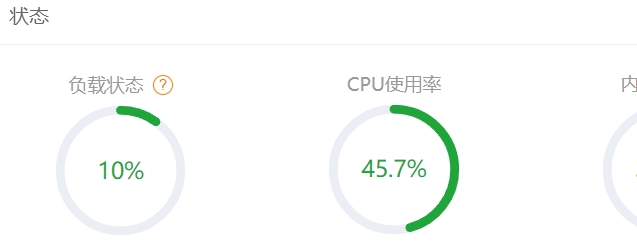
大量恶意爬虫占用系统资源,频繁访问服务器快耗竭。快速屏蔽掉无用爬虫可以参考下面方法。
3.229.95.193 - - 28/Apr/2025:08:27:58 +0800 "GET /news/1563.html HTTP/1.1" 200 11642 "-" "Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Amazonbot/0.1; +https://developer.amazon.com/support/amazonbot) Chrome/119.0.6045.214 Safari/537.36"
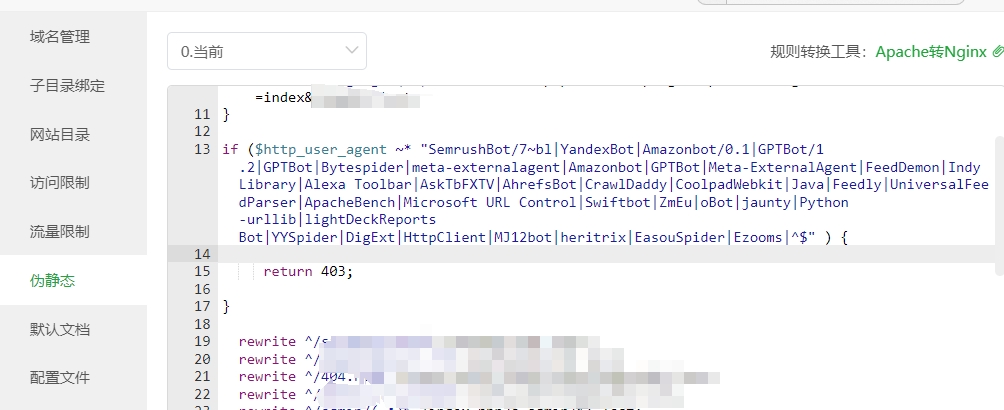
通过宝塔面板,伪静态重写,代码如下:
if (http_user_agent \~\* "SemrushBot/7\~bl\|YandexBot\|Amazonbot/0.1\|GPTBot/1.2\|GPTBot\|Bytespider\|meta-externalagent\|Amazonbot\|GPTBot\|Meta-ExternalAgent\|FeedDemon\|Indy Library\|Alexa Toolbar\|AskTbFXTV\|AhrefsBot\|CrawlDaddy\|CoolpadWebkit\|Java\|Feedly\|UniversalFeedParser\|ApacheBench\|Microsoft URL Control\|Swiftbot\|ZmEu\|oBot\|jaunty\|Python-urllib\|lightDeckReports Bot\|YYSpider\|DigExt\|HttpClient\|MJ12bot\|heritrix\|EasouSpider\|Ezooms\|\^" ) {
return 403;
}
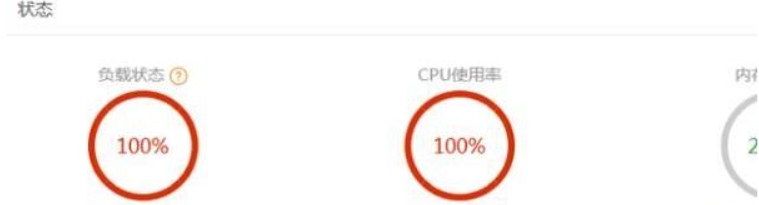
重写之后,系统负载正常。