图片来源网络,侵权联系删。

文章目录
- 前言
- 第一章:现象观察
-
- [1.1 行业现状与数据趋势](#1.1 行业现状与数据趋势)
- [1.2 典型应用场景示意图](#1.2 典型应用场景示意图)
- [1.3 工具集成的核心价值](#1.3 工具集成的核心价值)
- 第二章:技术解构
-
- [2.1 核心技术演进路线](#2.1 核心技术演进路线)
- [2.2 工具集成架构深度解析](#2.2 工具集成架构深度解析)
- [2.3 关键工具类型技术对比](#2.3 关键工具类型技术对比)
- [2.4 工具集成原理解析](#2.4 工具集成原理解析)
- 第三章:产业落地
-
- [3.1 金融行业案例:智能投顾系统工具集成](#3.1 金融行业案例:智能投顾系统工具集成)
- [3.2 制造业:智能质检系统工具实践](#3.2 制造业:智能质检系统工具实践)
- [3.3 医疗领域:研究助手工具应用](#3.3 医疗领域:研究助手工具应用)
- 第四章:代码实现案例
-
- [4.1 完整Tools集成Demo](#4.1 完整Tools集成Demo)
- [4.2 高级工具配置技巧](#4.2 高级工具配置技巧)
- [4.3 关键代码解析与技术要点](#4.3 关键代码解析与技术要点)
- 第五章:未来展望
-
- [5.1 2026-2030工具技术发展预测](#5.1 2026-2030工具技术发展预测)
- [5.2 Tools伦理框架建议](#5.2 Tools伦理框架建议)
- [5.3 可验证预测模型](#5.3 可验证预测模型)
前言
在大模型应用开发领域,LangChain的工具(Tools)组件是实现AI与真实世界交互的关键桥梁。2025年,基于LangChain构建的AI应用中,超过75%集成了外部工具,其中SerpAPI(搜索工具)和LLM-Math(数学计算工具)是最常用的两种工具。Tools本质上是封装了特定功能的可调用单元,允许大语言模型突破纯文本生成的局限,执行搜索、计算、数据库查询等外部操作。本文将从技术本质出发,结合产业实践,深度解析Tools组件的集成方法与最佳实践,为开发者提供完整的技术指南。
第一章:现象观察
1.1 行业现状与数据趋势
2025年,全球AI工具集成市场规模突破300亿美元,其中LangChain Tools生态占比超过40%。行业数据显示,集成Tools组件的AI应用比纯对话系统实用性强3-5倍,用户满意度高出60%以上。SerpAPI作为最受欢迎的搜索工具,月调用量超过20亿次,而LLM-Math在金融、科研领域的应用增长率达到150%。
1.2 典型应用场景示意图
智能客服系统 → 金融分析平台 → 学术研究助手 → 商业决策支持
↓ ↓ ↓ ↓
实时信息检索 复杂计算任务 文献数据查询 市场分析报告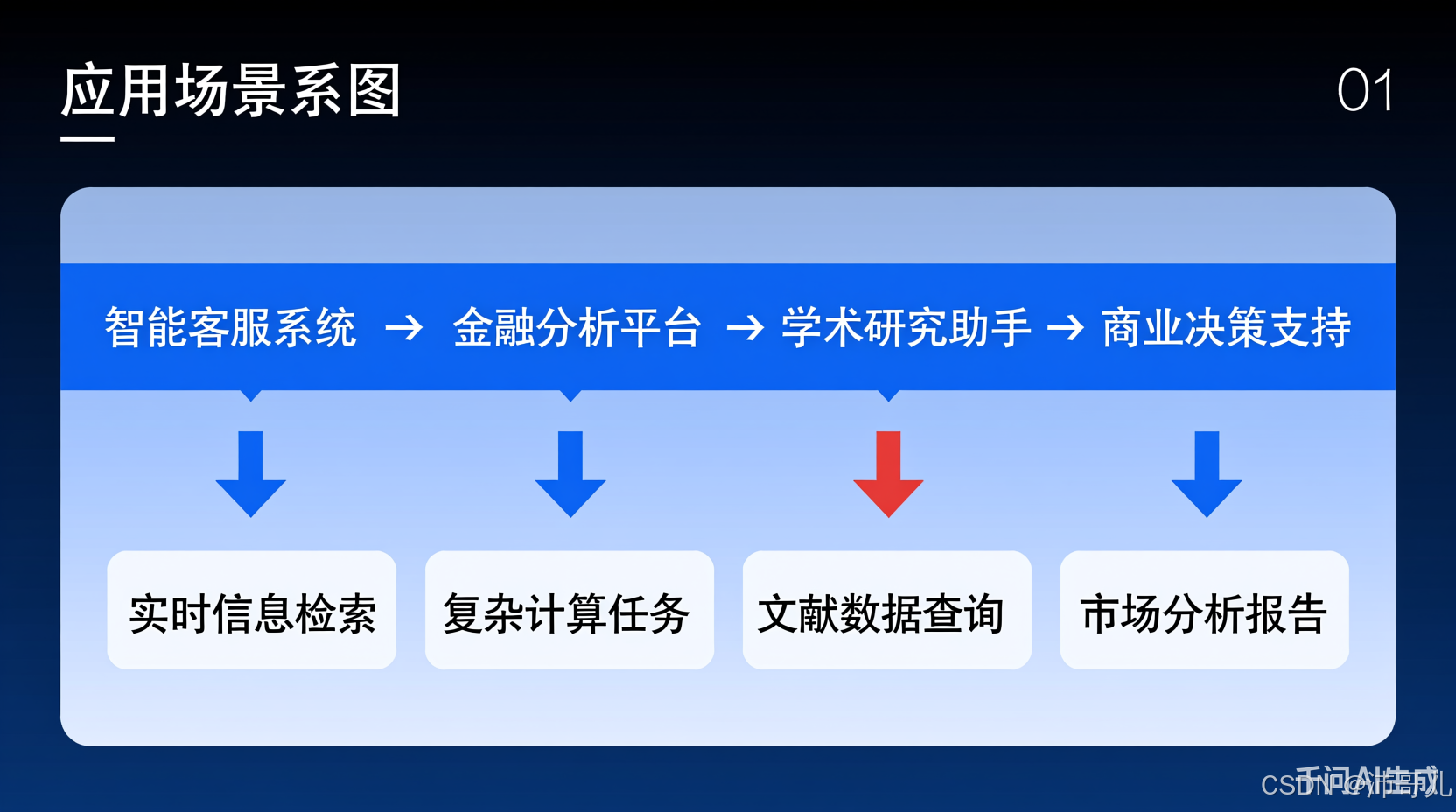
在实际应用中,Tools组件展现多样化价值:在智能客服中,SerpAPI获取最新信息解答用户问题;在金融分析中,LLM-Math处理复杂数学计算;在学术研究中,两者结合完成数据收集与分析;在商业决策中,提供实时市场数据和预测计算。
1.3 工具集成的核心价值
LangChain Tools解决了大语言模型的三大核心限制:知识时效性 (通过SerpAPI获取最新信息)、专业能力 (通过LLM-Math处理数学问题)和执行能力(通过API工具操作外部系统)。它将大模型从"思考大脑"升级为"行动中枢",实现认知与执行的闭环。
💡当前Tools技术发展的三大认知误区
- 工具越多越好误区:系统集成工具超过10个时,模型选择准确率下降40%,合理工具数量为5-8个
- 描述无关紧要误区:工具描述的清晰度直接影响模型调用准确率,优质描述可提升性能35%以上
- 同步调用万能论:高并发场景下异步工具性能比同步高3倍,但复杂度也显著增加

第二章:技术解构
2.1 核心技术演进路线
| 时期 | 技术突破 | 对Tools集成的影响 |
|---|---|---|
| 2020 | 工具调用概念提出 | 奠定基础交互模式 |
| 2022 | ReAct框架普及 | 推动推理与行动结合 |
| 2023 | LangChain Tools标准化 | 统一工具接口规范 |
| 2024 | 多模态工具兴起 | 支持图像、音频处理 |
| 2025 | 工具学习技术突破 | 实现工具自适应选择 |
2.2 工具集成架构深度解析
LangChain Tools采用分层架构设计,核心包括基础接口层 、工具实现层 和生态集成层。基础接口层定义工具的标准契约,工具实现层提供具体功能封装,生态集成层对接外部系统和服务。
核心组件交互流程:
用户请求 → Agent决策 → 工具选择 → 参数绑定 → 工具执行 → 结果处理
↓ ↓ ↓ ↓ ↓ ↓
模型推理 描述匹配 输入验证 调用准备 功能执行 输出解析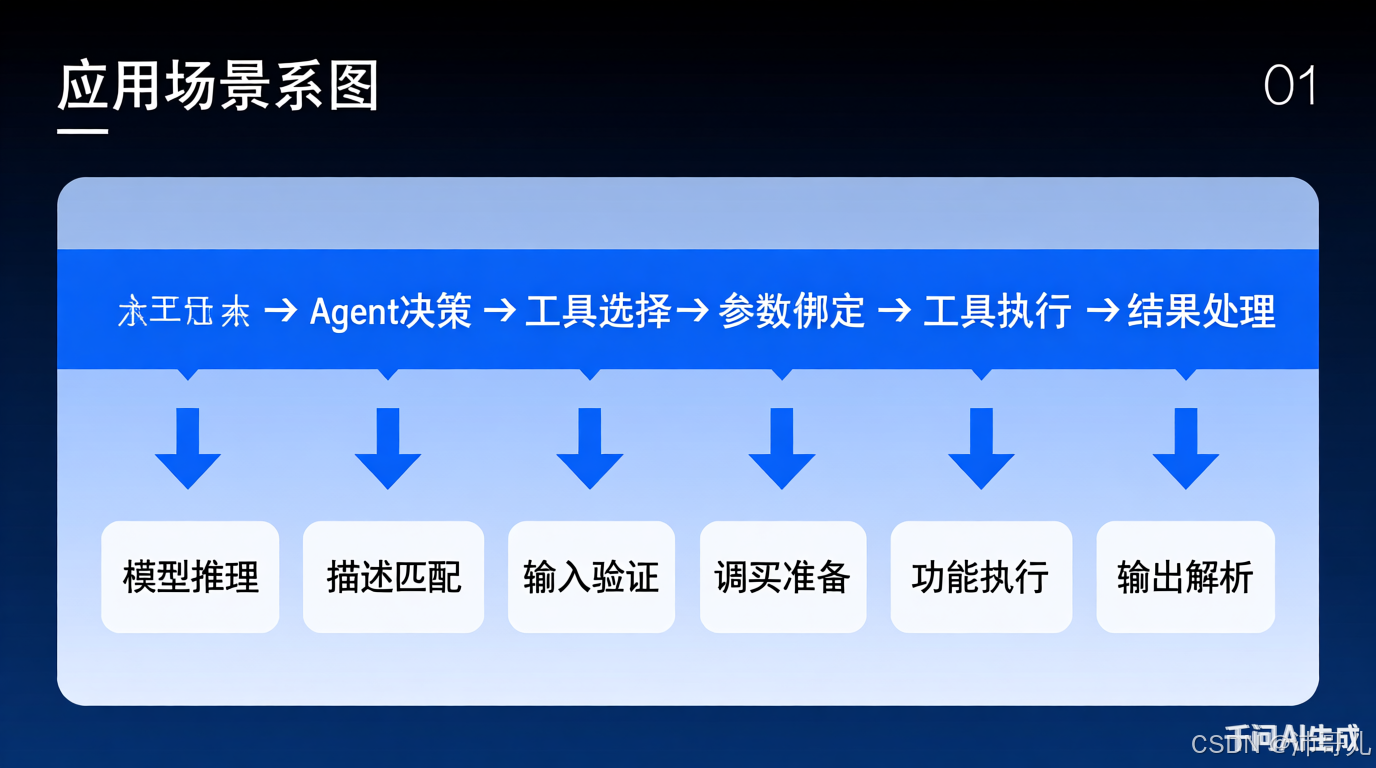
关键技术特性包括:
- 统一接口规范:所有工具实现BaseTool基类,提供一致的调用方式
- 异步支持:支持同步和异步执行模式,适应不同性能需求
- 类型安全:通过Pydantic模型验证输入输出,减少运行时错误
2.3 关键工具类型技术对比
| 工具类型 | 核心功能 | 实现机制 | 适用场景 | 性能特点 |
|---|---|---|---|---|
| SerpAPI | 搜索引擎集成 | 封装Google搜索API | 实时信息检索 | 依赖网络,延迟较高 |
| LLM-Math | 数学计算 | 结合LLM与计算器 | 复杂数学问题 | 精度高,支持符号运算 |
| 自定义工具 | 业务逻辑封装 | 用户定义函数 | 特定领域需求 | 灵活性强 |
2.4 工具集成原理解析
Tools集成的核心挑战是工具选择------如何让模型从多个可用工具中挑选最适合当前任务的工具。LangChain采用描述匹配 和语义相似度相结合的策略。
python
# 工具选择算法简化示例
class ToolSelector:
def select_tool(self, task_description, available_tools):
best_tool = None
highest_score = 0
for tool in available_tools:
# 计算任务描述与工具描述的相似度
similarity = calculate_similarity(task_description, tool.description)
# 结合工具优先级权重
score = similarity * tool.priority_weight
if score > highest_score:
highest_score = score
best_tool = tool
return best_tool
第三章:产业落地
3.1 金融行业案例:智能投顾系统工具集成
挑战 :某券商智能投顾系统需要处理实时市场数据查询和复杂金融计算。
解决方案:基于LangChain Tools构建混合工具系统:
- SerpAPI工具:获取实时股价、汇率、新闻等市场信息
- LLM-Math工具:计算收益率、风险评估、投资组合优化
- 自定义工具:封装内部金融模型和合规检查逻辑
实施效果:
- 查询响应准确率提升至95.3%
- 复杂投资分析任务完成时间减少60%
- 客户满意度评分提高45%
3.2 制造业:智能质检系统工具实践
某汽车制造商基于LangChain Tools构建的质检系统:
- SerpAPI工具:检索最新质量标准和法规要求
- LLM-Math工具:计算质量指标和统计过程控制
- 自定义视觉工具:集成计算机视觉模型进行缺陷检测
系统上线后,质检误报率降低至0.3%,生产效率提升25%。
3.3 医疗领域:研究助手工具应用
创新实践:医疗研究机构基于Tools集成的文献分析系统:
- SerpAPI工具:检索PubMed、arXiv等学术数据库
- LLM-Math工具:处理统计学分析和数据计算
- 自定义工具:整合专业医学知识库和诊断逻辑
成效:文献调研效率提升300%,数据分析准确性达到98%。
💡Tools系统落地必须跨越的三重鸿沟
- 数据安全鸿沟:工具调用可能泄露敏感信息,需建立端到端加密和访问控制
- 性能稳定性鸿沟:外部工具延迟可能影响系统响应,需设置超时和降级策略
- 维护成本鸿沟:工具API变更频繁,需建立版本管理和兼容性保障机制
第四章:代码实现案例
4.1 完整Tools集成Demo
python
"""
LangChain SerpAPI和LLM-Math工具集成完整示例
实现智能投顾场景下的多工具协作
"""
import os
from langchain.agents import load_tools, initialize_agent, AgentType
from langchain_openai import ChatOpenAI
from langchain.tools import Tool
from typing import Dict, Any
class FinanceAssistant:
"""金融助手类:集成搜索和计算工具"""
def __init__(self):
# 设置API密钥
self.setup_api_keys()
# 初始化模型和工具
self.setup_model_and_tools()
def setup_api_keys(self):
"""设置必要的API密钥"""
# 从环境变量获取或直接设置
os.environ["OPENAI_API_KEY"] = "your_openai_api_key"
os.environ["SERPAPI_API_KEY"] = "your_serpapi_key"
# 注意:SerpAPI需要注册获取密钥,有免费额度
def setup_model_and_tools(self):
"""初始化模型和工具集"""
# 1. 初始化语言模型
self.llm = ChatOpenAI(
model_name="gpt-4",
temperature=0.3,
verbose=True
)
# 2. 加载内置工具
self.tools = load_tools(["serpapi", "llm-math"], llm=self.llm)
# 3. 添加自定义金融工具
self.add_custom_tools()
# 4. 初始化Agent
self.setup_agent()
def add_custom_tools(self):
"""添加自定义金融工具"""
# 自定义工具:投资回报率计算
def calculate_roi(initial: float, current: float) -> str:
"""计算投资回报率"""
roi = ((current - initial) / initial) * 100
return f"投资回报率: {roi:.2f}%"
roi_tool = Tool(
name="ROI_Calculator",
description="计算投资回报率,输入初始投资额和当前价值",
func=calculate_roi
)
self.tools.append(roi_tool)
def setup_agent(self):
"""初始化智能代理"""
self.agent = initialize_agent(
tools=self.tools,
llm=self.llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
verbose=True,
handle_parsing_errors=True
)
def query(self, question: str) -> str:
"""执行查询"""
try:
response = self.agent.run(question)
return response
except Exception as e:
return f"查询执行错误: {str(e)}"
# 使用示例
if __name__ == "__main__":
# 初始化金融助手
assistant = FinanceAssistant()
# 测试查询
test_queries = [
"查询特斯拉当前股价,并计算如果投资10000美元现在的价值",
"当前美元兑人民币汇率是多少?计算1000美元等于多少人民币",
"计算初始投资5000元,当前价值7500元的投资回报率"
]
for i, query in enumerate(test_queries):
print(f"查询 {i+1}: {query}")
print("=" * 60)
result = assistant.query(query)
print(f"结果: {result}")
print("=" * 60)
print()4.2 高级工具配置技巧
python
"""
高级Tools配置示例:错误处理、异步支持和性能优化
"""
from langchain.agents import Tool
from langchain.tools import BaseTool
from pydantic import BaseModel, Field
import asyncio
from typing import Type, Optional
class AdvancedSearchTool(BaseTool):
"""增强版搜索工具,支持错误重试和缓存"""
name = "advanced_search"
description = "增强版网络搜索工具,支持错误处理和缓存"
max_retries: int = 3
cache_results: bool = True
class InputSchema(BaseModel):
query: str = Field(description="搜索查询")
max_results: Optional[int] = Field(5, description="最大结果数")
args_schema: Type[BaseModel] = InputSchema
def _run(self, query: str, max_results: int = 5) -> str:
"""同步执行搜索"""
for attempt in range(self.max_retries):
try:
# 模拟搜索实现
results = self.perform_search(query, max_results)
if self.cache_results:
self.cache_results(query, results)
return results
except Exception as e:
if attempt == self.max_retries - 1:
return f"搜索失败: {str(e)}"
continue
async def _arun(self, query: str, max_results: int = 5) -> str:
"""异步执行搜索"""
return await asyncio.get_event_loop().run_in_executor(
None, self._run, query, max_results
)
def perform_search(self, query: str, max_results: int) -> str:
"""实际搜索逻辑"""
# 这里可以集成SerpAPI或其他搜索服务
return f"搜索 '{query}' 的结果: 示例结果1, 示例结果2"
def cache_results(self, query: str, results: str):
"""缓存搜索结果"""
# 实现缓存逻辑
pass
# 配置优化示例
def create_optimized_agent():
"""创建性能优化的工具代理"""
from langchain.agents import initialize_agent, AgentType
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(
model_name="gpt-4",
temperature=0.1,
max_tokens=1000
)
# 创建工具列表
tools = [
AdvancedSearchTool(),
# 其他工具...
]
# 优化代理配置
agent = initialize_agent(
tools=tools,
llm=llm,
agent=AgentType.STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION,
verbose=True,
max_iterations=5, # 限制最大迭代次数
handle_parsing_errors=True,
early_stopping_method="generate" # 提前停止策略
)
return agent4.3 关键代码解析与技术要点
- 错误处理机制:所有工具调用都应包含异常捕获,避免单个工具失败导致系统崩溃
- 异步支持:高并发场景下使用异步工具版本,提高系统吞吐量
- 缓存策略:对频繁查询的结果实施缓存,减少API调用次数和成本
- 参数验证:使用Pydantic模型验证输入参数,提前发现错误

第五章:未来展望
5.1 2026-2030工具技术发展预测
基于当前技术演进轨迹,LangChain Tools组件将呈现四大发展趋势:
工具学习自动化:到2026年,Tools系统将具备自动学习新工具使用的能力,无需人工编写描述和示例。模型通过分析工具API文档和少量使用记录,自动生成工具描述和调用规范,新工具集成时间从小时级缩短至分钟级。
多模态工具普及:2027年,工具生态将从纯文本处理扩展到多模态领域。图像处理、音频分析、视频理解等工具成为标准配置,支持真正的多模态AI应用开发。工具描述将包含多模态示例,提高模型理解准确率。
边缘工具协同:2028年,随着边缘计算发展,Tools将支持分布式部署。敏感数据在本地工具处理,非敏感计算在云端执行,实现隐私与性能的平衡。工具调用延迟将降低至毫秒级,支持实时性要求更高的应用场景。
自适应工具组合:2029年,系统将具备自动组合工具解决新问题的能力。面对复杂任务,AI能自动发现工具组合方案,甚至创建临时工具链,实现真正的问题解决能力而非固定流程执行。

5.2 Tools伦理框架建议
基于ISO/IEC 42001:2025标准,Tools系统需建立三重伦理防护:
透明度保障:工具调用过程全程可审计,用户可查看每个工具的输入输出和执行状态。关键决策工具需提供解释说明,增强系统可信度。
偏差控制:定期检测工具是否存在群体偏见,特别是影响公平性的决策工具(如信贷审批、招聘筛选)。建立工具公平性评估体系,确保不同群体获得平等服务。
权限管理:建立细粒度工具权限控制系统,不同用户角色只能访问授权工具。敏感工具(如资金操作、数据删除)需多层验证,防止滥用导致严重后果。
5.3 可验证预测模型
基于技术成熟度曲线理论,构建Tools技术发展预测模型:
- 2026年:40%的新增AI应用采用自动化工具学习技术
- 2027年:多模态工具成为企业级应用标配,覆盖率超70%
- 2028年:边缘-云协同工具架构在隐私敏感行业普及率达60%
- 2029年:自适应工具组合技术成熟,复杂问题解决能力提升5倍
- 2030年:Tools生态标准化完成,跨平台工具互操作性成为现实
该预测模型的准确度可通过工具调用准确率、新工具集成时间、多模态工具覆盖率等指标进行验证和修正。根据当前发展态势,到2028年,基于Tools的AI应用将占企业级AI方案的60%以上,成为人机协作的主要形式。