一、常用数据处理模块Numpy
Numpy常用于高性能计算,在机器学习常常作为传递数据的容器。提供了两种基本对象:ndarray、ufunc。
ndarray具有矢量算术运算和复杂广播能力的快速且节省空间的多维数组。
ufunc提供了对数组快速运算的标准数学函数。
ndarry
创建
创建一维和二维数组,显示其属性值
python
import numpy as np
# 创建一维数组和二维数组,显示其属性值
a1 = np.array([1,2,3,4,3,5,6,9])
print(a1)
a2 = np.array([[1,2,3], [4,5,6], [7,8,9]])
print(a2)
# 特殊的ndarray
a3 = np.arange(1,100,5)
print('a3:\n', a3)
a4 = np.linspace(1,100,5)
print('a4:\n', a4)
a5 = np.logspace(1,3, 2)
print('a5:\n', a5)
a6 = np.logspace(0, 9, 10, base=2)
print('a6:\n', a6)
a7 = np.zeros((3,4))
print('a7:\n', a7)
a8 = np.eye(5)
print('a8:\n', a8)
a9 = np.ones((2,3))
print('a9:\n', a9)
a10 = np.diag([1,2,3,5])
print('a10:\n', a10)结果

|------------------------|--------------------------------|
| arange | 等差数列(开始值,终值,步长) |
| linspace | 等差数列(开始值,终值,元素数量) |
| logspace(a,b,c,base=d) | 等比数列(10的a次方到10的b次方共c个,基d默认为10) |
| zeros | 全为0的矩阵 |
| ones | 全为1的矩阵 |
| eye | 单位矩阵(对角线元素为1,其余为0) |
| diag | 对角矩阵(对角线元素为特定值,其余为0) |
索引与切片
python
import numpy as np
# 一维数组的索引和切片
a1 = np.arange(10)
print('a1:\n', a1)
print(a1[5])
print(a1[3:6])
print(a1[:-1])
print(a1[5:1:-2])
# 二维数组的索引和切片
a2 = np.array([[11,12,13,14,15], [21,22,23,24,25], [31,32,33,34,35]])
print('a2:\n', a2)
print(a2[0,3:5])
print(a2[1:,2:])
print(a2[:,2:])设置形状
python
import numpy as np
# 设置数组形状
a = np.arange(12)
print('生成一个一维数组a:\n', a)
a = a.reshape(3,4)
print(a)
a.resize(2,6)
print(a)
a.shape = (4,3)
print(a)展平
python
import numpy as np
# 展平数组
a = np.arange(12).reshape(3,4)
print('生成一个3*4数组a:\n',a)
b = a.ravel()
print('按行展平a:',b)
c = a.flatten('F')
print('按行展平a:',c)排序
python
import numpy as np
a = np.array([[1,12,3,9],[2,4,6,8],[10,11,7,5]])
print(a)
print('调用sort函数')
print(np.sort(a))
print('按列排序:')
print(np.sort(a,axis = 0))
# 在sort函数种排序字段
dt = np.dtype([('name','S10'),('age',int)])
ar = np.array([('fang', 26),('jie', 24),('ahao', 25),('ming', 22),('ajie', 28),('quan', 19)],dtype=dt)
print('原数组:\n',ar)
print('按name排序:\n')
print(np.sort(ar, order='name'))
print('按age排序:\n')
print(np.sort(ar, order='age'))搜索
python
import numpy as np
x = np.arange(9).reshape(3,3)
print(x)
print('大于3的元素的索引:')
y = np.where(x>3)
print(y)
print('使用这些索引搜索满足要求的元素')
print(x[y])
print('返回满足要求的元素')
condition = np.mod(x,2) == 0
print(np.extract(condition,x))ufunc
算术运算、三角运算、集合运算、比较运算、逻辑运算、统计运算。
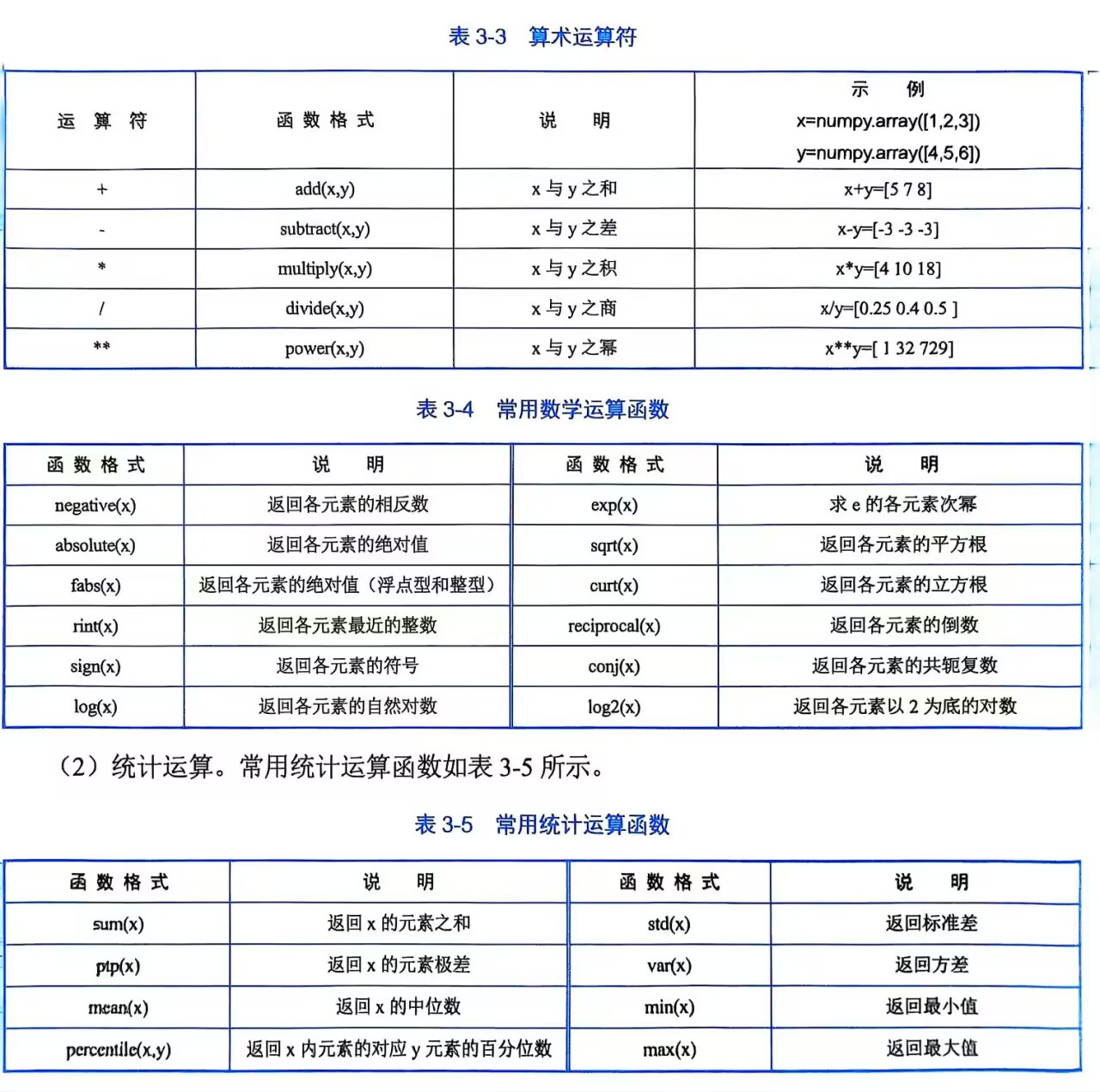
计算矩阵面积
python
import numpy as np
# 计算矩阵乘积(左上为1*5+2*7=19)
a = [[1,2],[3,4]]
b = [[5,6],[7,8]]
print(np.matmul(a,b))结果:
\[19 22
43 50\]
注:矩阵面积为左边的行乘右边的列,详见线性代数。结果的左上角19 = 1*5+2*7
二、常用数据处理模块Pandas
Pandas是基于Numpy创建的,为Python提供高性能、易使用的数据结构和数据分析工具。主要有Series和DataFrame
Series:基本数据结构,一维标签数组,能够保存任何数据类型
DataFrame:基本数据结构,一般为二维数组
Series
创建
pandas.Series(一维数组,数据索引标签(默认从0开始),数据类型,名称)
python
import numpy as np
import pandas as pd
# 用ndarray创建Series数据对象
print(pd.Series(np.arange(5),index=['a','b','c','d','e']))
# 用dict创建Series数据对象
print(pd.Series({'y':84,'h':94, 'w':96}))
# 用list创建Series数据对象
print(pd.Series([10,20,30],index=['a','b','c']))数据访问
python
import pandas as pd
import numpy as np
data = np.arange(5)
s = pd.Series(data,index=['a','b','c','d','e'])
print(s)
print(s['b'])
s['c'] = 75
print(s)DataFrame
创建
python
import numpy as np
import pandas as pd
dict1 = {'col1':[0,1,2,3],'col2':[4,5,6,7]}
print(pd.DataFrame(dict1))
list1 = [[30,45],[65,76],[25,86]]
print(pd.DataFrame(list1, index=['a','b','c'],columns=['A','B']))访问
python
import numpy as np
import pandas as pd
dict1 = {'col1':[0,1,2,3],'col2':[4,5,6,7]}
print(pd.DataFrame(dict1))
list1 = [[30,45],[65,76],[25,86]]
print(pd.DataFrame(list1, index=['a','b','c'],columns=['A','B']))增、删、改
python
import pandas as pd
dict = {'y':[90,76,82,61,62,72],'a':[75,73,86,85,91,76],'b':[66,64,74,89,85,90]}
d = pd.DataFrame(dict)
print(d)
d['y'] = [80,82,86,92,95,77]
d['g'] = [90,96,85,84,83,93]
print(d)
d.drop(['y','g'],axis=1,inplace=True)
print(d)三、常用数据可视化模块Matplotlib
一个2D绘图库。
matplotlib是最基础的扩展包,为pandas、seaborn提供基础绘图概念与语法。
它虽然不能直接提供绘制折线图的函数,但可以借助散点函数绘制折线图。
在我看来,它与MATLAB相比虽然需要手工导入函数,但可以与其他库配合使用。
柱状图
python
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
month = ['一月','二月','三月','四月','五月']
sales_amounts = [26, 75, 89, 56, 64]
month_index = range(len(month))
fig = plt.figure()
ax1 = fig.add_subplot(1,1,1)
ax1.bar(month_index, sales_amounts,align='center',color='darkblue')
ax1.xaxis.set_ticks_position('bottom')
ax1.yaxis.set_ticks_position('left')
plt.xticks(month_index,month,rotation=0,fontsize='small')
plt.xlabel('月份')
plt.ylabel('销售额')
plt.title('每个月的销售额')
plt.savefig('matplotlib336.png')饼图
python
from matplotlib import pyplot as plt
import numpy as np
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
fig = plt.figure()
ax = fig.add_subplot(1,1,1)
ax.axis('equal')
langs = ['数学', '程序设计', '外语', '数据库']
students = [24,27,39,35]
ax.pie(students, labels=langs, autopct='%1.4f%%')
plt.savefig('matplotlib337.png')折线图
python
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
x = ['day1','day2','day3','day4','day5','day6','day7']
y = [36,54,62,61,75,82,83]
plt.plot(x,y,'g',marker='D',markersize=5,label='积分')
plt.xlabel('天数')
plt.ylabel('完成任务数量')
plt.title('title')
plt.legend(loc='best')
plt.savefig('matplotlib338.png')四、数据收集、整理与清洗
数据收集
方法:
1.通过现有网络平台进行数据抽取而获得数据。
2.利用设备收集。利用各类传感器从系统外部收集数据并输入到系统内部。
3.系统日志采集方法。
4.网络数据采集方法。
以爬虫为例介绍如何从网络获取数据。
爬虫通过模拟是计算机对服务器端发起Request请求,接受服务器端的Response回应并解析,提取得到所需信息。
通过Python程序进行网络爬虫获取相关数据主要涉及3个Python库:Requests、Lxml、BeautifulSoup。
①Requests库的作用主要是请求网站获取网页数据。
python
import requests
res = requests.get('http://www.baidu.com')
print(res)
print(res.text)②Lxml为XML解析库,同时很好的支持HTML文档的解析功能,除了能直接读取字符串,也能从文件中提取内容。
③BeautifulSoup库用于解析Requests库请求的网页,并把网页源代码解析为Soup文档,以便过滤和提取数据。
例:爬取《天工开物》
python
from urllib.request import urlopen
url = 'https://www.gutenberg.org//files/25273/25273-0.txt'
text = urlopen(url).read()
text = text.decode('utf-8')
print(len(text))
text1 = text[596:733]
print(text1)
print()
import opencc
cc = opencc.OpenCC('t2s')
print(cc.convert(text1))
例:爬取豆瓣图书TOP250的信息
python
from lxml import etree
import requests
import csv
fp = open('D:/pythoncode/aiSelf/P114book.csv','wt',newline="", encoding='utf-8')
writer = csv.writer(fp)
writer.writerow(('name','url','author','publisher','date','price','rate','comment'))
urls = ['https://book.douban.com/top250?start={}'.format(str(i)) for i in range(0,250,25)]
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/135.0.0.0 Safari/537.36 Edg/135.0.0.0'
}
for url in urls:
html = requests.get(url, headers=headers)
selector = etree.HTML(html.text)
infos = selector.xpath('//tr[@class="item"]')
for info in infos:
name = info.xpath('td/div/a/@title')[0]
url = info.xpath('td/div/a/@href')[0]
book_infos = info.xpath('td/p/text()')[0]
author = book_infos.split('/')[0]
publisher = book_infos.split('/')[-3]
date = book_infos.split('/')[-2]
price = book_infos.split('/')[-1]
rate = info.xpath('td/div/span[2]/text()')[0]
comments = info.xpath('td/p/span/text()')
comment = comments[0] if len(comments)>0 else '空'
writer.writerow((name,url,author,publisher,date,price,rate,comment))
fp.close()
print('ok')
数据整理
文本内容查找
python
import re
f = open('D:/pythoncode/aiSelf/p115hello.txt')
source = f.read()
f.close()
r = 'hello'
s = len(re.findall(r,source))
print(s)文本内容替换
python
import re
f1 = open('D:/pythoncode/aiSelf/p115hello.txt')
f2 = open('D:/pythoncode/aiSelf/p115hello2.txt','r+')
for s in f1.readlines():
f2.write(s.replace('hello','hi'))
f1.close()
f2.close()文本内容排序
python
f = open('d:/pythoncode/aiSelf/p115hello3.txt')
result = list()
for line in f.readlines():
line = line.strip()
if not len(line) or line.startswith('#'):
continue
result.append(line)
result.sort()
print(result)
open('D:/pythoncode/aiSelf/p115hello3out.txt','w').write('\n'.join(result))数据清洗
数据清洗方法
人工检查,手工实现;通过专门编写的应用程序实现;解决某类特定应用域的问题;清理与特定应用领域无关数据。
isnull检查数据是否缺失
fillna不滤除缺失数据,以某值补上
|-------------------|------------------------------------|
| isnull() | 判断是否空值 |
| fillna() | 用某值替换NAN |
| mean() | 平均数 |
| median() | 中位数 |
| mode() | 众数(可能返回多个) |
| duplicated() | 判断是否为重复行。 DataFrame的该方法返回布尔型Series |
| drop_duplicates() | 去重。 DataFrame的该方法返回去重后的DataFrame |
对众数的补充说明
python
data = Series([3,3,3,2,2,2,7,7,7,6,5])
print(data.mode())
print(data.mode()[0])上述代码中,2,3,7都是众数。对于不止一个的众数,可以用下标指定某一个众数。

检查数据是否缺失
python
from pandas import Series, DataFrame
from numpy import nan as NA
string_data = Series(['abcd','efgh','ijkl',NA])
print(string_data)
print('......\n')
print(string_data.isnull())以某值填充,不剔除缺失数据
python
import numpy as np
from pandas import Series, DataFrame
from numpy import nan as NA
data = DataFrame(np.random.randn(7,3))
data.iloc[:4,1] = NA
data.iloc[:2,2] = NA
print(data)
print("....")
print(data.fillna(1))字典不同列填充不同值
python
import numpy as np
from pandas import Series, DataFrame
from numpy import nan as NA
data = DataFrame(np.random.randn(7,3))
data.iloc[:4,1] = NA
data.iloc[:2,2] = NA
print(data)
print(".....")
print(data.fillna({1:111,2:222}))用平均数、中位数补充缺失值
python
import numpy as np
from pandas import DataFrame, Series
from numpy import nan as NA
data1 = Series([1.0, NA, 3.5, NA, 7])
data2 = Series([1.0, NA, 3.5, NA, 7])
print(data1)
print("......")
print(data1.fillna(data1.mean()))
print("......")
print(data2.fillna(data2.median()))判断有无重复数据
python
import numpy as np
import pandas as pd
from pandas import DataFrame, Series
from numpy import nan as NA
data = pd.DataFrame({'k1':['one']*3+['two']*4,'k2':[1,1,2,2,3,3,4]})
print(data)
print(".....")
print(data.duplicated())数据去重
python
from pandas import DataFrame, Series
from numpy import nan as NA
import numpy as np
import pandas as pd
data = pd.DataFrame({'k1':['one']*3+['two']*4,'k2':[1,1,2,2,3,3,4]})
print(data)
print(".....")
print(data.drop_duplicates())图像处理
数字图像处理技术
图像变换、图像编码压缩、图像增强和复原图像、图像分割、图像描述、图像分类(识别)。
图像格式转化
PIL的9种模式
|-------|-------|-------------------------|
| 模式 | 每像素 | 说明 |
| 1 | 8bit | 二值图像;非黑即白,0黑255白 |
| L | 8bit | 灰度图像;0黑255白,其他数字为不同灰度 |
| P | 8bit | 8位彩色图像; |
| RGB | | 三通道图像;返回图像对象的默认模式 |
| RGBA | 32bit | 红绿蓝三通道+Alpha透明通道,各8bit |
| CMYK | 32bit | 印刷四分色模式 |
| YCbCr | 24bit | Y亮度分量,Cb蓝色色度分量,Cr红色色度分量 |
| I | 32bit | 整型灰度图像;0黑255白,其他数字为不同灰度 |
| F | | |
RGB模式转化为不同模式公式
L = I = R*299/1000 + G*587/1000 + B*114/1000
Y = R*0.257 + G*0.564 + B*0.098 + 16
Cb = -R*0.148 - G*0.291 + B*0.439 +128
Cr = R*0.439 - G*0.368 - B*0.071 + 128
其他必需知识
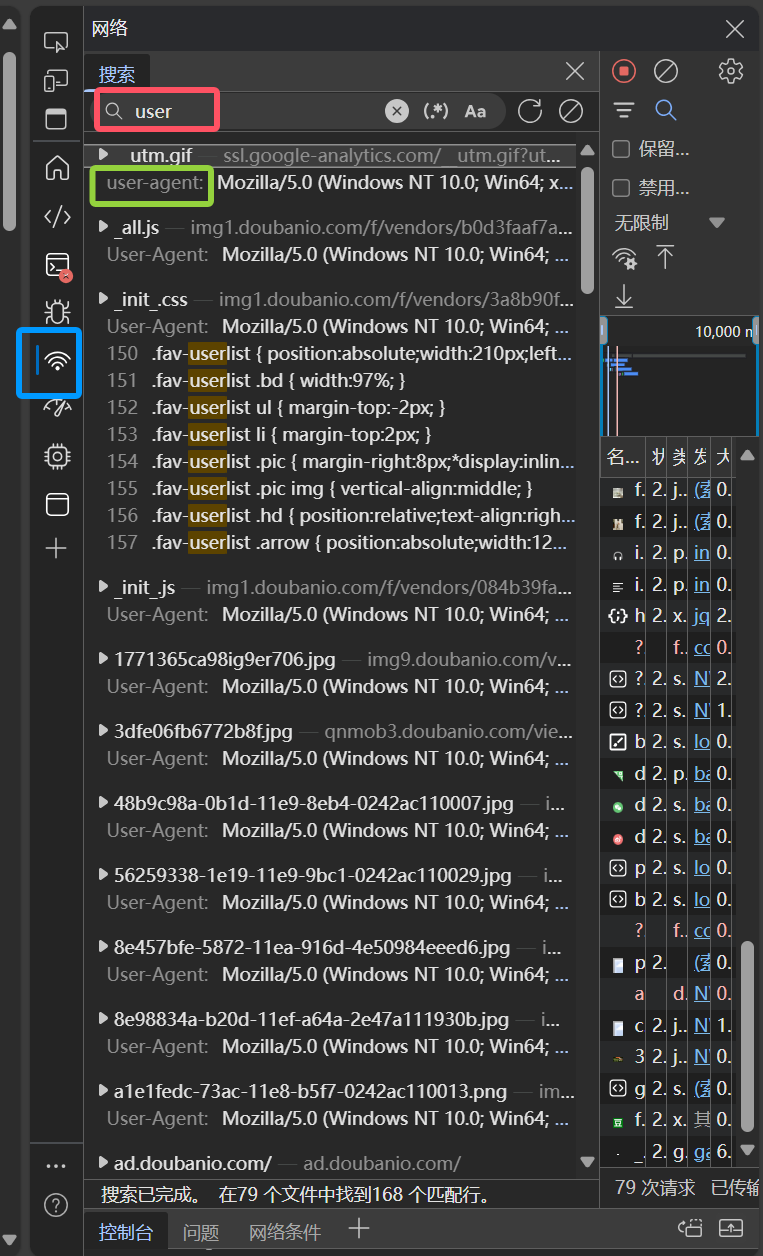
user-agent的获取
进入目标网页,按F12或右键检查,进入控制台,找到网络(蓝色框),刷新网页后输入user(红色框)找到user-agent(绿色框),复制。
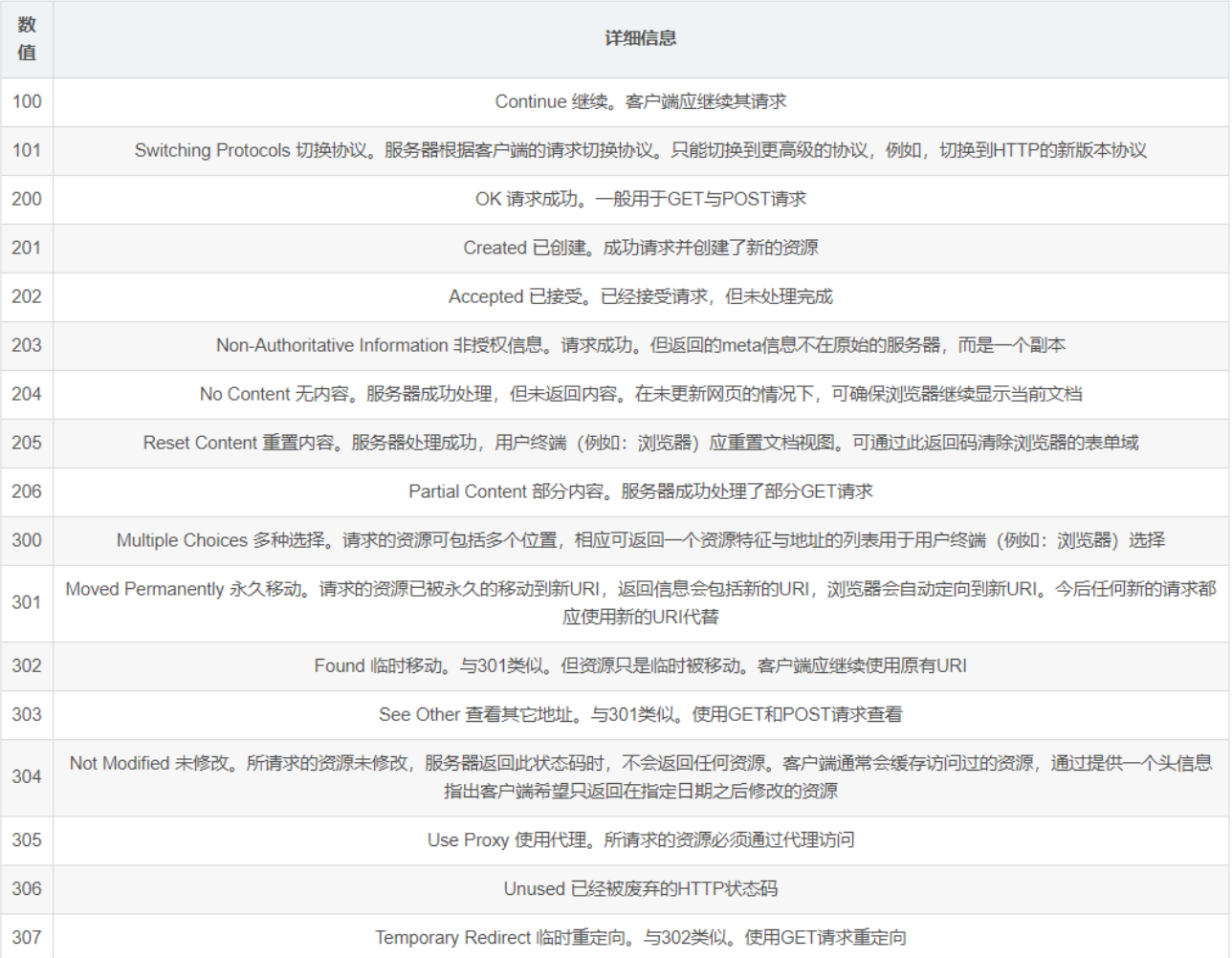
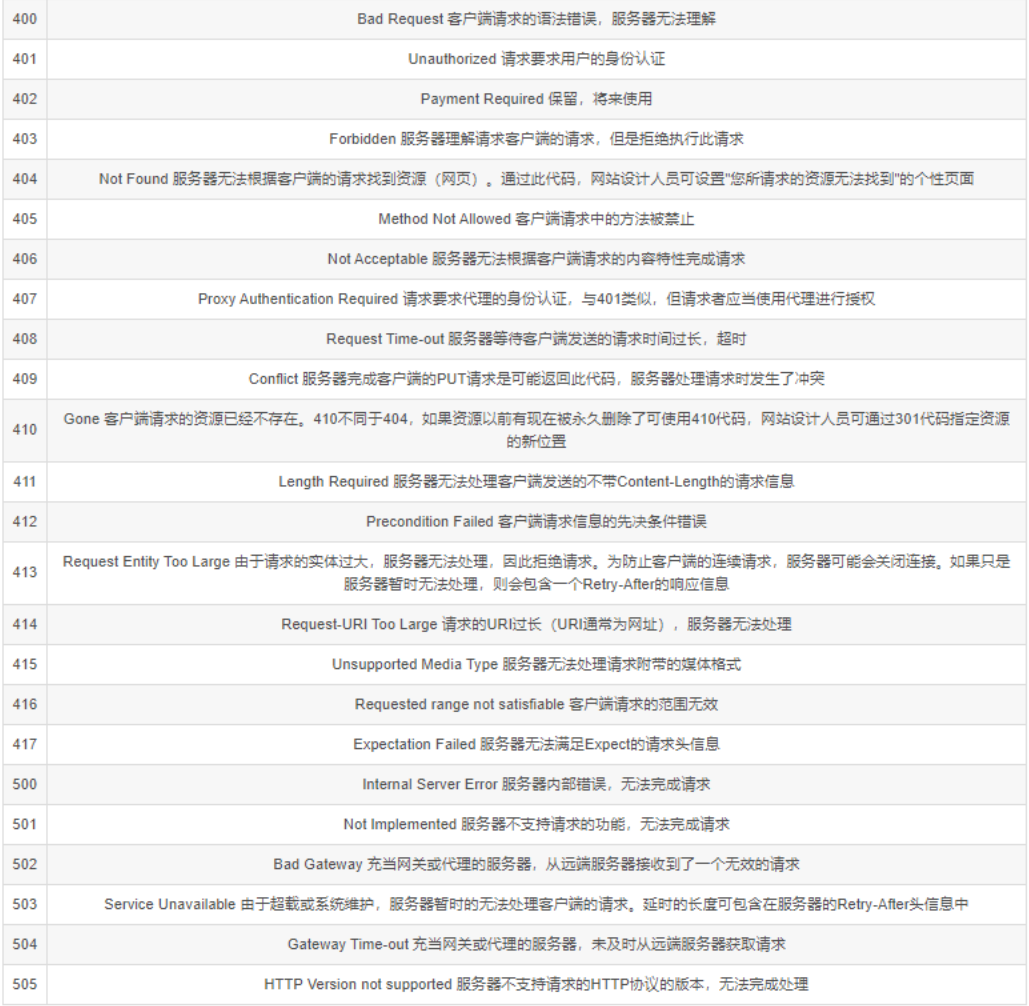
响应状态码
|-----|-------------------------------|
| 1xx | 服务器接收客户端消息,但没有接受完成,等待一段时间后发送的 |
| 2xx | 成功 |
| 3xx | 重定向 |
| 4xx | 客户端错误 |
| 5xx | 服务器端错误 |
Requests库的七个主要方法
|--------------------|------------------|---------|
| 方法 | 说明 | 对应HTTP的 |
| requests.request() | 构造一个请求,支撑以下各个方法的基础方法 ||
| requests.get() | 获取HTML网页的主要方法 | GET |
| requests.head() | 获取HTML头信息的方法 | HEAD |
| requests.post() | 向HTML提交POST请求的方法 | POST |
| requests.put() | 向HTML提交PUT请求的方法 | PUT |
| requests.patch() | 向HTML提交局部修改请求 | PATCH |
| requests.delete() | 向HTML提交删除请求 | DELETE |
Response对象的属性
|---------------------|-----------------------------|
| 属性 | 说明 |
| r.status_code | HTTP请求的返回状态,200连接成功,404连接失败 |
| r.text | HTTP相应内容的字符串形式,即url对应的页面内容 |
| r.encoding | 从HTTP header中猜测的相应内容编码方式 |
| r.apparent_encoding | 从内容中分析出的相应内容编码方式(备选编码方式) |
| r.content | HTTP相应内容的二进制形式 |
Requests库的异常
|---------------------------|--------------------------|
| 异常 | 说明 |
| requests.ConnectionError | 网络连接错误异常, 如DNS查询失败、拒绝连接等 |
| requests.HTTPError | HTTP错误异常 |
| requests.URLRequired | URL缺失异常 |
| requests.TooManyRedirects | 超过最大重定向次数,产生重定向异常 |
| requests.ConnectTimeout | 连接远程服务器超时异常 |
| requests.Timeout | 请求URL超时,产生超时异常 |
Python读写文件模式汇总
基本打开方式
| 模式 | 描述 | 文件存在 | 文件不存在 |
|---|---|---|---|
| r | 只读 | 打开文件 | 报错(FileNotFoundError) |
| w | 只写 | 清空文件 | 创建新文件 |
| a | 追加 | 从末尾写入 | 创建新文件 |
| x | 排他创建 | 报错(FileExistsError) | 创建新文件 |
组合模式
| 模式 | 描述 |
|---|---|
| r+ | 读写(文件必须存在) |
| w+ | 读写(清空文件或创建新文件) |
| a+ | 读写(从末尾追加或创建新文件) |
二进制模式
以上模式后加b,如rb,rb+,ab+。表示二进制模式。