
使用在线模型服务时,我们常常需要支付API调用费用,这对于个人开发者或小型组织来说可能是一笔不小的开支。那么,有没有方法可以在本地免费使用这些强大的模型呢?答案是肯定的------Ollama就是这样一个工具。
当然如果是比较大的组织或大模型推荐使用vLLM部署,强烈推荐您看(占坑,后续填上)
本文将介绍Ollama并且带您一步步在个人PC上部署一个自己的LLM。
笔者的电脑是windows,无GPU 。
将带您部署(若您计算机性能比较高,只需要参考文中模型与配置关系,更改更大模型即可)
Gemma 2B版本:约1.7GB什么是Ollama?
Ollama是一个开源的大语言模型管理平台,它允许用户在本地机器上部署、管理和使用各种开源语言模型。
Ollama最出色的优点如下:
-
将开源模型(如DeepSeek、Llama等)下载并部署到本地。从而让公司实现私有化+免费部署LLM。
-
性能强大:充分利用本地资源,既可以使用GPU也可以使用CPU。如果没有Ollama,我们需要自己配置GPU环境如cuda等等,与传统的模型部署相比,Ollama大大简化了GPU环境配置的复杂性,降低了使用门槛。
-
跨平台支持:Ollama 支持 macOs、Windows、Linux 以及 Docker多种操作系统环境下顺利部署和使用。无论你使用什么系统,都可以轻松部署和使用Ollama。
Ollama的下载与安装
在官网下载即可,本文以windows为例。
最好确保您的计算机C盘有10G+磁盘空间,因为后文下的大模型都会比较大。
以Windows为例,Ollama的安装过程非常简单,笔者安装中也没有遇到任何问题:
- 双击下载的EXE安装包
- 在弹出的安装界面中点击"Install"按钮
- 等待安装完成(通常只需几分钟)
本机部署问答模型
Ollama支持多种流行的开源大语言模型,您可以通过访问Ollama官网的Models页面浏览所有可用模型。
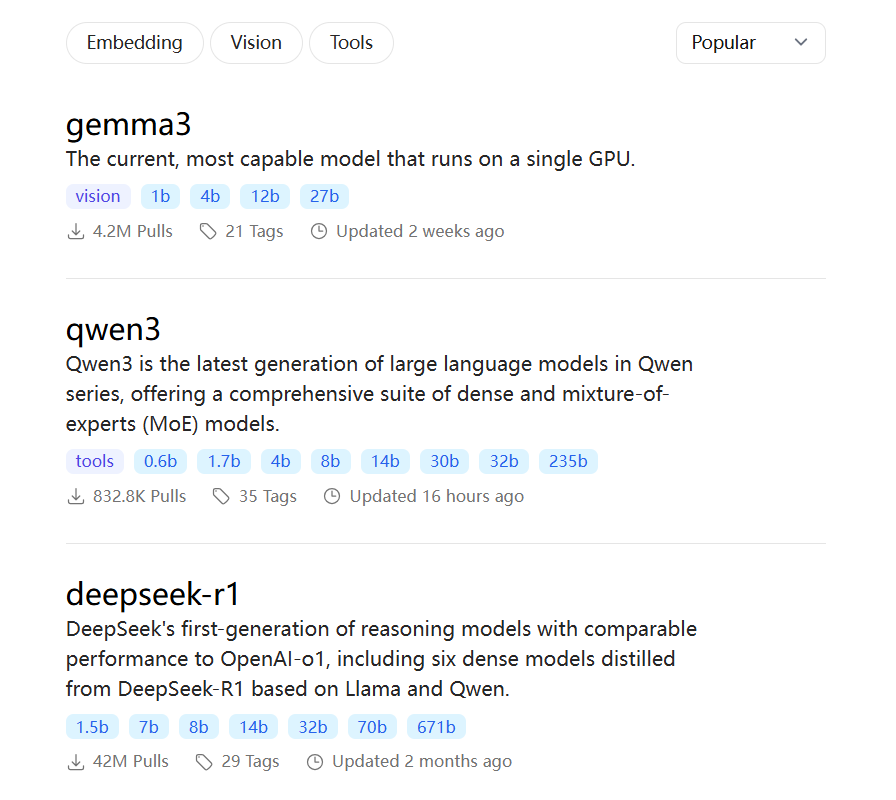
浏览Ollama模型库时,您会注意到每个模型都有不同的版本,如7B、13B、33B等。这里的"B"表示"Billion"(十亿),所以7B表示70亿参数,13B表示130亿参数,依此类推。
根据Ollama官方的建议,不同参数量的模型对系统资源(特别是内存)有以下最低要求:
| 模型参数量 | 最低内存需求 |
|---|---|
| 7B | 8GB RAM |
| 13B | 16GB RAM |
| 33B | 32GB RAM |
| 70B | 128GB RAM |
需要特别注意的是,虽然一些特别大的模型(如400GB+)可以下载到本地,但您的设备可能没有足够的GPU或CPU资源来流畅运行它们。
对于普通个人电脑用户,建议选择10GB以下大小的模型以保证运行流畅。
语言类模型推荐
- Gemma - Google开发的开源模型,性能优秀,资源需求适中
- DeepSeek - 中国开发的强大语言模型,各方面表现均衡
- Qwen(千问) - 阿里巴巴开发的模型,中文能力出色
视觉类模型推荐
- LLaVA - 专为图像识别和理解训练的模型,能够分析和描述图片内容
- MiniCPM-V - 轻量级但功能强大的视觉模型,支持图像理解和生成
实操过程
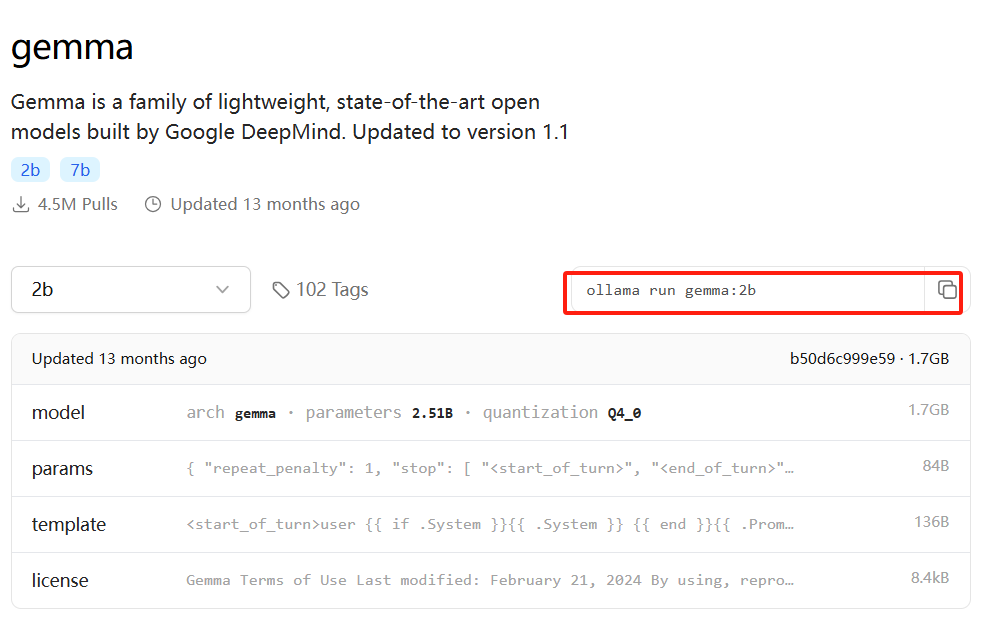
安装完Ollama后,我们首先需要下载模型才能开始使用。本文我们以Google开发的Gemma 2b模型为例。在官网查询gemma模型,输入后可以看到以下界面。红色方框的是命令行下下载gemma的命令ollama run gemma:2b。同时也可以看到这个模型大概会占用1.7GB磁盘
CMD中安装,下载完成后会直接启动该模型,我问了个给我讲个笑话:

常见命令
ollama list 列出所有已安装的模型
ollama pull [模型名称] 下载模型但不运行
ollama run [模型名称] 运行模型(首次会自动下载)
/clear 清除当前对话上下文,保持模型运行
Ctrl+D 退出当前模型
Ollama进阶:自定义模型创建与参数调优指南
在Ollama中,自定义模型是指基于已有的开源模型,通过调整其参数和行为特征来创建一个新模型。这个过程不涉及真正的模型训练或微调 ,而是通过配置文件来改变模型的输出特性和交互方式。
步骤一:创建Modelfile配置文件
首先,我们需要创建一个名为Modelfile的文本文件,在这个文件中定义模型的基础信息和参数。这个文件的基本结构如下:
FROM [基础模型名称]
PARAMETER [参数名] [参数值]
SYSTEM [系统提示词]例如,我们的Modelfile是这样的:
FROM gemma:2b
PARAMETER temperature 0.8
SYSTEM 你是一名叫做小智的助手,专长领域是文学和历史相关内容,喜欢使用生动有趣的方式与用户交谈。这个配置包含三个主要部分:
FROM:指定基础模型,这里我们选择了本机已装好的gemma:2b模型PARAMETER:设置模型参数,这里将temperature(温度)设为0.9SYSTEM:定义系统提示词,告诉模型它的角色和行为特点
步骤二:保存Modelfile文件
将创建好的Modelfile保存到本地磁盘,例如保存到C盘根目录。需要注意的是,这个文件不需要任何扩展名,就是纯文本的Modelfile。
这里笔者是保存在C:\Users\86199\AppData\Local\Ollama中的
步骤三:使用Ollama创建命令
使用以下命令创建自定义模型:
ollama create [自定义模型名称] -f [Modelfile路径]例如:
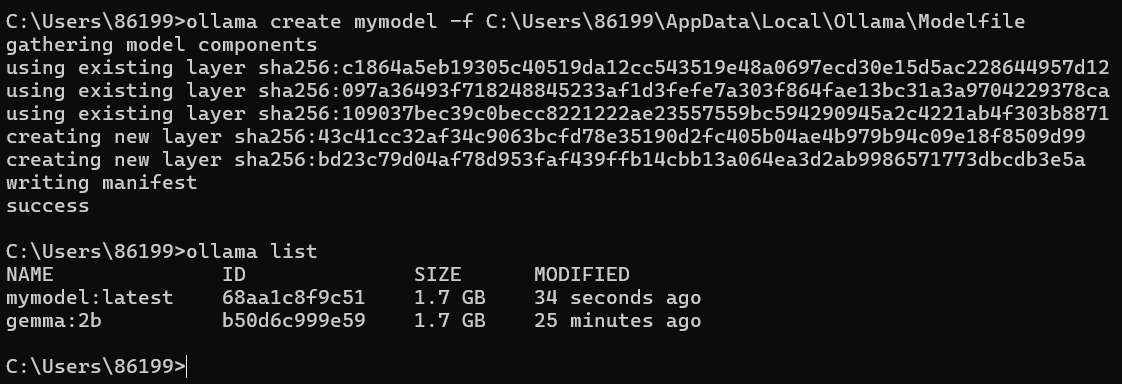
ollama create mymodel -f C:\Users\86199\AppData\Local\Ollama\Modelfile执行该命令后,Ollama会读取Modelfile中的配置,基于指定的基础模型创建一个新的自定义模型。成功后,会显示"success"提示。
若您想明确模型是否创建成功,使用ollama list命令查看本地模型列表,确认自定义模型已成功创建。新创建的模型会以指定的名称出现在列表中。
步骤四:使用自定义模型
创建完成后,可以像使用其他模型一样运行自定义模型:
ollama run mymodel