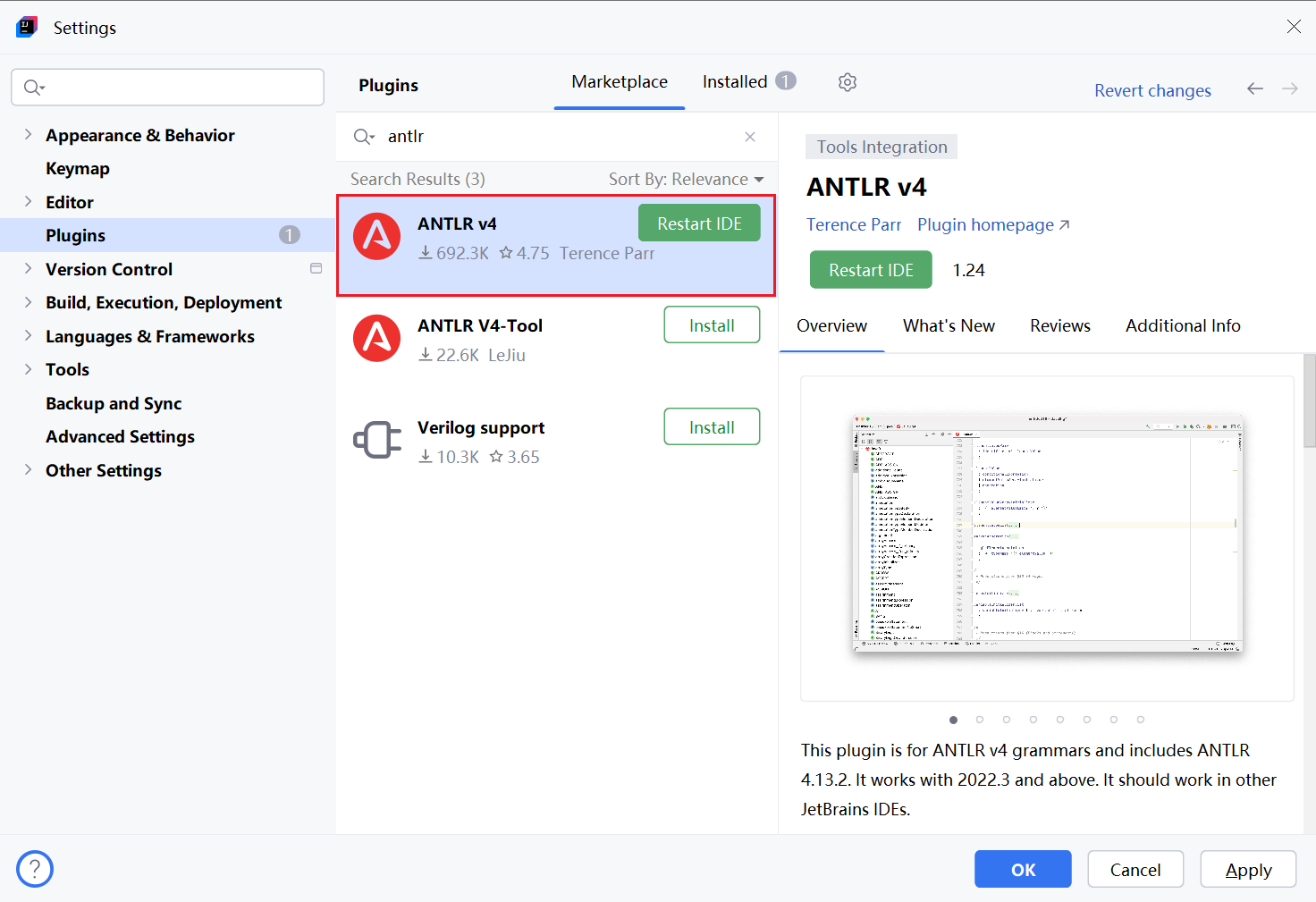
IDE 搜索安装插件
Antlr v4;(可选步骤) -
创建一个 Java 项目;
-
创建一个语法描述文件:Calc.g4,名字需要跟第1行的gammar Calc对应,用于生成分析器代码类的前缀;
-
在 Calc.g4 文件上右键,点击 Generate ANTLR Recognizer(IDE插件),就会生成Java语言的分析器代码;
此插件的本质是调用
antlr-{version}-complete.jar包。
- 默认只生成
Listenner方式遍历类,可通过Configuration配置同时生成Visitor方式遍历类;
-
Listenner方式使用深度优先的遍历方式,针对语法树每一个节点都会有一个进入方法( enterXXX ),一个退出方法( exitXXX ); -
Visitor 有更好的灵活性,你可以完全控制整个遍历过程,哪些分支不用遍历,哪些分支需要遍历等;
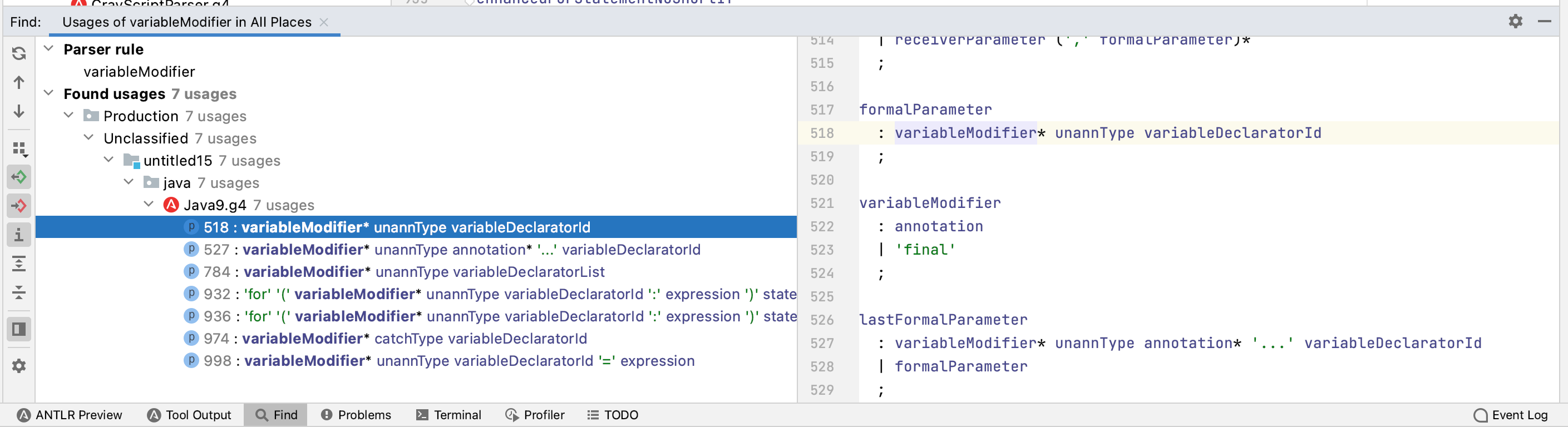
-
你可以基于生成的词法分析类 CalcLexer,语法分析类 CalcPaser,用来测试是否支持你编写的表达式。
-
为了实现计算,你还需要继承
Listenner或者Visitor来实现计算过程。
这个代码相对比较简单,就不贴出来了。
亦可参见本文上述所指的
MyCalculatorVisitor
Y 推荐文献
- Antlr
- https://www.antlr.org 【推荐】
- Github
- https://github.com/antlr/grammars-v4 (大量语法文件例子)
- Maven
- The Definitive ANTLR4 Reference
- Demo
-
IDEA 插件 :
Antlr v4