🔥个人主页:胡萝卜3.0****
📖个人专栏:************************************************************************************************************************************************************************************************************************************************************《C语言》、《数据结构》 、《C++干货分享》、LeetCode&牛客代码强化刷题****************************************************************************************************************************************************************************************************************************************************************
⭐️人生格言:不试试怎么知道自己行不行
🎥胡萝卜3.0🌸的简介:


目录
[1.1 编译的过程](#1.1 编译的过程)
[1.1.1 阶段1:预处理](#1.1.1 阶段1:预处理)
[1.1.2 阶段2:编译](#1.1.2 阶段2:编译)
[1.1.3 阶段3:汇编](#1.1.3 阶段3:汇编)
[1.1.4 阶段4:链接](#1.1.4 阶段4:链接)
[1.1.5 一键编译运行程序](#1.1.5 一键编译运行程序)
[1.2 一般程序的构建构成](#1.2 一般程序的构建构成)
[1.3 条件编译](#1.3 条件编译)
[1.4 为何一定是这四个步骤?](#1.4 为何一定是这四个步骤?)
[1.5 初步了解链接](#1.5 初步了解链接)
[1.5.1 初识库](#1.5.1 初识库)
[1.5.2 借书与买书:感性理解动态库与静态库](#1.5.2 借书与买书:感性理解动态库与静态库)
前言
在Linux下写C/C++程序,GCC就像你的厨房必备菜刀------每个程序员都在用,但大部分人只拿来切个黄瓜,不知道它还能雕花。
很多人对GCC的了解就停在:
bash
gcc hello.c -o hello
./hello看到"Hello World"出来就完事了。
这篇文章会告诉你:
-
编译的四个步骤:就像做菜要经过洗菜、切菜、炒菜、装盘,GCC编译也有四步,每步在干嘛
-
静态库 vs 动态库:就像自带调料包 vs 用公共调料台,各有什么优缺点
不再只是"让程序能跑",而是"让程序跑得更好"------这才是真正的程序员进阶之路。
一、编译四部曲:预处理、编译、汇编、链接的完整解析
我们知道编译器分为:
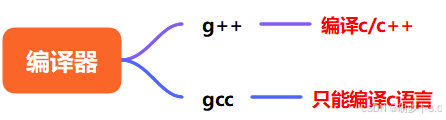
那究竟什么是编译器呢?
ok,编译器就是把源文件翻译成为可执行二进制文件------编译的过程
接下来,我们将通过一下几步完成这篇文章的学习:

1.1 编译的过程
编译过程分为:
- 预处理
- 编译
- 汇编
- 链接
1.1.1 阶段1:预处理
- **核心任务:**头文件展开、去注释、宏替换、条件编译;
头文件展开:把头文件相关内容拷贝到源文件中,这是头文件和源文件合并的过程,编译器只有在预处理的时候需要头文件
- 关键选项:-E ------预处理做完就停下;
- 输出文件:.i 后缀(预处理后的C文件)
- 实操命令
bash
gcc -E .c(源文件(C)) -o .i(生成的.i文件(还是C))
bash
[carrot@VM-0-16-centos ~]$ touch code.c
[carrot@VM-0-16-centos ~]$ vim code.c
[carrot@VM-0-16-centos ~]$ gcc -E code.c -o code.i
[carrot@VM-0-16-centos ~]$ ll
total 32
drwxrwxr-x 2 carrot carrot 4096 Dec 24 16:44 118
-rw-rw-r-- 1 carrot carrot 183 Dec 29 10:08 code.c
-rw-rw-r-- 1 carrot carrot 16982 Dec 29 10:08 code.i
-rw-rw-r-- 1 carrot carrot 827 Dec 26 17:29 install.sh
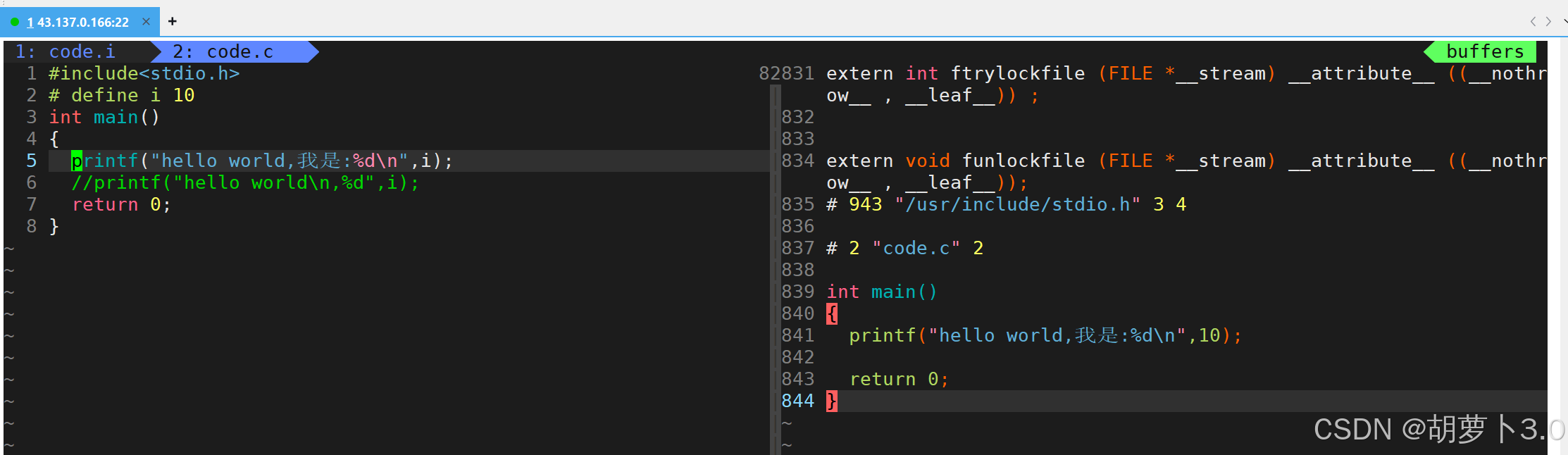
当我们使用vim打开code.i文件时,会发现:code.c文件中的头文件被展开了,宏替换,注释被去掉,完成了条件编译(条件编译后面会解释)
1.1.2 阶段2:编译
编译的过程就是将:C语言转成汇编语言的过程
- **核心任务:**检查语法错误,将预处理后的C语言代码(.i文件)转换成汇编代码;
- 关键选项:-S 仅执行程序的翻译(翻译成汇编语言),做完编译之后就停下来
- 输出文件:.s 后缀(汇编文件)
- 实操命令
bash
gcc -S .i后缀(文件) -o .s(生成的.s汇编文件)
bash
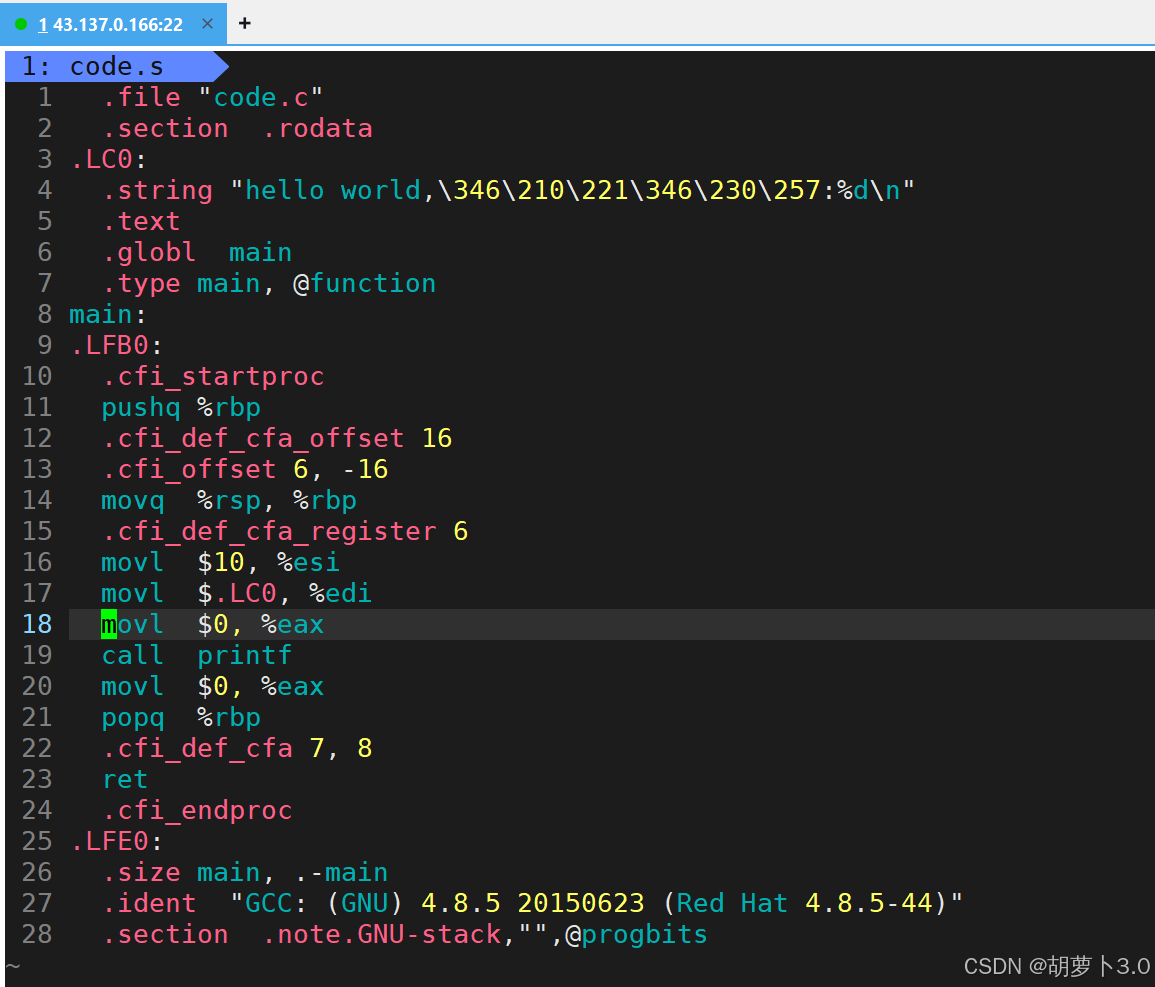
[carrot@VM-0-16-centos ~]$ gcc -S code.i -o code.s
[carrot@VM-0-16-centos ~]$ ll
total 36
drwxrwxr-x 2 carrot carrot 4096 Dec 24 16:44 118
-rw-rw-r-- 1 carrot carrot 132 Dec 29 10:52 code.c
-rw-rw-r-- 1 carrot carrot 16886 Dec 29 10:52 code.i
-rw-rw-r-- 1 carrot carrot 510 Dec 29 10:52 code.s
-rw-rw-r-- 1 carrot carrot 827 Dec 26 17:29 install.sh
bash
gcc -S code.i -o code.s
1.1.3 阶段3:汇编
- 核心任务: 将汇编代码(.s)转换成机器可识别的可重地位二进制目标文件
- 关键选项: -c 开始进行程序的翻译,汇编工作做完,就停下来
- 输出文件: .o/.obj后缀(目标文件或者可重定位二进制目标文件)文件不能被执行
- 实操命令:
bash
gcc -c .s后缀文件 -o .o(要生成的.o目标文件)
bash
[carrot@VM-0-16-centos ~]$ gcc -c code.s -o code.o
[carrot@VM-0-16-centos ~]$ ll
total 40
drwxrwxr-x 2 carrot carrot 4096 Dec 24 16:44 118
-rw-rw-r-- 1 carrot carrot 132 Dec 29 10:52 code.c
-rw-rw-r-- 1 carrot carrot 16886 Dec 29 10:52 code.i
-rw-rw-r-- 1 carrot carrot 1520 Dec 29 11:06 code.o
-rw-rw-r-- 1 carrot carrot 510 Dec 29 10:54 code.s
-rw-rw-r-- 1 carrot carrot 827 Dec 26 17:29 install.sh
bash
[carrot@VM-0-16-centos ~]$ gcc -c code.s -o code.o
1.1.4 阶段4:链接
- 核心任务: 将目标文件(.o)与系统库、第三方库链接,生成可执行文件
- 输出文件: 默认名是a.out可执行文件(可以通过-o指定名称)
- 实操命令:
bash
# 生成指定命名的可执行文件
gcc .o后缀(目标文件) -o .exe(自己命名的可执行文件,一般是以.exe后缀的)
# 直接生成默认的a.out可执行文件
gcc .o后缀文件(目标文件)
bash
[carrot@VM-0-16-centos ~]$ gcc code.o -o code.exe
[carrot@VM-0-16-centos ~]$ ll
total 52
drwxrwxr-x 2 carrot carrot 4096 Dec 24 16:44 118
-rw-rw-r-- 1 carrot carrot 132 Dec 29 10:52 code.c
-rwxrwxr-x 1 carrot carrot 8360 Dec 29 11:15 code.exe
-rw-rw-r-- 1 carrot carrot 16886 Dec 29 10:52 code.i
-rw-rw-r-- 1 carrot carrot 1520 Dec 29 11:06 code.o
-rw-rw-r-- 1 carrot carrot 510 Dec 29 10:54 code.s
-rw-rw-r-- 1 carrot carrot 827 Dec 26 17:29 install.sh
[carrot@VM-0-16-centos ~]$ ./code.exe
hello world,我是:10
[carrot@VM-0-16-centos ~]$ gcc code.o
[carrot@VM-0-16-centos ~]$ ll
total 64
drwxrwxr-x 2 carrot carrot 4096 Dec 24 16:44 118
-rwxrwxr-x 1 carrot carrot 8360 Dec 29 11:17 a.out
-rw-rw-r-- 1 carrot carrot 132 Dec 29 10:52 code.c
-rwxrwxr-x 1 carrot carrot 8360 Dec 29 11:15 code.exe
-rw-rw-r-- 1 carrot carrot 16886 Dec 29 10:52 code.i
-rw-rw-r-- 1 carrot carrot 1520 Dec 29 11:06 code.o
-rw-rw-r-- 1 carrot carrot 510 Dec 29 10:54 code.s
-rw-rw-r-- 1 carrot carrot 827 Dec 26 17:29 install.sh
[carrot@VM-0-16-centos ~]$ ./a.out
hello world,我是:10
一个记忆小技巧:
- ESc:iso
前面为前三个过程的选项,后面为对应的生成文件的后缀!!!
1.1.5 一键编译运行程序
- 方式一:
bash
[carrot@VM-0-16-centos ~]$ touch code.c
[carrot@VM-0-16-centos ~]$ vim code.c
[carrot@VM-0-16-centos ~]$ gcc code.c
[carrot@VM-0-16-centos ~]$ ./a.out
hello bit
hello bit
hello bit
hello bit
hello bit
hello bit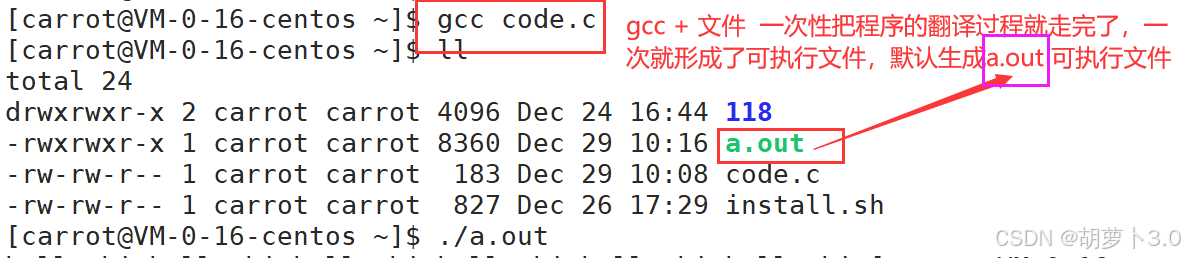
- gcc +文件名:一次性把程序的翻译过程就走完了,一次性就生成可执行文件,默认生成的可执行文件的文件名为a.out
- ./a.out:执行可执行文件
那我们可以改变一下生成的可执行文件的名字吗?当然可以
可以通过-o指定名称,-o 后面必须紧跟要生成的文件名
- 方式二:
bash
[carrot@VM-0-16-centos ~]$ gcc code.c -o code.exe
[carrot@VM-0-16-centos ~]$ ll
total 24
drwxrwxr-x 2 carrot carrot 4096 Dec 24 16:44 118
-rw-rw-r-- 1 carrot carrot 170 Dec 29 10:18 code.c
-rwxrwxr-x 1 carrot carrot 8360 Dec 29 10:26 code.exe
-rw-rw-r-- 1 carrot carrot 827 Dec 26 17:29 install.sh
# ./code.exe 只执行可执行文件code.exe
[carrot@VM-0-16-centos ~]$ ./code.exe
hello bit
hello bit
hello bit
hello bit
hello bit
1.2 一般程序的构建构成
我们可以在Linux中一步到位形成可执行文件(就如上面的样子),但是我们不喜欢这样做,我们更喜欢的是:
- 当有很多源文件的时候,先将源文件编成 .o 文件,然后再把 .o 文件链接成 可执行文件
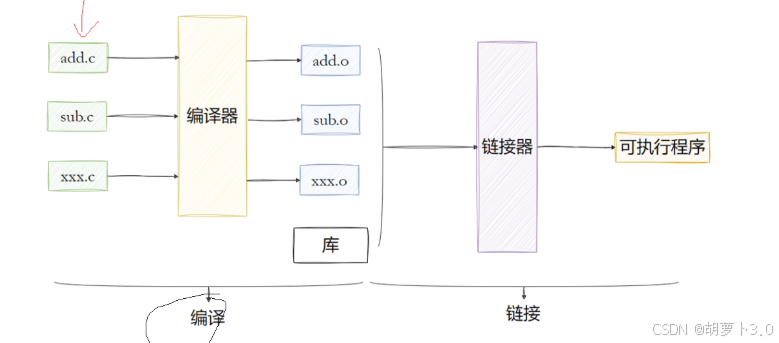
后面常见的步骤是这样的:
bash
[carrot@VM-0-16-centos ~]$ gcc -c code.c
[carrot@VM-0-16-centos ~]$ gcc -o code.exe code.o
[carrot@VM-0-16-centos ~]$ ./code.exe
hello world,我是:10
vs中也是先编成 .o文件,再链接成可执行文件!!!
当有多个.c源文件时,我们可以这么干:
bash
[carrot@VM-0-16-centos ~]$ gcc -c *.c
[carrot@VM-0-16-centos ~]$ gcc *.o -o code.exe
但是真实不是这么干的,后面会说!!!
- 那为什么要这么做呢?
.c文件先编译成 .o目标文件,再链接成可执行.exe文件,这种做法可以提高编译效率!!!
1.3 条件编译
条件编译,我们将通过两个小点进行讲解:
- 看条件编译;
- 谈应用场景
条件编译的代码这里就不详细介绍了,详细请看:预处理详解-CSDN博客
我们写一个简单的条件编译的代码------
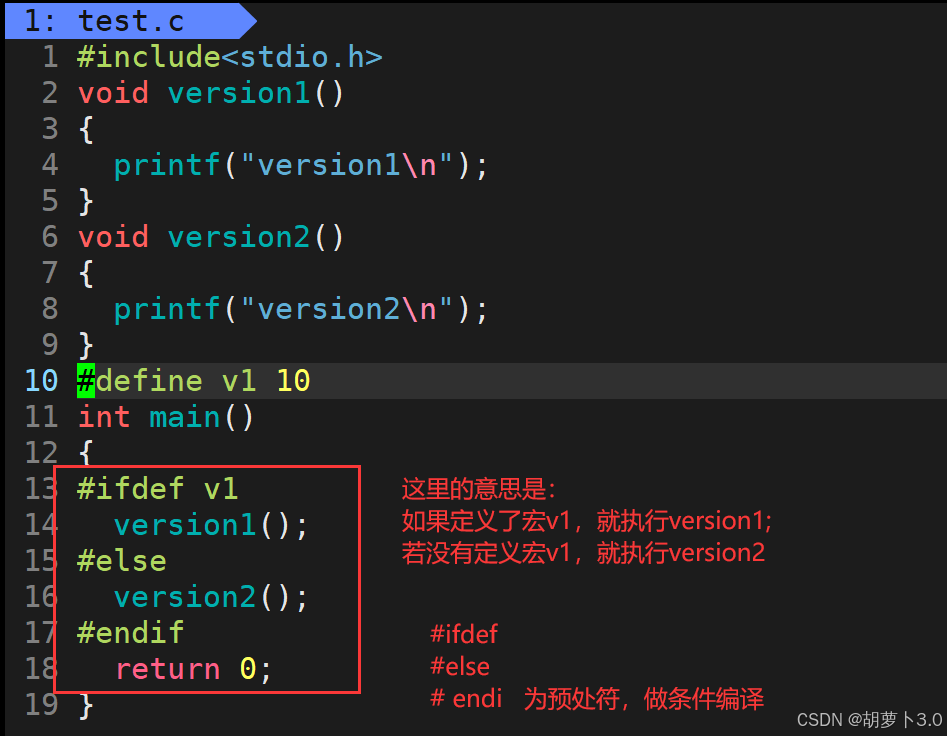
当我们执行代码的时候,条件编译会对代码进行裁剪------
- 如果有#define v1 10 ,只保留version1();
- 如果没有#define v1 10,只保留version2();
这时候,就会uu想说了,博主啊,你凭什么这么说,我又没有看见。
那我们该怎么证明进行了代码裁剪呢?
ok,我们知道条件编译是在预处理阶段进行的,所以我们可以进行一次预处理的过程------
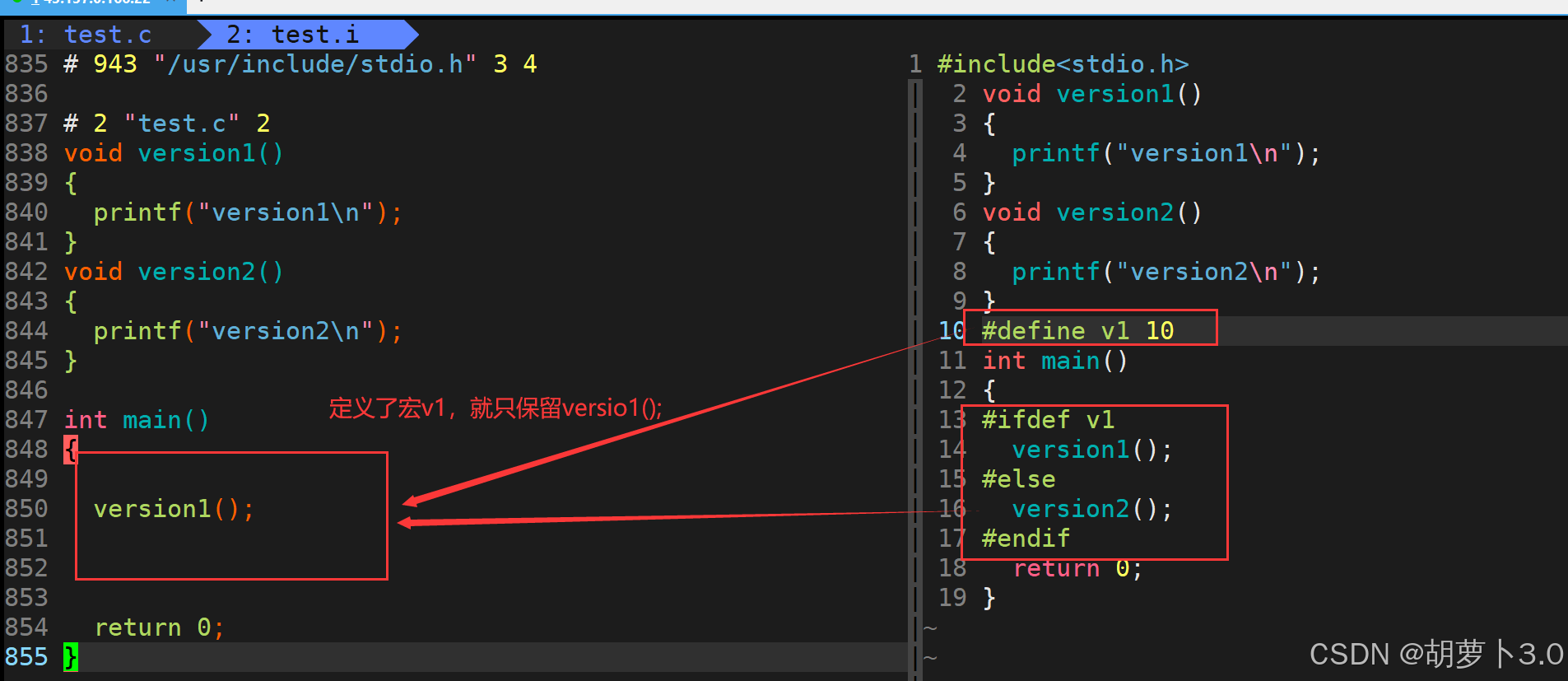
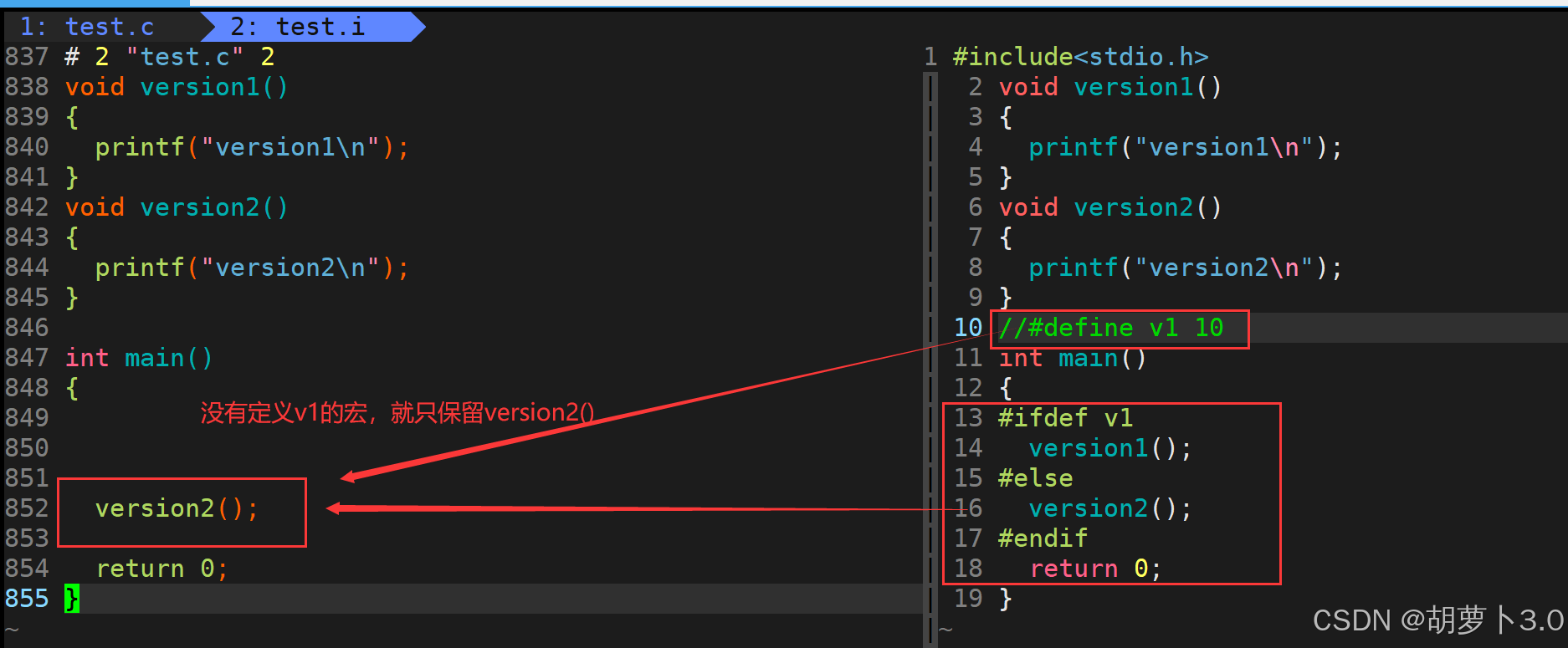
通过上图的对比,我们就可以清晰的看出:
条件编译是可以对我们的代码进行裁剪的!在预处理阶段!!!
理解:预处理符是给编译器看的!!!
编译器的预处理器可以对你写的C语言文本进行增删改的,头文件展开就是往源文件中增加代码,去注释就是把源文件中的多余代码删掉,宏替换就是修改代码中宏的位置
那为什么要有条件编译?
那我们对上面的代码改写一下------
bash
: test.c ? ? ?? buffers
1 #include<stdio.h>
2 void version1()
3 {
4 printf("免费\n");
5 }
6 void version2()
7 {
8 printf("收费\n");
9 }
10 #define Free 10
11 int main()
12 {
13 #ifdef Free
14 version1();
15 #else
16 version2();
17 #endif
18 return 0;
19 }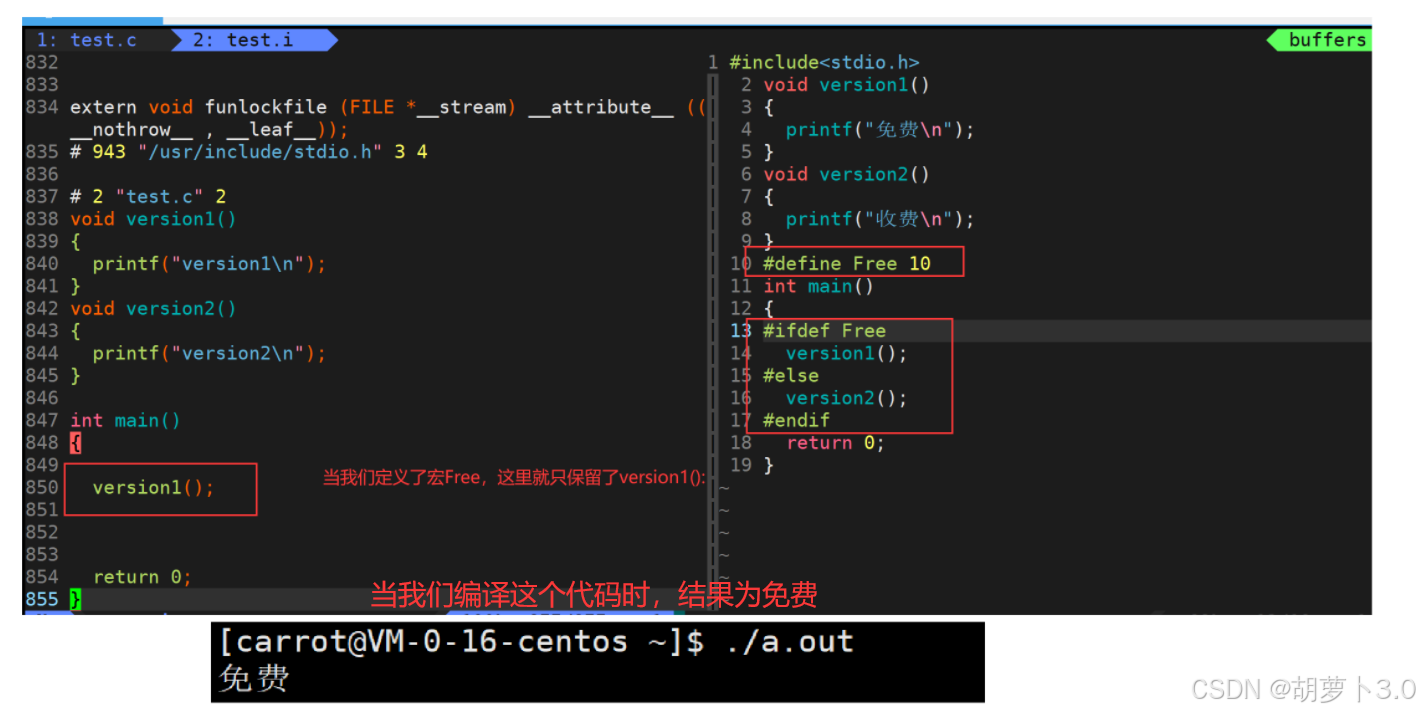
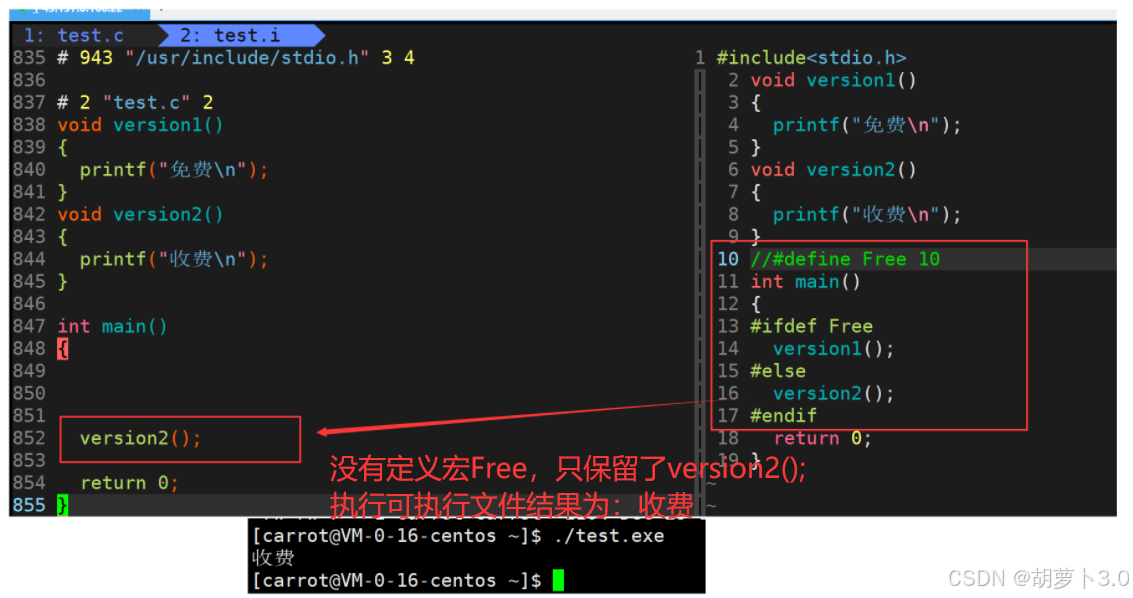
我们要知道的是:上面的结果是在条件编译的作用在完成的,那通过上面的结果,我们是不是就知道为什么要有条件编译了?
条件编译可以用来进行多商业软件,进行不同种类的管理!!!
ok,其实编译器自己也可以实现定义宏,也就是说我们可以不在代码中定义宏------
bash
gcc test.c -o test.exe -DFree
gcc test.c -o test.exe -DFree=10
bash
# 定义宏
[carrot@VM-0-16-centos ~]$ gcc test.c -o test.exe -DFree
[carrot@VM-0-16-centos ~]$ ./test.exe
免费
[carrot@VM-0-16-centos ~]$ gcc test.c -o test.exe -DFree=10
[carrot@VM-0-16-centos ~]$ ./test.exe
免费
# 不定义宏
[carrot@VM-0-16-centos ~]$ gcc test.c -o test.exe
[carrot@VM-0-16-centos ~]$ ./test.exe
收费如果以后有uu进行Linux源代码的开发,在Linux内核的源代码中就是使用条件编译进行代码裁剪的!!!
1.4 为何一定是这四个步骤?
ok,我们知道编译C语言所经历的过程是:

那为什么一定是这四个过程呢?
ok,那我们就要来聊一聊编译器的历史以及语言的历史了。
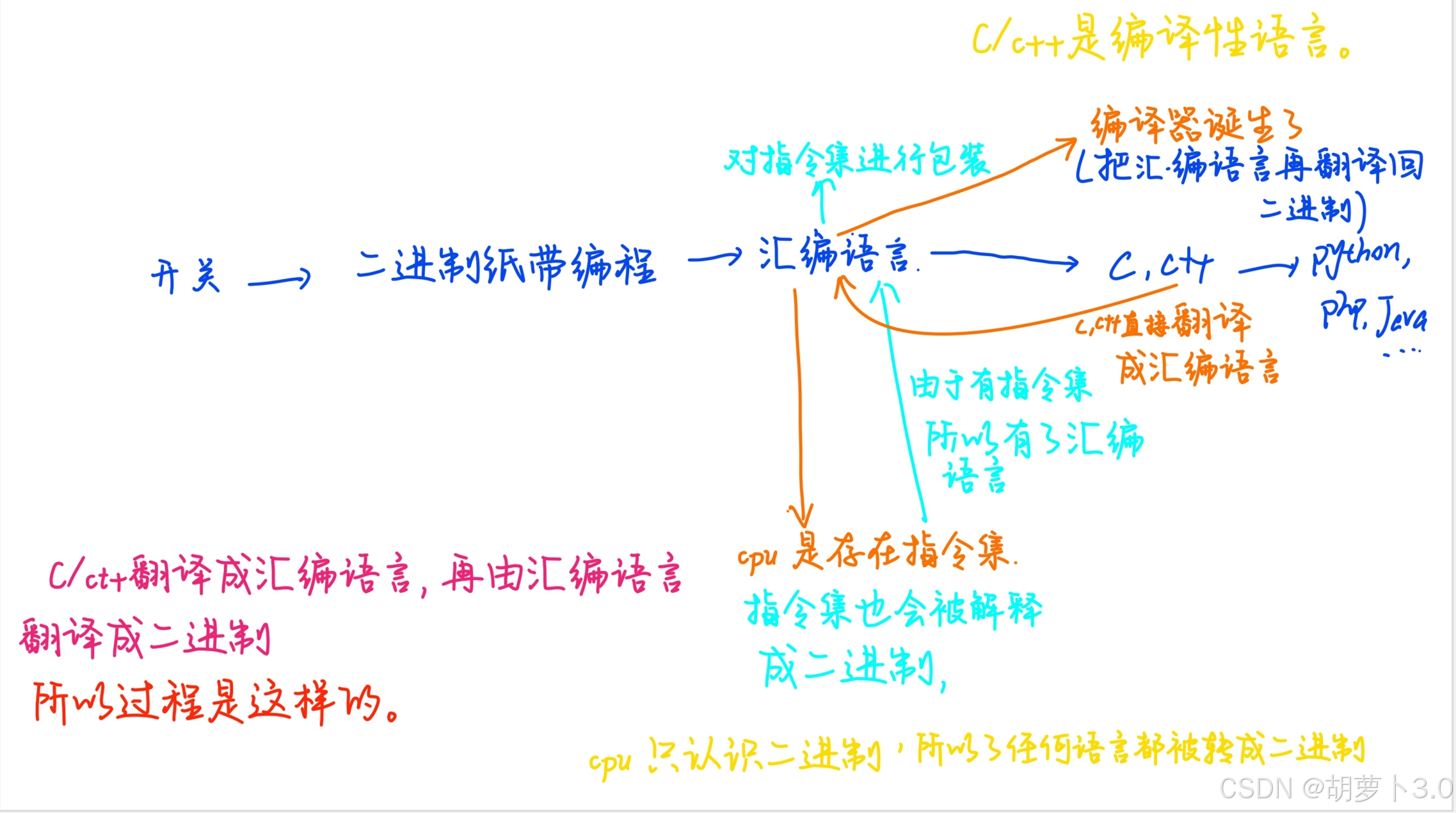
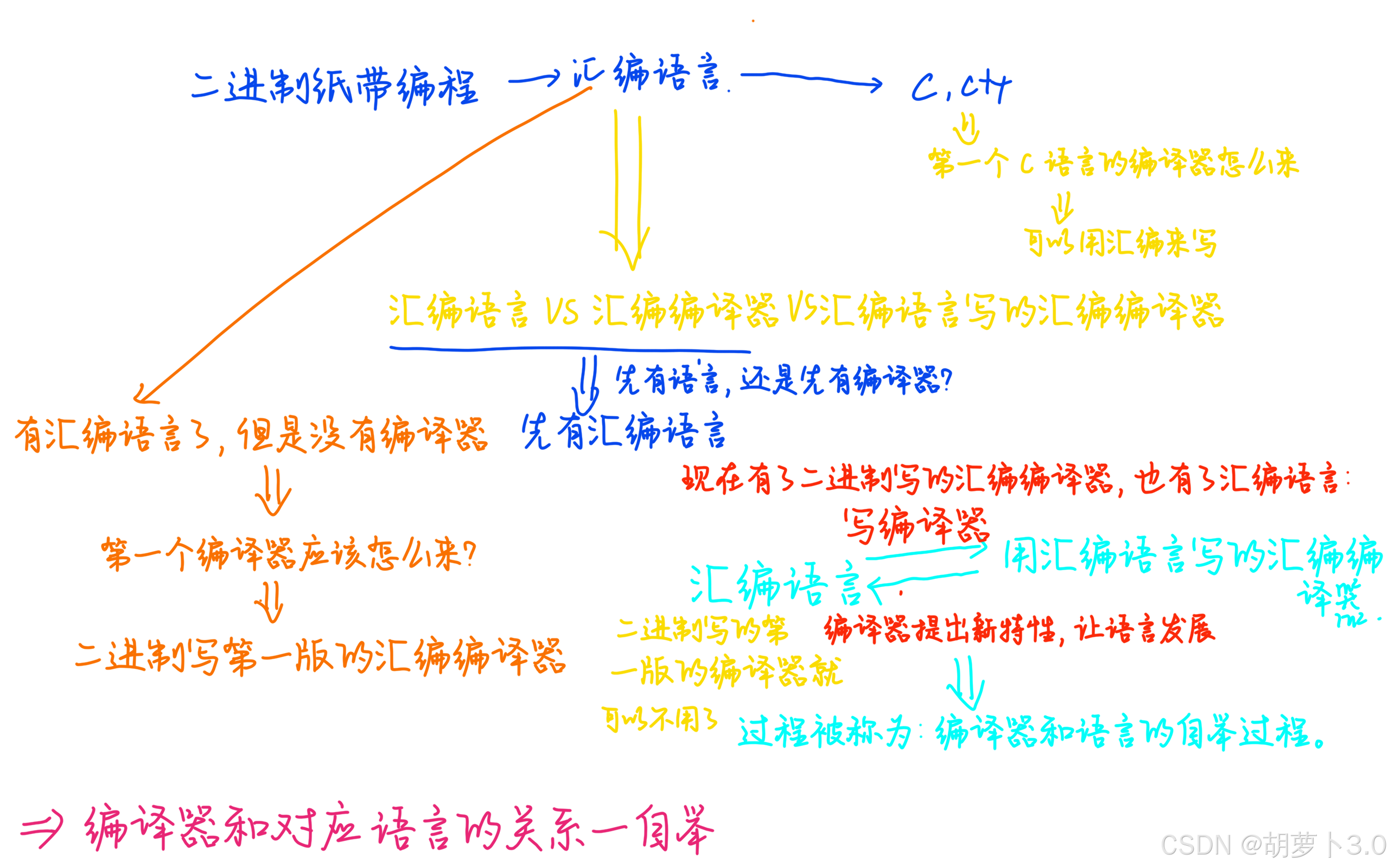
原来是因为历史的发展,所以我们必须是这四个过程!!!
1.5 初步了解链接
1.5.1 初识库
通过上面的学习,我们知道一个好的编译习惯是:
- 先将文件编成.o目标文件,再将.o目标文件链接成可执行文件
那我们看到上图中先将所有的 .c文件 编译成 .o文件,再由 .o文件 和**"库"**链接形成可执行程序。
哦?.o文件 必须和一个叫"库"的东西进行链接形成可执行文件。
库是什么?为什么要有库?库在哪里?

- 为什么要有这个库?
我们来想一想,如果一个程序员想要使用printf函数的时候,需要自己手动写一个,大概四五十分钟,世界上有成千上万个程序员,那这个是不是就有点浪费时间,所以就让世界上最顶尖的程序员写一个printf函数,供所有的程序员使用
这本质上是程序员间的一种浪漫的协作方式,我们站在巨人的肩膀上提高了开发的效率
Linux中的C库在/lib64/libc.*路径下
bash
[carrot@VM-0-16-centos ~]$ ll /lib64/libc.*
-rw-r--r-- 1 root root 253 Jun 4 2024 /lib64/libc.so
lrwxrwxrwx 1 root root 12 Jul 8 2024 /lib64/libc.so.6 -> libc-2.17.so不管是Linux,还是windows,都有属于自己的动态库和静态库:
|---------|------|------|
| 库 | 动态库 | 静态库 |
| windows | .dll | .lib |
| Linux | .so | .a |
库命名规则:
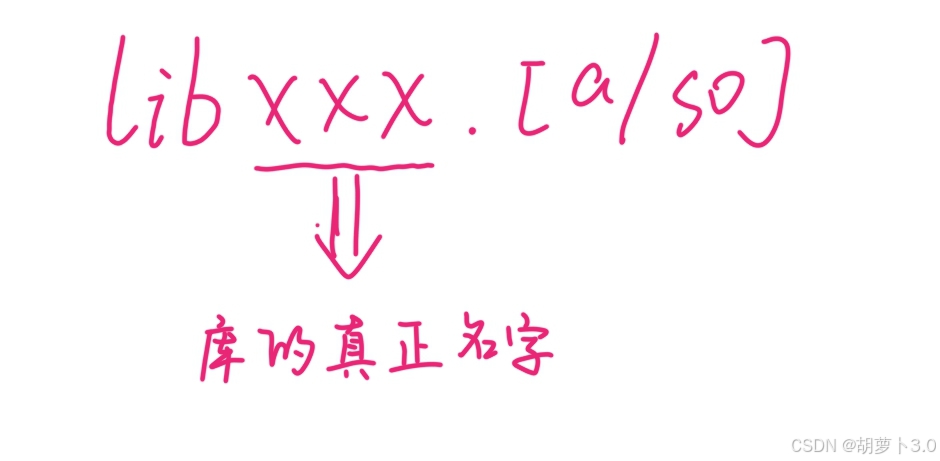

我们可以通过指令来查看一个可执行文件是否用到了库------
bash
ldd 二进制文件名
那什么是动态库,动态链接,静态库,静态链接呢?
- 动态库:通常和程序进行动态链接
- 静态库:通常和程序进行静态链接
1.5.2 借书与买书:感性理解动态库与静态库
这该如何理解呢?
ok,接下来,我们通过一个小故事来感性理解一下:
场景一:
小王以优异的成绩考进了一中,一中是一个军事化管理的高中,小王喜欢上网,但是学校禁止带手机,这就让小王很难受,于是就把诉求告诉了王爸,王爸说"你去找隔壁张三,他刚从一中毕业,他应该很清楚",小王找到张三,说"就是平时想上网,查一些资料该怎么办?",张三说"学校东门左100米,右100米,有一个小蚂蚁电竞馆"。
某周六,小王按计划完成作业,前去电竞馆上网,老板开了一台编号为1234的电脑,小王尽情的玩了起来,时间到了,小王继续回学校写作业,后来小王的同学"小张,小李,小其他......"都去"小蚂蚁电竞馆"上网。到了一次月考,全班成绩下滑,校长调查后举报了"小蚂蚁电竞馆",电竞馆关门了,导致所有人都不能去上网
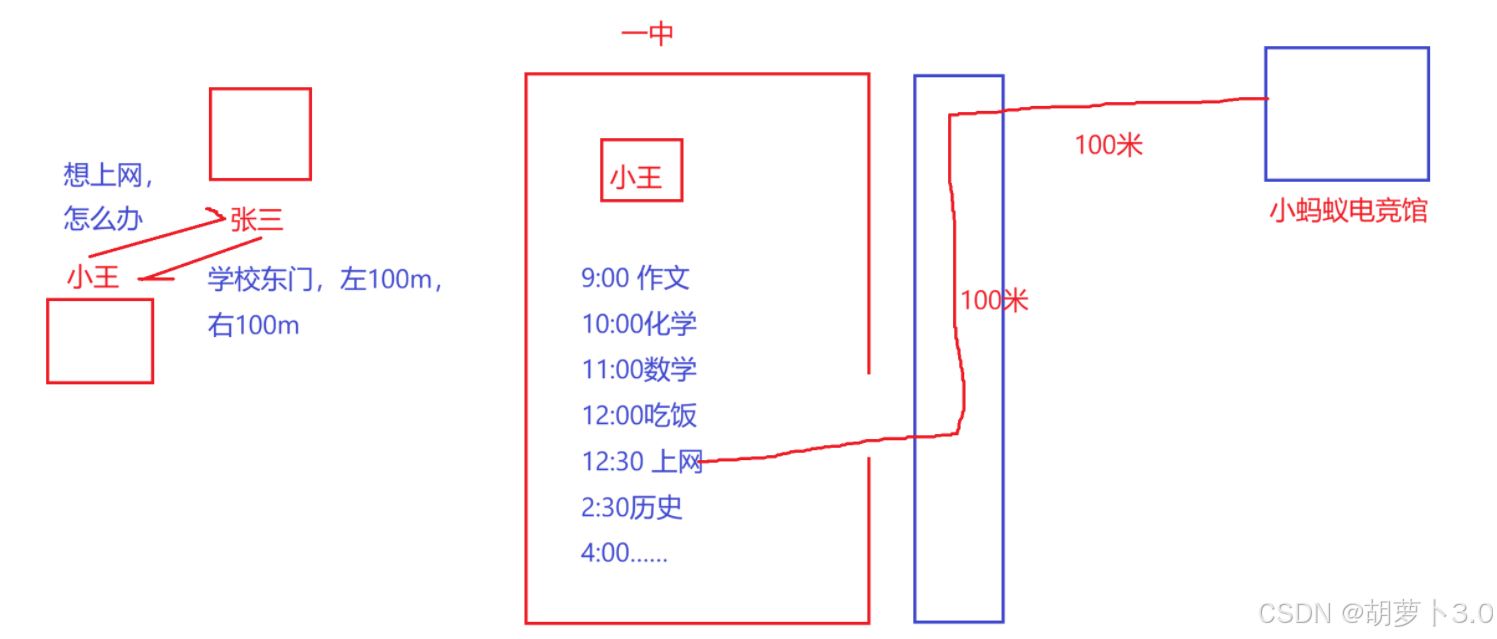
在这里有一些点需要理解一下:
- 小王------自己编写的程序
- 张三------编译器-连接器
- 一中------相当于内存
- 小蚂蚁电竞馆------动态库
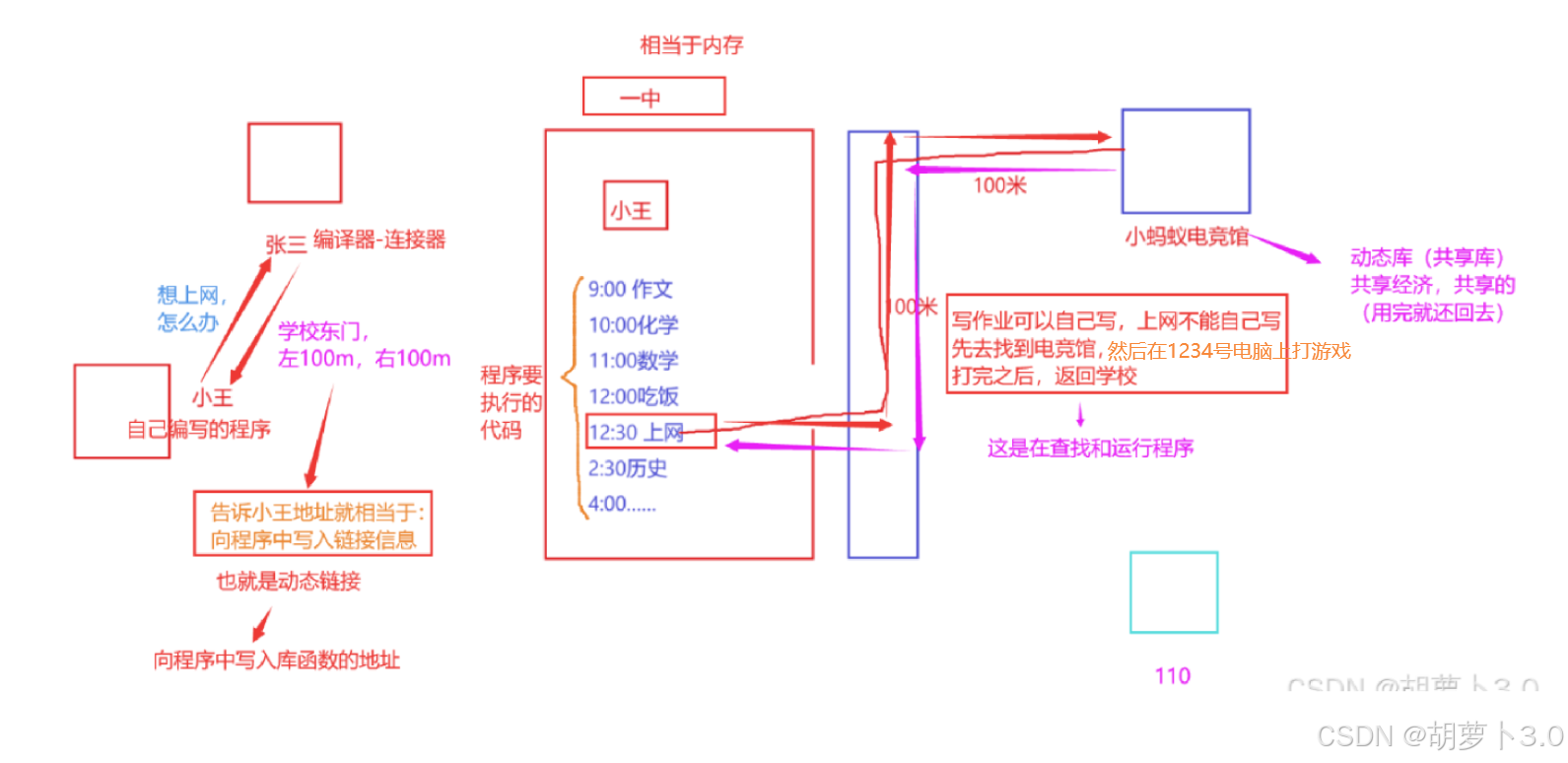
场景解析:
- 小王要完成的计划------程序要执行的代码
- 其中上网这一计划不是自己独立完成的,需要转到电竞馆执行,然后执行完返回------根据地址找到电竞馆,然后执行完返回,叫做------查找和运行程序
- 要去1234号电脑上网------相当于找到printf函数的地址
- 电竞馆关门了(动态库缺失),导致所有人不能去上网(程序无法运行)
bash
┌─────────────┐ 询问地址 ┌─────────────┐
│ 小王 │ ──────────────> │ 张三 │
│ (程序) │ │ (编译器/链接器)│
└─────────────┘ └─────────────┘
│ │
│ 获得地址:"东门左转100m右转100m"
│ │
▼ ▼
┌─────────────────────────────────────────────┐
│ 一中 │
│ (内存) │
└─────────────────────────────────────────────┘
│
│ 按计划执行:作业→上网→作业
│
▼
┌─────────────┐ 上网请求 ┌─────────────┐
│ 小王 │ ──────────────> │ 小蚂蚁电竞馆 │
│ (程序) │ │ (动态库) │
└─────────────┘ └─────────────┘
│
│ 分配1234号电脑
│ (库函数地址)
▼
┌─────────┐
│ 愉快上网 │
│ (函数执行)│
└─────────┘动态库是一个真实存在的文件,动态链接是形容一种动作------把未来要用到的库地址写到程序中,然后程序需要用到时,自动跳转到所对应的库地址,然后使用,使用完就还回去
动态库和动态链接的优缺点:
- **缺点:**一旦库文件缺失,所有程序无法正常运行
- 优点:节省资源(所有人在自己的程序中记录的不是某个函数方法的实现,而是这个方法对应的地址)
场景二:
小王因为不能上网,导致成绩下降,王爸了解情况后,和校长说:"让小王玩电脑,后果自负",王爸就去找老板买那台编号为1234的电脑,放在小王的桌子上,供小王使用,其他同学看到了,也这么干,所有人上网都可以在自己的电脑上上网了
理解:
- 王爸和电竞馆老板(静态库)将电脑(库函数)买下来安装在小王桌子上(静态链接)
- 小王和同学(多个程序)每个人都有一个电脑(静态链接时每个程序包含一份库代码)
- 现在上网(使用库函数)不依赖电竞馆(外部动态库),但每个人都可以在自己的电脑上上网(导致内存变大)
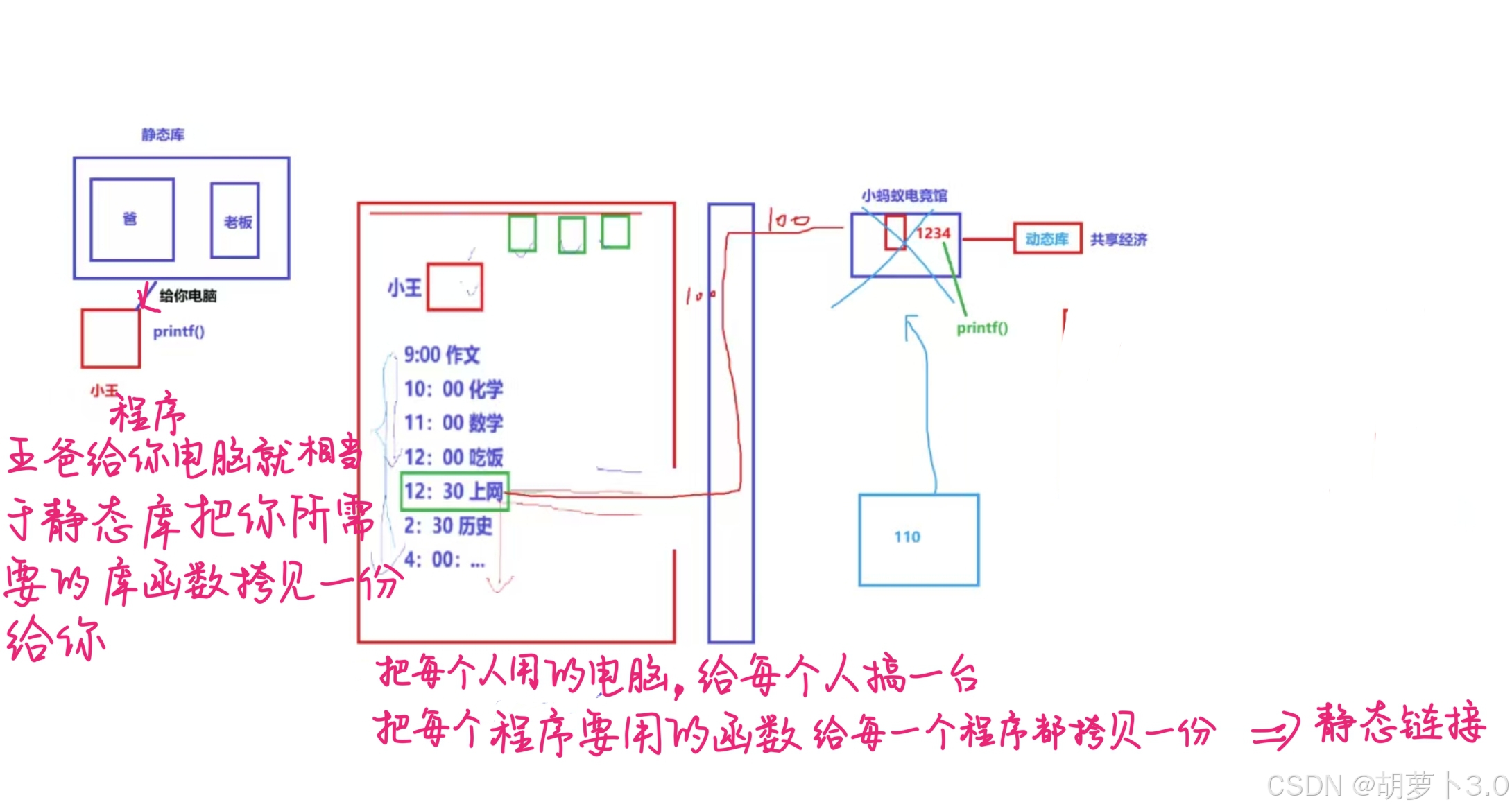
静态库和静态链接的优点和缺点:
- **优点:**程序不依赖任何其他的库
- **缺点:**让可执行程序变大,运行的时候,加载到内存:占用更多的内存空间,浪费资源
通过上面的两个场景,我们就能感性的理解一下动态库和动态链接,静态库和静态链接啦!!!
Linux也不傻,默认使用的是动态链接------
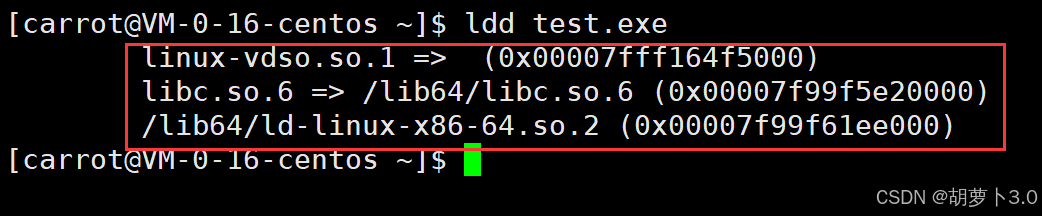
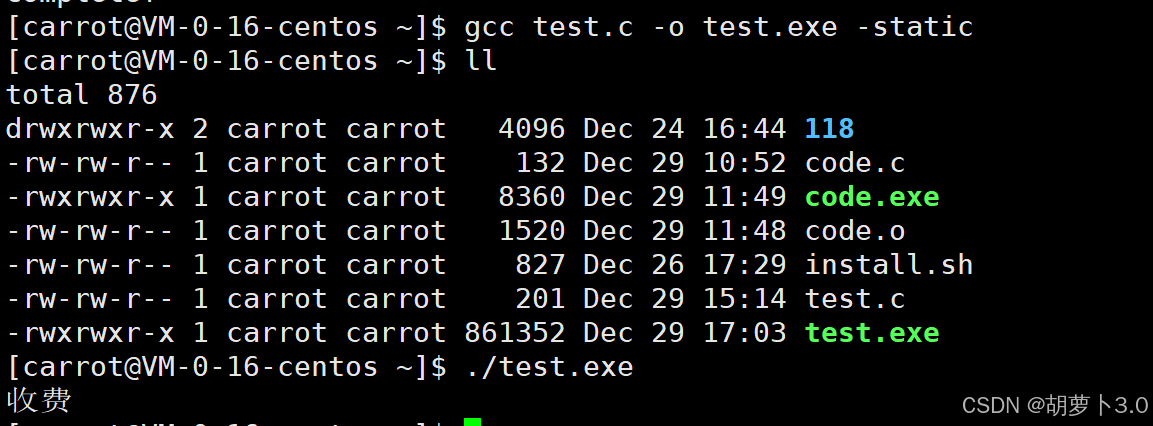
那如果我们想强制使用静态链接呢?该怎么办?
bash
# 后面加上 -static 就是强制静态链接
[carrot@VM-0-16-centos ~]$ gcc test.c -o test.exe -static但是gcc默认使用动态库和动态链接,也就是说Linux系统中,默认只安装了动态库和动态链接
Linux系统中没有安装静态库时的报错:

静态库需要自己安装------
bash
yum install glibc-static libstdc++-static -y安装完成后,就可以正常运行------
通过上图,我们也能看到静态链接确实会使内存变大!!!
- 细节:如果我删掉了C动态库会出现什么问题?
一般而言,删掉了C动态库,系统中大部分指令就没有办法运行了(包括可执行程序)
结尾
希望对学习Linux相关内容的uu有所帮助,不要忘记给博主"一键三连"哦!