文章目录
- 引言:从回归到分类
- 广义线性模型回顾
- 从二分类到多分类
- Softmax函数的推导
- Softmax回归模型
- 最大似然估计与交叉熵损失
- Softmax回归的实现要点
- Softmax与逻辑回归的关系
- Softmax在神经网络中的应用
- Softmax的变体与扩展
- 实际应用案例
- 总结
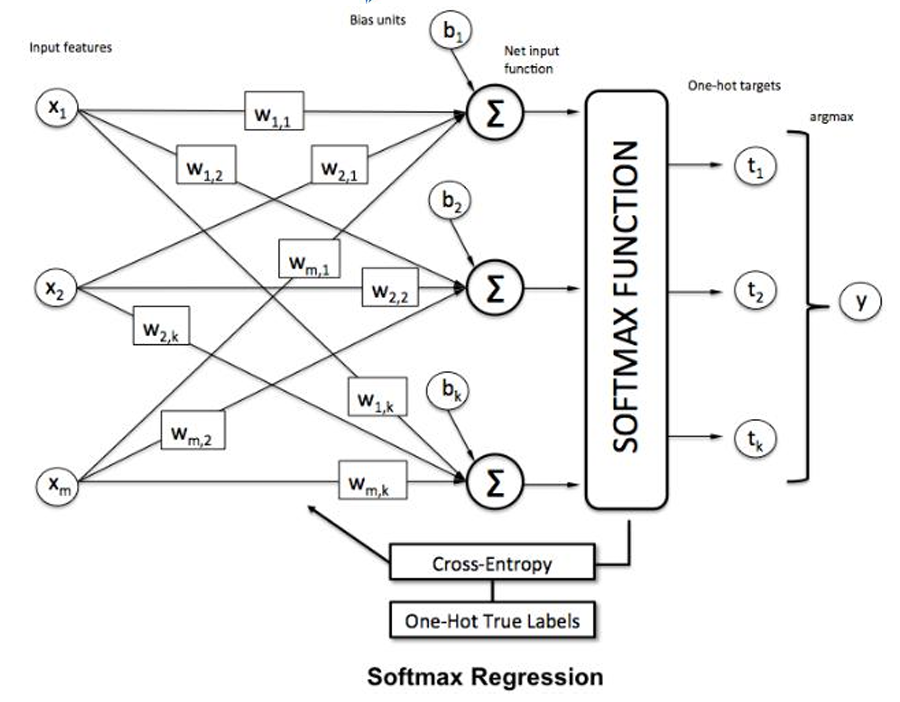
引言:从回归到分类
- 在机器学习领域,回归和分类是两大基本任务。线性回归处理连续值的预测,而当我们面对离散类别预测时,就需要分类模型。Softmax回归(也称为多项逻辑回归)是处理多分类问题的基础模型,它在神经网络中扮演着至关重要的角色,特别是在深度学习的分类任务中。
广义线性模型回顾
- 广义线性模型(GLM) 是线性回归的扩展,它通过连接函数(link function)将线性预测器与响应变量的期望值联系起来,并允许响应变量服从指数族分布。
- 一个广义线性模型由三个部分组成:
- 随机成分:响应变量 Y Y Y服从指数族分布
- 系统成分:线性预测器 η = X β η = Xβ η=Xβ
- 连接函数: g ( E Y ∣ X ) = η g(EY\|X) = η g(EY∣X)=η
- 对于线性回归,连接函数是恒等函数,响应变量假设服从高斯分布。而对于分类问题,我们需要不同的连接函数和分布假设。
从二分类到多分类
- 逻辑回归 是处理二分类问题的经典方法,它使用sigmoid函数将线性预测器的输出映射到 ( 0 , 1 ) (0,1) (0,1)区间,解释为概率:
P ( Y = 1 ∣ X ) = σ ( X β ) = 1 ( 1 + e ( − X β ) ) P(Y=1|X) = σ(Xβ) = \frac{1}{(1+e^{(-Xβ)})} P(Y=1∣X)=σ(Xβ)=(1+e(−Xβ))1 - 当我们需要处理 K K K个类别 ( K > 2 ) (K>2) (K>2)的分类问题时,就需要将其扩展为多项逻辑回归,即Softmax回归。
Softmax函数的推导
建模多类概率
- 假设我们有K个类别,每个类别都有自己的线性预测器:
η k = X β k , k = 1 , . . . , k η_k = Xβ_k, k=1,...,k ηk=Xβk,k=1,...,k - 我们需要将这些线性预测转换为类别概率,满足:
- 每个概率在0和1之间
- 所有类别概率之和为1
基于最大熵原理
- 从统计力学和信息论的角度,Softmax函数可以看作是最大熵模型在给定约束下的自然结果。我们希望找到在给定特征条件下类别分布的最大熵分布,同时满足特征与类别标签之间的期望约束。
具体推导步骤
-
假设对数几率比是线性的:
l n ( P ( Y = k ∣ X ) P ( Y = K ∣ X ) ) = X β k , k = 1 , . . . , K − 1 ln \frac{(P(Y=k|X)}{P(Y=K|X))} = Xβ_k, k=1,...,K-1 lnP(Y=K∣X))(P(Y=k∣X)=Xβk,k=1,...,K−1(选择类别K作为基准类别)
-
对上述等式取指数:
P ( Y = k ∣ X ) / P ( Y = K ∣ X ) = e ( X β k ) P(Y=k|X)/P(Y=K|X) = e^{(Xβ_k)} P(Y=k∣X)/P(Y=K∣X)=e(Xβk) -
令所有类别的概率和为1:
1 = Σ k = 1 K P ( Y = k ∣ X ) = P ( Y = K ∣ X ) 1 + Σ k = 1 K − 1 e ( X β k ) 1 = Σ_{k=1}^K P(Y=k|X) = P(Y=K|X) 1 + Σ_{k=1}\^{K-1} e\^{(Xβ_k)} 1=Σk=1KP(Y=k∣X)=P(Y=K∣X)1+Σk=1K−1e(Xβk) -
解得:
P ( Y = K ∣ X ) = 1 / ( 1 + Σ k = 1 K − 1 e ( X β k ) ) P(Y=K|X) = 1 / (1 + Σ_{k=1}^{K-1} e^{(Xβ_k)}) P(Y=K∣X)=1/(1+Σk=1K−1e(Xβk))对于k=1,...,K-1:
P ( Y = k ∣ X ) = e X β k P ( Y = k ∣ X ) = e ( X β k ) ( 1 + Σ j = 1 K − 1 e ( X β j ) ) P(Y=k|X) =e^{Xβ_k}P(Y=k|X)= \frac{e^{(Xβ_k)} }{ (1 + Σ_{j=1}^{K-1} e^{(Xβ_j)})} P(Y=k∣X)=eXβkP(Y=k∣X)=(1+Σj=1K−1e(Xβj))e(Xβk) -
为了对称性,我们也可以表示为(这就是Softmax函数):
P ( Y = k ∣ X ) = e ( X β k ) Σ j = 1 K e ( X β j ) P(Y=k|X) = \frac{e^{(Xβ_k) }}{ Σ_{j=1}^K e^{(Xβ_j)}} P(Y=k∣X)=Σj=1Ke(Xβj)e(Xβk)
Softmax函数的数学形式
- Softmax函数定义为:
σ ( z ) i = e ( z i ) Σ j = 1 K e ( z j ) , i = 1 , . . . , K σ(z)i = \frac{e^{(z_i)}} { Σ{j=1}^K e^{(z_j)}}, i=1,...,K σ(z)i=Σj=1Ke(zj)e(zi),i=1,...,K - 其中 z z z是输入向量, σ ( z ) i σ(z)_i σ(z)i表示第 i i i个输出元素。
Softmax回归模型
- 将Softmax函数应用于多分类问题,我们得到Softmax回归模型:
P ( Y = k ∣ X ) = e ( X β k ) Σ j = 1 K e ( X β j ) P(Y=k|X) = \frac{e^{(Xβ_k)}}{Σ_{j=1}^K e^{(Xβ_j)}} P(Y=k∣X)=Σj=1Ke(Xβj)e(Xβk) - 模型参数为{β_1,...,β_K},其中每个β_k都是一个与输入特征维度相同的向量。
参数的可辨识性
- 注意:如果将所有β_k加上一个相同的向量c,概率预测不会改变:
P ( Y = k ∣ X ) = e ( X ( β k + c ) ) ∑ j = 1 K e ( X ( β j + c ) ) = e ( X β k ) e ( X c ) ∑ j = 1 K e ( X β j ) e ( X c ) = e ( X β k ) ∑ j = 1 K e ( X β j ) \begin{align*} P(Y=k|X) &= \frac{ e^{ (X(\beta_k + c)) }}{\sum_{j=1}^K e^{(X(\beta_j + c))}} \\ &= \frac{e^{(X\beta_k)} e^{(Xc)}}{\sum_{j=1}^K e^{(X\beta_j)} e^{(Xc)}} \\ &= \frac{e^{(X\beta_k)}}{\sum_{j=1}^K e^{(X\beta_j)}} \end{align*} P(Y=k∣X)=∑j=1Ke(X(βj+c))e(X(βk+c))=∑j=1Ke(Xβj)e(Xc)e(Xβk)e(Xc)=∑j=1Ke(Xβj)e(Xβk)
推导过程说明:
- 第一行:原始Softmax公式,所有参数加上常数向量c
- 第二行:利用指数函数的性质将 e ( X ( β + c ) ) e^{(X(β+c))} e(X(β+c))拆分为 e ( X β ) e ( X c ) e^{(Xβ)}e^{(Xc)} e(Xβ)e(Xc)
- 第三行:分子分母中的exp(Xc)项相互抵消,结果与原始Softmax公式相同
- 因此,模型参数不是唯一可辨识的。通常我们通过设置一个基准类别(如 β K = 0 β_K=0 βK=0)来解决这个问题,这与最初的推导一致。
最大似然估计与交叉熵损失
似然函数
给定训练数据 ( x i , y i ) i = 1 N {(x_i,y_i)}{i=1}^N (xi,yi)i=1N,似然函数为:
L ( β ) = Π i = 1 N P ( Y = y i ∣ x i ) L(β) = Π{i=1}^N P(Y=y_i|x_i) L(β)=Πi=1NP(Y=yi∣xi)
对数似然:
l ( β ) = l n L ( β ) = Σ i = 1 N l n P ( Y = y i ∣ x i ) = Σ i = 1 N l n e ( X β k ) ∑ j = 1 K e ( X β j ) = Σ i = 1 N X i β y i − l n ( Σ j = 1 K e ( X i β j ) ) \begin{align*} l(β) &=lnL(β) \\ &= Σ_{i=1}^N ln P(Y=y_i|x_i) \\ &= Σ_{i=1}^N ln \frac{e^{(X\beta_k)}}{\sum_{j=1}^K e^{(X\beta_j)}} \\ &= Σ_{i=1}^N X_iβ_{y_i} - ln(Σ_{j=1}\^K e\^{(X_iβ_j))} \end{align*} l(β)=lnL(β)=Σi=1NlnP(Y=yi∣xi)=Σi=1Nln∑j=1Ke(Xβj)e(Xβk)=Σi=1NXiβyi−ln(Σj=1Ke(Xiβj))
交叉熵损失
- 最大化似然等价于最小化负对数似然,这定义了我们的损失函数:
J ( β ) = − Σ i = 1 N X i β y i − l n ( Σ j = 1 K e ( X i β j ) ) = Σ i = 1 N − X i β y i + l n ( Σ j = 1 K e ( X i β j ) ) \begin{align*} J(β) &= -Σ_{i=1}^N X_iβ_{y_i} - ln(Σ_{j=1}\^K e\^{(X_iβ_j))} \\ &= Σ_{i=1}^N -X_iβ_{y_i} + ln(Σ_{j=1}\^K e\^{(X_iβ_j))} \end{align*} J(β)=−Σi=1NXiβyi−ln(Σj=1Ke(Xiβj))=Σi=1N−Xiβyi+ln(Σj=1Ke(Xiβj))
这实际上就是交叉熵损失在多分类情况下的形式。
梯度计算
- 为了使用梯度下降优化参数,我们需要计算损失函数对参数的梯度:
∂ J / ∂ β k = − Σ i = 1 N 1 ( y i = k ) − P ( Y = k ∣ x i ) X i ∂J/∂β_k = -Σ_{i=1}^N 1(y_i=k) - P(Y=k\|x_i) X_i ∂J/∂βk=−Σi=1N1(yi=k)−P(Y=k∣xi)Xi
这个优雅的结果表明,梯度是特征向量在预测误差上的加权和。
Softmax回归的实现要点
数值稳定性
在实际实现中,直接计算 e ( X β ) e^{(Xβ)} e(Xβ)可能会遇到数值上溢或下溢的问题。常见的解决方案是使用以下恒等式:
σ ( z ) i = e ( z i − C ) Σ j e ( z j − C ) σ(z)_i = \frac{e^{(z_i - C)}} {Σ_j e^{(z_j - C)}} σ(z)i=Σje(zj−C)e(zi−C)
其中C通常取 m a x ( z i ) max(z_i) max(zi),保证了数值计算的稳定性。
正则化
为了防止过拟合,通常会在损失函数中加入正则化项,如L2正则化:
J ( β ) + = λ Σ k = 1 K ∣ ∣ β k ∣ ∣ 2 2 J(β) += \frac{λ Σ_{k=1}^K ||β_k||^2}{2} J(β)+=2λΣk=1K∣∣βk∣∣2
Softmax与逻辑回归的关系
- 当K=2时,Softmax回归退化为标准的逻辑回归。可以证明两者在这种情况下是等价的。
一、模型形式等价性证明
-
Softmax回归的一般形式 (K类):
P ( Y = k ∣ X ) = e θ k T X ∑ j = 1 K e θ j T X ( k = 1 , . . . , K ) P(Y=k|X) = \frac{e^{\theta_k^T X}}{\sum_{j=1}^K e^{\theta_j^T X}} \quad (k=1,...,K) P(Y=k∣X)=∑j=1KeθjTXeθkTX(k=1,...,K) -
当K=2时的特殊形式 :
{ P ( Y = 1 ∣ X ) = e θ 1 T X e θ 1 T X + e θ 2 T X P ( Y = 2 ∣ X ) = e θ 2 T X e θ 1 T X + e θ 2 T X \begin{cases} P(Y=1|X) = \frac{e^{\theta_1^T X}}{e^{\theta_1^T X} + e^{\theta_2^T X}} \\ P(Y=2|X) = \frac{e^{\theta_2^T X}}{e^{\theta_1^T X} + e^{\theta_2^T X}} \end{cases} ⎩ ⎨ ⎧P(Y=1∣X)=eθ1TX+eθ2TXeθ1TXP(Y=2∣X)=eθ1TX+eθ2TXeθ2TX -
参数冗余消除(令β = θ₁ - θ₂):
- 分子分母同除 e θ 1 T X e^{\theta_1^T X} eθ1TX:
P ( Y = 1 ∣ X ) = 1 1 + e ( θ 2 − θ 1 ) T X = 1 1 + e − β T X = σ ( β T X ) P(Y=1|X) = \frac{1}{1 + e^{(\theta_2 - \theta_1)^T X}} = \frac{1}{1 + e^{-\beta^T X}} = \sigma(\beta^T X) P(Y=1∣X)=1+e(θ2−θ1)TX1=1+e−βTX1=σ(βTX) - 这正是sigmoid函数的标准形式
- 分子分母同除 e θ 1 T X e^{\theta_1^T X} eθ1TX:
-
类别对称性 :
P ( Y = 2 ∣ X ) = 1 − σ ( β T X ) = σ ( − β T X ) P(Y=2|X) = 1 - \sigma(\beta^T X) = \sigma(-\beta^T X) P(Y=2∣X)=1−σ(βTX)=σ(−βTX)
二、损失函数等价性证明
-
Softmax交叉熵损失 (K=2):
L = − ∑ i = 1 N y i ln P ( Y = 1 ∣ X i ) + ( 1 − y i ) ln P ( Y = 2 ∣ X i ) \mathcal{L} = -\sum_{i=1}^N \left y_i \\ln P(Y=1\|X_i) + (1-y_i) \\ln P(Y=2\|X_i) \\right L=−i=1∑NyilnP(Y=1∣Xi)+(1−yi)lnP(Y=2∣Xi) -
代入概率表达式 :
L = − ∑ i = 1 N y i ln σ ( β T X i ) + ( 1 − y i ) ln ( 1 − σ ( β T X i ) ) \mathcal{L} = -\sum_{i=1}^N \left y_i \\ln \\sigma(\\beta\^T X_i) + (1-y_i) \\ln (1 - \\sigma(\\beta\^T X_i)) \\right L=−i=1∑Nyilnσ(βTXi)+(1−yi)ln(1−σ(βTXi)) -
与逻辑回归损失完全一致:
- 这正是二分类逻辑回归的二元交叉熵损失函数
- 梯度更新规则也完全相同:
∇ β L = ∑ i = 1 N ( σ ( β T X i ) − y i ) X i \nabla_\beta \mathcal{L} = \sum_{i=1}^N (\sigma(\beta^T X_i) - y_i)X_i ∇βL=i=1∑N(σ(βTXi)−yi)Xi
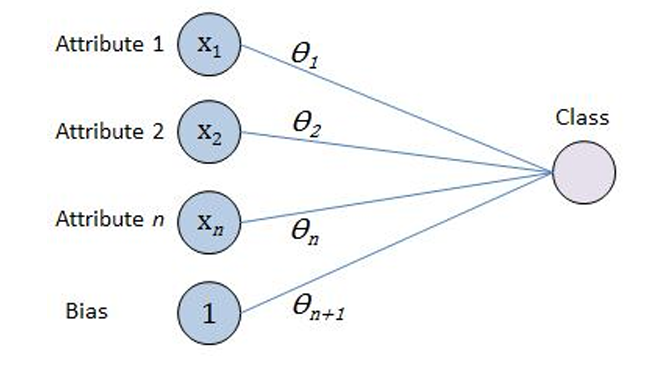
三、几何解释
-
决策边界对比:
- Softmax(K=2): ( θ 1 − θ 2 ) T X = 0 (\theta_1 - \theta_2)^T X = 0 (θ1−θ2)TX=0
- 逻辑回归: β T X = 0 \beta^T X = 0 βTX=0
- 两者定义相同的超平面决策边界
-
参数空间关系:
- Softmax有冗余参数(可设θ₂=0)
- 此时θ₁即对应逻辑回归的β参数
四、实际应用验证
python
# 用相同数据验证两种模型的等价性
import numpy as np
from sklearn.linear_model import LogisticRegression
from sklearn.linear_model import LogisticRegression as Softmax2
# 生成二分类数据
X = np.random.randn(100, 3)
y = (X[:, 0] > 0).astype(int)
# 训练模型
#multi_class='multinomial' 参数在 scikit-learn 1.5 版本中已被弃用,并将在 1.7 版本中移除。
#对于二分类任务,建议直接使用默认的逻辑回归模型(即自动采用 multi_class='ovr)
lr = LogisticRegression( solver='lbfgs').fit(X, y) # Softmax K=2
logit = LogisticRegression().fit(X, y) # 标准逻辑回归
# 比较参数(需注意符号方向)
assert np.allclose(lr.coef_[0], logit.coef_[0])五、重要注意事项
-
参数化差异:
- Softmax默认使用多参数形式(K个参数向量)
- 逻辑回归使用单参数形式(1个参数向量)
-
实现细节:
- 软件包中可能对截距项处理不同
- 类别标签编码方式(0/1 vs 1/2)会影响常数项
-
统计解释:
- 两者都是广义线性模型的特例
- 均采用最大似然估计,具有相同的统计效率
这个证明体系从代数形式、优化目标、几何意义到实际验证四个维度,完整展现了Softmax回归与逻辑回归在二分类场景下的本质一致性。这种等价关系也解释了为什么在神经网络中,二分类输出层可以使用单个sigmoid单元替代Softmax层。
Softmax在神经网络中的应用
- 在深度学习中,Softmax通常作为神经网络的最后一层,用于多分类任务:
- 前面的层学习特征表示
- 最后一层线性变换产生每个类别的"得分"
- Softmax将这些得分转换为概率分布
反向传播中的梯度
在神经网络中,Softmax层与交叉熵损失结合使用时,梯度计算特别简洁:
∂ J / ∂ z i = p i − y i ∂J/∂z_i = p_i - y_i ∂J/∂zi=pi−yi
其中 z i z_i zi是输入到Softmax的得分, p i p_i pi是Softmax输出概率, y i y_i yi是真实标签的one-hot编码。
Softmax的变体与扩展
- 温度参数
- 引入温度参数T控制输出的"尖锐"程度:
σ ( z ) i = e ( z i / T ) Σ j e ( z j / T ) σ(z)_i = \frac{e^{(z_i/T)} }{Σ_j e^{(z_j/T)}} σ(z)i=Σje(zj/T)e(zi/T)
较高的T使分布更均匀,较低的T使分布更集中。
- 稀疏Softmax:通过添加稀疏性约束或使用top-k变体,可以产生稀疏的概率分布。
实际应用案例
- 手写数字识别:在MNIST数据集中,Softmax回归可以直接达到约92%的准确率,作为强大的基线方法。
- 自然语言处理:在语言模型中,Softmax用于预测下一个词的概率分布,尽管对于大词汇表需要采样或层次化技巧。
- 计算机视觉:现代CNN架构通常在最后一层使用Softmax进行图像分类。
总结
- Softmax回归从广义线性模型的角度自然导出,为多分类问题提供了坚实的概率基础。通过最大似然估计,我们得到了广泛使用的交叉熵损失函数。在深度学习中,Softmax作为将原始得分转换为概率分布的标准方法,与神经网络完美结合。理解其数学原理不仅有助于正确应用,还能为模型调试和扩展提供坚实基础。