1. 位置编码模块:
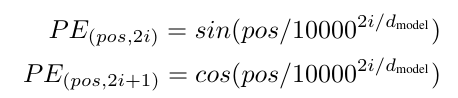
import torch
import torch.nn as nn
import math
class PositonalEncoding(nn.Module):
def __init__ (self, d_model, dropout, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
# [[1, 2, 3],
# [4, 5, 6],
# [7, 8, 9]]
pe = torch.zeros(max_len, d_model)
# [[0],
# [1],
# [2]]
position = torch.arange(0, max_len, dtype = torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
# 位置编码固定,不更新参数
# 保存模型时会保存缓冲区,在引入模型时缓冲区也被引入
self.register_buffer('pe', pe)
def forward(self, x):
# 不计算梯度
x = x + self.pe[:, :x.size(1)].requires_grad_(False)
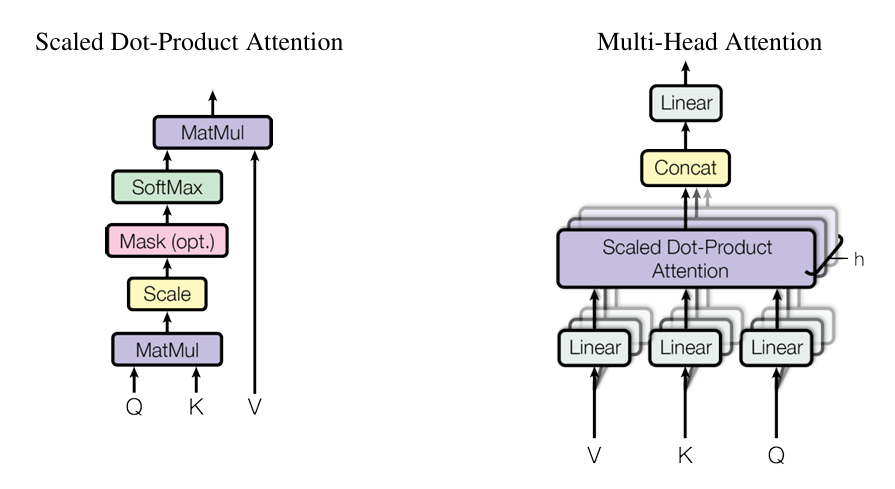
2. 多头注意力模块
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):
super(MultiHeadAttention, self).__init__()
assert d_model % num_heads == 0
self.d_k = d_model // num_heads
self.num_heads = num_heads
self.W_q = nn.Linear(d_model, d_model)
self.W_k = nn.Linear(d_model, d_model)
self.W_v = nn.Linear(d_model, d_model)
self.dropout = nn.Dropout(dropout)
self.W_o = nn.Linear(d_model, d_model)
def forward(self, query, key, value, mask=None):
batch_size = query.size(0)
Q = self.W_q(query).view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
K = self.W_k(key).view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
V = self.W_v(value).view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(self.d_k)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
attn_weights = torch.softmax(scores, dim=-1)
context = torch.matmul(attn_weights, V)
context = context.transpose(1, 2).contiguous().view(batch_size, -1, self.d_k * self.num_heads)
return self.W_o(context)
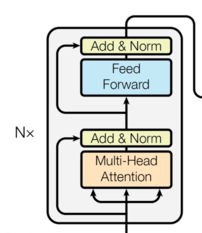
3. 编码器层
class EncoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_ff, dropout = 0.1):
super().__init__()
self.atten = MultiHeadAttention(d_model, num_heads)
self.feed_forward = nn.Sequential(
nn.Linear(d_model, d_ff),
nn.ReLU(),
nn.Linear(d_ff, d_model)
)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x, mask=None):
attn_output = self.attn(x, x, x, mask)
x = self.norm1(x + self.dropout(attn_output))
ff_output = self.feed_forward(x)
x = self.norm2(x + self.dropout(ff_output))
return x
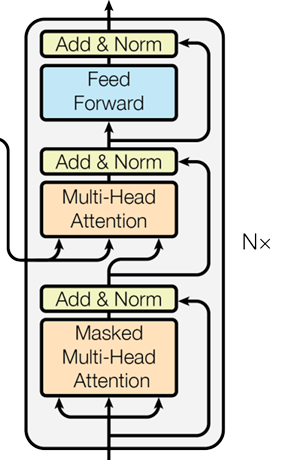
4. 解码器层
class DecoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_ff, dropout=0.1):
super(DecoderLayer, self).__init__()
self.self_attn = MultiHeadAttention(d_model, num_heads, dropout)
self.cross_attn = MultiHeadAttention(d_model, num_heads, dropout)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
self.feed_forward = nn.Sequential(
nn.Linear(d_model, d_ff),
nn.ReLU(),
nn.Linear(d_ff, d_model)
)
self.dropout = nn.Dropout(dropout)
def forward(self, x, enc_output, src_mask, tgt_mask):
attn_output = self.self_attn(x, x, x, tgt_mask)
x = self.norm1(x + self.dropout(attn_output))
attn_output = self.cross_attn(x, enc_output, enc_output, src_mask)
x = self.norm2(x + self.dropout(attn_output))
ff_output = self.feed_forward(x)
x = self.norm3(x + self.dropout(ff_output))
return x
5. 模型整合
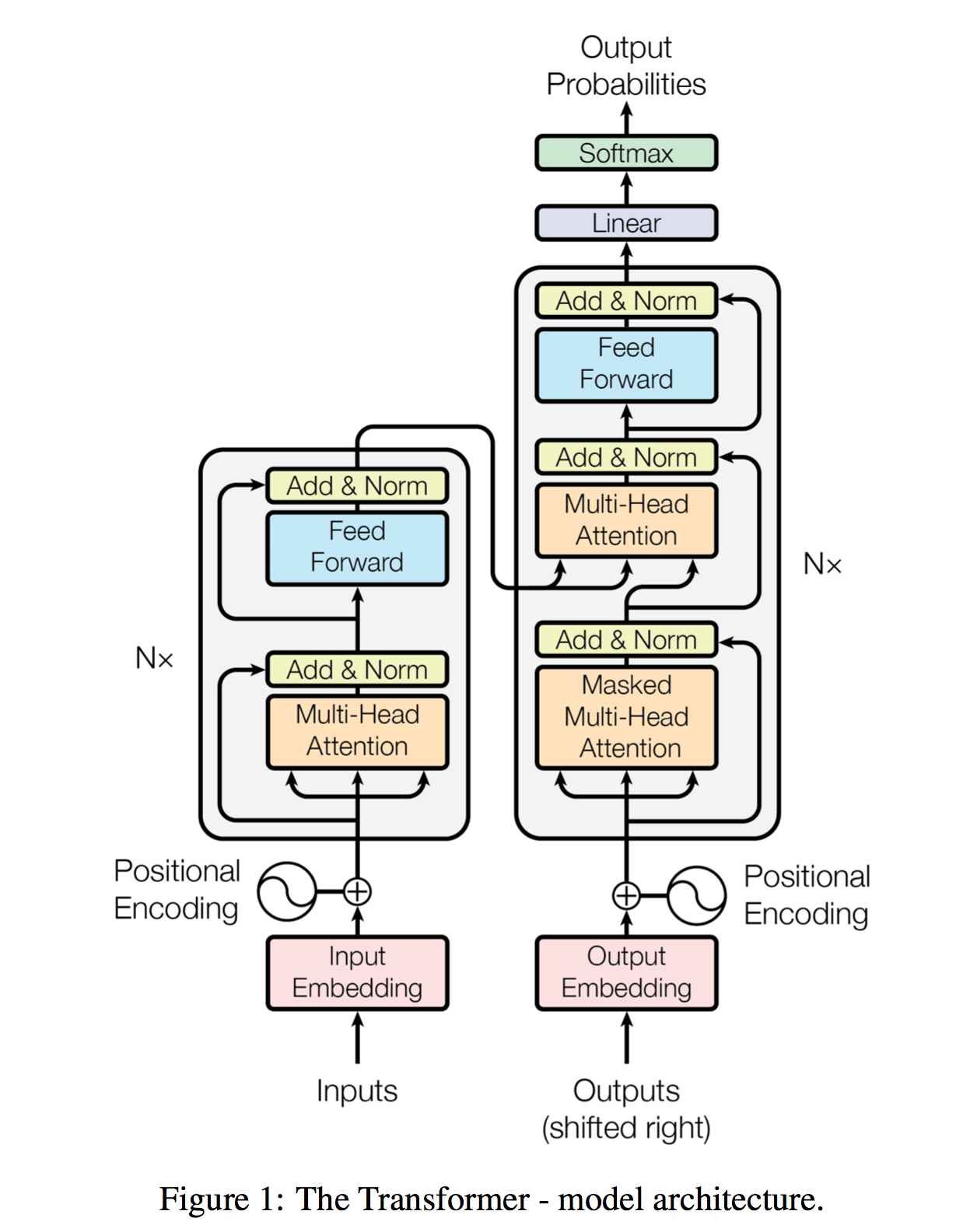
class Transformer(nn.module):
def __init__(self, src_vocab_size, tgt_vocab_size, d_model=512, num_heads=8,
num_layers=6, d_ff=2048, dropout=0.1):
super(Transformer, self).__init__()
self.encoder_embed = nn.Embedding(src_vocab_size, d_model)
self.decoder_embed = nn.Embedding(tgt_vocab_size, d_model)
self.pos_encoder = PositionalEncoding(d_model, dropout)
self.encoder_layers = nn.ModuleList([EncoderLayer(d_model, num_heads, d_ff, dropout) for _ in range(num_layers)])
self.decoder_layers = nn.ModuleList([DecoderLayer(d_model, num_heads, d_ff, dropout) for _ in range(num_layers)])
self.fc_out = nn.Linear(d_model, tgt_vocab_size)
def encode(self, src, src_mask):
src_embeded = self.encoder_embed(src)
src = self.pos_encoder(src_embeded)
for layer in self.encoder_layers:
src = layer(src, src_mask)
return src
def decode(self, tgt, enc_output, src_mask, tgt_mask):
tgt_embeded = self.decoder_embed(tgt)
tgt = self.pos_encoder(tgt_embeded)
for layer in self.decoder_layers:
tgt = layer(tgt, enc_output, src_mask, tgt_mask)
return tgt
def forward(self, src, tgt, src_mask, tgt_mask):
enc_output = self.encode(src, src_mask)
dec_output = self.decode(tgt, enc_output, src_mask, tgt_mask)
logits = self.fc_out(dec_output)
return logits