文章目录
-
- 前言
- 一、Ollama准备
-
- [1. 什么是Ollama?](#1. 什么是Ollama?)
- [2. 安装Ollama](#2. 安装Ollama)
- [3. 部署模型](#3. 部署模型)
- 二、Golang调用本地模型API
-
- [1. 非流式调用](#1. 非流式调用)
- [2. 流式调用](#2. 流式调用)
- 流式处理要点
- 总结
- 参考文献
前言
近年来,AI技术迅猛发展,作为后端程序员,掌握基本的AI应用开发能力变得尤为重要。即使不深入研究模型底层原理,具备快速部署模型并在应用中调用的能力,也能极大地扩展自身技能边界。
本系列文章将从AI模型的本地部署 到后端调用接口 ,再到前端交互展示,以最简化的方式,带领大家完成一个完整的AI应用开发流程。
本文作为系列的第一篇,主要内容是:使用Ollama部署本地模型 ,并通过Golang实现非流式和流式的API调用。
一、Ollama准备
1. 什么是Ollama?
Ollama是一个本地大模型部署工具,极其易用,非常适合快速上手体验AI应用开发。
2. 安装Ollama
Ollama的安装方式在网上有很多教程,这里推荐一篇讲解非常详细的文章:通过Ollama本地部署DeepSeek R1以及简单使用的教程(超详细)。
可以直接参考文中步骤完成安装。
3. 部署模型
安装完成后,我们可以从Ollama官网的Model库中选择模型。页面上提供了不同规模的模型,模型名称中的b(例如8b)代表参数量,参数量越大,对显卡显存要求越高。
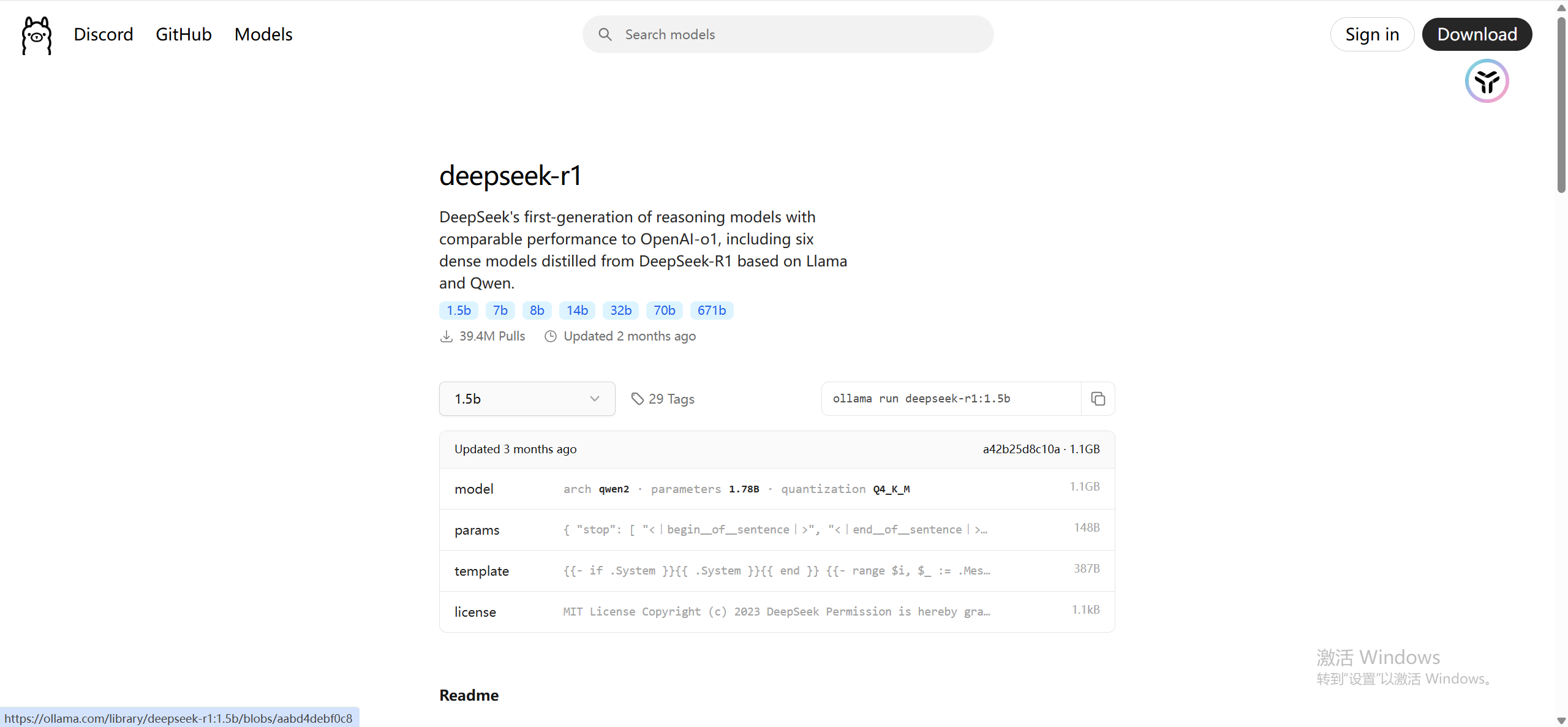
本文选择了DeepSeek R1 8B版本进行演示。
在命令行执行以下命令启动模型(首次执行会自动下载,需耐心等待):
bash
ollama run deepseek-r1:8b启动成功后,Ollama会监听本地的11434端口,等待接收请求。
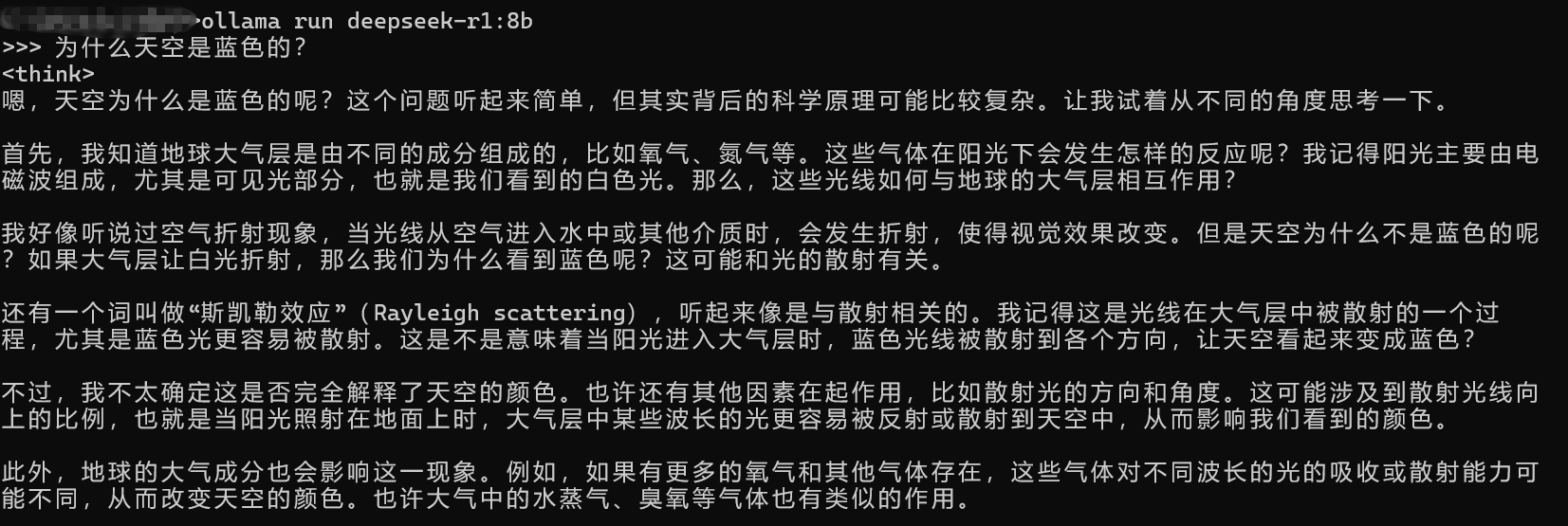
二、Golang调用本地模型API
模型部署完成后,我们就可以通过Golang编写代码与模型进行交互了。下面分别介绍非流式调用 和流式调用两种方式。
1. 非流式调用
非流式调用,意味着发送请求后,等待模型一次性返回完整的回复。
示例代码:
go
package main
import (
"bytes"
"encoding/json"
"fmt"
"net/http"
)
type Message struct {
Role string `json:"role"`
Content string `json:"content"`
}
type ChatRequest struct {
Model string `json:"model"`
Messages []Message `json:"messages"`
Stream bool `json:"stream"` // 设为false,表示非流式
}
type ChatResponse struct {
Message Message `json:"message"`
Done bool `json:"done"`
}
func main() {
reqBody := ChatRequest{
Model: "deepseek-r1:8b",
Stream: false,
Messages: []Message{
{
Role: "user",
Content: "介绍一下Golang的优势",
},
},
}
jsonData, err := json.Marshal(reqBody)
if err != nil {
panic(err)
}
resp, err := http.Post("http://localhost:11434/api/chat", "application/json", bytes.NewBuffer(jsonData))
if err != nil {
panic(err)
}
defer resp.Body.Close()
var result ChatResponse
if err := json.NewDecoder(resp.Body).Decode(&result); err != nil {
panic(err)
}
fmt.Println("AI回复:", result.Message.Content)
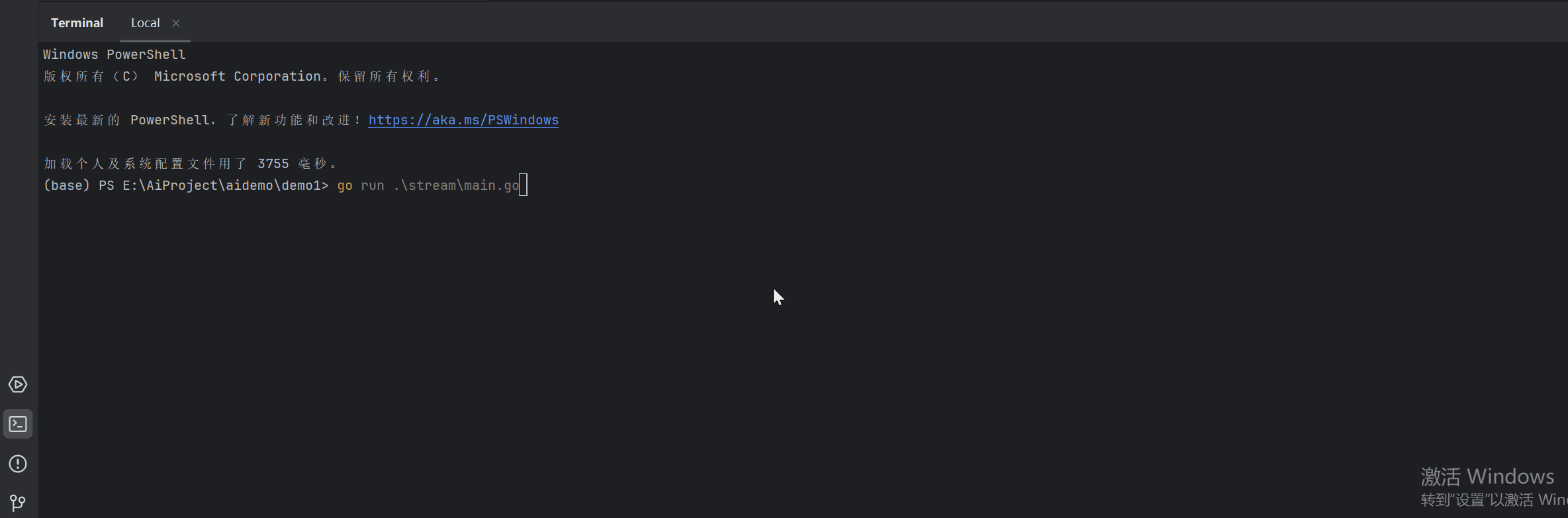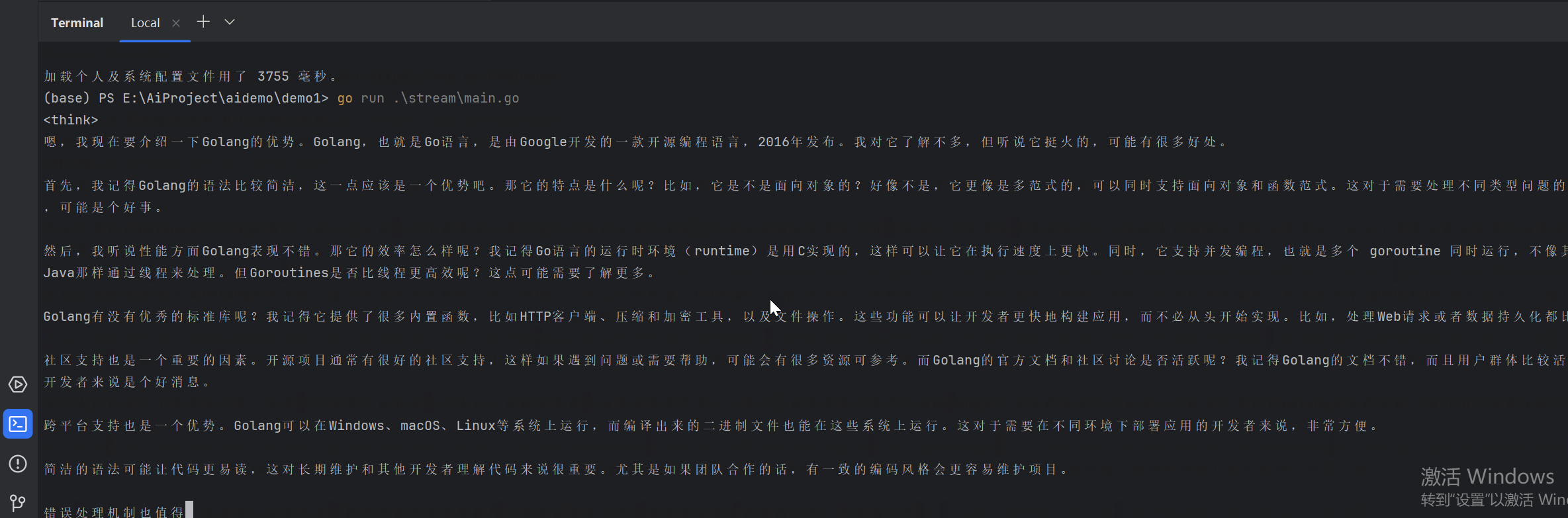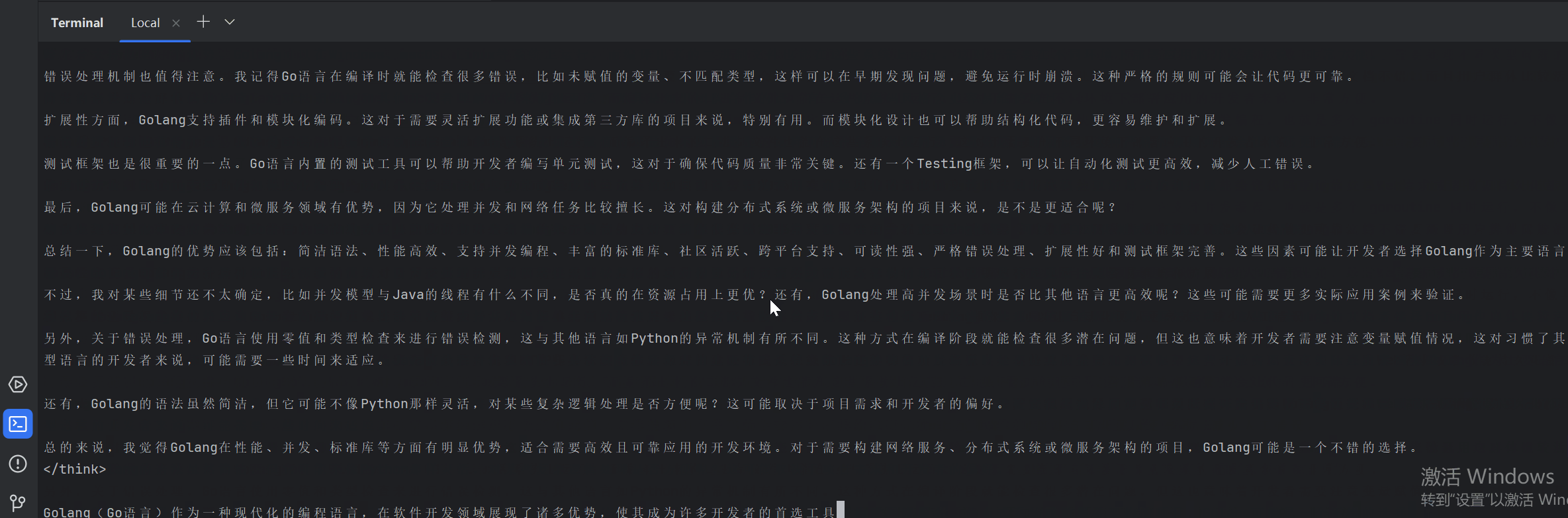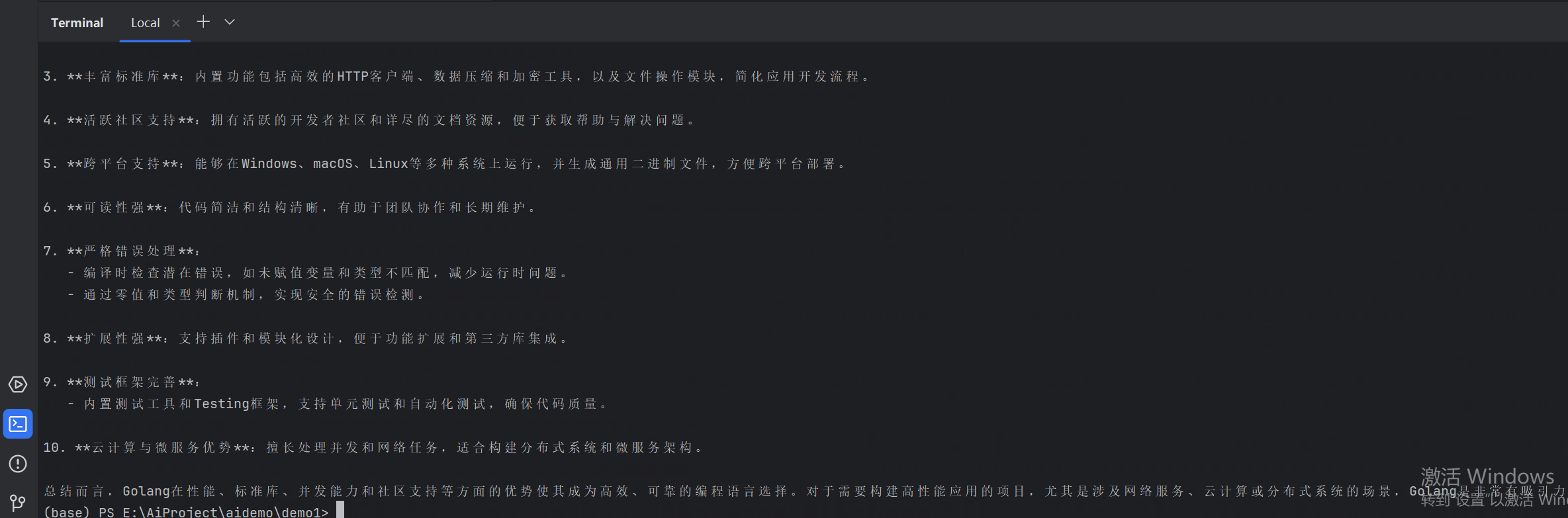
}非流式调用效果演示:
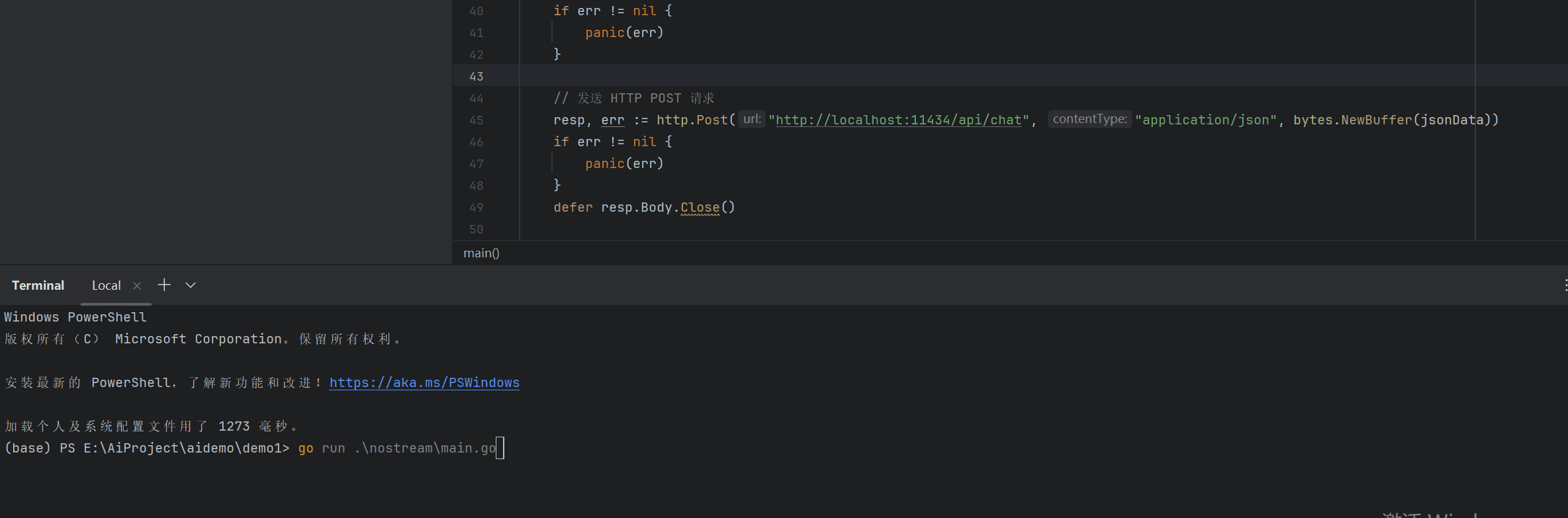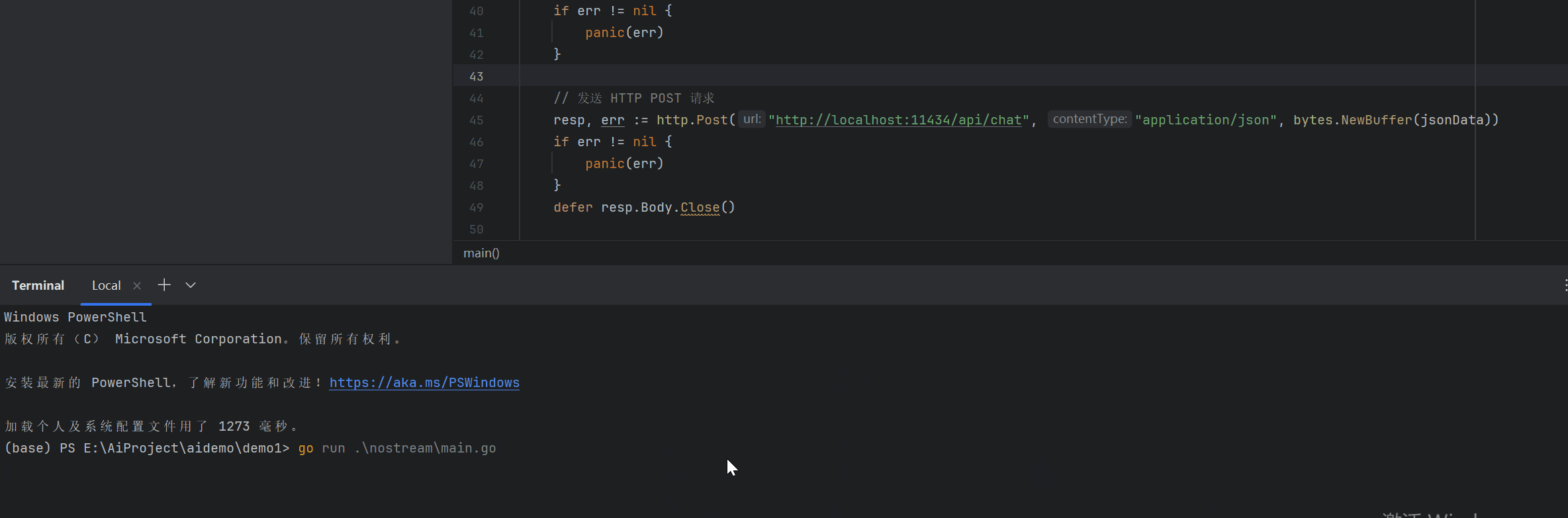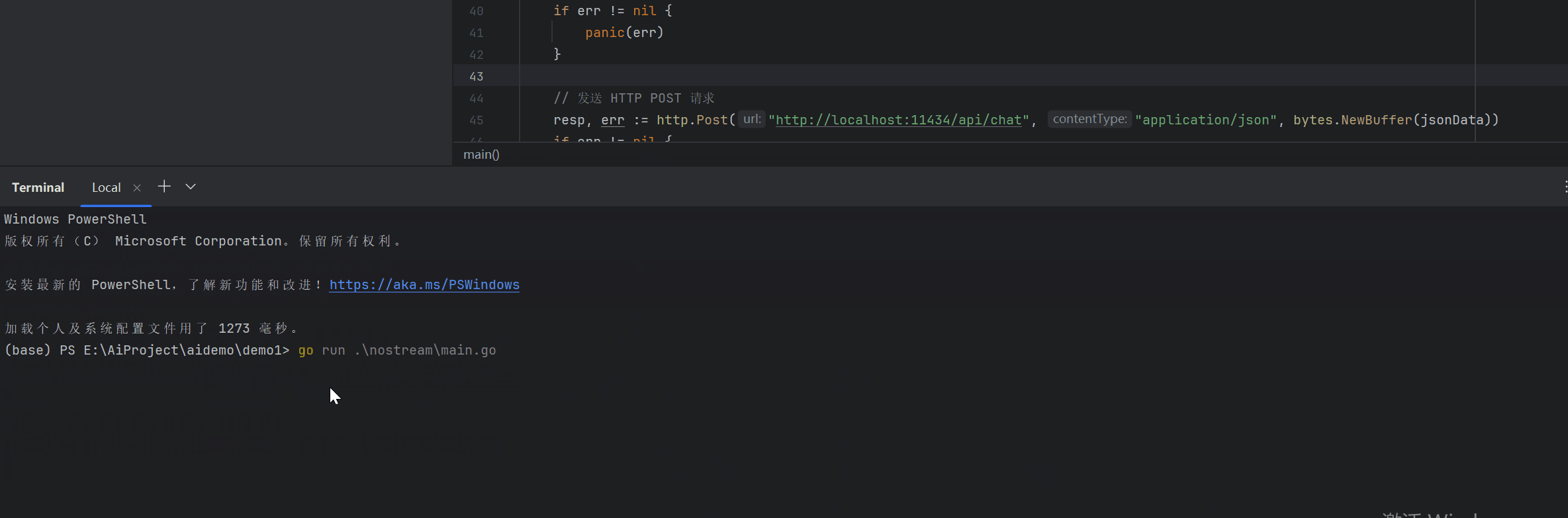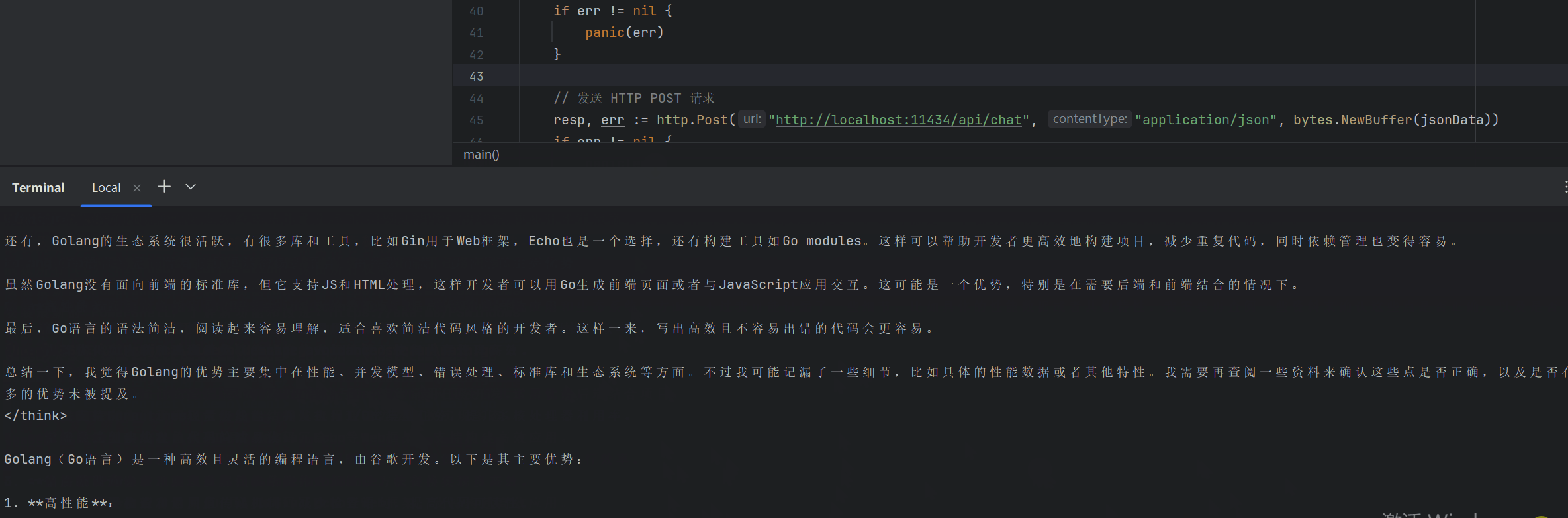
特点总结:
- 简单直接,一次请求返回完整内容;
- 不适合长文本、大内容生成,等待时间较长。
2. 流式调用
流式调用则是模型边生成边返回,每次返回一小块数据,直到全部完成。
示例代码:
go
package main
import (
"bufio"
"bytes"
"encoding/json"
"fmt"
"net/http"
)
type ChatRequest struct {
Model string `json:"model"`
Stream bool `json:"stream"`
Messages []struct {
Role string `json:"role"`
Content string `json:"content"`
} `json:"messages"`
}
func main() {
reqData := ChatRequest{
Model: "deepseek-r1:8b",
Stream: true,
}
reqData.Messages = append(reqData.Messages, struct {
Role string `json:"role"`
Content string `json:"content"`
}{
Role: "user",
Content: "介绍一下Golang的优势",
})
jsonData, err := json.Marshal(reqData)
if err != nil {
panic(err)
}
resp, err := http.Post("http://localhost:11434/api/chat", "application/json", bytes.NewBuffer(jsonData))
if err != nil {
panic(err)
}
defer resp.Body.Close()
scanner := bufio.NewScanner(resp.Body)
for scanner.Scan() {
line := scanner.Text()
if line == "" {
continue
}
var chunk struct {
Message struct {
Content string `json:"content"`
} `json:"message"`
Done bool `json:"done"`
}
if err := json.Unmarshal([]byte(line), &chunk); err != nil {
fmt.Println("解析失败:", err)
continue
}
fmt.Print(chunk.Message.Content)
if chunk.Done {
break
}
}
if err := scanner.Err(); err != nil {
fmt.Println("读取失败:", err)
}
}流式调用效果演示:
流式处理要点
-
stream: true告诉Ollama返回流式数据; -
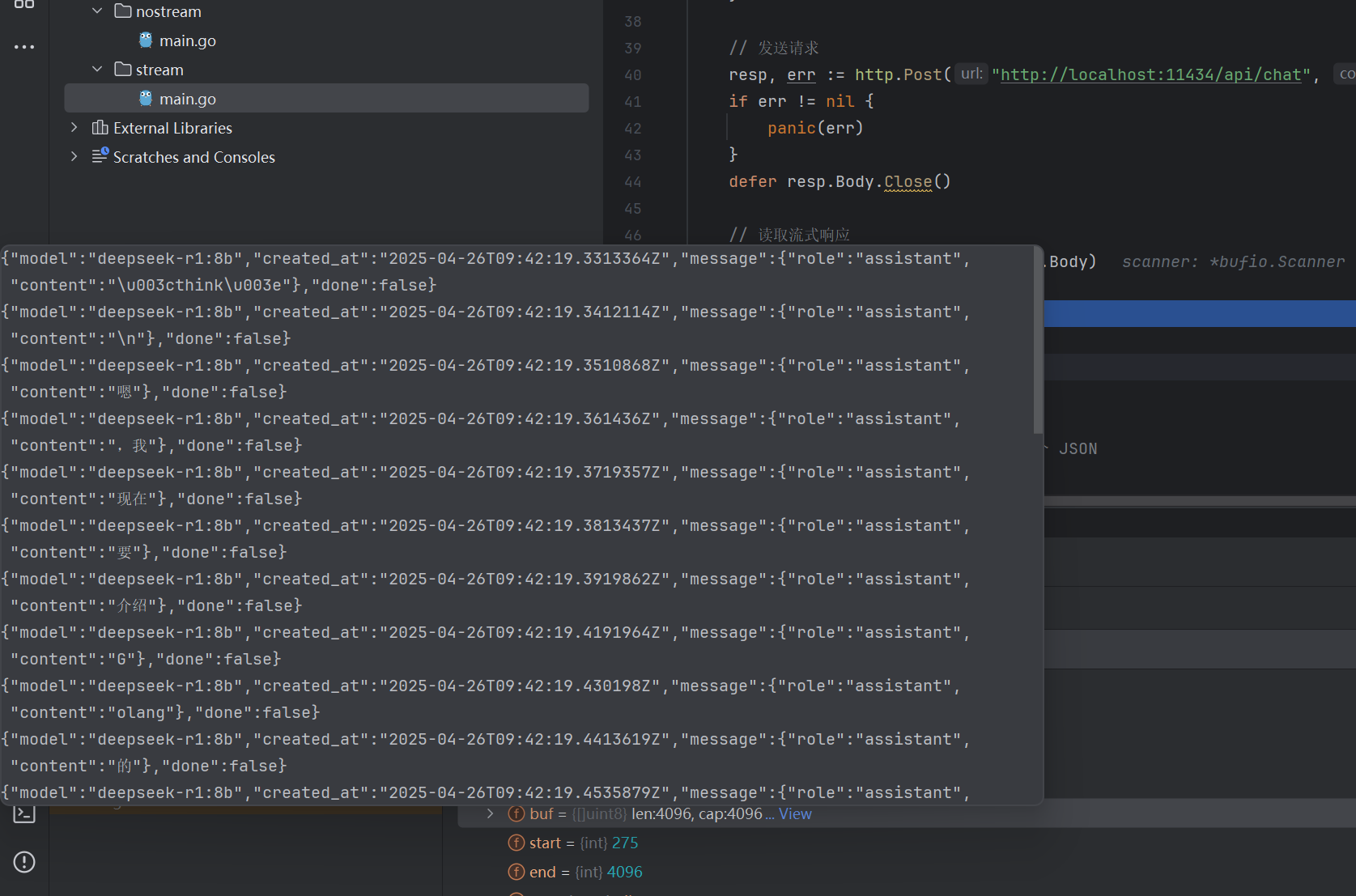
每行返回一段小的JSON数据:
-
每段数据里包含生成的文本内容;
-
最后一条数据的
done: true表示输出结束; -
使用
bufio.Scanner一行一行读取流式响应。
流式调用的体验非常接近于市面上主流的AI聊天应用(比如ChatGPT Web版),响应速度更快,用户体验更好。
总结
在本篇文章中,我们学习了:
- 如何安装并使用Ollama快速部署本地大模型;
- 如何使用Golang通过HTTP接口调用模型,支持非流式 和流式两种交互模式;
- 非流式适合短文本请求,流式更适合实时、大文本输出。
至此,我们已经掌握了本地大模型部署 和后端调用 的基本操作。
在下一篇文章中,我将继续带大家结合前端网页界面 和流式传输技术 ,实现一个简洁的AI对话小应用,让我们的模型真正"动起来"!
参考文献
【通过Ollama本地部署DeepSeek R1以及简单使用的教程(超详细)】
【简单搭建 Ollama 模型的流式响应】