int n = 51000;
vector<int> father = vector<int>(n);
/*
错误的方法
class Foo(){
private:
vector<string> name(5); //error in these 2 lines
vector<int> val(5,0);
}
正确的方法
C++11以后:
class Foo(){
private:
vector<string> name = vector<string>(5);
vector<int> val{vector<int>(5,0)};
}
*/
// 并查集初始化
void init() {
for (int i = 0; i < father.size(); i++) {
father[i] = i;
}
}
// 并查集里寻根的过程:路径压缩
int find(int a) {
if (father[a] == a)
return a;
else
return father[a] = find(father[a]);
}
bool same(int a, int b) {
a = find(a);
b = find(b);
return a == b;
}
// 将a->b 这条边加入并查集
void join(int a, int b) {
a = find(a); //找根
b = find(b);
if (a == b)
return;
else
father[a] = b;
}
init();
class Solution {
public:
int n = 200001;
vector<int> father = vector<int>(n);
void init() {
for (int i = 0; i < n; i++) {
father[i] = i;
}
}
int find(int a) {
if (a == father[a])
return a;
else {
return father[a] = find(father[a]);
}
}
void join(int a, int b) {
a = find(a);
b = find(b);
if (a == b)
return;
else {
father[a] = b;
}
}
bool validPath(int n, vector<vector<int>>& edges, int source,
int destination) {
init();
for (auto& a : edges) {
join(a[0], a[1]);
}
return find(source) == find(destination);
}
};
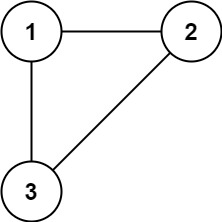
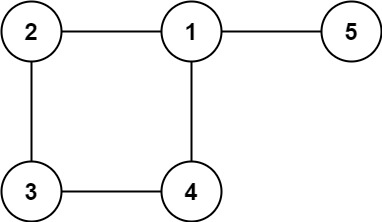
image-20240509155416437
class Solution {
public:
int n = 205;
vector<int> father{vector<int>(n)};
void init() {
for (int i = 0; i < n; i++) {
father[i] = i;
}
}
int find(int a) {
if (a == father[a])
return a;
else {
return father[a] = find(father[a]);
}
}
void join(int a, int b) {
a = find(a);
b = find(b);
if (a == b)
return;
else {
father[a] = b;
}
}
int findCircleNum(vector<vector<int>>& isConnected) {
init();
int len = isConnected.size();
for (int i = 0; i < len; i++) {
for (int j = 0; j < len; j++) {
if (isConnected[i][j]) {
join(i, j);
}
}
}
// 统计父节点的个数有两种方式:
// 1、使用set比较直观:但是复杂度高
// unordered_set<int> st;
// for (int i = 0; i < len; i++) {
// st.insert(find(i));
// }
// return st.size();
// 2、直接在范围内统计 father[i] == i为父节点,其他的都是指向父节点的子节点
int res = 0;
for(int i = 0;i<len;i++){
if(father[i]==i){
res++;
}
}
return res;
}
};
/*
思路:题目中有个环:环比树路径多,找到重复的路径
一般的树,不会出现,同一个根,只有环才可能出现两个节点的根一样
*/
class Solution {
public:
int n = 1001;
vector<int> father{vector<int>(n)};
void init() {
for (int i = 0; i < n; i++) {
father[i] = i;
}
}
int find(int a) {
if (a == father[a])
return a;
else
return father[a] = find(father[a]);
}
void join(int a, int b) {
a = find(a);
b = find(b);
if (a == b)
return;
father[a] = b;
}
vector<int> findRedundantConnection(vector<vector<int>>& edges) {
init();
vector<int> res;
for (auto& a : edges) {
if (find(a[0]) == find(a[1])) {
res = a;
break;
}
join(a[0], a[1]);
}
return res;
}
};
/*
思路:使用并查集将根节点都变成最小的,再遍历一下全换成根就行
有个坑点:if (find(s1[i]-'a') > find(s2[i]-'a'))
这里需要每次找到根,再去判断。
*/
class Solution {
public:
int n = 50;
vector<int> father = vector<int>(n);
void init() {
for (int i = 0; i < father.size(); i++) {
father[i] = i;
}
}
int find(int a) {
if (father[a] == a)
return a;
else
return father[a] = find(father[a]);
}
bool same(int a, int b) {
a = find(a);
b = find(b);
return a == b;
}
void join(int a, int b) {
a = find(a);
b = find(b);
if (a == b)
return;
else
father[a] = b;
}
string smallestEquivalentString(string s1, string s2, string baseStr) {
init();
for (int i = 0; i < s1.size(); i++) {
if (find(s1[i]-'a') > find(s2[i]-'a'))
join(s1[i] - 'a', s2[i] - 'a');
else
join(s2[i] - 'a', s1[i] - 'a');
}
for (auto& a : baseStr) {
a = find(a-'a')+'a';
}
return baseStr;
}
};
给定一个由表示变量之间关系的字符串方程组成的数组,每个字符串方程 equations[i] 的长度为 4,并采用两种不同的形式之一:"a==b" 或 "a!=b"。在这里,a 和 b 是小写字母(不一定不同),表示单字母变量名。
只有当可以将整数分配给变量名,以便满足所有给定的方程时才返回 true,否则返回 false。
示例 1:
复制代码
输入:["a==b","b!=a"]
输出:false
解释:如果我们指定,a = 1 且 b = 1,那么可以满足第一个方程,但无法满足第二个方程。没有办法分配变量同时满足这两个方程。
示例 2:
复制代码
输入:["b==a","a==b"]
输出:true
解释:我们可以指定 a = 1 且 b = 1 以满足满足这两个方程。
示例 3:
复制代码
输入:["a==b","b==c","a==c"]
输出:true
示例 4:
复制代码
输入:["a==b","b!=c","c==a"]
输出:false
示例 5:
复制代码
输入:["c==c","b==d","x!=z"]
输出:true
提示:
1 <= equations.length <= 500
equations[i].length == 4
equations[i][0] 和 equations[i][3] 是小写字母
equations[i][1] 要么是 '=',要么是 '!'
equations[i][2] 是 '='
c复制代码
/*
思路:取等号说明可以加入并查集
使用不等号进行判断:如果不等号两边是同一个根:说明之前等号过
注意:并查集加入似乎跟前后的顺序没有关系
*/
class Solution {
public:
int n = 30;
vector<int> father = vector<int>(n);
void init() {
for (int i = 0; i < n; i++) {
father[i] = i;
}
}
int find(int a) {
if (a == father[a])
return a;
return father[a] = find(father[a]);
}
void join(int a, int b) {
a = find(a);
b = find(b);
if (a == b)
return;
father[a] = b;
}
bool equationsPossible(vector<string>& equations) {
init();
for (auto& a : equations) {
if (a[1] == '=')
join(a[0] - 'a', a[3] - 'a');
}
for (auto& a : equations) {
if (a[1] == '!') {
if (find(a[0] - 'a') == find(a[3] - 'a')) {
return false;
}
}
}
return true;
}
};
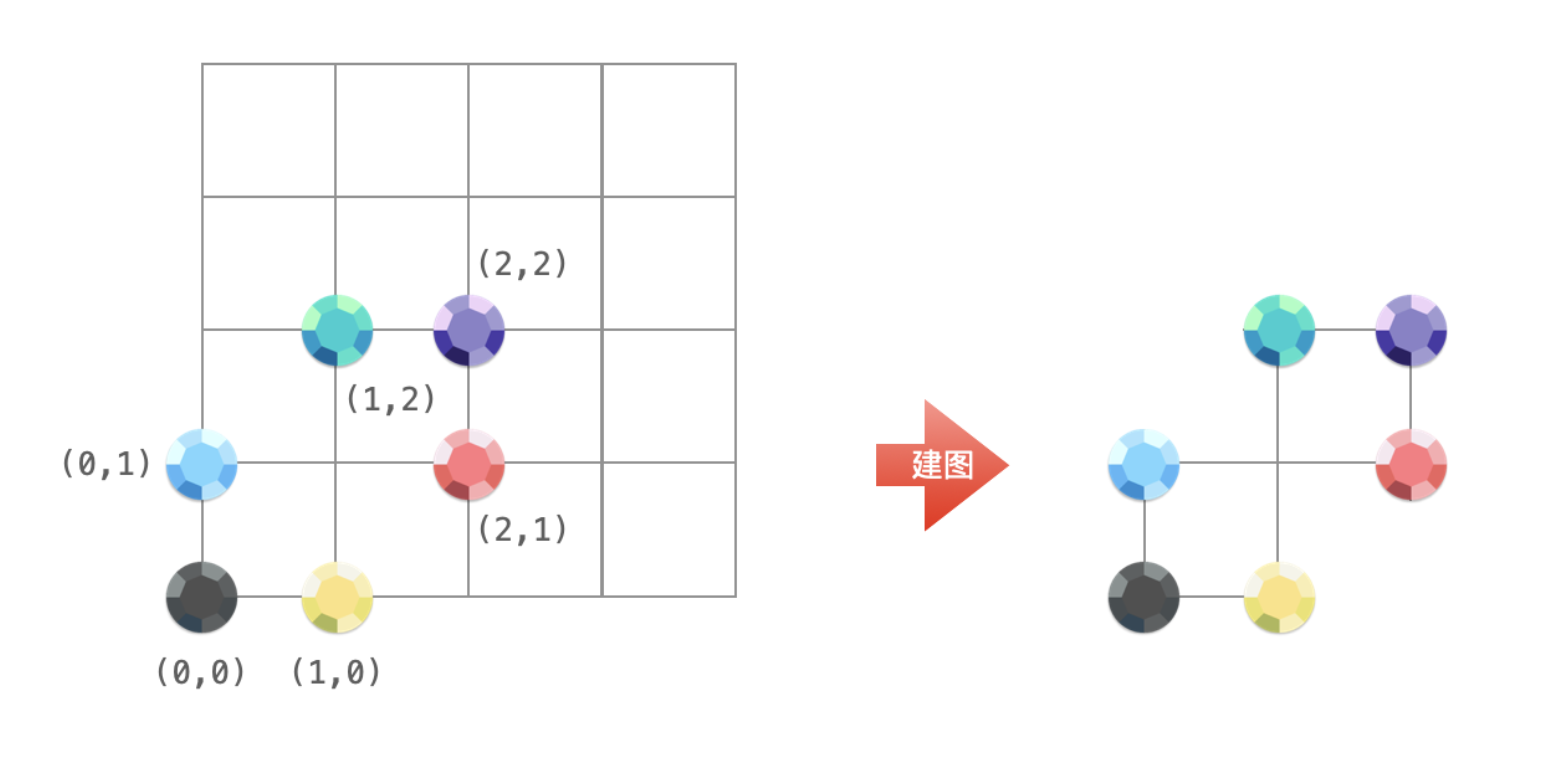
/*
思路难以想象:只能记模板:
把坐标x->y+10000上就能实现连通性分析问题:
只要在坐标上是联通的就可以得到同一个结果:同一个根:为什么?可以模拟出来,但是想不通
注意:Y需要加上最大值:为了解决
0 1
1 0
的问题
最后的结果都是:y的值最右边y的值
*/
class Solution {
public:
int n = 51000;
vector<int> father = vector<int>(n);
void init() {
for (int i = 0; i < father.size(); i++) {
father[i] = i;
}
}
int find(int a) {
if (father[a] == a)
return a;
else
return father[a] = find(father[a]);
}
bool same(int a, int b) {
a = find(a);
b = find(b);
return a == b;
}
void join(int a, int b) {
a = find(a);
b = find(b);
if (a == b)
return;
else
father[a] = b;
}
int removeStones(vector<vector<int>>& stones) {
init();
for (auto a : stones) {
join(a[0], a[1] + 20005);
}
unordered_map<int, int> mp;
for (auto a : stones) {
mp[find(a[0])] = 1;
}
return stones.size() - mp.size();
}
};